Distribuição global de dados com o Azure Cosmos DB - nos bastidores
APLICA-SE A: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Tabela
Tabela
O Azure Cosmos DB é um serviço fundamental no Azure, por isso é implantado em todas as regiões do Azure em todo o mundo, incluindo nuvens públicas, soberanas, do Departamento de Defesa (DoD) e governamentais.
Em um alto nível, os dados de contêiner do Azure Cosmos DB são particionados horizontalmente em muitos conjuntos de réplicas, que replicam gravações, em cada região. Conjuntos de réplicas confirmam gravações de forma durável usando um quórum majoritário.
Cada região contém todas as partições de dados de um contêiner do Azure Cosmos DB e pode servir leituras, bem como servir gravações quando as gravações de várias regiões estão habilitadas. Se sua conta do Azure Cosmos DB estiver distribuída em N regiões do Azure, haverá pelo menos N x 4 cópias de todos os seus dados.
Dentro de um data center, implantamos e gerenciamos o Azure Cosmos DB em grandes carimbos de máquinas, cada uma com armazenamento local dedicado. Dentro de um data center, o Azure Cosmos DB é implantado em muitos clusters, cada um potencialmente executando várias gerações de hardware. As máquinas dentro de um cluster normalmente estão espalhadas por 10 a 20 domínios de falha para alta disponibilidade dentro de uma região. A imagem a seguir mostra a topologia do sistema de distribuição global do Azure Cosmos DB:
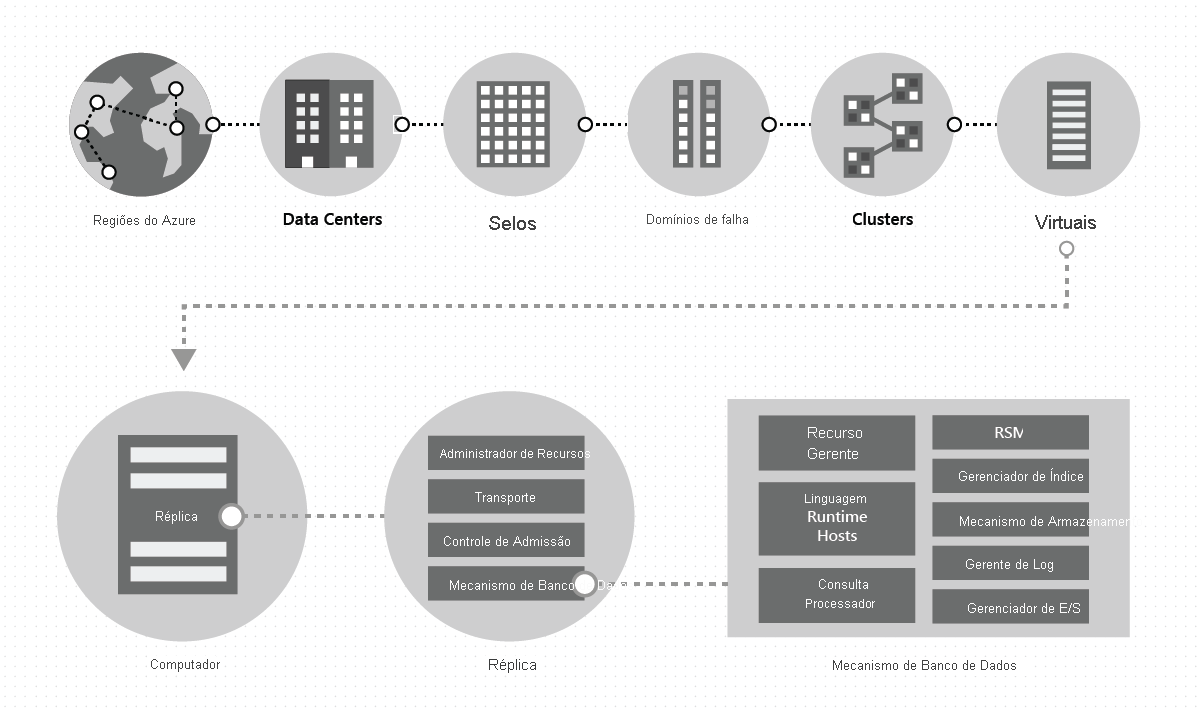
A distribuição global no Azure Cosmos DB é chave na mão: a qualquer momento, com alguns cliques ou programaticamente com uma única chamada de API, você pode adicionar ou remover as regiões geográficas associadas ao seu banco de dados do Azure Cosmos DB. Um banco de dados do Azure Cosmos DB, por sua vez, consiste em um conjunto de contêineres do Azure Cosmos DB. No Azure Cosmos DB, os contêineres servem como unidades lógicas de distribuição e escalabilidade. As coleções, tabelas e gráficos que você cria são (internamente) apenas contêineres do Azure Cosmos DB. Os contêineres são completamente independentes do esquema e fornecem um escopo para uma consulta. Os dados em um contêiner do Azure Cosmos DB são indexados automaticamente após a ingestão. A indexação automática permite que os usuários consultem os dados sem os incômodos do gerenciamento de esquema ou índice, especialmente em uma configuração distribuída globalmente.
Em uma determinada região, os dados dentro de um contêiner são distribuídos usando uma chave de partição, que você fornece e é gerenciada de forma transparente pelas partições físicas subjacentes (distribuição local).
Cada partição física também é replicada entre regiões geográficas (distribuição global).
Quando um aplicativo que usa o Azure Cosmos DB dimensiona elasticamente a taxa de transferência em um contêiner do Azure Cosmos DB ou consome mais armazenamento, o Azure Cosmos DB lida de forma transparente com operações de gerenciamento de partição (dividir, clonar, excluir) em todas as regiões. Independentemente da escala, distribuição ou falhas, o Azure Cosmos DB continua a fornecer uma única imagem de sistema dos dados dentro dos contêineres, que são distribuídos globalmente em qualquer número de regiões.
Como mostrado na imagem a seguir, os dados dentro de um contêiner são distribuídos em duas dimensões - dentro de uma região e entre regiões, em todo o mundo:
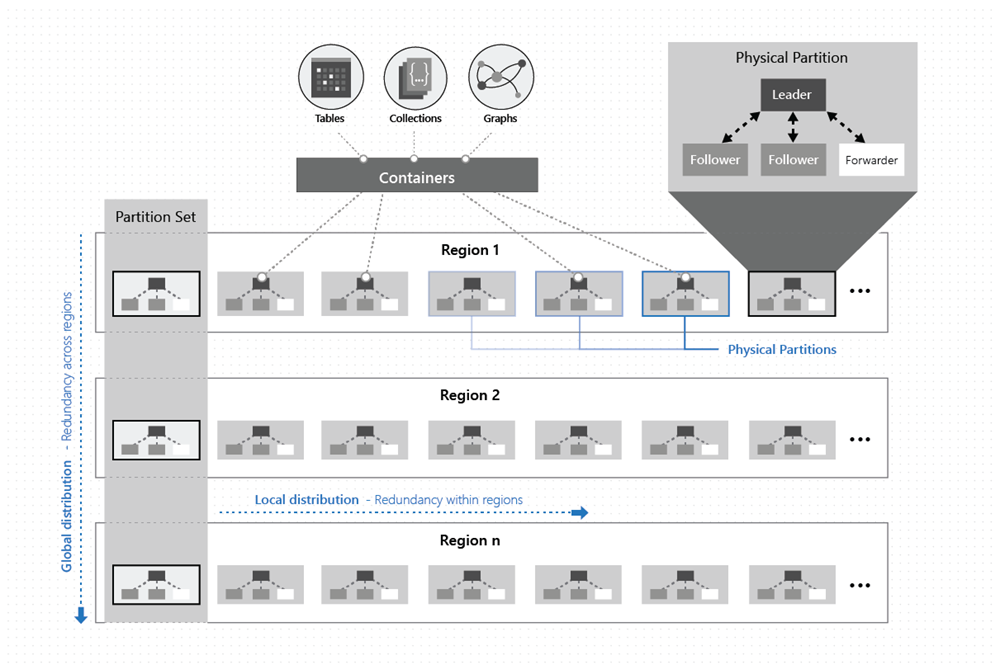
Uma partição física é implementada por um grupo de réplicas, chamado de conjunto de réplicas. Cada máquina hospeda centenas de réplicas que correspondem a várias partições físicas dentro de um conjunto fixo de processos, como mostrado na imagem acima. As réplicas correspondentes às partições físicas são colocadas dinamicamente e a carga balanceada entre as máquinas dentro de um cluster e data centers dentro de uma região.
Uma réplica pertence exclusivamente a um locatário do Azure Cosmos DB. Cada réplica hospeda uma instância do mecanismo de banco de dados do Azure Cosmos DB, que gerencia os recursos, bem como os índices associados. O mecanismo de banco de dados do Azure Cosmos DB opera em um sistema de tipo baseado em ARS (atom-record-sequence). O mecanismo é agnóstico ao conceito de um esquema, borrando a fronteira entre a estrutura e os valores de instância dos registros. O Azure Cosmos DB alcança o agnosticismo de esquema completo indexando automaticamente tudo após a ingestão de uma maneira eficiente, o que permite que os usuários consultem seus dados distribuídos globalmente sem ter que lidar com o gerenciamento de esquema ou índice.
O mecanismo de banco de dados do Azure Cosmos DB consiste em componentes, incluindo a implementação de várias primitivas de coordenação, tempos de execução de linguagem, o processador de consultas e os subsistemas de armazenamento e indexação responsáveis pelo armazenamento transacional e indexação de dados, respectivamente. Para fornecer durabilidade e alta disponibilidade, o mecanismo de banco de dados persiste seus dados e índice em SSDs e os replica entre as instâncias do mecanismo de banco de dados dentro do(s) conjunto(s) de réplicas, respectivamente. Locatários maiores correspondem a uma escala maior de taxa de transferência e armazenamento e têm réplicas maiores ou mais ou ambas. Cada componente do sistema é totalmente assíncrono – nenhum thread nunca bloqueia, e cada thread faz um trabalho de curta duração sem incorrer em switches de thread desnecessários. A limitação de taxa e a contrapressão são canalizadas em toda a pilha, desde o controle de admissão até todos os caminhos de E/S. O mecanismo de banco de dados do Azure Cosmos DB foi projetado para explorar simultaneidade refinada e fornecer alta taxa de transferência enquanto opera com quantidades frugais de recursos do sistema.
A distribuição global do Azure Cosmos DB depende de duas abstrações principais: conjuntos de réplicas e conjuntos de partições. Um conjunto de réplicas é um bloco modular de Lego para coordenação, e um conjunto de partições é uma sobreposição dinâmica de uma ou mais partições físicas geograficamente distribuídas. Para entender como funciona a distribuição global, precisamos entender essas duas abstrações fundamentais.
Conjuntos de réplicas
Uma partição física é materializada como um grupo de réplicas autogerenciado e com balanceamento dinâmico de carga espalhadas por vários domínios de falha, chamado de conjunto de réplicas. Esse conjunto implementa coletivamente o protocolo de máquina de estado replicado para tornar os dados dentro da partição física altamente disponíveis, duráveis e consistentes. A associação do conjunto de réplicas N é dinâmica – ela continua flutuando entre NMin e NMax com base nas falhas, nas operações administrativas e no tempo para as réplicas com falha se regenerarem/recuperarem. Com base nas alterações de associação, o protocolo de replicação também reconfigura o tamanho dos quóruns de leitura e gravação. Para distribuir uniformemente a taxa de transferência atribuída a uma determinada partição física, empregamos duas ideias:
Primeiro, o custo de processar as solicitações de gravação no líder é maior do que o custo de aplicar as atualizações no seguidor. Correspondentemente, o líder é orçado mais recursos do sistema do que os seguidores.
Em segundo lugar, na medida do possível, o quórum de leitura para um determinado nível de consistência é composto exclusivamente pelas réplicas dos seguidores. Evitamos entrar em contato com o líder para servir leituras, a menos que necessário. Empregamos várias ideias da pesquisa feita sobre a relação de carga e capacidade nos sistemas baseados em quórum para os cinco modelos de consistência suportados pelo Azure Cosmos DB.
Conjuntos de partições
Um grupo de partições físicas, uma de cada uma das regiões de banco de dados do Azure Cosmos DB, é composto para gerenciar o mesmo conjunto de chaves replicadas em todas as regiões configuradas. Esta primitiva de coordenação superior é chamada de conjunto de partições - uma sobreposição dinâmica geograficamente distribuída de partições físicas gerenciando um determinado conjunto de chaves. Enquanto uma determinada partição física (um conjunto de réplicas) tem o escopo dentro de um cluster, um conjunto de partições pode abranger clusters, data centers e regiões geográficas, conforme mostrado na imagem abaixo:
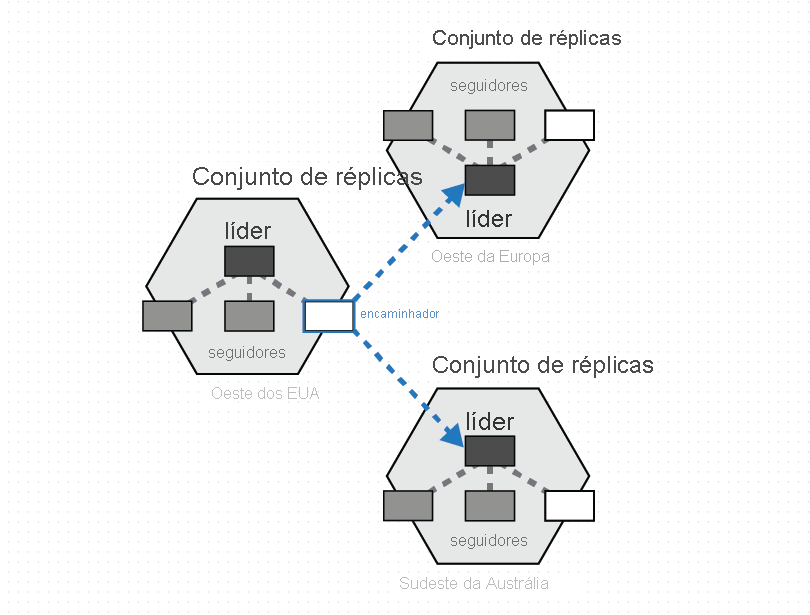
Você pode pensar em um conjunto de partições como um "super conjunto de réplicas" geograficamente disperso, que é composto por vários conjuntos de réplicas que possuem o mesmo conjunto de chaves. Semelhante a um conjunto de réplicas, a associação de um conjunto de partições também é dinâmica – flutua com base em operações implícitas de gerenciamento de partições físicas para adicionar/remover novas partições de/para um determinado conjunto de partições (por exemplo, quando você dimensiona a taxa de transferência em um contêiner, adiciona/remove uma região ao seu banco de dados do Azure Cosmos DB ou quando ocorrem falhas). Em virtude de ter cada uma das partições (de um conjunto de partições) gerenciar a associação do conjunto de partições dentro de seu próprio conjunto de réplicas, a associação é totalmente descentralizada e altamente disponível. Durante a reconfiguração de um conjunto de partições, a topologia da sobreposição entre partições físicas também é estabelecida. A topologia é selecionada dinamicamente com base no nível de consistência, distância geográfica e largura de banda de rede disponível entre as partições físicas de origem e de destino.
O serviço permite que você configure seus bancos de dados do Azure Cosmos DB com uma única região de gravação ou várias regiões de gravação e, dependendo da escolha, os conjuntos de partições são configurados para aceitar gravações em exatamente uma ou em todas as regiões. O sistema emprega um protocolo de consenso aninhado de dois níveis – um nível opera dentro das réplicas de um conjunto de réplicas de uma partição física aceitando as gravações, e o outro opera no nível de um conjunto de partições para fornecer garantias completas de ordenação para todas as gravações confirmadas dentro do conjunto de partições. Esse consenso aninhado em várias camadas é fundamental para a implementação de nossos SLAs rigorosos para alta disponibilidade, bem como para a implementação dos modelos de consistência que o Azure Cosmos DB oferece a seus clientes.
Resolução de conflitos
Nosso design para a propagação de atualizações, resolução de conflitos e rastreamento de causalidade é inspirado no trabalho anterior sobre algoritmos epidêmicos e o sistema Bayou. Embora os núcleos das ideias tenham sobrevivido e forneçam um quadro de referência conveniente para comunicar o design do sistema do Azure Cosmos DB, eles também sofreram uma transformação significativa à medida que os aplicamos ao sistema Azure Cosmos DB. Isso era necessário, porque os sistemas anteriores não foram projetados nem com a governança de recursos nem com a escala na qual o Azure Cosmos DB precisa operar, nem para fornecer os recursos (por exemplo, consistência de obsoletos limitados) e os SLAs rigorosos e abrangentes que o Azure Cosmos DB oferece aos seus clientes.
Lembre-se de que um conjunto de partições é distribuído em várias regiões e segue o protocolo de replicação do Azure Cosmos DB (gravações de várias regiões) para replicar os dados entre as partições físicas que compõem um determinado conjunto de partições. Cada partição física (de um conjunto de partições) aceita gravações e serve leituras normalmente para os clientes que são locais para essa região. As gravações aceitas por uma partição física dentro de uma região são comprometidas de forma durável e altamente disponíveis dentro da partição física antes de serem reconhecidas ao cliente. Estas são gravações provisórias e são propagadas para outras partições físicas dentro do conjunto de partições usando um canal anti-entropia. Os clientes podem solicitar gravações provisórias ou confirmadas passando um cabeçalho de solicitação. A propagação anti-entropia (incluindo a frequência de propagação) é dinâmica, baseada na topologia do conjunto de partições, na proximidade regional das partições físicas e no nível de consistência configurado. Dentro de um conjunto de partições, o Azure Cosmos DB segue um esquema de confirmação primário com uma partição de árbitro selecionada dinamicamente. A seleção do árbitro é dinâmica e é parte integrante da reconfiguração do conjunto de partições com base na topologia da sobreposição. As gravações confirmadas (incluindo atualizações de várias linhas/lotes) têm a garantia de serem encomendadas.
Empregamos relógios vetoriais codificados (contendo ID de região e relógios lógicos correspondentes a cada nível de consenso no conjunto de réplicas e partições, respectivamente) para rastreamento de causalidade e vetores de versão para detetar e resolver conflitos de atualização. A topologia e o algoritmo de seleção de pares são projetados para garantir armazenamento fixo e mínimo e sobrecarga de rede mínima de vetores de versão. O algoritmo garante a propriedade de convergência estrita.
Para os bancos de dados do Azure Cosmos DB configurados com várias regiões de gravação, o sistema oferece várias políticas flexíveis de resolução automática de conflitos para os desenvolvedores escolherem, incluindo:
- Last-Write-Wins (LWW), que, por padrão, usa uma propriedade timestamp definida pelo sistema (que se baseia no protocolo de relógio de sincronização de tempo). O Azure Cosmos DB também permite especificar qualquer outra propriedade numérica personalizada a ser usada para resolução de conflitos.
- Política de resolução de conflitos definida pelo aplicativo (personalizada) (expressa por meio de procedimentos de mesclagem), que é projetada para a reconciliação semântica de conflitos definida pelo aplicativo. Esses procedimentos são invocados após a deteção dos conflitos de gravação-gravação sob os auspícios de uma transação de banco de dados no lado do servidor. O sistema fornece exatamente uma garantia única para a execução de um procedimento de fusão como parte do protocolo de compromisso. Há vários exemplos de resolução de conflitos disponíveis para você jogar.
Modelos de consistência
Se você configurar seu banco de dados do Azure Cosmos DB com uma única ou várias regiões de gravação, poderá escolher entre os cinco modelos de consistência bem definidos. Com várias regiões de gravação, a seguir estão alguns aspetos notáveis dos níveis de consistência:
A consistência de obsoletamento delimitado garante que todas as leituras estarão dentro de prefixos K ou segundos T a partir da última gravação em qualquer uma das regiões. Além disso, leituras com consistência de obsoletos limitados são garantidamente monotônicas e com garantias de prefixo consistentes. O protocolo anti-entropia opera de forma limitada e garante que os prefixos não se acumulem e a contrapressão sobre as gravações não precise ser aplicada. A consistência da sessão garante leitura monotônica, escrita monotônica, leitura de suas próprias gravações, gravação após leitura e garantias de prefixo consistentes, em todo o mundo. Para os bancos de dados configurados com forte consistência, os benefícios (baixa latência de gravação, alta disponibilidade de gravação) de várias regiões de gravação não se aplicam, devido à replicação síncrona entre regiões.
A semântica dos cinco modelos de consistência no Azure Cosmos DB é descrita aqui e matematicamente descrita usando especificações TLA+ de alto nível aqui.
Próximos passos
Em seguida, saiba como configurar a distribuição global usando os seguintes artigos:
- Adicionar/remover regiões da sua conta de banco de dados
- Como criar uma política de resolução de conflitos personalizada
- Tentando fazer o planejamento de capacidade para uma migração para o Azure Cosmos DB? Você pode usar informações sobre seu cluster de banco de dados existente para planejamento de capacidade.
- Se tudo o que você sabe é o número de vcores e servidores em seu cluster de banco de dados existente, leia sobre como estimar unidades de solicitação usando vCores ou vCPUs
- Se você souber as taxas de solicitação típicas para sua carga de trabalho de banco de dados atual, leia sobre como estimar unidades de solicitação usando o planejador de capacidade do Azure Cosmos DB
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários