Disponibilidade por meio de redundância local e de zona - Instância Gerenciada de SQL do Azure
Aplica-se a: ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure
Este artigo descreve a arquitetura da Instância Gerenciada de SQL do Azure que alcança a disponibilidade por meio da redundância local, e a alta disponibilidade por meio da redundância de zona.
Importante
A configuração com redundância de zona está em visualização pública para a camada de serviço de Uso Geral e em disponibilidade geral para a camada de serviço Comercialmente Crítico.
Visão geral
A Instância Gerenciada de SQL do Azure é executada na versão estável mais recente do mecanismo de banco de dados do SQL Server no sistema operacional Windows com todos os patches aplicáveis. A Instância Gerenciada de SQL cuida automaticamente de tarefas de serviço críticas, como aplicação de patch, backups, atualizações do mecanismo de banco de dados de SQL e do Windows, bem como eventos não planejados, como hardware subjacente, software ou falhas de rede. Ao aplicar patch ou fazer failover de uma instância, o tempo de inatividade não será perceptível se você empregar a lógica de repetição no aplicativo. A Instância Gerenciada de SQL pode se recuperar rapidamente, até mesmo nas circunstâncias mais críticas, garantindo que os dados estejam sempre disponíveis. A maioria dos usuários não percebe que as atualizações são executadas de modo contínuo.
Por padrão, a Instância Gerenciada de SQL do Azure alcança disponibilidade por meio da redundância local, disponibilizando sua instância durante:
- Operações de gerenciamento iniciadas pelo cliente que resultam em um curto tempo de inatividade
- Operações de manutenção de serviços
- Problemas e interrupções do data center com:
- o rack onde os computadores que acionam seu serviço estão sendo executados
- o computador físico que hospeda a VM que executa o mecanismo de banco de dados de SQL
- a máquina virtual que executa o mecanismo de banco de dados de SQL
- Outros problemas com o mecanismo de banco de dados de SQL
- Outras possíveis interrupções locais não planejadas
A solução padrão de alta disponibilidade foi projetada para garantir que os dados confirmados nunca sejam perdidos devido a falhas, que as operações de manutenção não afetem sua carga de trabalho e que a instância não seja um ponto único de falha em sua arquitetura de software.
No entanto, para minimizar o impacto em seus dados no caso de uma interrupção em uma zona inteira, você pode alcançar alta disponibilidade habilitando a redundância de zona. Sem redundância de zona, os failovers ocorrem localmente no mesmo data center, o que pode resultar na indisponibilidade da instância até que a interrupção seja resolvida. A única maneira de recuperar é por meio de uma solução de recuperação de desastres, como por meio de um grupo de failover ou uma restauração geográfica de um backup com redundância geográfica. Para saber mais, revise a visão geral da continuidade dos negócios.
A alta disponibilidade aumenta a confiabilidade do seu serviço, protegendo-o contra impactos na:
- Zona de disponibilidade que forma o data center
Há dois modelos de arquitetura de alta disponibilidade diferentes com base na camada de serviço:
- O modelo de armazenamento remoto se baseia em uma separação entre a computação e o armazenamento nas camadas de serviço Uso Geral e Uso Geral de Próxima Geração que depende da alta disponibilidade e confiabilidade do armazenamento remoto e da alta disponibilidade de clusters de computação gerenciados pelo Azure Service Fabric. Esse modelo de alta disponibilidade destina-se a aplicativos de negócios orientados a orçamento que podem tolerar alguma degradação do desempenho durante atividades de manutenção.
- O modelo de armazenamento local é baseado em um cluster de processos de mecanismo de banco de dados que dependem de um quorum de nós de mecanismo de banco de dados disponíveis na camada de serviço Business Critical que possuem armazenamento local. Esse modelo de armazenamento local destina-se a aplicativos de missão crítica que têm uma alta taxa de transações e exigem alto desempenho de E/S. A arquitetura de alta disponibilidade garante um impacto mínimo no desempenho da sua carga de trabalho durante as atividades de manutenção.
Para obter mais informações sobre SLAs específicos para diferentes camadas de serviço, confira SLA para Instância Gerenciada de SQL do Azure.
Disponibilidade por meio de redundância local
A disponibilidade com redundância local baseia-se em armazenar os nós de computação e os dados em um único datacenter na região primária e protege os dados em caso de falha local, como uma falha na rede de pequena escala ou de energia. Caso ocorra um desastre em larga escala na região, como um incêndio ou uma inundação, todas as réplicas da conta de armazenamento ou dados dos nós de computação poderão ser perdidos ou se tornarem irrecuperáveis. Dessa forma, para proteger ainda mais seus dados ao usar a opção de disponibilidade com redundância local, considere usar uma opção de armazenamento mais resiliente para os backups de banco de dados.
Camada de serviço de Uso Geral
A camada de serviço Uso Geral usa a arquitetura de disponibilidade de armazenamento remoto. A figura a seguir mostra quatro nós diferentes com as camadas de computação e armazenamento separadas.
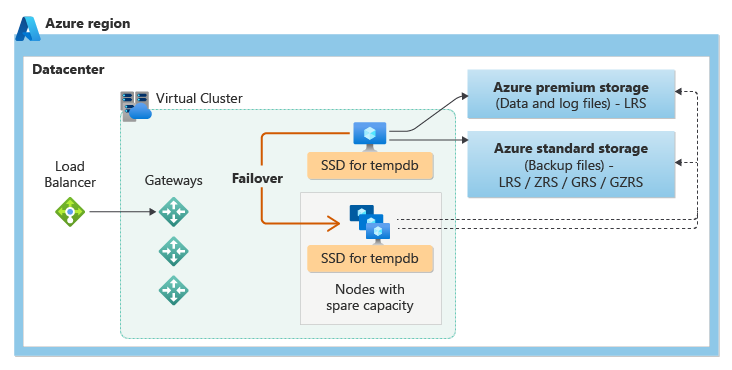
O modelo de disponibilidade de armazenamento remoto inclui duas camadas:
- Uma camada de computação sem estado que executa o processo do mecanismo de banco de dados e contém apenas dados transitórios e em cache, como os bancos de dado
tempdbemodelno SSD anexado e cache de planos, pool de buffer e pool columnstore na memória. Este nó sem estado é operado pelo Microsoft Azure Service Fabric, que inicializa o mecanismo de banco de dados, controla a integridade do nó e executa o failover para outro nó, se necessário. - Uma camada de dados com estado, com arquivos de banco de dados (
.mdfe.ldf) que são armazenados no Armazenamento de Blobs do Azure. O Armazenamento de Blobs do Azure possui recursos internos de redundância e disponibilidade de dados. A disponibilidade com redundância local baseia-se em armazenar os dados no LRS (armazenamento com redundância local), que copia seus dados três vezes em um único datacenter na região primária. Ele garante que todos os registros no arquivo de log ou na página do arquivo de dados serão preservados mesmo se o processo do mecanismo de banco de dados falhar.
Sempre que o mecanismo de banco de dados ou o sistema operacional for atualizado ou uma falha for detectada, o Azure Service Fabric moverá o processo do mecanismo de banco de dados sem estado para outro nó de computação sem estado com capacidade livre suficiente. Os dados no Armazenamento de Blobs do Azure não são afetados pela movimentação, e os arquivos de dados/log são anexados ao processo do mecanismo de banco de dados recém-inicializado. Esse processo garante a alta disponibilidade, mas uma carga de trabalho pesada pode enfrentar degradação do desempenho durante a transição, uma vez que o novo processo do mecanismo de banco de dados começa com o cache frio.
Camada de serviço Uso Geral de Última Geração
Observação
No momento, a atualização da camada de serviço Uso Geral de Última Geração está em preview.
Uso Geral de Próxima Geração é uma atualização da arquitetura da camada de serviço Uso Geral existente que usa uma camada de armazenamento remoto atualizada que armazena dados de instância e arquivos de registros em discos gerenciados em vez de em blobs de páginas, e os mantêm locais.
Camada de serviço comercialmente crítica
A camada de serviço Comercialmente Crítico usa o modelo de disponibilidade de armazenamento local, que integra os recursos de computação (processo do mecanismo de banco de dados) e o armazenamento (SSD anexado localmente) em um nó individual. A alta disponibilidade é obtida com a replicação da computação e do armazenamento para nós adicionais.
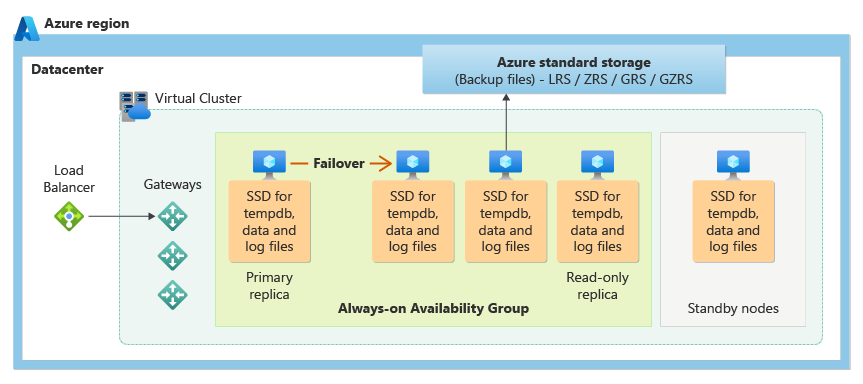
Os arquivos de banco de dados subjacentes (.mdf/.ldf) são colocados no armazenamento SSD anexado para fornecer uma E/S de latência muito baixa para sua carga de trabalho. A alta disponibilidade é implementada usando tecnologia semelhante ao SQL Server Grupos de Disponibilidade AlwaysOn. O cluster inclui uma única réplica primária que é acessível para cargas de trabalho de leitura/gravação do cliente e até três réplicas secundárias (computação e armazenamento) que contêm cópias de dados. A réplica primária envia constantemente as alterações para as réplicas secundárias sequencialmente para garantir que os dados sejam mantidos em um número suficiente de réplicas secundárias antes de confirmar cada transação. Esse processo garante que, se a réplica primária ou uma réplica secundária legível ficar indisponível por qualquer motivo, uma réplica totalmente sincronizada estará sempre disponível para o failover. O failover é iniciado pelo Azure Service Fabric. Depois que a réplica secundária se torna a nova réplica primária, outra réplica secundária é criada para garantir que o cluster tenha o número suficiente de réplicas para manter o quorum. Após a conclusão do failover, as conexões do Azure SQL são redirecionadas automaticamente para a nova réplica primária (ou réplica secundária legível com base na cadeia de conexão).
Como um benefício extra, o modelo de disponibilidade armazenamento local inclui a capacidade de redirecionar conexões SQL do Azure somente leitura para uma das réplicas secundárias. Esse recurso é chamado de Expansão de Leitura. Ele fornece uma capacidade de computação adicional de 100%, sem custo adicional, para operações somente leitura fora do carregamento, como cargas de trabalho analíticas, da réplica primária.
Alta disponibilidade por meio de redundância de zona
A disponibilidade com redundância de zona baseia-se na colocação de réplicas em três zonas de disponibilidade do Azure na região primária. Cada zona de disponibilidade é um local físico separado com energia, resfriamento e rede independentes.
Por padrão, o cluster de nós para o modelo de disponibilidade de armazenamento local é criado no mesmo data center. Com a introdução das Zonas de Disponibilidade do Azure, a Instância Gerenciada de SQL pode colocar diferentes réplicas em diferentes zonas de disponibilidade na mesma região. Para eliminar um ponto único de falha, o anel de controle também é duplicado entre várias zonas. O tráfego do painel de controle é então roteado para um balanceador de carga que também é implantado em zonas de disponibilidade. O roteamento de tráfego do painel de controle para o balanceador de carga é controlado pelo Gerenciador de Tráfego do Azure (ATM).
Ao usar uma configuração com redundância de zona, você pode tornar as instâncias do tipo Comercialmente Crítico ou Uso Geral resilientes a um conjunto muito maior de falhas, incluindo interrupções catastróficas do data center, sem nenhuma alteração na lógica de aplicativo. É possível converter quaisquer instâncias do tipo Comercialmente Crítico ou Uso Geral existentes para a configuração com redundância de zona.
Como a instância com redundância de zona tem réplicas em diferentes datacenters com alguma distância entre eles, a latência de rede aumentada pode aumentar o tempo de confirmação da transação e, desse modo, afetar o desempenho de algumas cargas de trabalho OLTP. Você sempre poderá retornar à configuração de única zona desabilitando a configuração com redundância de zona. Esse processo é uma operação online semelhante à atualização do objetivo da camada de serviço normal. No final do processo, a instância será migrada de um anel com redundância de zona para um anel de única zona ou vice-versa.
Para começar a usar a redundância de zona para sua instância gerenciada de SQL, confira Configurar redundância de zona.
Camada de serviço de Uso Geral
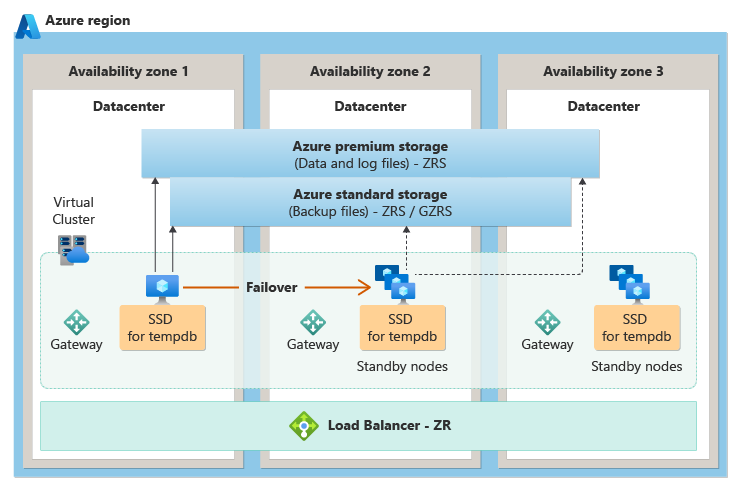
Na camada de serviço Uso Geral, a redundância de zona é obtida colocando nós de computação sem estado em diferentes zonas de disponibilidade, e então depende de um armazenamento com redundância de zona (ZRS) com estado anexado a qualquer nó que contenha atualmente o processo ativo do Mecanismo de Banco de Dados de SQL. No caso de uma interrupção, o processo do Mecanismo de Banco de Dados de SQL fica ativo em um dos nós sem estado, que então acessa os dados no armazenamento com estado.
O diagrama a seguir demonstra a arquitetura de redundância de zona para a camada de serviço Uso Geral:
Observação
A redundância de zona está atualmente em preview para a camada de serviço Uso Geral.
Camada de serviço comercialmente crítica
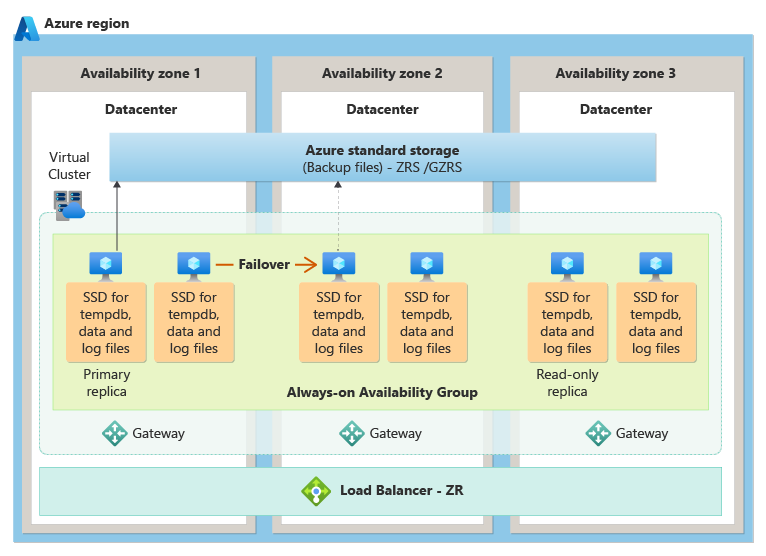
Na camada de serviço Comercialmente Crítico, a redundância de zona é obtida colocando réplicas de computação e armazenamento em diferentes zonas de disponibilidade e, em seguida, usando a tecnologia de grupo de disponibilidade Always On subjacente para replicar alterações de dados da instância primária para réplicas em espera em outras zonas de disponibilidade. No caso de uma interrupção, há um failover automático que faz a transição perfeita de uma das réplicas em espera para ser primária.
O diagrama a seguir demonstra a arquitetura de redundância de zona para a camada de serviço Comercialmente Crítico:
Testar a resiliência de falha do aplicativo
A alta disponibilidade é uma parte fundamental da plataforma da Instância Gerenciada de SQL que funciona de maneira transparente para o aplicativo de banco de dados. No entanto, reconhecemos que talvez você queira testar como as operações de failover automático iniciadas durante os eventos planejados ou não planejados afetariam um aplicativo antes de implantá-lo na produção. Você pode disparar um failover manualmente chamando uma API especial para reiniciar uma instância gerenciada. Como a operação de reinicialização é intrusiva e o excesso da mesma pode sobrecarregar a plataforma, apenas uma chamada de failover é permitida a cada 15 minutos para cada instância gerenciada.
Durante um failover verdadeiro, as conexões com a instância falham enquanto o serviço de SQL torna-se primário em um nó diferente. Para simular um failover, invoque o comando que reinicia o processo de SQL para simular a inicialização do serviço como se houvesse um failover. No entanto, as conexões podem falhar por um período mais longo durante um failover verdadeiro em comparação com um failover simulado, já que durante um failover verdadeiro, o processo de SQL torna-se o primário em outra máquina virtual no cluster (localmente ou em outra zona se a redundância de zona estiver habilitada), e durante um failover simulado, o processo de SQL é reiniciado na máquina virtual existente.
O comando de failover manual nesta seção comporta-se da mesma maneira em configurações com redundância de zona e redundância local. Ele apenas reinicia o processo de SQL localmente e não inicia um failover para outro nó. Esse failover local é diferente de um failover que ocorre para um grupo de failover.
Um failover local pode ser iniciado usando o PowerShell, a API REST ou a CLI do Azure:
| PowerShell | API REST | CLI do Azure |
|---|---|---|
| Invoke-AzSqlInstanceFailover | Instância Gerenciada de SQL – Failover | az sql mi failover pode ser usado para invocar uma chamada à API REST de CLI do Azure |
Conclusão
A Instância Gerenciada de SQL do Azure apresenta uma solução de alta disponibilidade interna, que está profundamente integrada com a plataforma Azure. O serviço depende do Service Fabric para detectar falhas e recuperá-las, do armazenamento de Blob do Azure para proteger os dados e das Zonas de Disponibilidade para maior tolerância a falhas. Para a camada de serviço Comercialmente Crítico, a Instância Gerenciada de SQL usa a tecnologia de grupo de disponibilidade Always On do SQL Server para replicação e failover de banco de dados. A combinação dessas tecnologias permite que os aplicativos percebam em sua totalidade os benefícios de um modelo de armazenamento misto e deem suporte aos SLAs mais exigentes.
Próximas etapas
- Habilite a redundância de zona para a Instância Gerenciada de SQL do Azure.
- Saiba mais sobre as Zonas de Disponibilidade do Azure
- Saiba mais sobre o Service Fabric
- Saiba mais sobre o Gerenciador de Tráfego do Microsoft Azure
- Saiba Como iniciar um failover manual na Instância Gerenciada de SQL
- Para obter mais opções de alta disponibilidade e recuperação de desastres, consulte Continuidade de negócios
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários