Desempenho e resolução de problemas de extração de dados SAP
Este artigo faz parte da série de artigos "Expandir e inovar dados do SAP: Melhores práticas".
- Identificar origens de dados SAP
- Escolher o melhor conector SAP
- Desempenho e resolução de problemas de extração de dados SAP
- Segurança de integração de dados para SAP no Azure
- Arquitetura genérica da integração de dados SAP
Existem várias formas de ligar ao sistema SAP para integração de dados. As secções abaixo descrevem considerações e recomendações gerais e específicas do conector.
Desempenho
É importante configurar as definições ideais para a origem e o destino para que possa obter o melhor desempenho durante a extração e processamento de dados.
Considerações gerais
- Certifique-se de que os parâmetros SAP corretos estão definidos para uma ligação simultânea máxima.
- Considere utilizar o tipo de início de sessão do Grupo SAP para um melhor desempenho e distribuição de carga.
- Certifique-se de que a máquina virtual de runtime de integração autoalojada (SHIR) está dimensionada adequadamente e está altamente disponível.
- Quando trabalha com conjuntos de dados grandes, verifique se o conector que está a utilizar fornece uma capacidade de criação de partições. Muitos dos conectores SAP suportam capacidades de criação de partições e paralelização para acelerar o carregamento de dados. Quando utiliza este método, os dados são empacotados em segmentos mais pequenos que podem ser carregados através de vários processos paralelos. Para obter mais informações, veja a documentação específica do conector.
Recomendações gerais
Utilize a transação SAP RZ12 para modificar valores para ligações simultâneas máximas.
Parâmetros SAP para RFC – RZ12: o parâmetro seguinte pode restringir o número de chamadas RFC permitidas para um utilizador ou uma aplicação, pelo que certifique-se de que esta restrição não está a causar um estrangulamento.
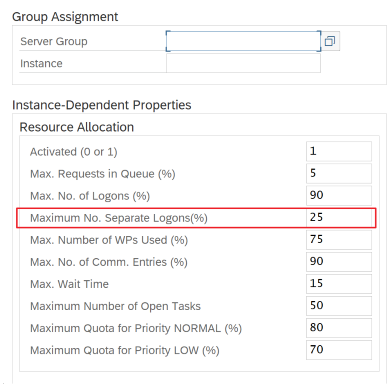
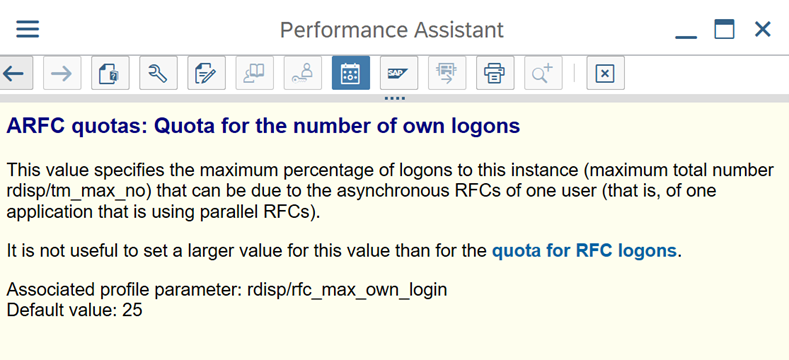
Ligação ao SAP através do Grupo de Início de Sessão: o SHIR (runtime de integração autoalojado) deve ligar-se ao SAP através de um Grupo de Início de Sessão SAP (através do servidor de mensagens) e não a um servidor de aplicações específico para garantir uma distribuição de carga de trabalho em todos os servidores de aplicações disponíveis.
Nota
O cluster do Spark de Fluxo de Dados e o SHIR são poderosos. Muitas atividades de cópia sap internas, por exemplo, 16, podem ser acionadas e executadas. No entanto, se o número de ligação simultâneo do servidor SAP for pequeno, por exemplo, 8, o desempenho lê os dados do lado do SAP.
Comece com VMs de 4vCPUs e 16 GB para SHIR. Os passos seguintes mostram a ligação do processo de trabalho da caixa de diálogo no SAP com o SHIR.
- Verifique se o cliente utiliza um computador físico fraco para configurar e instalar o SHIR para executar uma cópia sap interna.
- Aceda ao portal de Azure Data Factory e localize o serviço ligado SAP CDC que é utilizado no fluxo de dados. Verifique o nome do SHIR referenciado.
- Verifique as definições de CPU, memória, rede e disco do computador físico onde o SHIR está instalado.
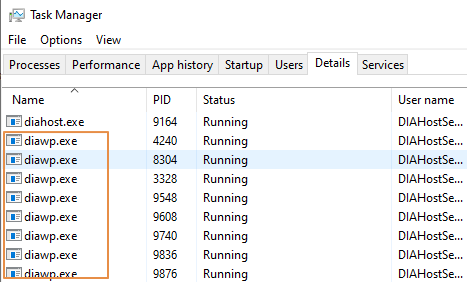
- Verifique quantos
diawp.exeestão em execução no computador SHIR. Pode-sediawp.exeexecutar uma atividade de cópia. O número dediawp.exeé baseado nas definições de CPU, memória, rede e disco do computador.
Se quiser executar várias partições em paralelo no SHIR ao mesmo tempo, utilize uma máquina virtual avançada para configurar o SHIR. Em alternativa, utilize funcionalidades de elevada disponibilidade e escalabilidade do SHIR para ter vários nós. Para obter mais informações, veja Elevada disponibilidade e escalabilidade.
Partições
A secção seguinte descreve o processo de criação de partições para um conector SAP CDC. O processo é o mesmo para um conector SAP Table e SAP BW Open Hub.

O dimensionamento pode ser efetuado no IR autoalojado ou no IR do Azure, consoante os requisitos de desempenho. Reveja o consumo da CPU do SHIR para ver as métricas para o ajudar a decidir sobre a sua abordagem de dimensionamento. O SHIR pode ser vertical ou horizontalmente dimensionado com base nas suas necessidades. Recomendamos que implemente o IR do Azure num SKU inferior. Aumente verticalmente para satisfazer os seus requisitos de desempenho, conforme determinado através de testes de carga, em vez de começar desnecessariamente na extremidade superior.
Nota
Se estiver a atingir 70% de capacidade, aumente verticalmente ou aumente verticalmente para o SHIR.

A criação de partições é útil para cargas completas iniciais ou grandes e normalmente não é necessária para cargas delta. Se não especificar a partição, por predefinição, 1 "produtor" no sistema SAP (normalmente um processo de lote) obtém os dados de origem para a fila de dados operacional (ODQ) e o SHIR obtém os dados do ODQ. Por predefinição, o SHIR utiliza quatro threads para obter os dados do ODQ, pelo que, potencialmente, são ocupados quatro processos de caixa de diálogo no SAP nesse momento.
A ideia de criação de partições é dividir um grande conjunto de dados inicial em múltiplos subconjuntores menores desarticulados que são idealmente iguais em tamanho e que podem ser processados em paralelo. Este método reduz o tempo necessário para produzir os dados da tabela de origem para o ODQ de forma linear. Este método pressupõe que existem recursos suficientes no lado do SAP para processar a carga.
Nota
- O número de partições executadas em paralelo é limitado pelo número de núcleos de controlador no IR do Azure. Está em curso uma resolução para esta limitação.
- Cada unidade ou pacote na transação SAP ODQMON é um único ficheiro na pasta de teste.
Considerações de conceção ao executar os pipelines com a CDC
Verifique o SAP para a duração da fase.
Verifique o desempenho do runtime no sink.
Considere utilizar a funcionalidade de criação de partições para melhorar o desempenho para um melhor débito.
Se a duração do SAP para fase for lenta, considere redimensionar o SHIR para especificações mais elevadas.
Verifique se o tempo de processamento do sink é demasiado lento.
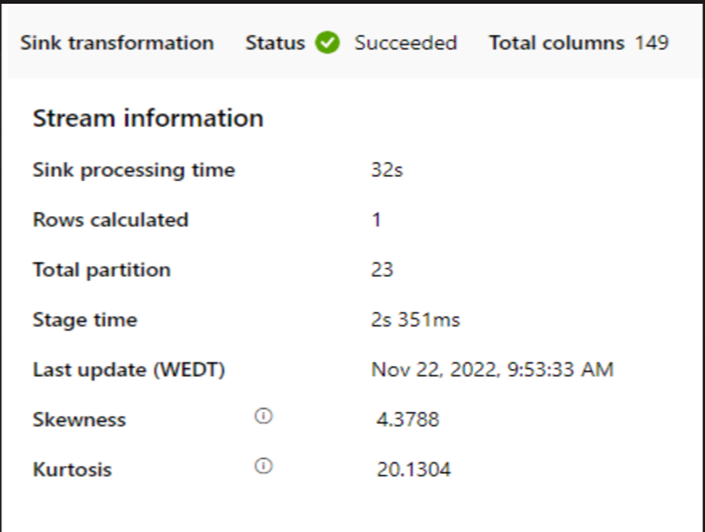
Se um pequeno cluster for utilizado para executar o fluxo de dados de mapeamento, pode afetar o desempenho no sink. Utilize um cluster grande, por exemplo, 16 + 256 núcleos, para que o índice leia os dados da fase e escreva no sink.
Para grandes volumes de dados, recomendamos a criação de partições da carga para executar tarefas paralelas, mas mantenha o número de partições menor ou igual ao núcleo do Azure IR, também denominado núcleo de cluster do Spark.
Utilize o separador Otimizar para definir as partições. Pode utilizar a criação de partições de origem no conector CDC.
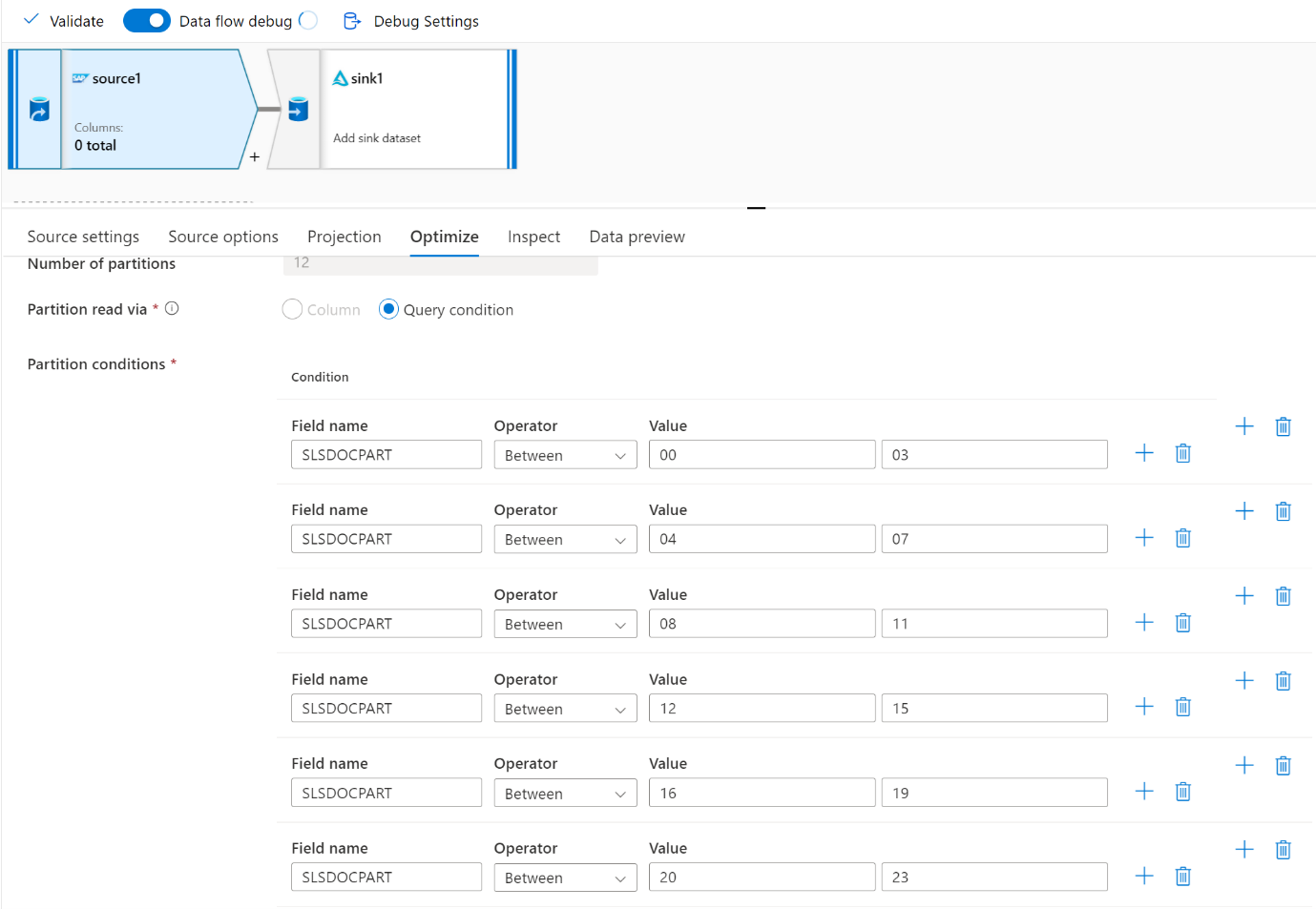
Nota
- Existe uma correlação direta entre o número de partições com núcleos SHIR e nós do Azure IR.
- O conector DO SAP CDC está listado como o tipo de subscritor Odata "Acesso Odata para Aprovisionamento de Dados Operacionais" em ODQMON no sistema SAP.
Considerações de conceção ao utilizar um conector de Tabelas
- Otimize a criação de partições para um melhor desempenho.
- Considere o grau de paralelismo da Tabela SAP.
- Considere uma estrutura de ficheiro única para o sink de destino.
- Faça uma referência ao débito quando utiliza grandes volumes de dados.
Conceber recomendações ao utilizar um conector de Tabelas
Partição: Quando cria partições no conector da Tabela SAP, esta divide uma instrução seletiva subjacente em várias ao utilizar o local onde as cláusulas estão num campo adequado, por exemplo, um campo com cardinalidade elevada. Se a tabela SAP tiver um grande volume de dados, ative a criação de partições para dividir os dados em partições mais pequenas. Tente otimizar o número de partições (parâmetro
maxPartitionsNumber) para que as partições sejam pequenas o suficiente para evitar capturas de memória no SAP, mas suficientemente grandes para acelerar a extração.Paralelismo: O grau de paralelismo de cópia (parâmetro
parallelCopies) funciona em conjunto com a criação de partições e instrui o SHIR a fazer chamadas RFC paralelas para o sistema SAP. Por exemplo, se definir este parâmetro como 4, o serviço gera e executa simultaneamente quatro consultas com base na opção e definições de partição especificadas. Cada consulta obtém uma parte dos dados da tabela SAP.Para obter resultados ideais, o número de partições deve ser um múltiplo do número do grau de paralelismo de cópia.
Quando copia dados da Tabela SAP para sinks binários, a contagem paralela real é ajustada automaticamente com base na quantidade de memória disponível no SHIR. Registe o tamanho da VM SHIR para cada ciclo de teste, o grau de paralelismo de cópia e o número de partições. Observe o desempenho da VM SHIR, o desempenho do sistema SAP de origem e o grau de paralelismo pretendido vs. o grau real de paralelismo. Utilize um processo iterativo para identificar as definições ideais e o tamanho ideal para a VM SHIR. Considere todos os pipelines de ingestão que carregam simultaneamente dados de um ou vários sistemas SAP.
Tenha em atenção o número observado de chamadas RFC para SAP relativamente ao grau de paralelismo configurado. Se o número de chamadas RFC para SAP for inferior ao grau de paralelismo, verifique se a VM SHIR tem memória e recursos de CPU suficientes disponíveis. Se necessário, selecione uma máquina virtual maior. O sistema SAP de origem está configurado para limitar o número de ligações paralelas. Para obter mais informações, veja a secção Recomendações gerais neste artigo.
Número de ficheiros: Quando copia dados para um arquivo de dados baseado em ficheiros e o sink de destino é configurado para ser uma pasta, são gerados vários ficheiros por predefinição. Se definir a
fileNamepropriedade no sink, os dados são escritos num único ficheiro. Recomenda-se que escreva numa pasta como múltiplos ficheiros porque obtém um débito de escrita mais elevado em comparação com a escrita num único ficheiro.Referência de desempenho: Recomendamos que utilize o exercício de benchmarking de desempenho para ingerir grandes quantidades de dados. Este método varia os parâmetros, como a criação de partições, o grau de paralelismo e o número de ficheiros para determinar a definição ideal para a determinada arquitetura, volume e tipo de dados. Recolha dados de testes no seguinte formato.


Resolução de problemas
Para a extração lenta ou com falhas do sistema SAP, utilize os registos SAP do SM37 e corresponda-os às leituras no Data Factory.
Se apenas uma tarefa de lote for acionada, defina as partições de origem SAP para melhorar o desempenho no fluxo de dados de mapeamento no Data Factory. Para obter mais informações, veja o passo 6 nas propriedades do fluxo de dados de mapa.
Se forem acionadas várias tarefas de lote no sistema SAP e existir uma diferença significativa entre a hora de início de cada tarefa de lote, altere o tamanho do Azure IR. Quando aumenta o número de nós de controlador no Azure IR, o paralelismo das tarefas em lote no lado do SAP aumenta.
Nota
O número máximo de nós de controlador para o Azure IR é 16. Cada nó de controlador só pode acionar um processo de lote.
Verifique os registos no SHIR. Para ver os registos, aceda a VM SHIR. Abra o Runtime de Integração de Aplicações e registos de serviços do Visualizador > de Eventos >> .
Para enviar registos para suporte, aceda à VM SHIR. Abra os Registos de Envio de Diagnósticos > do gestor > de configuração do Integration Runtime. Esta ação envia os registos dos últimos sete dias e fornece-lhe um ID de relatório. Precisa deste ID do relatório e do RunId da sua execução. Documente o ID do relatório para referência futura.
Quando utiliza o conector SAP CDC num cenário SLT:
Certifique-se de que os pré-requisitos são cumpridos. As funções são necessárias para o utilizador sap Landscape Transformation (SLT), por exemplo ADFSLTUSER em sistemas OLTP ou ECC para que a replicação SLT funcione. Para obter mais informações, veja Que autorizações e funções são necessárias.
Se ocorrerem erros num cenário SLT, veja as recomendações para análise. Isole e teste primeiro o cenário na solução SAP. Por exemplo, teste-o fora do Data Factory ao executar o programa de teste fornecido pelo SAP
RODPS_REPL_TESTno SE38. Se o problema estiver do lado do SAP, receberá o mesmo erro quando utiliza o relatório. Pode analisar a extração de dados no SAP com o códigoODQMONde transação .Se a replicação funcionar quando utiliza este relatório de teste, mas não com o Data Factory, contacte o suporte do Azure ou do Data Factory.
O exemplo seguinte mostra um relatório para
RODPS_REPL_TESTno SE38: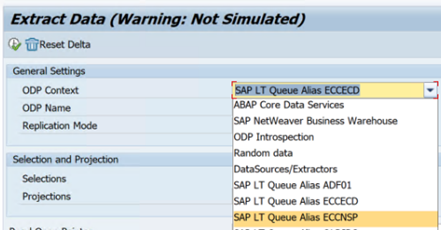
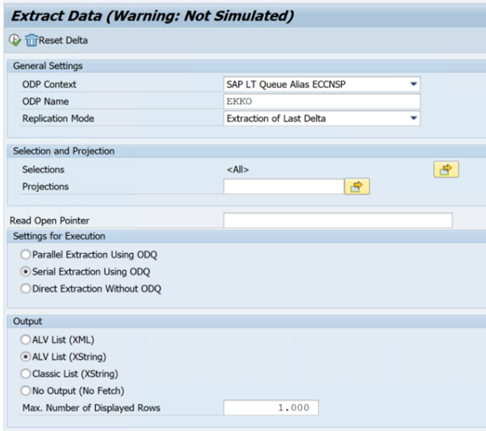

O exemplo seguinte mostra o código
ODQMONde transação: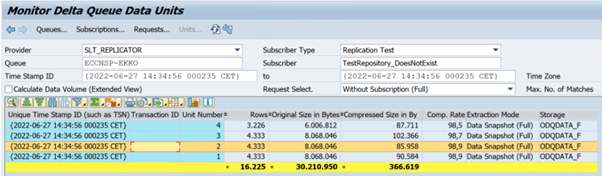
Quando o serviço ligado do Data Factory se liga ao sistema SLT, não mostra os IDs de transferência em massa do SLT quando atualiza o campo Contexto .
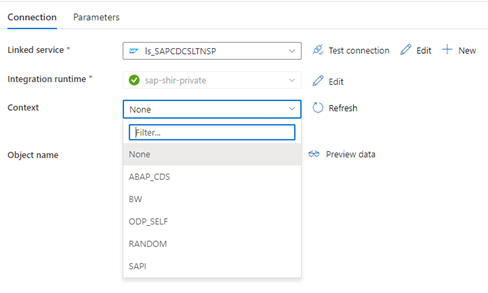
Para executar o cenário de replicação ODP/ODQ para o Servidor de Replicação SAP LT, ative a seguinte implementação do suplemento empresarial (BAdI).
BAdI:
BADI_ODQ_QUEUE_MODELImplementação de melhoramento:
ODQ_ENH_SLT_REPLICATIONNa transação LTRC, aceda ao separador Função de Especialista e selecione Ativar/Desativar Implementação do BAdI para ativar a implementação.
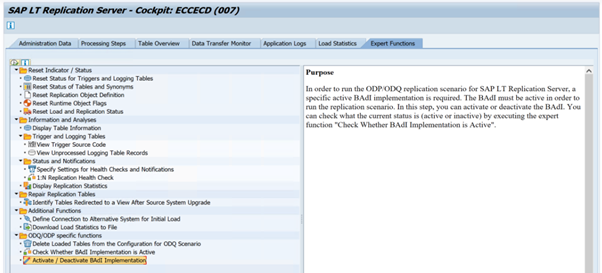
Selecione Yes (Sim).
Na pasta funções específicas ODQ/ODP , selecione Verificar se a Implementação do BAdI está Ativa.

A caixa de diálogo mostra a atividade do programa.
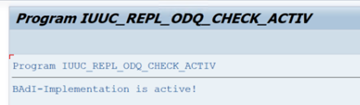
Repor subscrições. Para começar com uma nova extração ou parar os dados de replicação, remova a subscrição no ODQMON. Esta ação também remove as entradas da LTRC. Depois de repor a subscrição, poderá demorar alguns minutos até ver o efeito na LTRC. Agendar tarefas de limpeza do Aprovisionamento de Dados Operacionais (ODP) para manter as filas delta limpas, por exemplo
ODQ_CLEANUP_CLIENT_004CDS_VIEW (transação DHCDCMON). A partir de S/4HANA 1909, o SAP replica dados de vistas CDS que utilizam acionadores baseados em dados em vez de colunas de data. O conceito é semelhante ao SLT, mas em vez de utilizar a transação LTRC para monitorizá-lo, utiliza a transação DHCDCMON.
Resolução de problemas do SLT
O Servidor de Replicação SLT fornece replicação de dados em tempo real a partir de origens SAP e/ou origens não SAP para destinos SAP e/ou destinos não SAP. Existem três tipos de conjuntos de ferramentas para monitorizar a extração do SLT para o Azure.
- O ODQMON é a ferramenta de monitorização geral para a extração de dados. Inicie a análise com o ODQMON para controlar inconsistências de dados, análise de desempenho inicial e pedidos de subscrição e extração abertos.
- LTRC é a transação a utilizar para verificar a análise de desempenho. É útil se tiver problemas de replicação de dados do sistema de origem para o ODP, porque pode monitorizar o fluxo de dados e encontrar inconsistências.
- O SM37 fornece monitorização detalhada de cada passo de extração de SLT.
A limpeza normal deve ser feita com o ODQMON, onde pode gerir a subscrição diretamente e não deve utilizar LTRC para o mesmo.
Poderá encontrar problemas ao extrair dados do SLT, tais como:
A extração não é executada. Verifique se a ligação DO SAP CDC criou uma ligação no ODQMON e verifique se a subscrição existe.
Inconsistências de dados. Verifique o ODQMON para ver o pedido individual de dados e confirme que pode ver os dados aí. Se conseguir ver os dados no ODQMON, mas não no Azure Synapse ou no Data Factory, a investigação deverá ocorrer no lado do Azure. Se não conseguir ver os dados no ODQMON, faça uma análise da arquitetura SLT com LTRC.
Problemas de desempenho. A extração de dados é uma abordagem de dois passos. Primeiro, o SLT lê os dados do sistema de origem e transfere-os para o ODP. Em segundo lugar, o conector SAP CDC recolhe os dados do ODP e transfere-os para o arquivo de dados escolhido. A transação LTRC permite-lhe analisar a primeira parte do processo de extração. Para analisar a extração de dados do ODP para o Azure, utilize as ferramentas de monitorização ODQMON e Data Factory ou Synapse.
Nota
Para obter mais informações, veja estes recursos:
Desempenho do SLT
No modo de carregamento inicial (ODPSLT), existem três passos para extrair dados do SLT para o ODP:
- Criar objetos de migração. Este processo demora apenas alguns segundos.
- Aceda ao cálculo do plano que divide a tabela de origem em segmentos mais pequenos. Este passo depende do modo de carga inicial que selecionar durante a configuração SLT e o tamanho da tabela. A opção otimizada para recursos é recomendada.
- A carga de dados transfere os dados do sistema de origem para o ODP.
Cada passo é controlado pelas tarefas em segundo plano. Pode utilizar as transações SM37 e LTRC para monitorizar a duração. Se o seu sistema estiver sobreutilizado, as tarefas em segundo plano poderão começar mais tarde porque não existem processos de trabalho em lotes gratuitos suficientes. Quando as tarefas estão inativas, o desempenho sofre.
Se o cálculo do plano de acesso demorar muito tempo e o modo de carga inicial estiver definido como "otimizado para o desempenho", altere-o para "otimizado para recursos" e execute novamente a extração. Se a carga de dados demorar muito tempo, aumente o número de threads paralelos na configuração.
Se utilizar uma arquitetura autónoma para a replicação SLT (servidor de replicação SLT dedicado), o débito de rede entre o sistema de origem e o servidor de replicação poderá afetar o desempenho da extração.
Para replicação:
- Certifique-se de que tem tarefas de transferência de dados suficientes que não estão reservadas para a carga inicial.
- Verifique se não tem um registo de tabela de registo não processado nas estatísticas de carga.
- Certifique-se de que a opção de replicação está definida como em tempo real.
As definições avançadas de replicação estão disponíveis no LTRS. Para obter mais informações, veja o guia de resolução de problemas do SLT.
As diferentes versões SAP têm interfaces de utilizador LTRC diferentes. As capturas de ecrã seguintes mostram a mesma página para duas versões diferentes.
SAP S/4HANA:

SAP ECC:



Monitor
Para obter informações sobre como monitorizar a extração de dados SAP, veja estes recursos:
Passos seguintes
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários