Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Aplica-se a:![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Este artigo ensina como configurar um grupo de failover para a Instância Gerenciada SQL do Azure usando o portal do Azure e o Azure PowerShell.
Para obter um script PowerShell de ponta a ponta para criar ambas as instâncias em um grupo de failover, consulte Adicionar instância a um grupo de failover com o PowerShell.
Pré-requisitos
Para configurar um grupo de failover, você já deve ter permissões adequadas e uma instância gerenciada SQL que pretende usar como principal. Consulte Criar instância para começar.
Certifique-se de revisar as limitações antes de criar sua instância secundária e seu grupo de failover.
Requisitos de configuração
Para configurar um grupo de failover entre uma Instância Gerenciada SQL primária e secundária, considere os seguintes requisitos:
- A instância gerenciada secundária deve estar vazia, sem bancos de dados de usuários.
- A configuração da instância primária e secundária deve ser a mesma para garantir que a instância secundária possa processar de forma sustentável as alterações replicadas da instância primária, inclusive durante períodos de pico de atividade. Isso inclui o tamanho da computação, o tamanho do armazenamento e a camada de serviço.
- O intervalo de endereços IP da rede virtual da instância primária não deve se sobrepor ao intervalo de endereços da rede virtual da instância gerenciada secundária ou a qualquer outra rede virtual emparelhada com a rede virtual primária ou secundária.
- Ambas as instâncias devem estar na mesma zona DNS. Ao criar sua instância gerenciada secundária, você deve especificar o ID da zona DNS da instância primária. Se não o fizeres, o ID da zona é gerado como uma cadeia de caracteres aleatória quando a primeira instância é criada em cada rede virtual e o mesmo ID é atribuído a todas as outras instâncias na mesma sub-rede. Depois de atribuída, a zona DNS não pode ser modificada.
- As regras NSG (Network Security Groups) para as sub-redes de ambas as instâncias devem ter conexões TCP de entrada e saída abertas para a porta 5022 e o intervalo de portas 11000-11999 para facilitar a comunicação entre as duas instâncias.
- As instâncias gerenciadas devem ser implantadas em regiões emparelhadas por motivos de desempenho. As instâncias gerenciadas que residem em regiões emparelhadas geograficamente se beneficiam de uma velocidade de replicação geográfica significativamente maior em comparação com regiões não emparelhadas.
- Ambas as instâncias devem usar a mesma política de atualização.
Criar a instância secundária
Ao criar a instância secundária, você deve usar uma rede virtual que tenha um espaço de endereço IP que não se sobreponha ao intervalo de espaço de endereço IP da instância primária. Além disso, ao configurar a nova instância secundária, você deve especificar o ID da zona da instância primária.
Você pode configurar a rede virtual secundária e criar a instância secundária usando o portal do Azure e o PowerShell.
Criar a rede virtual
Para criar uma rede virtual para sua instância secundária no portal do Azure, siga estas etapas:
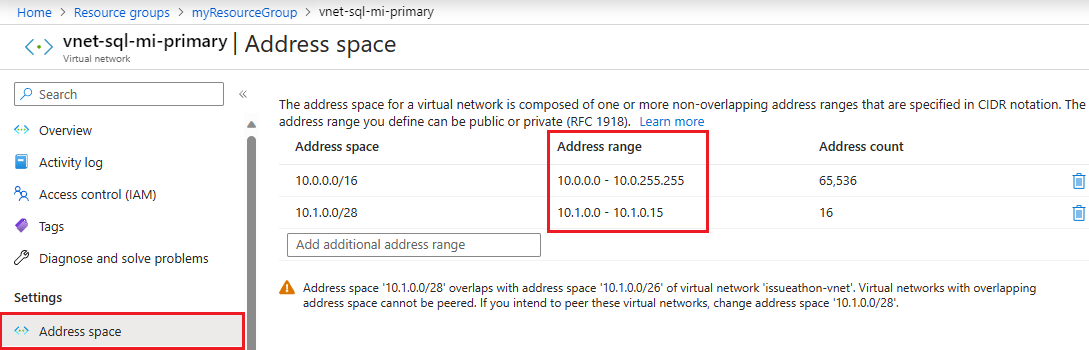
Verifique o espaço de endereço da instância principal. Vá para o recurso de rede virtual para a instância primária no portal do Azure e, em Configurações, selecione Espaço de endereço. Verifique o intervalo em Intervalo de endereços:
Crie uma nova rede virtual que você planeja usar para a instância secundária indo para a página Criar rede virtual .
Na guia Noções básicas da página Criar rede virtual :
- Selecione o Grupo de Recursos que você pretende usar para a instância secundária. Crie um novo se ele ainda não existir.
- Forneça um nome para sua rede virtual, como
vnet-sql-mi-secondary. - Selecione uma região emparelhada com a região onde está a instância principal.
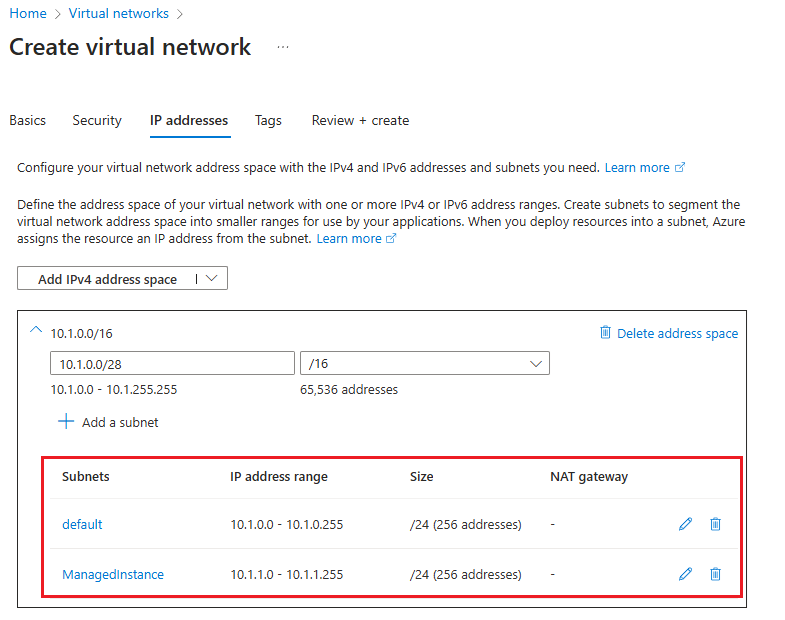
Na guia Endereços IP da página Criar rede virtual :
- Utilize Eliminar espaço de endereços para eliminar o espaço de endereços IPv4 existente.
- Depois que o espaço de endereço for excluído, selecione Adicionar espaço de endereço IPv4 para adicionar um novo espaço e forneça um espaço de endereço IP diferente do espaço de endereço usado pela rede virtual da instância primária. Por exemplo, se sua instância primária atual usa um espaço de endereço de 10.0.0.16, insira
10.1.0.0/16o espaço de endereço da rede virtual que você pretende usar para a instância secundária. - Use + Adicionar uma sub-rede para adicionar uma sub-rede padrão com valores padrão.
- Use + Adicionar uma sub-rede para adicionar uma sub-rede vazia nomeada
ManagedInstanceque será dedicada à instância secundária, usando um intervalo de endereços diferente da sub-rede padrão. Por exemplo, se a sua instância primária usa um intervalo de endereços de 10.0.0.0 - 10.0.255.255, forneça um intervalo de sub-rede para a sub-rede da instância secundária10.1.1.0 - 10.1.1.255.
Utilize Rever + Criar para rever as suas definições e, em seguida, utilize Criar para criar a sua nova rede virtual.

Criar instância secundária
Depois que sua rede virtual estiver pronta, siga estas etapas para criar sua instância secundária no portal do Azure:
Vá para Criar Instância Gerenciada SQL do Azure no portal do Azure.
Na guia Noções básicas da página Criar Instância Gerenciada SQL do Azure :
- Escolha uma região para sua instância secundária que seja emparelhada com a instância primária.
- Escolha uma camada de serviço que corresponda à camada de serviço da instância primária.
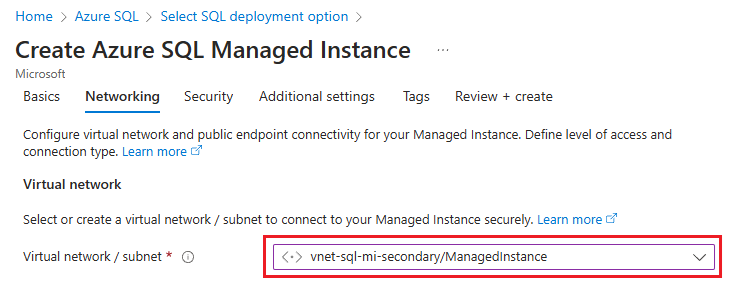
Na guia Rede da página Criar Instância Gerenciada SQL do Azure , use a lista suspensa em Rede virtual / sub-rede para selecionar a rede virtual e a sub-rede que você criou anteriormente:
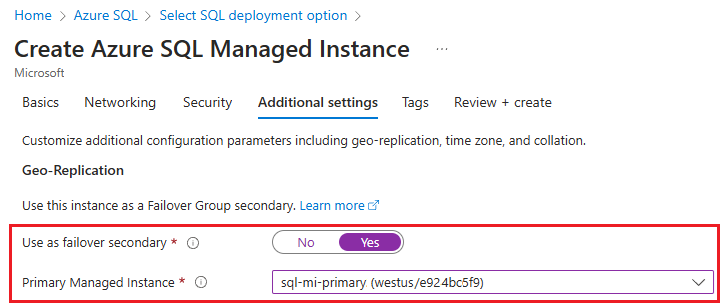
Na guia Configurações adicionais da página Criar Instância Gerida do SQL do Azure, selecione Sim para Usar como Failover Secundário e escolha a instância primária apropriada na lista suspensa.
Configure o restante da instância de acordo com suas necessidades de negócios e, em seguida, crie-a usando Review + Create.

Estabeleça conectividade entre as instâncias
Para um fluxo de tráfego de replicação geográfica ininterrupto, você deve estabelecer conectividade entre as sub-redes de rede virtual que hospedam as instâncias primária e secundária. Há várias maneiras de conectar instâncias gerenciadas em diferentes regiões do Azure, incluindo:
- Interconexão de rede virtual global
- Azure ExpressRoute
- Gateways de VPN
O emparelhamento de rede virtual global é recomendado como a maneira mais eficiente e robusta de estabelecer conectividade entre instâncias em um grupo de failover. O emparelhamento de rede virtual global fornece uma conexão privada de baixa latência e alta largura de banda entre redes virtuais emparelhadas usando a infraestrutura de backbone da Microsoft. Não é necessária Internet pública, gateways ou encriptação adicional na comunicação entre as redes virtuais em modo de peering.
Importante
Formas alternativas de conectar instâncias que envolvem dispositivos de rede adicionais podem complicar a solução de problemas de conectividade ou velocidade de replicação, possivelmente exigindo o envolvimento ativo de administradores de rede e potencialmente prolongando significativamente o tempo de resolução.
Se você usar um mecanismo para estabelecer conectividade entre as instâncias diferentes do emparelhamento de rede virtual global recomendado, verifique o seguinte:
- Os dispositivos de rede, como firewalls ou dispositivos virtuais de rede (NVAs), não bloqueiam o tráfego em conexões de entrada e saída para a porta 5022 (TCP) e o intervalo de portas 11000-11999.
- O encaminhamento está corretamente configurado e se o encaminhamento assimétrico é evitado.
- Se você implantar grupos de failover em uma topologia de rede hub-and-spoke entre regiões, para evitar problemas de conectividade e velocidade de replicação, o tráfego de replicação deverá ir diretamente entre as duas sub-redes de instância gerenciada em vez de ser direcionado pelas redes de hub.
Este artigo orienta você a configurar o emparelhamento de rede virtual global entre as redes das duas instâncias usando o portal do Azure e o PowerShell.
No portal do Azure, vá para o recurso de rede virtual para sua instância gerenciada principal.
Selecione Emparelhamento em Configurações para abrir a página Emparelhamento e, em seguida, use + Adicionar na barra de comandos para abrir a página Adicionar emparelhamento .
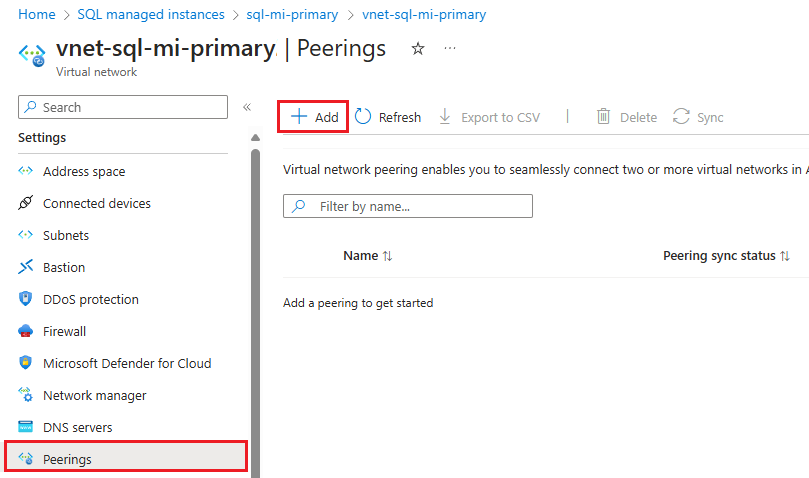
Na página Adicionar emparelhamento, insira ou selecione valores para as seguintes definições.
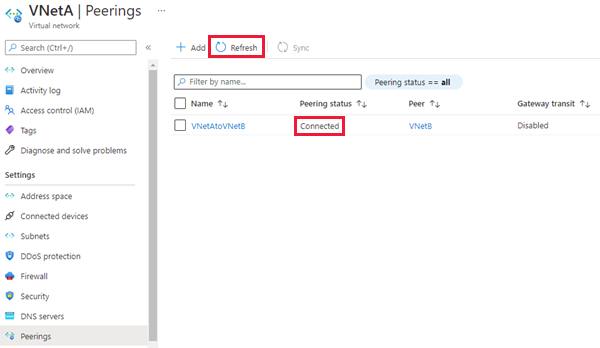
Configurações Descrição Resumo da rede virtual remota Nome do link de peering O nome para o emparelhamento deve ser exclusivo dentro da rede virtual. Este artigo usa Fog-peering.Modelo de implantação de rede virtual Selecione Gerenciador de recursos. Sei o meu ID de recurso Você pode deixar essa caixa desmarcada, a menos que saiba o ID do recurso. Subscrição Selecione a assinatura na lista suspensa. Rede virtual Selecione a rede virtual da instância secundária na lista pendente. Configurações de interconexão de rede virtual remota Permitir que a 'rede virtual secundária' acesse a 'rede virtual primária' Marque a caixa para permitir a comunicação entre as duas redes. A habilitação da comunicação entre redes virtuais permite que os recursos conectados a qualquer rede virtual se comuniquem entre si com a mesma largura de banda e latência como se estivessem conectados à mesma rede virtual. Toda a comunicação entre recursos nas duas redes virtuais é feita através da rede privada do Azure. Permitir que a 'rede virtual secundária' receba tráfego encaminhado da 'rede virtual primária' Você pode marcar ou desmarcar esta caixa, em ambos os casos tanto faz para este guia. Para obter mais informações, consulte Como criar emparelhamento. Permitir que o gateway ou o servidor de rota em 'rede virtual secundária' encaminhe o tráfego para a 'rede virtual primária' Você pode marcar ou desmarcar esta caixa, em ambos os casos tanto faz para este guia. Para obter mais informações, consulte Como criar emparelhamento. Habilite a 'rede virtual secundária' para usar o gateway remoto da 'rede virtual primária ou o servidor de rotas Deixe esta caixa desmarcada. Para obter mais informações sobre as outras opções disponíveis, consulte Estabelecer uma ligação. Resumo da rede virtual local Nome do link de peering O nome da mesma interligação utilizado para a rede virtual remota. Este artigo usa Fog-peering.Permitir que a 'rede virtual primária' acesse a 'rede virtual secundária' Marque a caixa para permitir a comunicação entre as duas redes. A habilitação da comunicação entre redes virtuais permite que os recursos conectados a qualquer rede virtual se comuniquem entre si com a mesma largura de banda e latência como se estivessem conectados à mesma rede virtual. Toda a comunicação entre recursos nas duas redes virtuais é feita através da rede privada do Azure. Permitir que a 'rede virtual primária' receba tráfego encaminhado da 'rede virtual secundária' Você pode marcar ou desmarcar esta caixa, em ambos os casos tanto faz para este guia. Para obter mais informações, consulte Como criar emparelhamento. Permitir que o gateway ou o servidor de rotas em 'rede virtual primária' encaminhe o tráfego para 'rede virtual secundária' Você pode marcar ou desmarcar esta caixa, em ambos os casos tanto faz para este guia. Para obter mais informações, consulte Como criar emparelhamento. Ativar a 'rede virtual primária' para utilizar o 'gateway remoto' ou o 'servidor de rotas' da rede virtual secundária. Deixe esta caixa desmarcada. Para obter mais informações sobre as outras opções disponíveis, consulte Estabelecer uma ligação. Use Adicionar para configurar o emparelhamento com a rede virtual selecionada e navegue automaticamente de volta para a página Emparelhamento , que mostra que as duas redes estão conectadas:
Configurar portas e regras do NSG
Independentemente do mecanismo de conectividade escolhido entre as duas instâncias, suas redes devem atender aos seguintes requisitos para o fluxo de tráfego de replicação geográfica:
- A tabela de rotas e os grupos de segurança de rede atribuídos às sub-redes da instância gerenciada não são compartilhados entre as duas redes virtuais emparelhadas.
- As regras do NSG (Network Security Group) em ambas as sub-redes que hospedam cada instância permitem o tráfego de entrada e de saída para a outra instância na porta 5022 e o intervalo de portas 11000-11999.
Você pode configurar sua comunicação de porta e regras NSG usando o portal do Azure e o PowerShell.
Para abrir portas NSG (Grupo de Segurança de Rede) no portal do Azure, siga estas etapas:
Acesse o recurso Grupo de Segurança de Rede para a instância primária.
Em Configurações, selecione Regras de segurança de entrada. Verifique se você já tem regras que permitem o tráfego para a porta 5022 e o intervalo 11000-11999. Se você fizer isso, e a fonte atender às suas necessidades de negócios, ignore esta etapa. Se as regras não existirem ou se você quiser usar uma fonte diferente (como o endereço IP mais seguro), exclua a regra existente e selecione + Adicionar na barra de comandos para abrir o painel Adicionar regra de segurança de entrada :
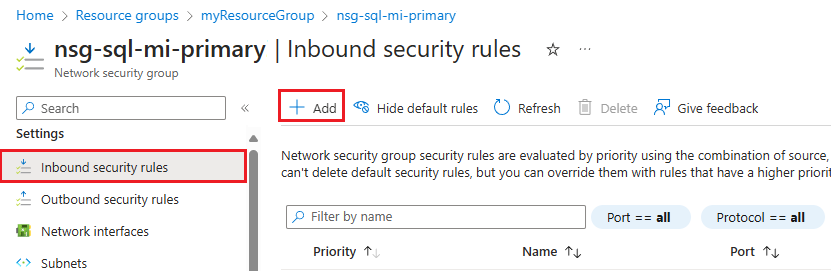
No painel Adicionar regras de segurança de entrada , insira ou selecione valores para as seguintes configurações:
Configurações Valor recomendado Descrição Fonte Endereços IP ou etiqueta de serviço O filtro para a fonte da comunicação. O endereço IP é o mais seguro e recomendado para ambientes de produção. A etiqueta de serviço é apropriada para ambientes que não são de produção. Etiqueta de serviço de origem Se você selecionou Etiqueta de serviço como a fonte, forneça VirtualNetworkcomo a marca de origem.As tags padrão são identificadores predefinidos que representam uma categoria de endereços IP. A tag VirtualNetwork indica todos os espaços de endereço de rede virtual e local. Endereços IP de origem Se você selecionou endereços IP como a origem, forneça o endereço IP da instância secundária. Forneça um intervalo de endereços usando a notação CIDR (por exemplo, 192.168.99.0/24 ou 2001:1234::/64) ou um endereço IP (por exemplo, 192.168.99.0 ou 2001:1234::). Você também pode fornecer uma lista separada por vírgulas de endereços IP ou intervalos de endereços usando IPv4 ou IPv6. Intervalos de portas de origem 5022 Isso especifica em quais portas essa regra permitirá o tráfego. Serviço Personalizado O serviço especifica o protocolo de destino e o intervalo de portas para esta regra. Intervalos de portas de destino 5022 Isso especifica em quais portas essa regra permitirá o tráfego. Essa porta deve corresponder ao intervalo de portas de origem. Ação Permitir Permitir a comunicação na porta especificada. Protocolo TCP Determina o protocolo para comunicação de portas. Prioridade 1200 As regras são processadas em ordem de prioridade; quanto menor o número, maior a prioridade. Nome permitir_geodr_inbound O nome da regra. Descrição Opcional Pode optar por fornecer uma descrição ou deixar este campo em branco. Selecione Adicionar para salvar suas configurações e adicionar sua nova regra.
Repita estas etapas para adicionar outra regra de segurança de entrada para o intervalo de
11000-11999portas com um nome como allow_redirect_inbound e uma prioridade um pouco maior do que a regra 5022, como1100.Em Configurações, selecione Regras de segurança de saída. Verifique se você já tem regras que permitem o tráfego para a porta 5022 e o intervalo 11000-11999. Se você fizer isso, e a fonte atender às suas necessidades de negócios, ignore esta etapa. Se as regras não existirem ou se você quiser usar uma fonte diferente (como o endereço IP mais seguro), exclua a regra existente e selecione + Adicionar na barra de comandos para abrir o painel Adicionar regra de segurança de saída .
No painel Adicionar regra de segurança de saída , use a mesma configuração para a porta 5022 e o intervalo
11000-11999que fez para as portas de entrada.Vá para o grupo de segurança de rede para a instância secundária e repita estas etapas para que ambos os grupos de segurança de rede tenham as seguintes regras:
- Permitir tráfego de entrada na porta 5022
- Permitir tráfego de entrada no intervalo de portas
11000-11999 - Permitir tráfego de saída na porta 5022
- Permitir tráfego de saída no intervalo de portas
11000-11999
Criar o grupo de failover
Crie o grupo de failover para suas instâncias gerenciadas usando o portal do Azure ou o PowerShell.
Crie o grupo de failover para suas Instâncias Gerenciadas SQL usando o portal do Azure.
Selecione Azure SQL no menu esquerdo do portal do Azure. Se o Azure SQL não estiver na lista, selecione Todos os serviços e digite Azure SQL na caixa de pesquisa. (Opcional) Selecione a estrela ao lado do SQL do Azure para adicioná-la como um item favorito à navegação à esquerda.
Selecione a instância gerenciada primária que você deseja adicionar ao grupo de failover.
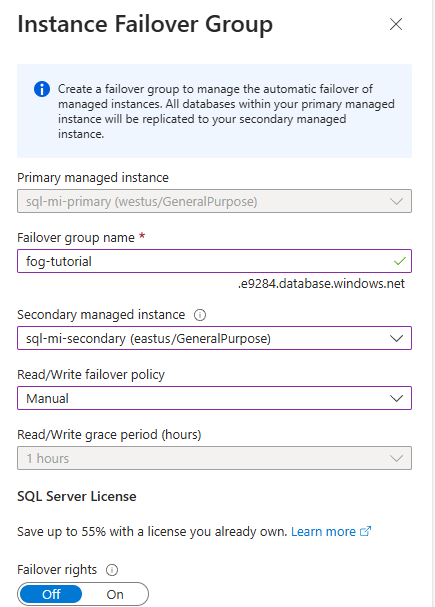
Em Gestão de Dados, selecione Grupos de Failover e use Adicionar Grupo para abrir a página Grupo de Failover de Instância:
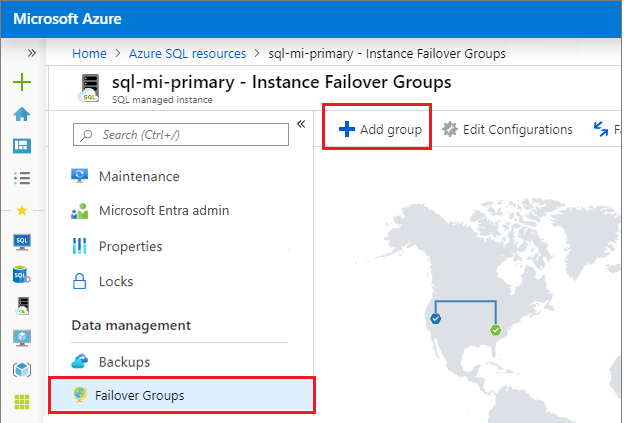
Na página Grupo de Tolerância a Falhas de Instância:
- A instância gerenciada primária está pré-selecionada.
- Em Nome do grupo de failover, insira um nome para o grupo de failover.
- Em Instância gerenciada secundária, selecione a instância gerenciada que você deseja usar como secundária no grupo de failover.
- Escolha uma política de comutação por falha de leitura/gravação no menu suspenso. Manual é recomendado para lhe dar controle sobre o failover.
- Deixe Habilitar direitos de failover para Desativado, a menos que você pretenda usar essa réplica apenas para recuperação de desastres.
- Use Criar para salvar suas configurações e criar seu grupo de failover.
Depois que a implantação do grupo de failover for iniciada, você será levado de volta para a página Grupos de failover . A página é atualizada para mostrar o novo grupo de failover após a conclusão da implantação.
Ativação pós-falha de teste
Teste a tolerância a falhas do seu grupo de tolerância a falhas usando o Portal do Azure ou o PowerShell.
Teste o failover do seu grupo de recuperação utilizando o portal do Azure.
Vá para a instância gerenciada primária ou secundária no portal do Azure.
Em Gestão de dados, selecione Grupos de ativação pós-falha.
No painel Grupos de failover , observe qual instância é a instância primária e qual instância é a instância secundária.
No painel Grupos de alternância, selecione Alternar na barra de comandos. Selecione Sim no aviso sobre sessões TDS sendo desconectadas e observe a implicação de licenciamento.
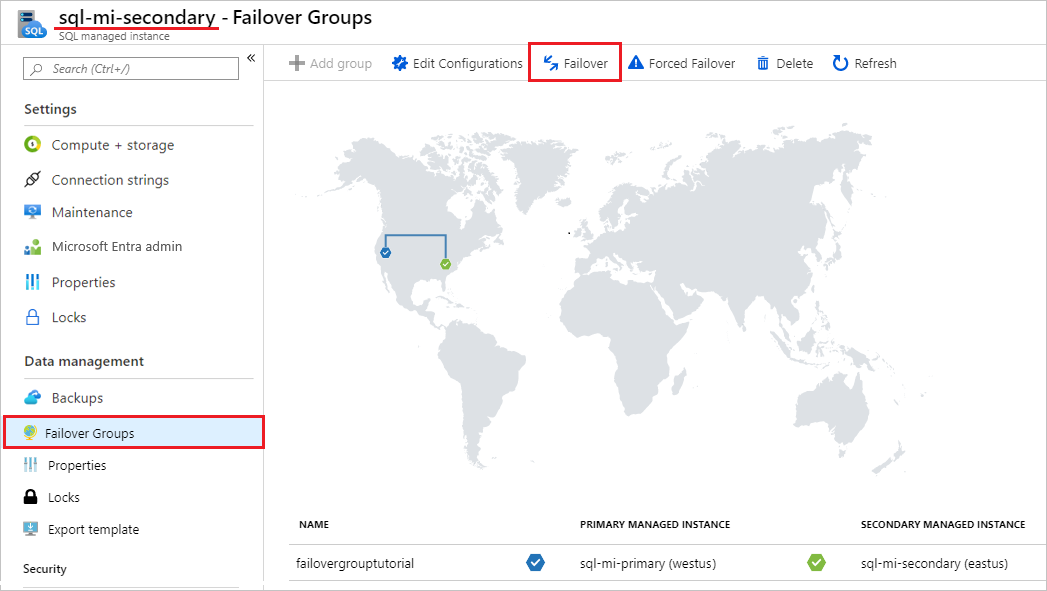
No painel Grupos de failover , após o failover ser bem-sucedido, as instâncias alternam de função para que o secundário anterior se torne o novo primário e o primário anterior se torne o novo secundário.
Importante
Se as funções não mudarem, verifique a conectividade entre as instâncias e as regras relacionadas de NSG e firewall. Prossiga com a próxima etapa somente depois que as funções mudarem.
(Opcional) No painel Grupos de failover, use Failover para retornar as funções para que o primário original volte a ser o primário.

Rastrear failover no registro de atividades
Você pode usar o log de atividades no portal do Azure para acompanhar o status da operação de failover. Para o fazer, siga estes passos:
Vá para a sua instância gerenciada do SQL
no portal do Azure. Selecione Registro de atividades para abrir o painel Registro de atividades .
Limpe todos os filtros para Recurso.
Procurar operações com o nome
Failover Azure SQL Database failover group: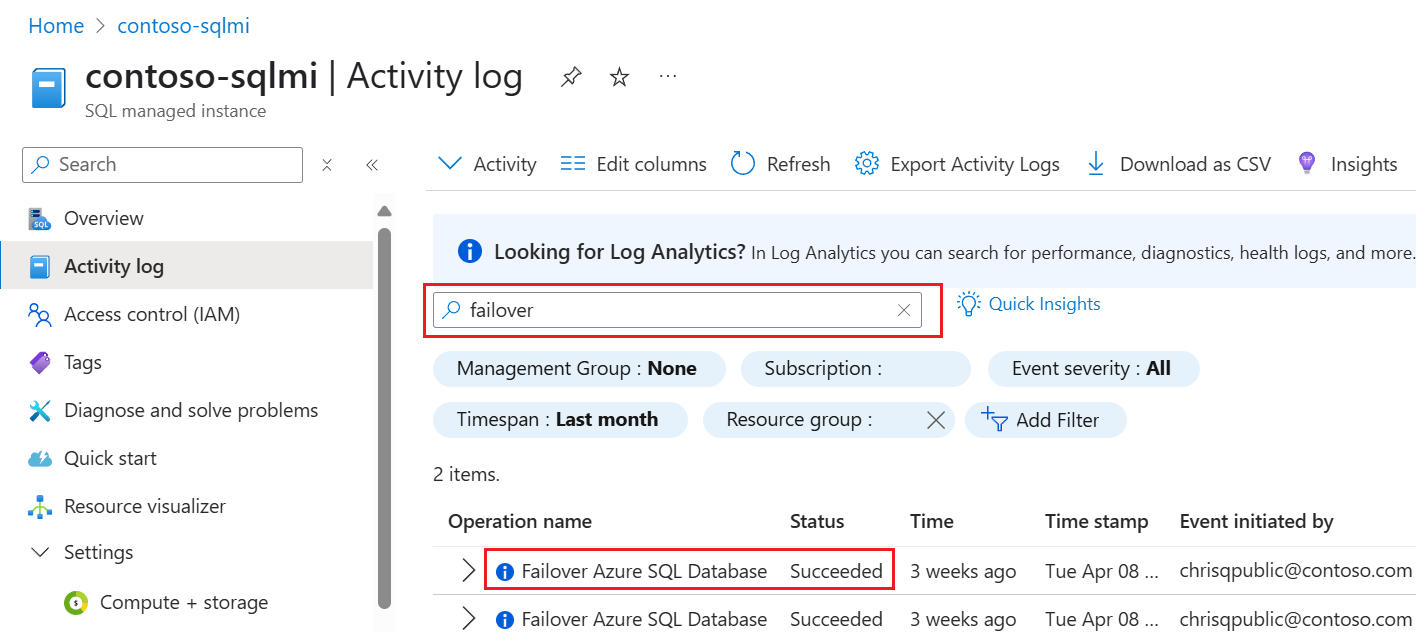

Modificar grupo de failover existente
Você pode modificar um grupo de failover existente, como para alterar a política de failover, usando o portal do Azure, PowerShell, CLI do Azure e as APIs REST.
Para modificar um grupo de failover existente usando o portal do Azure, siga estas etapas:
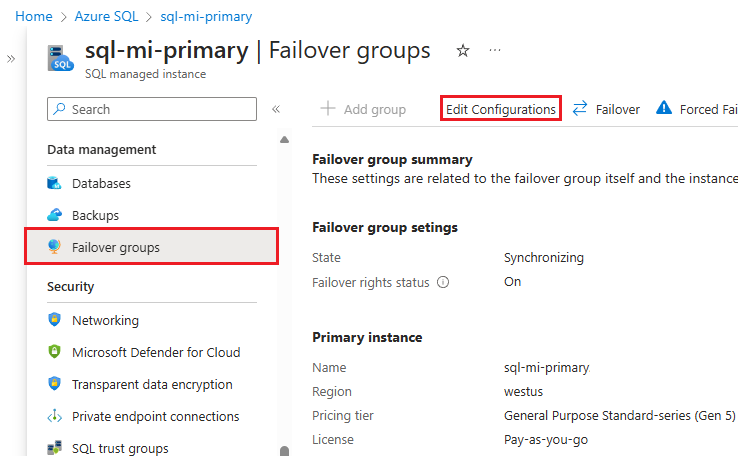
Vá para a sua instância gerenciada do SQL
no portal do Azure. Em Gerenciamento de dados, selecione Grupos de failover para abrir o painel Grupos de failover .
No painel Grupos de failover , selecione Editar configurações na barra de comandos para abrir o painel Editar grupo de failover :
Localizar ponto de extremidade do ouvinte
Depois que o grupo de failover estiver configurado, atualize a cadeia de conexão do seu aplicativo para apontar para o ponto de extremidade do ouvinte de leitura/gravação para que seu aplicativo continue a se conectar à instância principal após o failover. Usando o ponto de extremidade do ouvinte, você não precisa atualizar manualmente sua cadeia de conexão toda vez que o grupo de failover fizer failover, pois o tráfego sempre é roteado para o primário atual. Você também pode apontar a carga de trabalho somente leitura para o ponto de extremidade do ouvinte somente leitura .
Importante
Embora a conexão a uma instância em um grupo de failover usando a cadeia de conexão específica da instância seja suportada, é fortemente desencorajada. Em vez disso, use os pontos de extremidade do ouvinte.
Para localizar o ponto de extremidade do ouvinte no portal do Azure, vá para sua instância gerenciada SQL e, em Gerenciamento de dados, selecione Grupos de failover.
Role para baixo para encontrar os pontos de extremidade do ouvinte:
- O ponto final do ouvinte de leitura/gravação, na forma de
fog-name.dns-zone.database.windows.net, encaminha o tráfego para a instância primária. - O ponto de escuta em modo somente leitura, na forma de
fog-name.secondary.dns-zone.database.windows.net, encaminha o tráfego para a instância secundária.

Criar grupo de failover entre entidades em diferentes assinaturas
Você pode criar um grupo de failover entre Instâncias Gerenciadas do SQL em duas assinaturas diferentes, desde que as assinaturas estejam associadas ao mesmo locatário do Microsoft Entra.
- Ao usar a API do PowerShell, você pode fazer isso especificando o
PartnerSubscriptionIdparâmetro para a Instância Gerenciada SQL secundária. - Ao usar a API REST, cada ID de instância incluído no parâmetro
properties.managedInstancePairspode ter a sua própria ID de Subscrição. - O portal do Azure não oferece suporte à criação de grupos de failover em assinaturas diferentes.
Importante
A criação de um grupo de failover entre duas instâncias em diferentes grupos de recursos ou assinaturas só é suportada com o Azure PowerShell ou a API REST, e não com o portal do Azure ou a CLI do Azure.
Evitar a perda de dados críticos
Devido à alta latência das redes de longa distância, a replicação geográfica usa um mecanismo de replicação assíncrona. A replicação assíncrona torna inevitável a possibilidade de perda de dados se o primário falhar. Para proteger transações críticas contra perda de dados, um desenvolvedor de aplicativos pode chamar o procedimento armazenado sp_wait_for_database_copy_sync imediatamente após confirmar a transação. Chamar sp_wait_for_database_copy_sync bloqueia o encadeamento de chamada até que a última transação confirmada tenha sido transmitida e consolidada no log de transações do banco de dados secundário. No entanto, não espera pelas transações transmitidas serem reexecutadas no secundário.
sp_wait_for_database_copy_sync tem como escopo um link de replicação geográfica específico. Qualquer usuário com direitos de conexão com o banco de dados primário pode chamar este procedimento.
Para evitar a perda de dados durante o failover geográfico planeado iniciado pelo utilizador, a replicação muda automaticamente e temporariamente para replicação síncrona e, em seguida, executa um failover. Em seguida, a replicação retorna ao modo assíncrono após a finalização do failover geográfico.
Observação
sp_wait_for_database_copy_sync evita a perda de dados após o geo-failover para transações específicas, mas não garante a sincronização completa para a leitura. O atraso causado por uma chamada de procedimento sp_wait_for_database_copy_sync pode ser significativo e depende do tamanho do log de transações que ainda não foi transmitido no sistema primário no momento da chamada.
Alterar a região secundária
Vamos supor que a instância A é a instância primária, a instância B é a instância secundária existente e a instância C é a nova instância secundária na terceira região. Para fazer a transição, siga estas etapas:
- Crie a instância C com o mesmo tamanho que A e na mesma zona DNS.
- Elimine o grupo de alternância entre as instâncias A e B. Neste momento, as tentativas de iniciar sessão começam a falhar porque os aliases SQL para os escutadores do grupo de alternância foram eliminados e o gateway não reconhecerá o nome do grupo de alternância. Os bancos de dados secundários são desconectados dos primários e se tornam bancos de dados de leitura-gravação.
- Crie um grupo de failover com o mesmo nome entre as instâncias A e C. Siga as instruções no guia de configuração do grupo de failover. Esta é uma operação baseada no tamanho dos dados e é concluída quando todos os bancos de dados da instância A são inicializados e sincronizados.
- Exclua a instância B se não for necessário para evitar cobranças desnecessárias.
Observação
Após a etapa 2 e até que a etapa 3 seja concluída, os bancos de dados da instância A permanecerão desprotegidos contra uma falha catastrófica da instância A.
Alterar a região primária
Vamos supor que a instância A é a instância primária, a instância B é a instância secundária existente e a instância C é a nova instância primária na terceira região. Para fazer a transição, siga estas etapas:
- Crie a instância C com o mesmo tamanho que B e na mesma zona DNS.
- Inicie um failover manual a partir da instância B para torná-la a nova principal. A instância A torna-se a nova instância secundária automaticamente.
- Exclua o grupo de recuperação entre as instâncias A e B. A partir deste momento, as tentativas de entrada usando os pontos de extremidade do grupo de recuperação começam a falhar. Os bancos de dados secundários em A são desconectados dos primários e se tornam bancos de dados de leitura-gravação.
- Crie um grupo de failover com o mesmo nome entre as instâncias B e C. Esta é uma operação de tamanho de dados e é concluída quando todos os bancos de dados da instância B são propagados e sincronizados com a instância C. Neste ponto, as tentativas de login param de falhar.
- Faça failover manualmente para alternar a instância C para a função principal. A instância B torna-se a nova instância secundária automaticamente.
- Exclua a instância A se não for necessário para evitar cobranças desnecessárias.
Atenção
Após a etapa 3 e até que a etapa 4 seja concluída, os bancos de dados da instância A permanecerão desprotegidos contra uma falha catastrófica da instância A.
Importante
Quando o grupo de failover é eliminado, os registos DNS dos pontos de extremidade do listener também são eliminados. Nesse ponto, há uma probabilidade não nula de outra pessoa criar um grupo de "failover" com o mesmo nome. Como os nomes de grupo de failover devem ser globalmente exclusivos, isso impedirá que você use o mesmo nome novamente. Para minimizar este risco, não use nomes genéricos para grupos de failover.
Alterar a política de atualização
As instâncias em um grupo de failover devem ter políticas de atualização correspondentes. Para alterar a política de atualização para uma versão superior em instâncias que fazem parte de um grupo de failover, primeiro habilite a política de atualização na instância secundária, aguarde até que a alteração entre em vigor e, em seguida, atualize a política para a instância primária.
Embora a alteração da política de atualização na instância primária no grupo de failover faça com que a instância faça failover para outro nó local (semelhante às operações de gerenciamento em instâncias que não fazem parte de um grupo de failover), isso não faz com que o grupo de failover faça failover, mantendo a instância primária na função principal.
Atenção
Depois que a política atualizada for alterada para a versão superior do SQL Server, incluindo Always-up-to-date, alterá-la novamente para a política de atualização de versão inferior não será mais possível.
Habilitar cenários dependentes de objetos dos bancos de dados do sistema
As bases de dados do sistema não são replicadas para a instância secundária num grupo de tolerância a falhas. Para habilitar cenários que dependem de objetos dos bancos de dados do sistema, certifique-se de criar os mesmos objetos na instância secundária e mantê-los sincronizados com a instância primária.
Por exemplo, se você planeja usar os mesmos logons na instância secundária, certifique-se de criá-los com o SID idêntico.
-- Code to create login on the secondary instance
CREATE LOGIN foo WITH PASSWORD = '<enterStrongPasswordHere>', SID = <login_sid>;
Para saber mais, consulte Replicação de logins e tarefas de agente.
Sincronizar propriedades de instância e instâncias de políticas de retenção
As instâncias em um grupo de failover permanecem recursos separados do Azure e nenhuma alteração feita na configuração da instância primária será replicada automaticamente para a instância secundária. Certifique-se de executar todas as alterações relevantes no primário e na instância secundária. Por exemplo, se você alterar a redundância de armazenamento de backup ou a política de retenção de backup de longo prazo na instância principal, certifique-se de alterá-la também na instância secundária.
Dimensionamento de instâncias
A configuração da instância primária e secundária deve ser a mesma. Isso inclui o tamanho da computação, o tamanho do armazenamento e a camada de serviço. Se você precisar alterar a configuração do seu grupo de failover, poderá fazê-lo dimensionando cada instância para a mesma configuração de acordo.
Para evitar problemas de uma camada de serviço mais baixa ou geossecundária com poucos recursos ficando sobrecarregada, ou tendo que replantar durante um processo de upgrade ou downgrade, considere o seguinte:
- Você pode dimensionar a instância primária e secundária para cima ou para baixo para um tamanho de computação diferente dentro da mesma camada de serviço ou para uma camada de serviço diferente.
- Ao aumentar a escala dentro da mesma camada de serviço, expanda primeiro o geosecundário e, em seguida, expanda o primário.
- Ao reduzir a escala dentro da mesma camada de serviço, inverta a ordem: reduza o primário primeiro e, em seguida, diminua o secundário.
- Segue a mesma sequência quando mudares a configuração da tua instância. **
Se estiver a aumentar os recursos, faça isso primeiro no secundário. Se estiveres a reduzir a escala, faz isso primeiro na primária. Isto aplica-se às seguintes alterações de configuração da instância:
- Atualizar ou fazer downgrade do nível de serviço.
- Alterar o número de vCores.
- Dimensionamento do tamanho do armazenamento.
- Alterar a alocação de memória da sua instância de próxima geração de uso geral.
Permissões
As permissões para um grupo de failover são gerenciadas por meio do controle de acesso baseado em função do Azure (Azure RBAC).
A função de Colaborador da Instância Gerenciada SQL , com escopo para os grupos de recursos da instância gerenciada primária e secundária, é suficiente para executar todas as operações de gerenciamento em grupos de failover.
A tabela a seguir fornece uma visão granular das permissões mínimas necessárias e seus respetivos níveis mínimos de escopo necessários para operações de gerenciamento em grupos de failover:
| Operação de gestão | Permissão | Âmbito de aplicação |
|---|---|---|
| Criar/atualizar grupo de failover | Microsoft.Sql/locations/instanceFailoverGroups/write |
Grupos de recursos de instância gerenciada primária e secundária |
| Criar/atualizar grupo de failover | Microsoft.Sql/managedInstances/write |
Instância gerenciada primária e secundária |
| Grupo de failover de failover | Microsoft.Sql/locations/instanceFailoverGroups/failover/action |
Grupos de recursos de instância gerenciada primária e secundária |
| Forçar grupo de failover | Microsoft.Sql/locations/instanceFailoverGroups/forceFailoverAllowDataLoss/action |
Grupos de recursos de instância gerenciada primária e secundária |
| Excluir grupo de failover | Microsoft.Sql/locations/instanceFailoverGroups/delete |
Grupos de recursos de instância gerenciada primária e secundária |
Limitações
Ao criar um novo grupo de failover, considere as seguintes limitações:
- Os grupos de failover não podem ser criados entre duas instâncias na mesma região do Azure.
- Uma instância pode participar apenas de um grupo de failover a qualquer momento.
- Um grupo de failover não pode ser criado entre duas instâncias que pertencem a locatários diferentes do Azure.
- A criação de um grupo de failover entre duas instâncias em diferentes grupos de recursos ou assinaturas só é suportada com o Azure PowerShell ou a API REST, e não com o portal do Azure ou a CLI do Azure. Depois que o grupo de failover é criado, ele fica visível no portal do Azure e todas as operações são suportadas no portal do Azure ou com a CLI do Azure.
- Se a propagação inicial de todos os bancos de dados não for concluída em 7 dias, a criação do grupo de failover falhará e todos os bancos de dados replicados com êxito serão excluídos da instância secundária.
- No momento, não há suporte para a criação de um grupo de failover com uma instância configurada com um link de Instância Gerenciada .
- Os grupos de failover não podem ser criados entre instâncias se qualquer uma delas estiver num pool de instâncias.
- Os bancos de dados migrados para a Instância Gerida SQL do Azure usando o Log Replay Service (LRS) não podem ser adicionados a um grupo de failover até que a etapa de transferência seja executada.
Ao usar grupos de failover, considere as seguintes limitações:
- Não é possível mudar o nome dos grupos de ativação pós-falha. Terá de eliminar os grupos e voltar a criá-los com outro nome.
- Um grupo de failover contém exatamente duas instâncias gerenciadas. Não há suporte para a adição de instâncias adicionais ao grupo de failover.
- Os backups completos são feitos automaticamente:
- antes da primeira semeadura e pode atrasar visivelmente o início deste processo.
- após o failover, e pode atrasar ou impedir um failover subsequente.
- Não há suporte para a renomeação de banco de dados para bancos de dados no grupo de failover. Você precisará excluir temporariamente o grupo de failover para poder renomear um banco de dados.
- As bases de dados do sistema não são replicadas na instância secundária num grupo de ativação pós-falha. Portanto, os cenários que dependem de objetos dos bancos de dados do sistema, como logons de servidor e trabalhos de agente, exigem que os objetos sejam criados manualmente nas instâncias secundárias e também mantidos manualmente em sincronia após quaisquer alterações feitas na instância primária. A única exceção é a Chave Mestra de Serviço (SMK) para Instância Gerenciada SQL que é replicada automaticamente para instância secundária durante a criação do grupo de failover. Quaisquer alterações subsequentes do SMK na instância primária, no entanto, não serão replicadas para a instância secundária. Para saber mais, veja como Ativar cenários dependentes de objetos a partir das bases de dados do sistema.
- Para instâncias dentro de um grupo de failover, não há suporte para alterar a camada de serviço para, ou de, a camada de Propósito Geral de Próxima geração. Você deve primeiro excluir o grupo de failover antes de modificar qualquer réplica e, em seguida, recriar o grupo de failover depois que a alteração entrar em vigor.
- As instâncias gerenciadas pelo SQL em um grupo de failover devem ter a mesma política de atualização, embora seja possível alterar a política de atualização para instâncias dentro de um grupo de failover.
Gerencie grupos de failover programaticamente
Os grupos de failover também podem ser gerenciados programaticamente usando o Azure PowerShell, a CLI do Azure e a API REST. As tabelas a seguir descrevem o conjunto de comandos disponíveis. Os grupos de failover incluem um conjunto de APIs do Azure Resource Manager para gerenciamento, incluindo a API REST do Banco de Dados SQL do Azure e cmdlets do Azure PowerShell. Essas APIs exigem o uso de grupos de recursos e dão suporte ao controle de acesso baseado em função do Azure (Azure RBAC). Para obter mais informações sobre como implementar funções de acesso, consulte Controle de acesso baseado em função do Azure (Azure RBAC).
| Cmdlet | Descrição |
|---|---|
| New-AzSqlDatabaseInstanceFailoverGroup | Este comando cria um grupo de failover e o registra em instâncias primárias e secundárias |
| Set-AzSqlDatabaseInstanceFailoverGroup | Modifica a configuração de um grupo de contingência |
| Get-AzSqlDatabaseInstanceFailoverGroup | Recupera a configuração de um grupo de failover |
| Switch-AzSqlDatabaseInstanceFailoverGroup | Aciona o failover de um grupo de failover para a instância secundária |
| Remove-AzSqlDatabaseInstanceFailoverGroup | Remove um grupo de failover |