Descrição geral da continuidade empresarial com o Azure SQL Managed Instance
Aplica-se a:![]() Instância Gerenciada SQL do Azure
Instância Gerenciada SQL do Azure
Este artigo fornece uma visão geral dos recursos de continuidade de negócios e recuperação de desastres da Instância Gerenciada SQL do Azure, descrevendo as opções e recomendações para a recuperação de eventos com interrupções que podem levar à perda de dados ou fazer com que sua instância e aplicativo fiquem indisponíveis. Saiba o que fazer quando um erro de usuário ou aplicativo afeta a integridade dos dados, uma zona ou região de disponibilidade do Azure tem uma interrupção ou seu aplicativo requer manutenção.
Descrição geral
A continuidade de negócios na Instância Gerenciada SQL do Azure refere-se aos mecanismos, políticas e procedimentos que permitem que sua empresa continue operando em caso de interrupção, fornecendo disponibilidade, alta disponibilidade e recuperação de desastres.
Na maioria dos casos, a Instância Gerenciada SQL lida com eventos disruptivos que podem acontecer em um ambiente de nuvem e mantém seus aplicativos e processos de negócios em execução. No entanto, existem alguns eventos disruptivos em que a mitigação pode levar algum tempo, tais como:
- O usuário exclui ou atualiza acidentalmente uma linha em uma tabela.
- Invasor mal-intencionado exclui dados com êxito ou descarta um banco de dados.
- Um evento de desastre natural catastrófico derruba um datacenter ou uma zona ou região de disponibilidade.
- Datacenter raro, zona de disponibilidade ou interrupção em toda a região causada por uma alteração de configuração, bug de software ou falha de componente de hardware.
Disponibilidade
A Instância Gerenciada SQL do Azure vem com uma promessa de resiliência e confiabilidade central que a protege contra falhas de software ou hardware. Os backups de banco de dados são automatizados para proteger seus dados contra corrupção ou exclusão acidental. Como uma plataforma como serviço (PaaS), o serviço de Instância Gerenciada SQL do Azure fornece disponibilidade como um recurso pronto para uso com um SLA de disponibilidade líder do setor de 99,99%.
Elevada Disponibilidade
Para obter alta disponibilidade no ambiente de nuvem do Azure, habilite a redundância de zona para que a instância use zonas de disponibilidade para garantir resiliência a falhas zonais. Muitas regiões do Azure fornecem zonas de disponibilidade, que são grupos separados de data centers dentro de uma região que têm infraestrutura independente de energia, resfriamento e rede. As zonas de disponibilidade são projetadas para fornecer serviços regionais, capacidade e alta disponibilidade nas zonas restantes se uma zona sofrer uma interrupção. Ao habilitar a redundância de zona, a instância é resiliente a falhas zonais de hardware e software e a recuperação é transparente para os aplicativos. Quando a alta disponibilidade está habilitada, o serviço de Instância Gerenciada SQL do Azure é capaz de fornecer um SLA de maior disponibilidade de 99,995%.
Recuperação após desastre
Para obter maior disponibilidade e redundância entre regiões, você pode habilitar os recursos de recuperação de desastres para recuperar rapidamente a instância de uma falha regional catastrófica. As opções para recuperação de desastres com a Instância Gerenciada SQL do Azure são:
- Os grupos de failover permitem a sincronização contínua entre uma instância primária e secundária. Os grupos de failover fornecem pontos de extremidade de escuta de leitura-gravação e somente leitura que permanecem inalterados, portanto, não é necessário atualizar as cadeias de conexão do aplicativo após o failover.
- A restauração geográfica permite que você se recupere de uma interrupção regional restaurando a partir de backups replicados geograficamente quando não for possível acessar seu banco de dados na região primária criando um novo banco de dados em qualquer instância existente em qualquer região do Azure.
Recursos que fornecem continuidade de negócios
Por exemplo, existem quatro grandes cenários potenciais de perturbação. A tabela a seguir lista os recursos de continuidade de negócios da Instância Gerenciada SQL que você pode usar para mitigar um possível cenário de interrupção de negócios:
| Cenário de interrupção de negócios | Recurso de continuidade de negócios |
|---|---|
| Falhas locais de hardware ou software que afetam o nó do banco de dados. | Para mitigar falhas locais de hardware e software, a Instância Gerenciada SQL inclui uma arquitetura de disponibilidade, que garante a recuperação automática dessas falhas com SLA de disponibilidade de até 99,99%. |
| Corrupção ou exclusão de dados normalmente causada por um bug do aplicativo ou erro humano. Essas falhas são específicas do aplicativo e normalmente não podem ser detetadas pelo serviço. | Para proteger sua empresa contra perda de dados, a Instância Gerenciada SQL cria automaticamente backups completos de banco de dados semanalmente, backups diferenciais de banco de dados a cada 12 ou 24 horas e backups de log de transações a cada 5 a 10 minutos. Por padrão, os backups são armazenados em armazenamento com redundância geográfica por sete dias e suportam um período de retenção de backup configurável para restauração point-in-time de até 35 dias. Você pode restaurar um banco de dados excluído até o ponto em que ele foi excluído se a instância não tiver sido excluída ou se você tiver configurado a retenção de longo prazo. |
| Rara interrupção do datacenter ou da zona de disponibilidade, possivelmente causada por um evento de desastre natural, alteração de configuração, bug de software ou falha de componente de hardware. | Para atenuar a interrupção do datacenter ou da zona de disponibilidade, habilite a redundância de zona para a Instância Gerenciada do SQL para usar as Zonas de Disponibilidade do Azure e fornecer redundância em várias zonas físicas dentro de uma região do Azure. Habilitar a redundância de zona garante que a instância gerenciada seja resiliente a falhas zonais com SLA de alta disponibilidade de até 99,995%. |
| Rara interrupção da região que afeta todas as zonas de disponibilidade e os datacenters que as compõem, possivelmente causada por um evento catastrófico de desastre natural. | Para mitigar uma interrupção em toda a região, habilite a recuperação de desastres usando uma das opções: - Sincronização contínua de dados com grupos de failover para réplicas em uma região secundária usada para failover. - Configuração de redundância de armazenamento de backup para armazenamento de backup com redundância geográfica para usar restauração geográfica. |
RTO e RPO
Ao desenvolver seu plano de continuidade de negócios, entenda o tempo máximo aceitável antes que o aplicativo se recupere totalmente após o evento de interrupção. O tempo necessário para que um aplicativo se recupere totalmente é conhecido como RTO (Recovery Time Objetive, objetivo de tempo de recuperação). Entenda também o período máximo de atualizações de dados recentes (intervalo de tempo) que o aplicativo pode tolerar perder ao se recuperar de um evento disruptivo não planejado. A perda potencial de dados é conhecida como RPO (Recovery Point Objetive, objetivo de ponto de recuperação).
A tabela a seguir compara RPO e RTO de cada opção de continuidade de negócios:
| Opção de continuidade de negócios | RTO (tempo de inatividade) | RPO (perda de dados) |
|---|---|---|
| Alta disponibilidade (habilitando redundância de zona) |
Normalmente menos de 30 segundos | 0 |
| Recuperação de desastres (habilitando grupos de failover) |
1 hora | 5 segundos (depende de alterações de dados antes do evento de interrupção que não foram replicadas) |
| Recuperação de desastres (usando restauração geográfica) |
12 horas | 1 hora |
Recuperar um banco de dados dentro da mesma região do Azure
Você pode usar backups automáticos de banco de dados para restaurar um banco de dados para um ponto no tempo no passado. Desta forma, você pode se recuperar de corrupções de dados causadas por erros humanos. A restauração point-in-time (PITR) permite criar um novo banco de dados para a mesma instância, ou uma instância diferente, que representa o estado dos dados antes do evento corrompido. A operação de restauração é um tamanho de operação de dados que também depende da carga de trabalho atual da instância de destino. Pode levar mais tempo para recuperar um banco de dados muito grande ou muito ativo. Para obter mais informações sobre o tempo de recuperação, consulte Tempo de recuperação do banco de dados.
Se o período máximo de retenção de backup suportado para restauração point-in-time (PITR) não for suficiente para seu aplicativo, você poderá estendê-lo configurando uma política de retenção de longo prazo (LTR) para o(s) banco(s) de dados. Para obter mais informações, consulte Retenção de backup de longo prazo.
Recuperar um banco de dados para uma instância existente
Embora raro, um datacenter do Azure pode ter uma interrupção. Quando ocorre uma indisponibilidade, esta causa uma interrupção do negócio que poderá demorar apenas alguns minutos ou pode durar horas.
- Uma opção é esperar que sua instância fique online novamente quando a interrupção do datacenter terminar. Isso funciona para aplicativos que podem se dar ao luxo de ter seu banco de dados offline. Por exemplo, um projeto de desenvolvimento ou uma versão de avaliação gratuita nos quais não tem de trabalhar constantemente. Quando um datacenter tem uma interrupção, você não sabe quanto tempo a interrupção pode durar, então essa opção só funciona se você não precisar do banco de dados por algum tempo.
- Se você estiver usando armazenamento com redundância geográfica (GRS) ou com redundância de zona geográfica (GZRS), outra opção é restaurar um banco de dados para qualquer instância gerenciada do SQL em qualquer região do Azure usando backups de banco de dados com redundância geográfica (restauração geográfica). A restauração geográfica usa um backup com redundância geográfica como origem e pode ser usada para recuperar um banco de dados até o último point-in-time disponível, mesmo que o banco de dados ou datacenter esteja inacessível devido a uma interrupção. O backup disponível pode ser encontrado na região emparelhada.
- Finalmente, você pode se recuperar rapidamente de uma interrupção se tiver configurado um geosecundário usando um grupo de failover para sua instância, usando failover gerenciado pelo cliente (recomendado) ou gerenciado pela Microsoft. Enquanto o failover em si leva apenas alguns segundos, o serviço leva pelo menos 1 hora para ativar um failover geográfico gerenciado pela Microsoft, se configurado. Isso é necessário para garantir que o failover seja justificado pela escala da interrupção. Além disso, o failover pode resultar na perda de dados recentemente alterados devido à natureza da replicação assíncrona entre as regiões emparelhadas.
À medida que elabora o seu plano de continuidade empresarial, tem de saber qual o tempo máximo aceitável antes de a aplicação recuperar totalmente após o evento problemático. O tempo necessário para que o aplicativo se recupere totalmente é conhecido como Recovery Time Objetive (RTO). Você também precisa entender o período máximo de atualizações de dados recentes (intervalo de tempo) que o aplicativo pode tolerar perder ao se recuperar de um evento disruptivo não planejado. A perda potencial de dados é conhecida como RPO (Recovery Point Objetive, objetivo de ponto de recuperação).
Diferentes métodos de recuperação oferecem diferentes níveis de RPO e RTO. Você pode escolher um método de recuperação específico ou usar uma combinação de métodos para obter a recuperação completa do aplicativo.
Use grupos de failover se seu aplicativo atender a qualquer um destes critérios:
- É fundamental para a atividade crítica.
- Tem um contrato de nível de serviço (SLA) que não permite 12 horas ou mais de tempo de inatividade.
- O tempo de inatividade pode resultar em responsabilidade financeira.
- Tem uma alta taxa de alteração de dados e 1 hora de perda de dados não é aceitável.
- O custo adicional da georreplicação ativa é inferior aos potenciais encargos financeiros e perda empresarial associada.
Você pode optar por usar uma combinação de backups de banco de dados e grupos de failover, dependendo dos requisitos do aplicativo.
As seções a seguir fornecem uma visão geral das etapas de recuperação usando backups de banco de dados ou grupos de failover.
Preparar para uma indisponibilidade
Independentemente da funcionalidade de continuidade empresarial utilizada, tem de:
- Identifique e prepare a instância de destino, incluindo regras de firewall IP de rede, logins e
masterpermissões no nível do banco de dados. - Determinar como redirecionar clientes e aplicativos cliente para a nova instância
- Documentar outras dependências, tais como definições e alertas de auditoria
Se você não se preparar corretamente, colocar seus aplicativos on-line após um failover ou uma recuperação de banco de dados leva tempo adicional e, provavelmente, também requer solução de problemas em um momento de estresse - uma má combinação.
Failover para uma instância secundária replicada geograficamente
Se você estiver usando grupos de failover como mecanismo de recuperação, poderá configurar uma política de failover automática. Uma vez iniciado, o failover faz com que a instância secundária se torne a nova principal, pronta para registrar novas transações e responder a consultas - com perda mínima de dados para os dados ainda não replicados.
Nota
Quando o datacenter volta a ficar online, o primário antigo se reconecta automaticamente ao novo primário para se tornar a instância secundária. Se precisar realocar o primário de volta para a região original, você pode iniciar um failover planejado manualmente (failback).
Efetuar um georrestauro
Se você estiver usando backups automatizados com armazenamento com redundância geográfica (a opção de armazenamento padrão ao criar sua instância), poderá recuperar o banco de dados usando a restauração geográfica. A recuperação geralmente ocorre dentro de 12 horas - com perda de dados de até uma hora determinada por quando o último backup de log foi feito e replicado. Até concluir a recuperação, a base de dados não consegue registar quaisquer transações nem responder a consultas. Observe que a restauração geográfica apenas restaura o banco de dados para o último point-in-time disponível.
Nota
Se o datacenter voltar a ficar online antes de você alternar seu aplicativo para o banco de dados recuperado, você poderá cancelar a recuperação.
Efetuar a ativação pós-falha/tarefas de recuperação
Após a recuperação a partir de qualquer mecanismo de recuperação, tem de efetuar as seguintes tarefas adicionais antes de os seus utilizadores e aplicações ficarem funcionais:
- Redirecione os clientes e as aplicações cliente para a nova instância e a base de dados restaurada.
- Verifique se as regras apropriadas de firewall IP de rede estão em vigor para que os usuários se conectem.
- Verifique se os logins apropriados e
masteras permissões no nível do banco de dados estão em vigor (ou use usuários contidos). - Configure auditorias, conforme adequado.
- Configure alertas, conforme adequado.
Nota
Se você estiver usando um grupo de failover e se conectar à instância usando o ouvinte de leitura-gravação, o redirecionamento após o failover acontecerá automaticamente e de forma transparente para o aplicativo.
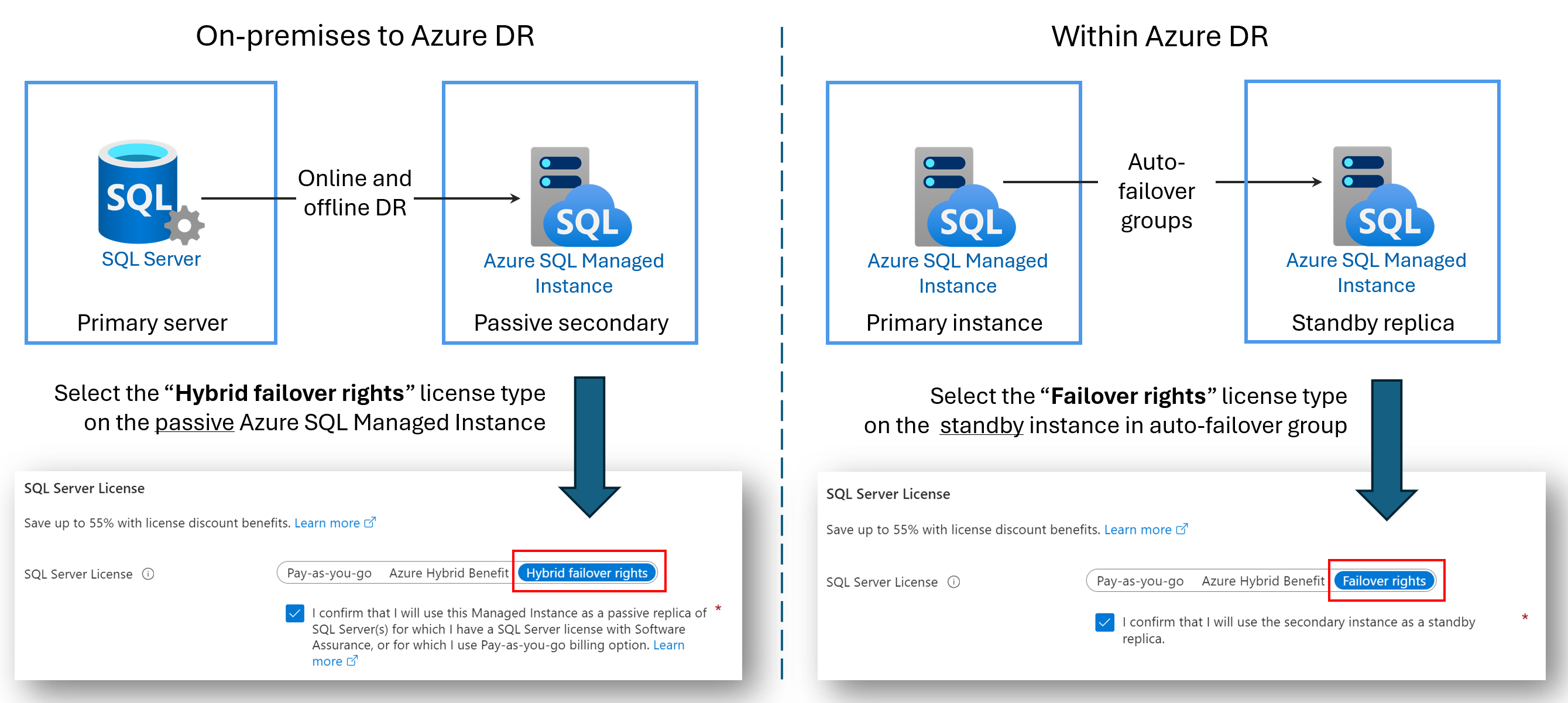
Réplicas DR sem licença
Você pode economizar nos custos de licenciamento configurando uma Instância Gerenciada SQL do Azure secundária apenas para recuperação de desastres (DR). Esse benefício estará disponível se você estiver usando um grupo de failover entre duas instâncias gerenciadas do SQL ou se tiver configurado um link híbrido entre o SQL Server e a Instância Gerenciada do SQL do Azure. Contanto que a instância secundária não tenha nenhuma carga de trabalho de leitura ou gravação e seja apenas uma espera passiva de DR, você não será cobrado pelos custos de licenciamento vCore usados pela instância secundária.
Quando você designa uma instância secundária apenas para recuperação de desastres e nenhuma carga de trabalho de leitura ou gravação está sendo executada na instância, a Microsoft fornece o número de vCores licenciados para a instância principal sem custo adicional sob o benefício de direitos de failover. Você ainda é cobrado pela computação e armazenamento que a instância secundária usa. Para obter termos e condições precisos do benefício de direitos de failover híbrido, consulte os termos de licenciamento do SQL Server online na seção "SQL Server – Direitos de failover".
O nome do benefício depende do seu cenário:
- Direitos de failover híbridos para uma réplica passiva: ao configurar um link entre o SQL Server e a Instância Gerenciada SQL do Azure, você pode usar o benefício Direitos de failover híbridos para economizar nos custos de licenciamento vCore para a réplica secundária passiva.
- Direitos de failover para uma réplica em espera: ao configurar um grupo de failover entre duas instâncias gerenciadas, você pode usar o benefício de direitos de failover para economizar nos custos de licenciamento vCore para a réplica secundária em espera.
O diagrama a seguir demonstra o benefício para cada cenário:
Próximos passos
Para saber mais sobre os recursos de continuidade de negócios, consulte Backups automatizados e grupos de failover. Em caso de desastre, consulte Recuperar um banco de dados.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários