Tutorial: Configurar a Sincronização de Dados SQL entre bases de dados na Base de Dados SQL do Azure e no SQL Server
Aplica-se a:![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
Neste tutorial, você aprenderá a configurar a Sincronização de Dados SQL criando um grupo de sincronização que contém o Banco de Dados SQL do Azure e instâncias do SQL Server. O grupo de sincronização é configurado de forma personalizada e sincronizado na agenda definida.
O tutorial pressupõe que você tenha pelo menos alguma experiência anterior com o Banco de dados SQL e o SQL Server.
Para obter uma visão geral da Sincronização de Dados SQL, consulte Sincronizar dados em bancos de dados locais e na nuvem com a Sincronização de Dados SQL.
Para obter exemplos do PowerShell sobre como configurar a Sincronização de Dados SQL, consulte Como sincronizar entre bancos de dados no Banco de Dados SQL ou entre bancos de dados no Banco de Dados SQL do Azure e no SQL Server
Importante
O banco de dados hub é o ponto de extremidade central de uma topologia de sincronização, no qual um grupo de sincronização tem vários pontos de extremidade de banco de dados. Todos os outros bancos de dados membros com pontos de extremidade no grupo de sincronização, sincronizam com o banco de dados do hub .
Atualmente, a Sincronização de Dados SQL só tem suporte no Banco de Dados SQL do Azure. O banco de dados de hub deve ser um Banco de Dados SQL do Azure.
O Hiperdimensionamento do Banco de Dados SQL do Azure só tem suporte como um banco de dados membro, não como um banco de dados de hub .
Criar grupo de sincronização
Aceda ao portal do Azure. Procure e selecione bancos de dados SQL para localizar um Banco de Dados SQL do Azure existente.
Selecione o banco de dados existente que você deseja usar como o banco de dados de hub para Sincronização de Dados.
No menu de recursos do banco de dados SQL para o banco de dados selecionado, em Gerenciamento de dados, selecione Sincronizar com outros bancos de dados.
Na página Sincronizar com outros bancos de dados, selecione Novo Grupo de Sincronização. A página do grupo Criar Sincronização de Dados é aberta.
Na página Criar Grupo de Sincronização de Dados, defina as seguintes configurações:
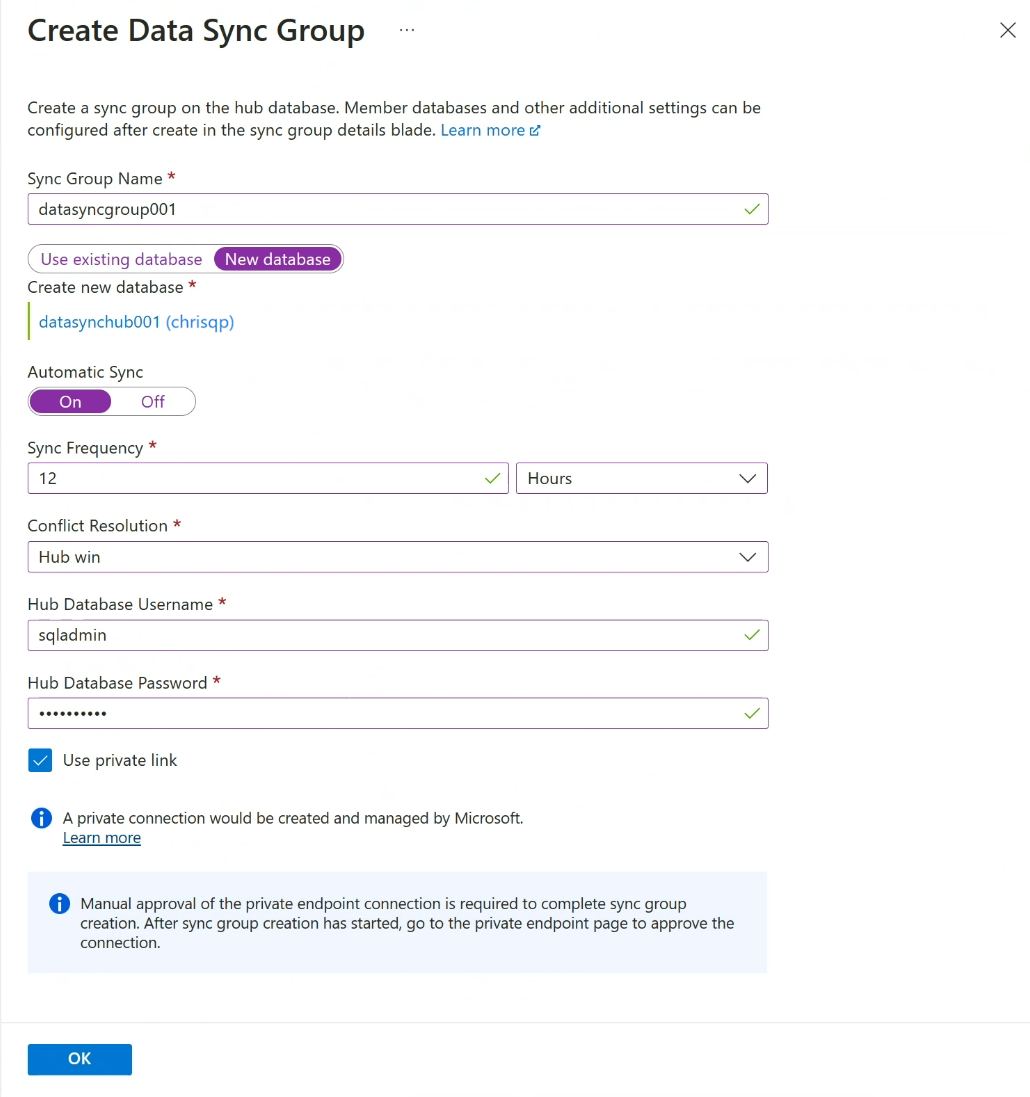
Cenário Description Sincronizar nome do grupo Insira um nome para o novo grupo de sincronização. Esse nome é distinto do nome do próprio banco de dados. Sincronizar banco de dados de metadados Escolha criar um banco de dados (recomendado) ou usar um banco de dados existente para servir como o Banco de Dados de Metadados de Sincronização.
A Microsoft recomenda a criação de um novo banco de dados vazio para uso como o Banco de Dados de Metadados de Sincronização. A Sincronização de Dados cria tabelas nesta base de dados e executa uma carga de trabalho frequente. Esse banco de dados é compartilhado como o Banco de Dados de Metadados de Sincronização para todos os grupos de sincronização em uma região e assinatura selecionadas. Não é possível alterar o banco de dados ou seu nome sem remover todos os grupos de sincronização e agentes de sincronização na região.
Se você optar por criar um novo banco de dados, selecione Novo banco de dados. Selecione Definir configurações do banco de dados. Na página Banco de Dados SQL, nomeie e configure um novo Banco de Dados SQL do Azure e selecione OK.
Se você escolher Usar banco de dados existente, selecione o banco de dados na lista suspensa Sincronizar banco de dados de metadados.Sincronização automática Selecione Ativado ou Desativado.
Se escolher Ativado, introduza um número e selecione Segundos, Minutos, Horas ou Dias na secção Frequência de Sincronização .
A primeira sincronização começa depois que o período de intervalo selecionado decorre a partir do momento em que a configuração é salva.Resolução de Conflitos Selecione Vitória do Hub ou Vitória do Membro.
A vitória do hub significa que, quando ocorrem conflitos, os dados no banco de dados do hub substituem os dados conflitantes no banco de dados membro.
Vitória de membro significa que, quando ocorrem conflitos, os dados no banco de dados de membros substituem os dados conflitantes no banco de dados do hub.Nome de usuário do banco de dados de hub e senha do banco de dados de hub Forneça o nome de usuário e a senha para o logon autenticado SQL do administrador do servidor para o banco de dados Hub. Este é o nome de usuário e a senha do administrador do servidor para o mesmo servidor lógico SQL do Azure no qual você começou. A autenticação Microsoft Entra (anteriormente Azure Ative Directory) não é suportada atualmente. Usar link privado Escolha um ponto de extremidade privado gerenciado pelo serviço para estabelecer uma conexão segura entre o serviço de sincronização e o banco de dados do hub. Selecione OK e aguarde até que o grupo de sincronização seja criado e implantado.
Na página Novo Grupo de Sincronização, se você selecionou Usar link privado, precisará aprovar a conexão de ponto de extremidade privado. O link na mensagem informativa levará você para a experiência de conexões de ponto de extremidade privado, onde você pode aprovar a conexão.
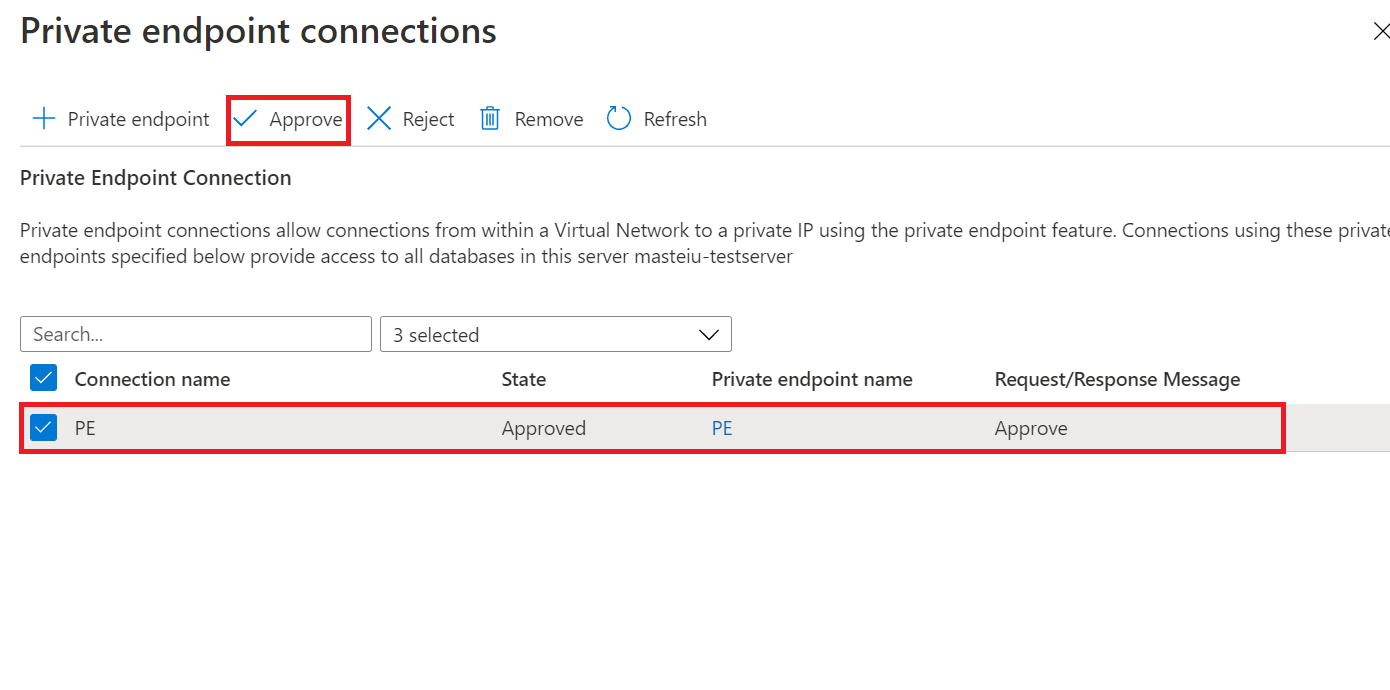
Nota
Os links privados para o grupo de sincronização e os membros de sincronização precisam ser criados, aprovados e desabilitados separadamente.
Adicionar membros de sincronização
Depois que o novo grupo de sincronização for criado e implantado, abra o grupo de sincronização e acesse a página Bancos de dados, onde você selecionará os membros da sincronização.
Nota
Para atualizar ou inserir o nome de usuário e a senha no banco de dados do hub, vá para a seção Banco de Dados do Hub na página Selecionar membros de sincronização.
Adicionar um banco de dados no Banco de Dados SQL do Azure como membro a um grupo de sincronização
Na seção Selecionar membros de sincronização, opcionalmente, adicione um banco de dados no Banco de Dados SQL do Azure ao grupo de sincronização selecionando Adicionar um Banco de Dados do Azure. A página Configurar Banco de Dados do Azure é aberta.
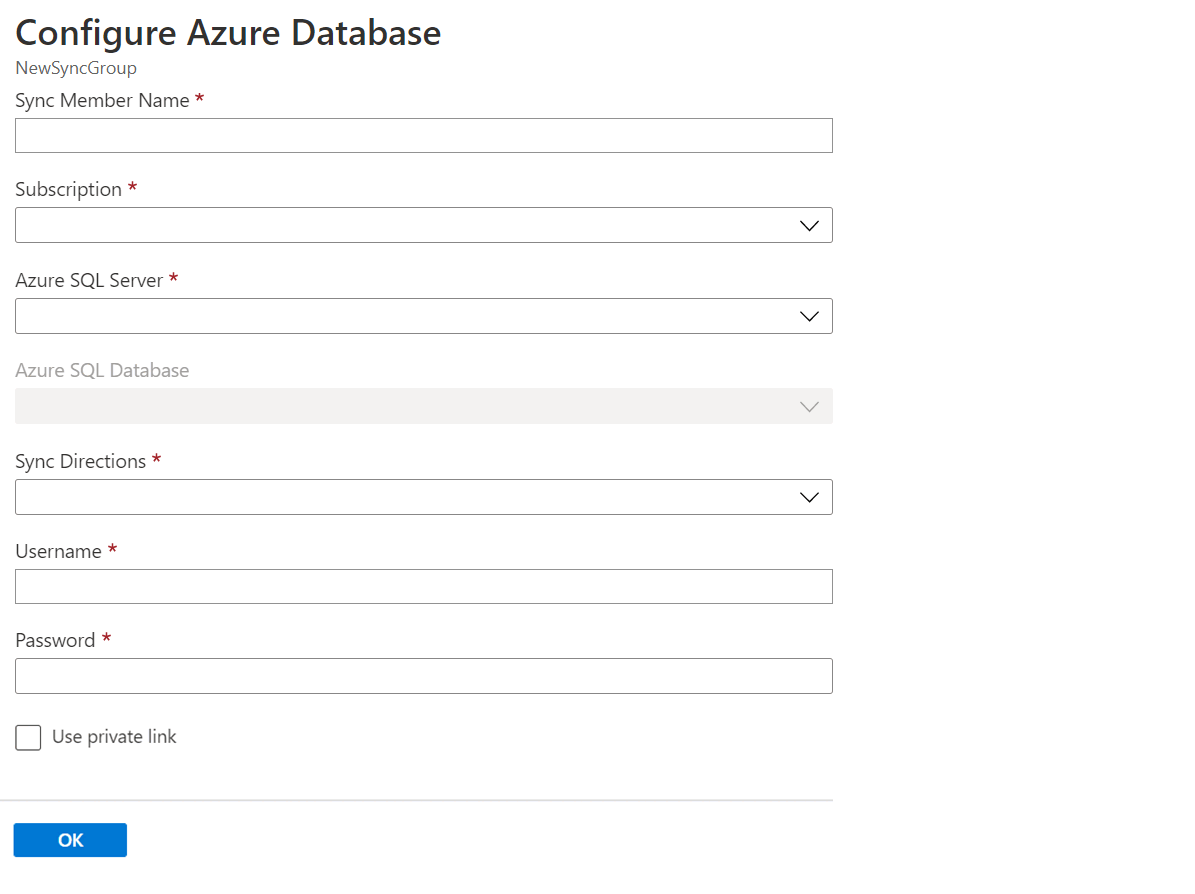
Na página Configurar Banco de Dados SQL do Azure, altere as seguintes configurações:
Cenário Description Sincronizar Nome do Membro Forneça um nome para o novo membro de sincronização. Esse nome é distinto do próprio nome do banco de dados. Subscrição Selecione a assinatura do Azure associada para fins de cobrança. Azure SQL Server Selecione o servidor existente. Base de Dados SQL do Azure Selecione o banco de dados existente no Banco de dados SQL. Sincronizar direções A Direção de Sincronização pode ser Hub para Membro, Membro para Hub, ou ambos. Selecione Do Hub, Para o Hub ou Sincronização Bidirecional. Para obter mais informações, consulte Como funciona. Nome de utilizador e palavra-passe Insira as credenciais existentes para o servidor no qual o banco de dados membro está localizado. Não insira novas credenciais nesta seção. Usar link privado Escolha um ponto de extremidade privado gerenciado pelo serviço para estabelecer uma conexão segura entre o serviço de sincronização e o banco de dados membro. Selecione OK e aguarde até que o novo membro de sincronização seja criado e implantado.
Adicionar um banco de dados em uma instância do SQL Server como membro a um grupo de sincronização
Na seção Banco de Dados de Membros, opcionalmente, adicione um banco de dados em uma instância do SQL Server ao grupo de sincronização selecionando Adicionar um Banco de Dados Local.
A página Configurar Local é aberta, onde você pode fazer o seguinte:
Selecione Choose the Sync Agent Gateway (Escolher o gateway do agente de sincronização). A página Select Sync Agent (Selecionar agente de sincronização ) é aberta.
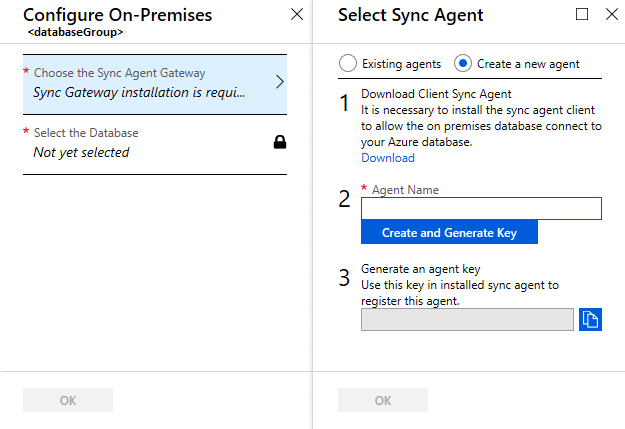
Na página Escolha o agente de sincronização, escolha se deseja usar um agente existente ou criar um agente.
Se você escolher Agentes existentes, selecione o agente existente na lista.
Se você escolher Criar um novo agente, faça o seguinte:
Baixe o agente de sincronização de dados do link fornecido e instale-o em um servidor diferente de onde a instância do SQL Server está localizada. Você também pode baixar o agente diretamente do SQL Data Sync Agent do Azure. Para obter as práticas recomendadas no agente de cliente de sincronização, consulte Práticas recomendadas para o Azure SQL Data Sync.
Importante
Você precisa abrir a porta TCP de saída 1433 no firewall para permitir que o agente cliente se comunique com o servidor.
Insira um nome de agente.
Selecione Criar e gerar chave e copie a chave do agente para a área de transferência.
Selecione OK para fechar a página Selecionar agente de sincronização .
No servidor onde o agente do cliente de sincronização está instalado, localize e execute o aplicativo Client Sync Agent.
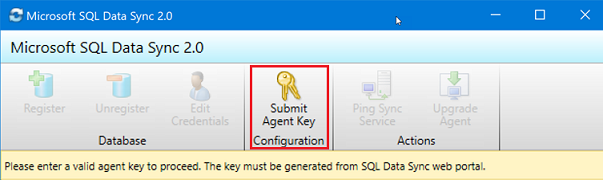
No aplicativo do agente de sincronização, selecione Enviar chave do agente. A caixa de diálogo Sincronizar Configuração do Banco de Dados de Metadados é aberta.
Na caixa de diálogo Sincronizar Configuração do Banco de Dados de Metadados, cole a chave do agente copiada do portal do Azure. Forneça também as credenciais existentes para o servidor no qual o banco de dados do Banco de Dados de Metadados de Sincronização está localizado. Selecione OK e aguarde a conclusão da configuração.
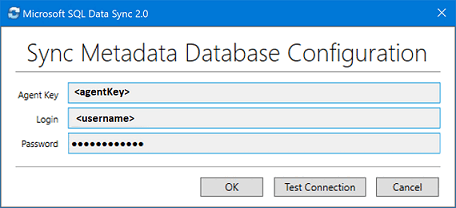
Nota
Se você receber um erro de firewall, crie uma regra de firewall no Azure para permitir o tráfego de entrada do computador do SQL Server. Você pode criar a regra manualmente no portal ou no SQL Server Management Studio (SSMS). No SSMS, conecte-se ao banco de dados de hub no Azure inserindo seu nome como
<hub_database_name>.database.windows.net.Selecione Registrar para registrar um banco de dados do SQL Server com o agente. A caixa de diálogo Configuração do SQL Server é aberta.
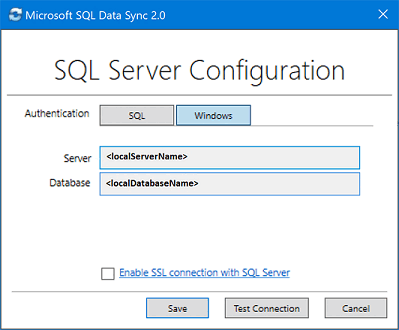
Na caixa de diálogo Configuração do SQL Server, escolha conectar-se usando a autenticação do SQL Server ou a autenticação do Windows. Se você escolher a autenticação do SQL Server, insira as credenciais existentes. Forneça o nome do SQL Server e o nome do banco de dados que você deseja sincronizar e selecione Testar conexão para testar suas configurações. Em seguida, selecione Salvar e o banco de dados registrado aparecerá na lista.
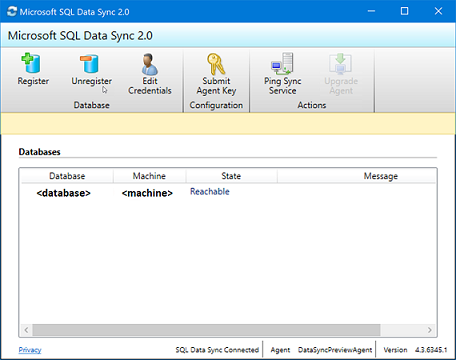
Feche o aplicativo Client Sync Agent.
No portal do Azure, na página Configurar Local , selecione Selecionar o Banco de Dados.
Na página Selecionar Banco de Dados, no campo Nome do Membro de Sincronização, forneça um nome para o novo membro de sincronização. Esse nome é distinto do nome do próprio banco de dados. Selecione o banco de dados na lista. No campo Direções de Sincronização, selecione Sincronização Bidirecional, Para o Hub ou Do Hub.
Selecione OK para fechar a página Selecionar banco de dados . Em seguida, selecione OK para fechar a página Configurar Local e aguardar até que o novo membro de sincronização seja criado e implantado. Por fim, selecione OK para fechar a página Selecionar membros da sincronização.
Nota
Para se conectar à Sincronização de Dados SQL e ao agente local, adicione seu nome de usuário à função DataSync_Executor. A Sincronização de Dados cria essa função na instância do SQL Server.
Configurar grupo de sincronização
Depois que os novos membros do grupo de sincronização forem criados e implantados, vá para a seção Tabelas na página Grupo de Sincronização de Banco de Dados.
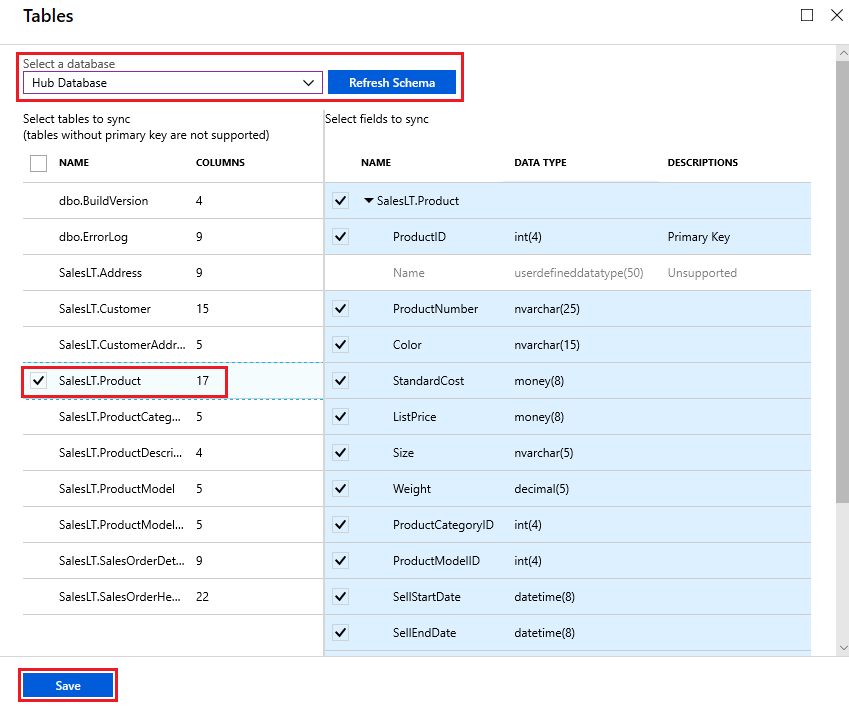
Na página Tabelas, selecione um banco de dados na lista de membros do grupo de sincronização e selecione Atualizar esquema. Espere alguns minutos de atraso no esquema de atualização, o atraso pode ser alguns minutos maior se estiver usando link privado.
Na lista, selecione as tabelas que deseja sincronizar. Por padrão, todas as colunas são selecionadas, portanto, desative a caixa de seleção das colunas que você não deseja sincronizar. Certifique-se de deixar a coluna de chave primária selecionada.
Selecione Guardar.
Por padrão, os bancos de dados não são sincronizados até que sejam agendados ou executados manualmente. Para executar uma sincronização manual, navegue até seu banco de dados no Banco de Dados SQL no portal do Azure, selecione Sincronizar com outros bancos de dados e selecione o grupo de sincronização. A página Sincronização de dados é aberta. Selecione Sincronizar.
FAQ
Esta seção responde a perguntas frequentes sobre o serviço Azure SQL Data Sync.
O SQL Data Sync cria tabelas totalmente?
Se existirem tabelas do esquema de sincronização em falta na base de dados de destino, a Sincronização de Dados SQL cria-as com as colunas que selecionou. No entanto, isso não resulta em um esquema de fidelidade total pelos seguintes motivos:
- Apenas as colunas que selecionar são criadas na tabela de destino. As colunas não selecionadas são ignoradas.
- Apenas os índices de colunas selecionadas são criados na tabela de destino. Para as colunas não selecionadas, esses índices são ignorados.
- Não são criados os índices em colunas de tipo XML.
- Não são criadas restrições CHECK.
- Não são criados acionadores em tabelas de origem.
- Não são criados procedimentos armazenados e vistas.
Devido a estas limitações, recomendamos os seguintes procedimentos:
- Para ambientes de produção, crie o esquema de fidelidade total por conta própria.
- Ao experimentar com o serviço, utilize a funcionalidade de aprovisionamento automático.
Por que motivo vejo tabelas que não criei?
A Sincronização de Dados cria tabelas adicionais no banco de dados para controle de alterações. Não os exclua ou a Sincronização de Dados para de funcionar.
Os meus dados são convergentes após uma sincronização?
Não necessariamente. Pegue um grupo de sincronização com um hub e três raios (A, B e C) onde as sincronizações são Hub para A, Hub para B e Hub para C. Se for feita uma alteração no banco de dados A após a sincronização do Hub para A, essa alteração não será gravada no banco de dados B ou no banco de dados C até a próxima tarefa de sincronização.
Como faço para obter alterações de esquema em um grupo de sincronização?
Faça e propague todas as alterações de esquema manualmente.
- Replique as alterações de esquema manualmente para o hub e para todos os membros de sincronização.
- Atualize o esquema de sincronização.
Para adicionar novas tabelas e colunas:
Novas tabelas e colunas não afetam a sincronização atual e a Sincronização de Dados as ignora até que sejam adicionadas ao esquema de sincronização. Ao adicionar novos objetos de banco de dados, siga a sequência:
- Adicione novas tabelas ou colunas ao hub e a todos os membros da sincronização.
- Adicione novas tabelas ou colunas ao esquema de sincronização.
- Comece a inserir valores nas novas tabelas e colunas.
Para alterar o tipo de dados de uma coluna:
Quando você altera o tipo de dados de uma coluna existente, a Sincronização de Dados continua a funcionar desde que os novos valores se ajustem ao tipo de dados original definido no esquema de sincronização. Por exemplo, se você alterar o tipo no banco de dados de origem de int para bigint, a Sincronização de Dados continuará a funcionar até que você insira um valor muito grande para o tipo de dados int. Para concluir a alteração, replique a alteração de esquema manualmente para o hub e para todos os membros de sincronização e, em seguida, atualize o esquema de sincronização.
Como posso exportar e importar um banco de dados com o Data Sync?
Depois de exportar um banco de dados como um arquivo e importar o arquivo para criar um .bacpac banco de dados, faça o seguinte para usar a Sincronização de Dados no novo banco de dados:
- Limpe os objetos da Sincronização de Dados e as tabelas adicionais no novo banco de dados usando a Limpeza completa da Sincronização de Dados.sql. O script exclui todos os objetos de sincronização de dados necessários do banco de dados.
- Recrie o grupo de sincronização com o novo banco de dados. Se você não precisar mais do grupo de sincronização antigo, exclua-o.
Onde posso encontrar informações sobre o agente do cliente?
Para perguntas frequentes sobre o agente cliente, consulte Perguntas frequentes sobre o agente.
É necessário aprovar manualmente o link antes de começar a usá-lo?
Sim. Você deve aprovar manualmente o ponto de extremidade privado gerenciado pelo serviço, na página Conexões de ponto de extremidade privado do portal do Azure durante a implantação do grupo de sincronização ou usando o PowerShell.
Por que recebo um erro de firewall quando o trabalho de sincronização está provisionando meu banco de dados do Azure?
Isso pode acontecer porque os recursos do Azure não têm permissão para acessar seu servidor. Existem duas soluções:
- Verifique se o firewall no banco de dados do Azure definiu Permitir que os serviços e recursos do Azure acessem este servidor como Sim. Para obter mais informações, consulte Banco de Dados SQL do Azure e controles de acesso à rede.
- Configure um link privado para a Sincronização de Dados, que é diferente de um Link Privado do Azure. Private Link é a maneira de criar grupos de sincronização usando conexão segura com bancos de dados protegidos por um firewall. O SQL Data Sync Private Link é um ponto de extremidade gerenciado pela Microsoft e cria internamente uma sub-rede dentro da rede virtual existente, portanto, não há necessidade de criar outra rede virtual ou sub-rede.
Próximos passos
Parabéns! Você criou um grupo de sincronização que inclui um banco de dados SQL do Azure e um banco de dados do SQL Server.
Para obter mais informações sobre a Sincronização de Dados SQL, veja:
- O que é a Sincronização de Dados SQL para o Azure?
- Agente de sincronização de dados para sincronização de dados SQL do Azure
- Práticas recomendadas e como solucionar problemas com o Azure SQL Data Sync
- Monitorizar Sincronização de Dados SQL com os registos do Azure Monitor
- Atualizar o esquema de sincronização com Transact-SQL ou PowerShell
Para obter mais informações sobre a Base de Dados SQL, veja:
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários