Operações de machine learning
Operações de aprendizado de máquina (também chamadas de MLOps) são a aplicação dos princípios de DevOps a aplicativos infundidos por IA. Para implementar operações de aprendizado de máquina em uma organização, habilidades, processos e tecnologia específicos devem estar em vigor. O objetivo é fornecer soluções de aprendizado de máquina que sejam robustas, escaláveis, confiáveis e automatizadas.
Neste artigo, saiba como planejar recursos para dar suporte a operações de aprendizado de máquina no nível da organização. Analise as práticas recomendadas e recomendações baseadas no uso do Aprendizado de Máquina do Azure para adotar operações de aprendizado de máquina na empresa.
O que são operações de machine learning?
Algoritmos e estruturas modernas de aprendizado de máquina tornam cada vez mais fácil desenvolver modelos que podem fazer previsões precisas. As operações de aprendizado de máquina são uma maneira estruturada de incorporar o aprendizado de máquina no desenvolvimento de aplicativos na empresa.
Em um cenário de exemplo, você criou um modelo de aprendizado de máquina que excede todas as suas expectativas de precisão e impressiona seus patrocinadores de negócios. Agora é hora de implantar o modelo na produção, mas isso pode não ser tão fácil quanto você esperava. A organização provavelmente precisará ter pessoas, processos e tecnologia antes de poder usar seu modelo de aprendizado de máquina na produção.
Com o tempo, você ou um colega podem desenvolver um novo modelo que funcione melhor do que o modelo original. A substituição de um modelo de aprendizado de máquina usado na produção introduz algumas preocupações que são importantes para a organização:
- Você desejará implementar o novo modelo sem interromper as operações de negócios que dependem do modelo implantado.
- Para fins regulatórios, pode ser necessário explicar as previsões do modelo ou recriá-lo se previsões incomuns ou tendenciosas resultarem de dados no novo modelo.
- Os dados que você usa em seu modelo e treinamento de aprendizado de máquina podem mudar ao longo do tempo. Com as alterações nos dados, talvez seja necessário treinar novamente periodicamente o modelo para manter sua precisão de previsão. Uma pessoa ou função precisará receber a responsabilidade de alimentar os dados, monitorar o desempenho do modelo, treinar novamente o modelo e corrigir o modelo se ele falhar.
Suponha que você tenha um aplicativo que atenda às previsões de um modelo por meio da API REST. Mesmo um caso de uso simples como este pode causar problemas na produção. A implementação de uma estratégia de operações de aprendizado de máquina pode ajudá-lo a resolver problemas de implantação e dar suporte a operações de negócios que dependem de aplicativos infundidos por IA.
Algumas tarefas de operações de aprendizado de máquina se encaixam bem na estrutura geral de DevOps. Os exemplos incluem a configuração de testes de unidade e testes de integração e o controle de alterações usando o controle de versão. Outras tarefas são mais exclusivas para operações de aprendizado de máquina e podem incluir:
- Habilite a experimentação e a comparação contínuas em relação a um modelo de linha de base.
- Monitore os dados recebidos para detetar desvio de dados.
- Acione o retreinamento do modelo e configure uma reversão para recuperação de desastres.
- Crie pipelines de dados reutilizáveis para treinamento e pontuação.
O objetivo das operações de aprendizado de máquina é fechar a lacuna entre desenvolvimento e produção e entregar valor aos clientes mais rapidamente. Para atingir esse objetivo, é preciso repensar os processos tradicionais de desenvolvimento e produção.
Nem todos os requisitos de operações de aprendizado de máquina da organização são os mesmos. A arquitetura de operações de aprendizado de máquina de uma grande empresa multinacional provavelmente não será a mesma infraestrutura que uma pequena startup estabelece. As organizações normalmente começam pequenas e se acumulam à medida que sua maturidade, catálogo de modelos e experiência crescem.
O modelo de maturidade das operações de aprendizado de máquina pode ajudá-lo a ver onde sua organização está na escala de maturidade das operações de aprendizado de máquina e ajudá-lo a planejar o crescimento futuro.
Operações de aprendizado de máquina versus DevOps
As operações de aprendizado de máquina são diferentes do DevOps em várias áreas-chave. As operações de aprendizado de máquina têm estas características:
- A exploração precede o desenvolvimento e as operações.
- O ciclo de vida da ciência de dados requer uma forma adaptativa de trabalhar.
- Os limites de qualidade e disponibilidade dos dados limitam o progresso.
- É necessário um esforço operacional maior do que no DevOps.
- As equipas de trabalho requerem especialistas e especialistas no domínio.
Para um resumo, analise os sete princípios das operações de aprendizado de máquina.
A exploração precede o desenvolvimento e as operações
Os projetos de ciência de dados são diferentes dos projetos de desenvolvimento de aplicações ou engenharia de dados. Um projeto de ciência de dados pode chegar à produção, mas muitas vezes há mais etapas envolvidas do que em uma implantação tradicional. Após uma análise inicial, pode ficar claro que o resultado do negócio não pode ser alcançado com os conjuntos de dados disponíveis. Uma fase de exploração mais detalhada geralmente é o primeiro passo em um projeto de ciência de dados.
O objetivo da fase de exploração é definir e refinar o problema. Durante esta fase, os cientistas de dados executam a análise exploratória de dados. Eles usam estatísticas e visualizações para confirmar ou falsificar as hipóteses do problema. As partes interessadas devem compreender que o projeto pode não se estender para além desta fase. Ao mesmo tempo, é importante tornar esta fase o mais perfeita possível para uma rápida recuperação. A menos que o problema a resolver inclua um elemento de segurança, evite restringir a fase exploratória com processos e procedimentos. Os cientistas de dados devem poder trabalhar com as ferramentas e os dados que preferirem. São necessários dados reais para este trabalho exploratório.
O projeto pode passar para os estágios de experimentação e desenvolvimento quando as partes interessadas estão confiantes de que o projeto de ciência de dados é viável e pode fornecer valor comercial real. Nesta fase, as práticas de desenvolvimento tornam-se cada vez mais importantes. É uma boa prática capturar métricas para todos os experimentos que são feitos nesta etapa. Também é importante incorporar o controle do código-fonte para que você possa comparar modelos e alternar entre diferentes versões do código.
As atividades de desenvolvimento incluem refatoração, teste e automação de código de exploração em pipelines de experimentação repetíveis. A organização deve criar aplicativos e pipelines para atender aos modelos. A refatoração de código em componentes modulares e bibliotecas ajuda a aumentar a reutilização, os testes e a otimização do desempenho.
Finalmente, os pipelines de inferência de aplicativo ou lote que servem aos modelos são implantados em ambientes de preparação ou produção. Além de monitorar a confiabilidade e o desempenho da infraestrutura, como para um aplicativo padrão, em uma implantação de modelo de aprendizado de máquina, você deve monitorar continuamente a qualidade dos dados, o perfil de dados e o modelo para degradação ou desvio. Os modelos de aprendizado de máquina também exigem retreinamento ao longo do tempo para permanecerem relevantes em um ambiente em mudança.
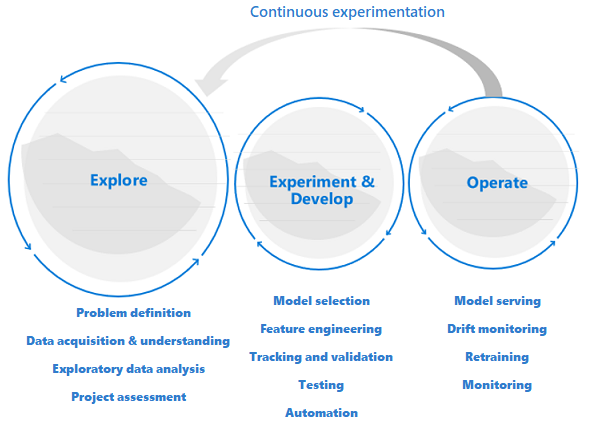
O ciclo de vida da ciência de dados requer uma forma adaptativa de trabalhar
Como a natureza e a qualidade dos dados inicialmente são incertas, você pode não atingir suas metas de negócios se aplicar um processo típico de DevOps a um projeto de ciência de dados. A exploração e a experimentação são atividades e necessidades recorrentes ao longo do processo de aprendizagem automática. As equipes da Microsoft usam um ciclo de vida do projeto e um processo de trabalho que refletem a natureza das atividades específicas da ciência de dados. O Processo de Ciência de Dados da Equipe e o Processo de Ciclo de Vida da Ciência de Dados são exemplos de implementações de referência.
Os limites de qualidade e disponibilidade dos dados limitam o progresso
Para que uma equipe de aprendizado de máquina desenvolva efetivamente aplicativos infundidos de aprendizado de máquina, o acesso aos dados de produção é preferido para todos os ambientes de trabalho relevantes. Se o acesso aos dados de produção não for possível devido a requisitos de conformidade ou restrições técnicas, considere implementar o controle de acesso baseado em função do Azure (Azure RBAC) com o Azure Machine Learning, acesso just-in-time ou pipelines de movimentação de dados para criar réplicas de dados de produção e melhorar a produtividade do usuário.
O aprendizado de máquina requer um esforço operacional maior
Ao contrário do software tradicional, o desempenho de uma solução de aprendizado de máquina está constantemente em risco porque a solução depende da qualidade dos dados. Para manter uma solução qualitativa na produção, é fundamental que você monitore e reavalie continuamente a qualidade dos dados e do modelo. Espera-se que um modelo de produção exija retreinamento, reimplantação e ajuste oportunos. Essas tarefas se somam aos requisitos diários de segurança, monitoramento de infraestrutura e conformidade, e exigem conhecimento especializado.
Equipes de aprendizado de máquina exigem especialistas e especialistas em domínio
Embora os projetos de ciência de dados compartilhem funções com projetos de TI regulares, o sucesso de um esforço de aprendizado de máquina depende muito de ter especialistas essenciais em tecnologia de aprendizado de máquina e especialistas no assunto do domínio. Um especialista em tecnologia tem a formação certa para fazer experimentação de aprendizado de máquina de ponta a ponta. Um especialista em domínio pode dar suporte ao especialista analisando e sintetizando dados ou qualificando dados para uso.
As funções técnicas comuns que são exclusivas para projetos de ciência de dados são especialista em domínio, engenheiro de dados, cientista de dados, engenheiro de IA, validador de modelos e engenheiro de aprendizado de máquina. Para saber mais sobre funções e tarefas em uma equipe típica de ciência de dados, consulte o Processo de Ciência de Dados da Equipe.
Sete princípios de operações de aprendizado de máquina
Ao planejar adotar operações de aprendizado de máquina em sua organização, considere aplicar os seguintes princípios fundamentais como base:
Use o controle de versão para código, dados e saídas de experimentação. Ao contrário do desenvolvimento de software tradicional, os dados têm uma influência direta na qualidade dos modelos de aprendizagem automática. Você deve fazer a versão da base de código de experimentação, mas também os conjuntos de dados para garantir que possa reproduzir experimentos ou resultados de inferência. As saídas de experimentação de versionamento, como modelos, podem economizar esforço e o custo computacional de recriá-las.
Use vários ambientes. Para separar o desenvolvimento e os testes do trabalho de produção, replique sua infraestrutura em pelo menos dois ambientes. O controle de acesso para usuários pode ser diferente para cada ambiente.
Gerencie sua infraestrutura e configurações como código. Ao criar e atualizar componentes de infraestrutura em seus ambientes de trabalho, use a infraestrutura como código, para que as inconsistências não se desenvolvam em seus ambientes. Gerencie as especificações do trabalho do experimento de aprendizado de máquina como código para que você possa facilmente executar e reutilizar uma versão do seu experimento em vários ambientes.
Rastreie e gerencie experimentos de aprendizado de máquina. Acompanhe indicadores-chave de desempenho e outros artefatos para seus experimentos de aprendizado de máquina. Quando você mantém um histórico de desempenho no trabalho, pode fazer uma análise quantitativa do sucesso da experimentação e melhorar a colaboração e a agilidade da equipe.
Teste o código, valide a integridade dos dados e garanta a qualidade do modelo. Teste sua base de código de experimentação para preparar dados corretos e funções de extração de recursos, integridade de dados e desempenho do modelo.
Integração e entrega contínuas de aprendizagem automática. Use a integração contínua (CI) para automatizar os testes para sua equipe. Inclua o treinamento modelo como parte dos pipelines de treinamento contínuo. Inclua testes A/B como parte de sua versão para garantir que apenas um modelo qualitativo seja usado na produção.
Monitore serviços, modelos e dados. Quando você atende modelos em um ambiente de operações de aprendizado de máquina, é fundamental monitorar os serviços quanto ao tempo de atividade da infraestrutura, conformidade e qualidade do modelo. Configure o monitoramento para identificar dados e desvios de modelo e para entender se é necessário um novo treinamento. Considere a configuração de gatilhos para retreinamento automático.
Práticas recomendadas do Azure Machine Learning
O Azure Machine Learning oferece serviços de gestão de ativos, orquestração e automação para o ajudar a gerir o ciclo de vida dos fluxos de trabalho de formação e implementação do seu modelo de aprendizagem automática. Reveja as melhores práticas e recomendações para aplicar operações de aprendizagem automática nas áreas de recursos de pessoas, processos e tecnologia, todas suportadas pelo Azure Machine Learning.
Pessoas
Trabalhe em equipes de projeto para melhor usar o conhecimento especializado e de domínio em sua organização. Configure os espaços de trabalho do Azure Machine Learning para cada projeto para cumprir os requisitos de segregação de casos de uso.
Defina um conjunto de responsabilidades e tarefas como uma função para que qualquer membro da equipe em uma equipe de projeto de operações de aprendizado de máquina possa ser atribuído e cumprir várias funções. Use funções personalizadas no Azure para definir um conjunto de operações granulares do RBAC do Azure para o Aprendizado de Máquina do Azure que cada função pode executar.
Padronizar o ciclo de vida do projeto e a metodologia ágil. O Processo de Ciência de Dados da Equipe fornece uma implementação de ciclo de vida de referência.
Equipes equilibradas podem executar todos os estágios de operações de aprendizado de máquina, incluindo exploração, desenvolvimento e operações.
Processo
Padronize em um modelo de código para reutilização de código e para acelerar o tempo de ramp-up em um novo projeto ou quando um novo membro da equipe ingressa no projeto. Use pipelines do Azure Machine Learning, scripts de envio de trabalho e pipelines de CI/CD como base para novos modelos.
Use o controle de versão. Os trabalhos enviados de uma pasta apoiada pelo Git rastreiam automaticamente os metadados do repositório com o trabalho no Aprendizado de Máquina do Azure para reprodutibilidade.
Use o controle de versão para entradas e saídas experimentais para reprodutibilidade. Use os conjuntos de dados do Azure Machine Learning, o gerenciamento de modelos e os recursos de gerenciamento de ambiente para facilitar o controle de versão.
Construa um histórico de execução de execuções de experimentos para comparação, planejamento e colaboração. Use uma estrutura de acompanhamento de experimentos como o MLflow para coletar métricas.
Meça e controle continuamente a qualidade do trabalho de sua equipe através de CI na base de código de experimentação completa.
Encerre o treinamento no início do processo quando um modelo não convergir. Use uma estrutura de controle de experimentos e o histórico de execução no Aprendizado de Máquina do Azure para monitorar execuções de trabalho.
Definir uma estratégia de gestão de experiências e modelos. Considere usar um nome como campeão para se referir ao modelo de linha de base atual. Um modelo challenger é um modelo candidato que pode superar o modelo campeão em produção. Aplique tags no Aprendizado de Máquina do Azure para marcar experimentos e modelos. Em um cenário como a previsão de vendas, pode levar meses para determinar se as previsões do modelo são precisas.
Eleve a IC para treinamento contínuo, incluindo treinamento de modelo na construção. Por exemplo, comece o treinamento de modelo no conjunto de dados completo com cada solicitação pull.
Reduza o tempo necessário para obter feedback sobre a qualidade do pipeline de aprendizado de máquina executando uma compilação automatizada em uma amostra de dados. Use os parâmetros de pipeline do Azure Machine Learning para parametrizar conjuntos de dados de entrada.
Use a implantação contínua (CD) para modelos de aprendizado de máquina para automatizar a implantação e testar serviços de pontuação em tempo real em seus ambientes do Azure.
Em alguns setores regulamentados, pode ser necessário concluir as etapas de validação do modelo antes de poder usar um modelo de aprendizado de máquina em um ambiente de produção. A automatização das etapas de validação pode acelerar o tempo de entrega. Quando as etapas manuais de revisão ou validação ainda forem um gargalo, considere se você pode certificar o pipeline de validação de modelo automatizado. Use marcas de recursos no Aprendizado de Máquina do Azure para indicar a conformidade de ativos e candidatos para revisão ou como gatilhos para implantação.
Não treine novamente na produção e, em seguida, substitua diretamente o modelo de produção sem fazer testes de integração. Embora o desempenho do modelo e os requisitos funcionais possam parecer bons, entre outros problemas potenciais, um modelo retreinado pode ter uma pegada de ambiente maior e quebrar o ambiente do servidor.
Quando o acesso aos dados de produção estiver disponível apenas em produção, use o RBAC do Azure e funções personalizadas para dar acesso de leitura a um número selecionado de profissionais de aprendizado de máquina. Algumas funções podem precisar ler os dados para exploração de dados relacionados. Como alternativa, disponibilize uma cópia de dados em ambientes que não sejam de produção.
Concorde em convenções de nomenclatura e tags para experimentos do Azure Machine Learning para diferenciar pipelines de aprendizado de máquina de linha de base de retreinamento do trabalho experimental.
Tecnologia
Se você enviar trabalhos atualmente por meio da interface do usuário ou CLI do estúdio do Azure Machine Learning, em vez de enviar trabalhos por meio do SDK, use as tarefas CLI ou Azure DevOps Machine Learning para configurar as etapas do pipeline de automação. Esse processo pode reduzir o espaço ocupado pelo código reutilizando os mesmos envios de trabalho diretamente de pipelines de automação.
Use programação baseada em eventos. Por exemplo, acione um pipeline de teste de modelo offline usando o Azure Functions depois que um novo modelo for registrado. Ou envie uma notificação para um alias de e-mail designado quando um pipeline crítico não for executado. O Azure Machine Learning cria eventos na Grade de Eventos do Azure. Várias funções podem se inscrever para serem notificadas de um evento.
Quando você usa o Azure DevOps para automação, use as Tarefas de DevOps do Azure para Machine Learning para usar modelos de aprendizado de máquina como gatilhos de pipeline.
Ao desenvolver pacotes Python para seu aplicativo de aprendizado de máquina, você pode hospedá-los em um repositório do Azure DevOps como artefatos e publicá-los como um feed. Usando essa abordagem, você pode integrar o fluxo de trabalho de DevOps para criar pacotes com seu espaço de trabalho do Azure Machine Learning.
Considere o uso de um ambiente de preparo para testar a integração do sistema de pipeline de aprendizado de máquina com componentes de aplicativos upstream ou downstream.
Crie testes de unidade e integração para seus pontos de extremidade de inferência para depuração aprimorada e para acelerar o tempo de implantação.
Para acionar o retreinamento, use monitores de conjunto de dados e fluxos de trabalho orientados a eventos. Assine eventos de desvio de dados e automatize o gatilho de pipelines de aprendizado de máquina para reciclagem.
Fábrica de IA para operações de machine learning da organização
Uma equipe de ciência de dados pode decidir que pode gerenciar vários casos de uso de aprendizado de máquina internamente. A adoção de operações de aprendizado de máquina ajuda uma organização a configurar equipes de projeto para melhor qualidade, confiabilidade e manutenibilidade das soluções. Por meio de equipes equilibradas, processos suportados e automação de tecnologia, uma equipe que adota operações de aprendizado de máquina pode escalar e se concentrar no desenvolvimento de novos casos de uso.
À medida que o número de casos de uso cresce em uma organização, a carga de gerenciamento de suporte aos casos de uso cresce linearmente, ou até mais. O desafio para a organização torna-se como acelerar o tempo de comercialização, apoiar uma avaliação mais rápida da viabilidade de casos de uso, implementar a repetibilidade e usar melhor os recursos e conjuntos de habilidades disponíveis em uma variedade de projetos. Para muitas organizações, desenvolver uma fábrica de IA é a solução.
Uma fábrica de IA é um sistema de processos de negócios repetíveis e artefatos padronizados que facilita o desenvolvimento e a implantação de um grande conjunto de casos de uso de aprendizado de máquina. Uma fábrica de IA otimiza a configuração da equipe, as práticas recomendadas, a estratégia de operações de aprendizado de máquina, os padrões arquitetônicos e os modelos reutilizáveis que são adaptados aos requisitos de negócios.
Uma fábrica de IA bem-sucedida depende de processos repetíveis e ativos reutilizáveis para ajudar a organização a escalar eficientemente de dezenas de casos de uso para milhares de casos de uso.
A figura a seguir resume os principais elementos de uma fábrica de IA:

Padronizar em padrões arquitetônicos repetíveis
A repetibilidade é uma característica fundamental de uma fábrica de IA. As equipes de ciência de dados podem acelerar o desenvolvimento de projetos e melhorar a consistência entre projetos, desenvolvendo alguns padrões de arquitetura repetíveis que abrangem a maioria dos casos de uso de aprendizado de máquina para sua organização. Quando esses padrões estão em vigor, a maioria dos projetos pode usá-los para obter os seguintes benefícios:
- Fase de projeto acelerada
- Aprovações aceleradas das equipes de TI e segurança quando reutilizam ferramentas em projetos
- Desenvolvimento acelerado devido à infraestrutura reutilizável como modelos de código e modelos de projeto
Os padrões de arquitetura podem incluir, mas não estão limitados aos seguintes tópicos:
- Serviços preferenciais para cada etapa do projeto
- Conectividade e governança de dados
- Uma estratégia de operações de aprendizado de máquina adaptada aos requisitos do setor, do negócio ou da classificação de dados
- Modelos de campeão e desafiante de gerenciamento de experimentos
Facilite a colaboração e o compartilhamento entre equipes
Repositórios de código compartilhado e utilitários podem acelerar o desenvolvimento de soluções de aprendizado de máquina. Os repositórios de código podem ser desenvolvidos de forma modular durante o desenvolvimento do projeto para que sejam genéricos o suficiente para serem usados em outros projetos. Eles podem ser disponibilizados em um repositório central que todas as equipes de ciência de dados podem acessar.
Partilhar e reutilizar propriedade intelectual
Para maximizar a reutilização de código, revise a seguinte propriedade intelectual no início de um projeto:
- Código interno que foi projetado para reutilizar na organização. Os exemplos incluem pacotes e módulos.
- Conjuntos de dados que foram criados em outros projetos de aprendizado de máquina ou que estão disponíveis no ecossistema do Azure.
- Projetos de ciência de dados existentes que têm uma arquitetura e problemas de negócios semelhantes.
- GitHub ou repositórios de código aberto que podem acelerar o projeto.
Qualquer retrospetiva de projeto deve incluir um item de ação para determinar se os elementos do projeto podem ser compartilhados e generalizados para reutilização mais ampla. A lista de ativos que a organização pode compartilhar e reutilizar se expande ao longo do tempo.
Para ajudar com o compartilhamento e a descoberta, muitas organizações introduziram repositórios compartilhados para organizar trechos de código e artefatos de aprendizado de máquina. Os artefatos no Aprendizado de Máquina do Azure, incluindo conjuntos de dados, modelos, ambientes e pipelines, podem ser definidos como código, para que você possa compartilhá-los de forma eficiente entre projetos e espaços de trabalho.
Modelos de projeto
Para acelerar o processo de migração de soluções existentes e maximizar a reutilização de código, muitas organizações padronizam um modelo de projeto para iniciar novos projetos. Exemplos de modelos de projeto recomendados para uso com o Azure Machine Learning são exemplos do Azure Machine Learning, o Processo de Ciclo de Vida da Ciência de Dados e o Processo de Ciência de Dados da Equipe.
Gestão central de dados
O processo de obter acesso a dados para exploração ou uso de produção pode ser demorado. Muitas organizações centralizam o gerenciamento de dados para reunir produtores e consumidores de dados para facilitar o acesso aos dados para experimentação de aprendizado de máquina.
Utilitários compartilhados
Sua organização pode usar painéis centralizados em toda a empresa para consolidar informações de registro e monitoramento. Os painéis podem incluir registro de erros, disponibilidade e telemetria do serviço e monitoramento de desempenho do modelo.
Use as métricas do Azure Monitor para criar um painel para o Azure Machine Learning e serviços associados, como o Armazenamento do Azure. Um painel ajuda você a acompanhar o progresso da experimentação, a integridade da infraestrutura de computação e a utilização da cota de GPU.
Equipe de engenharia especializada em aprendizado de máquina
Muitas organizações implementaram o papel de engenheiro de aprendizado de máquina. Um engenheiro de aprendizado de máquina é especializado na criação e execução de pipelines robustos de aprendizado de máquina, fluxos de trabalho de monitoramento e retreinamento de deriva e painéis de monitoramento. O engenheiro tem a responsabilidade geral pela industrialização da solução de aprendizado de máquina, desde o desenvolvimento até a produção. O engenheiro trabalha em estreita colaboração com engenharia de dados, arquitetos, segurança e operações para garantir que todos os controles necessários estejam em vigor.
Embora a ciência de dados exija profundo conhecimento de domínio, a engenharia de aprendizado de máquina é mais técnica em foco. A diferença torna o engenheiro de aprendizado de máquina mais flexível, para que ele possa trabalhar em vários projetos e com vários departamentos de negócios. Grandes práticas de ciência de dados podem se beneficiar de uma equipe de engenharia especializada em aprendizado de máquina que impulsiona a repetibilidade e a reutilização de fluxos de trabalho de automação em vários casos de uso e áreas de negócios.
Habilitação e documentação
É importante fornecer orientações claras sobre o processo de fábrica de IA para equipes e usuários novos e existentes. A orientação ajuda a garantir a consistência e reduzir o esforço exigido da equipe de engenharia de aprendizado de máquina quando ela industrializa um projeto. Considere criar conteúdo especificamente para as várias funções em sua organização.
Todos têm uma maneira única de aprender, portanto, uma mistura dos seguintes tipos de orientação pode ajudar a acelerar a adoção da estrutura de fábrica de IA:
- Um hub central que tem links para todos os artefatos. Por exemplo, esse hub pode ser um canal no Microsoft Teams ou um site do Microsoft SharePoint.
- Formação e um plano de capacitação desenhado para cada função.
- Uma apresentação resumida de alto nível da abordagem e um vídeo complementar.
- Um documento ou manual detalhado.
- Vídeos de instruções.
- Avaliações de prontidão.
Operações de aprendizagem automática na série de vídeos do Azure
Uma série de vídeos sobre operações de aprendizagem automática no Azure mostra-lhe como estabelecer operações de aprendizagem automática para a sua solução de aprendizagem automática, desde o desenvolvimento inicial até à produção.
Ética
A ética desempenha um papel fundamental no design de uma solução de IA. Se os princípios éticos não forem implementados, os modelos treinados podem exibir o mesmo viés que está presente nos dados em que foram treinados. O resultado pode ser a descontinuação do projeto. Mais importante ainda, a reputação da organização pode estar em risco.
Para garantir que os princípios éticos fundamentais que a organização defende sejam implementados em todos os projetos, a organização deve fornecer uma lista desses princípios e maneiras de validá-los de uma perspetiva técnica durante a fase de testes. Utilize as funcionalidades de aprendizagem automática no Azure Machine Learning para compreender o que é a aprendizagem automática responsável e como incorporá-la nas suas operações de aprendizagem automática.
Próximos passos
Saiba mais sobre como organizar e configurar ambientes do Azure Machine Learning ou assista a uma série de vídeos práticos sobre operações de aprendizado de máquina no Azure.
Saiba mais sobre como gerenciar orçamentos, cotas e custos no nível da organização usando o Azure Machine Learning: