Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A:
![]() MongoDB
MongoDB
O Azure Cosmos DB para MongoDB aproveita os principais recursos de gerenciamento de índice do Azure Cosmos DB. Este artigo se concentra em como adicionar índices usando o Azure Cosmos DB para MongoDB. Os índices são estruturas de dados especializadas que tornam a consulta dos seus dados aproximadamente uma ordem de grandeza mais rápida.
Indexação para o servidor MongoDB versão 3.6 e superior
O servidor Azure Cosmos DB para MongoDB versão 3.6+ indexa automaticamente o _id campo e a chave de estilhaço (apenas em coleções fragmentadas). A API impõe automaticamente a exclusividade do campo por chave de _id estilhaço.
A API para MongoDB se comporta de forma diferente do Azure Cosmos DB para NoSQL, que indexa todos os campos por padrão.
Editando a política de indexação
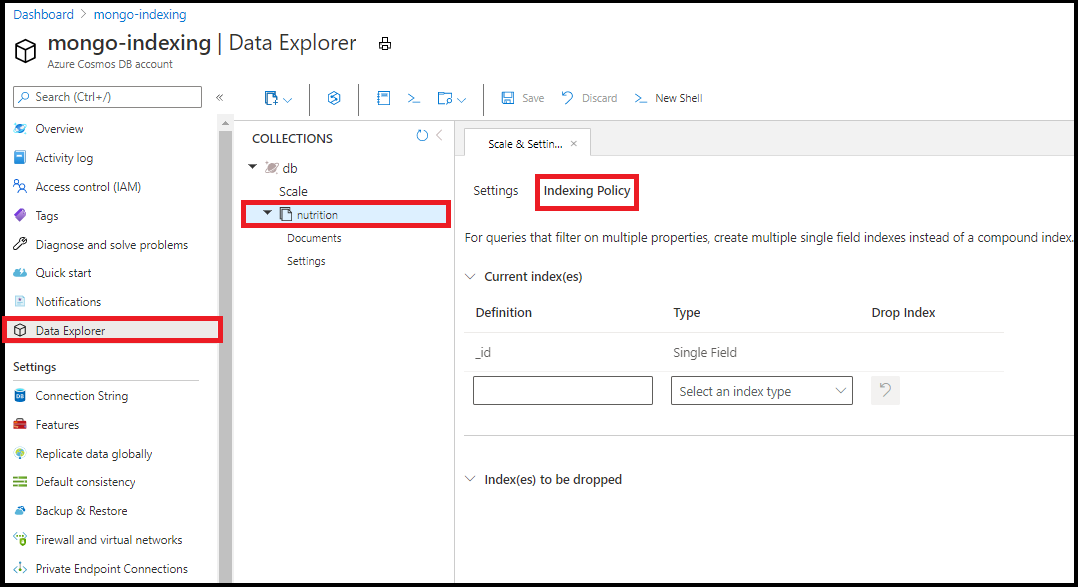
Recomendamos editar sua política de indexação no Data Explorer dentro do portal do Azure. Você pode adicionar índices de campo único e curinga do editor de política de indexação no Data Explorer:
Nota
Não é possível criar índices compostos usando o editor de políticas de indexação no Data Explorer.
Tipos de índice
Campo único
Você pode criar índices em qualquer campo. A ordem de classificação do índice de campo único não importa. O comando a seguir cria um índice no campo name:
db.coll.createIndex({name:1})
Você pode criar o mesmo índice de campo único no name portal do Azure:
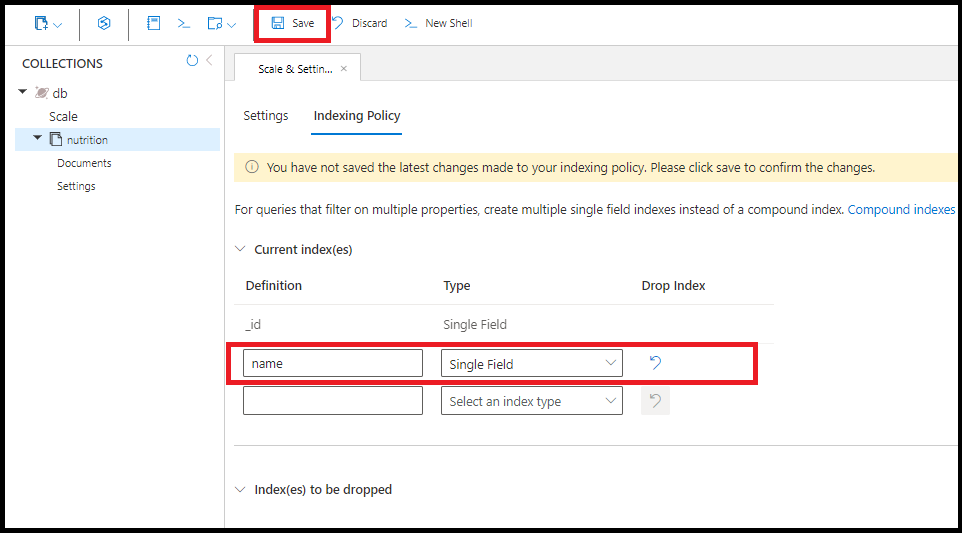
Uma consulta usa vários índices de campo único, quando disponíveis. Você pode criar até 500 índices de campo único por coleção.
Índices compostos (servidor MongoDB versão 3.6+)
Na API para MongoDB, índices compostos são necessários se sua consulta precisar da capacidade de classificar em vários campos de uma só vez. Para consultas com vários filtros que não precisam classificar, crie vários índices de campo único em vez de um índice composto para economizar nos custos de indexação.
Um índice composto ou índices de campo único para cada campo no índice composto resulta no mesmo desempenho para filtragem em consultas.
Os índices compostos em campos aninhados não são suportados por padrão devido a limitações com matrizes. Se o campo aninhado não contiver uma matriz, o índice funcionará como pretendido. Se o campo aninhado contiver uma matriz (em qualquer lugar do caminho), esse valor será ignorado no índice.
Como exemplo, um índice composto contendo people.dylan.age funciona neste caso, uma vez que não há nenhuma matriz no caminho:
{
"people": {
"dylan": {
"name": "Dylan",
"age": "25"
},
"reed": {
"name": "Reed",
"age": "30"
}
}
}
Esse mesmo índice composto não funciona neste caso, pois há uma matriz no caminho:
{
"people": [
{
"name": "Dylan",
"age": "25"
},
{
"name": "Reed",
"age": "30"
}
]
}
Esse recurso pode ser ativado para sua conta de banco de dados ativando o recurso 'EnableUniqueCompoundNestedDocs'.
Nota
Não é possível criar índices compostos em matrizes.
O comando a seguir cria um índice composto nos campos name e age:
db.coll.createIndex({name:1,age:1})
Você pode usar índices compostos para classificar eficientemente em vários campos de uma só vez, conforme mostrado no exemplo a seguir:
db.coll.find().sort({name:1,age:1})
Você também pode usar o índice composto anterior para classificar eficientemente uma consulta com a ordem de classificação oposta em todos os campos. Eis um exemplo:
db.coll.find().sort({name:-1,age:-1})
No entanto, a sequência dos caminhos no índice composto deve corresponder exatamente à consulta. Aqui está um exemplo de uma consulta que exigiria um índice composto adicional:
db.coll.find().sort({age:1,name:1})
Índices multichave
O Azure Cosmos DB cria índices de várias chaves para indexar conteúdo armazenado em matrizes. Se você indexar um campo com um valor de matriz, o Azure Cosmos DB indexará automaticamente todos os elementos da matriz.
Índices geoespaciais
Muitos operadores geoespaciais beneficiarão de índices geoespaciais. Atualmente, o Azure Cosmos DB para MongoDB dá suporte a 2dsphere índices. A API ainda não suporta 2d índices.
Aqui está um exemplo de criação de um índice geoespacial no location campo:
db.coll.createIndex({ location : "2dsphere" })
Índices de texto
Atualmente, o Azure Cosmos DB para MongoDB não oferece suporte a índices de texto. Para consultas de pesquisa de texto em cadeias de caracteres, você deve usar a integração do Azure AI Search com o Azure Cosmos DB.
Índices curinga
Você pode usar índices curinga para suportar consultas sobre campos desconhecidos. Vamos imaginar que você tem uma coleção que contém dados sobre famílias.
Aqui está parte de um documento de exemplo nessa coleção:
"children": [
{
"firstName": "Henriette Thaulow",
"grade": "5"
}
]
Aqui está outro exemplo, desta vez com um conjunto ligeiramente diferente de propriedades em children:
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"pets": [
{ "givenName": "Goofy" },
{ "givenName": "Shadow" }
]
},
{
"familyName": "Merriam",
"givenName": "John",
}
]
Nesta coleção, os documentos podem ter muitas propriedades possíveis diferentes. Se quiser indexar todos os dados na children matriz, você tem duas opções: criar índices separados para cada propriedade individual ou criar um índice curinga para toda children a matriz.
Criar um índice curinga
O comando a seguir cria um índice coringa em quaisquer propriedades de children:
db.coll.createIndex({"children.$**" : 1})
Ao contrário do MongoDB, os índices curinga podem suportar múltiplos campos nos predicados de consulta. Não haverá diferença no desempenho da consulta se você usar um único índice curinga em vez de criar um índice separado para cada propriedade.
Você pode criar os seguintes tipos de índice usando a sintaxe curinga:
- Campo único
- Geoespacial
Indexação de todas as propriedades
Veja como você pode criar um índice curinga em todos os campos:
db.coll.createIndex( { "$**" : 1 } )
Você também pode criar índices curinga usando o Data Explorer no portal do Azure:
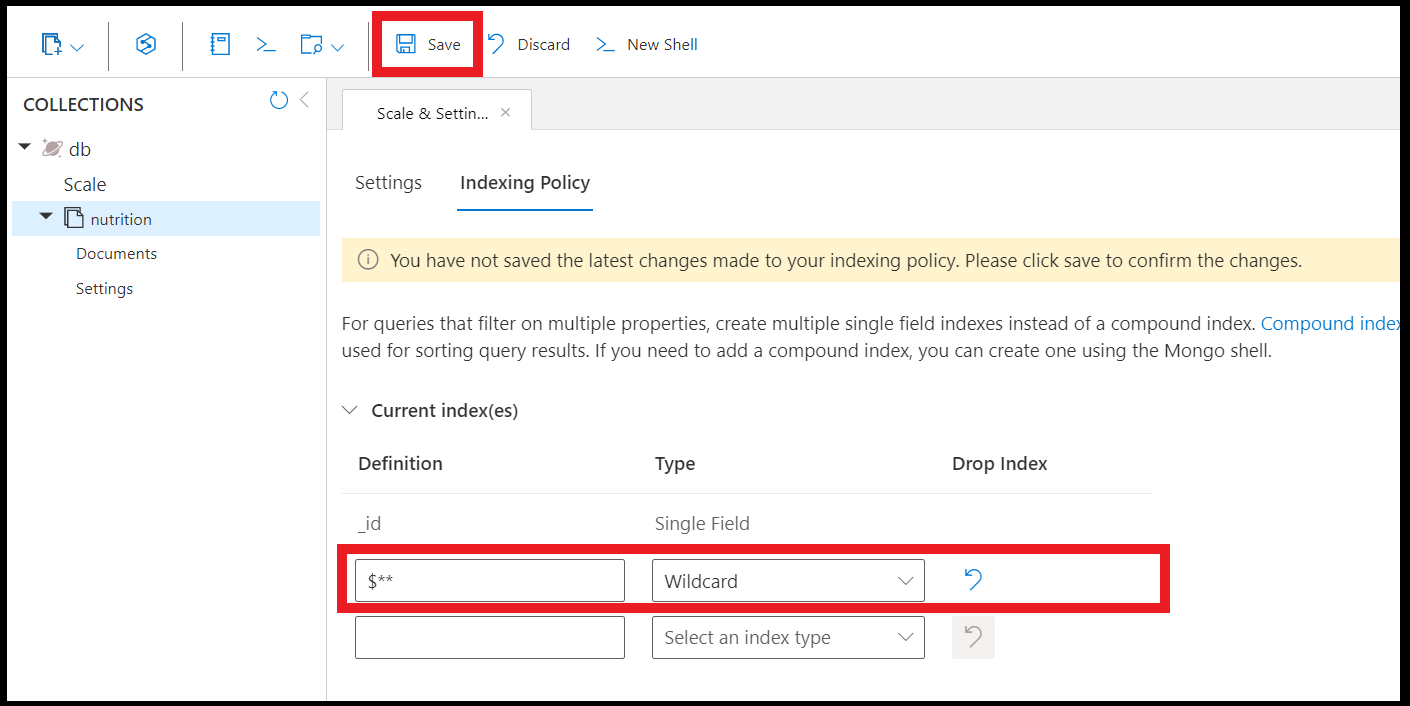
Nota
Se você está apenas começando o desenvolvimento, é altamente recomendável começar com um índice curinga em todos os campos. Isso pode simplificar o desenvolvimento e facilitar a otimização de consultas.
Documentos com muitos campos podem ter uma alta taxa de Unidade de Solicitação (RU) para gravações e atualizações. Portanto, se tiver uma carga de trabalho intensiva em escrita, deve optar por indexar caminhos individualmente em vez de usar índices genéricos.
Limitações
Os índices wildcard não oferecem suporte a nenhum dos seguintes tipos ou propriedades de índice:
- Compostos
- TTL
- Exclusivo
Ao contrário do MongoDB, no Azure Cosmos DB para MongoDB você não pode usar índices curinga para:
Criar um índice curinga que inclui vários campos específicos
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection " : { "children.givenName" : 1, "children.grade" : 1 } } )Criar um índice de carateres universais que exclui vários campos específicos
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection" : { "children.givenName" : 0, "children.grade" : 0 } } )
Como alternativa, pode criar vários índices curinga.
Propriedades do índice
As operações a seguir são comuns para contas que servem o protocolo de transferência versão 4.0 e contas que servem versões anteriores. Você pode saber mais sobre índices suportados e propriedades indexadas.
Índices exclusivos
Os índices exclusivos são úteis para impor que dois ou mais documentos não contenham o mesmo valor para campos indexados.
O comando a seguir cria um índice exclusivo no campo student_id:
globaldb:PRIMARY> db.coll.createIndex( { "student_id" : 1 }, {unique:true} )
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 4
}
Para coleções fragmentadas, deve-se fornecer a chave de fragmento (partição) para criar um índice exclusivo. Em outras palavras, todos os índices exclusivos em uma coleção fragmentada são índices compostos nos quais um dos campos é a chave de fragmentação. O primeiro campo na ordem deve ser a chave de fragmento.
Os comandos a seguir criam uma coleção coll fragmentada (a chave de fragmento é university) com um índice exclusivo nos campos student_id e university:
globaldb:PRIMARY> db.runCommand({shardCollection: db.coll._fullName, key: { university: "hashed"}});
{
"_t" : "ShardCollectionResponse",
"ok" : 1,
"collectionsharded" : "test.coll"
}
globaldb:PRIMARY> db.coll.createIndex( { "university" : 1, "student_id" : 1 }, {unique:true});
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 3,
"numIndexesAfter" : 4
}
No exemplo anterior, omitir a "university":1 cláusula retorna um erro com a seguinte mensagem:
cannot create unique index over {student_id : 1.0} with shard key pattern { university : 1.0 }
Limitações
Índices exclusivos precisam ser criados enquanto a coleção está vazia.
Índices únicos em campos aninhados não são suportados por padrão devido a limitações com matrizes. Se o campo aninhado não contiver uma matriz, o índice funcionará como pretendido. Se o campo aninhado contiver uma matriz (em qualquer lugar do caminho), esse valor será ignorado no índice exclusivo e a exclusividade não será preservada para esse valor.
Por exemplo, um índice exclusivo em people.tom.age funcionará neste caso, uma vez que não há nenhuma matriz no caminho:
{ "people": { "tom": { "age": "25" }, "mark": { "age": "30" } } }
mas não funcionará neste caso, pois há uma matriz no caminho:
{ "people": { "tom": [ { "age": "25" } ], "mark": [ { "age": "30" } ] } }
Esse recurso pode ser ativado para sua conta de banco de dados ativando o recurso 'EnableUniqueCompoundNestedDocs'.
Índices TTL
Para habilitar a expiração de documentos em uma coleção específica, você precisa criar um índice TTL (time-to-live). Um índice TTL é um índice do campo _ts com valor expireAfterSeconds.
Exemplo:
globaldb:PRIMARY> db.coll.createIndex({"_ts":1}, {expireAfterSeconds: 10})
O comando anterior exclui todos os documentos da db.coll coleção que não foram modificados nos últimos 10 segundos.
Nota
O campo _ts é específico do Azure Cosmos DB e não é acessível a partir de clientes MongoDB. É uma propriedade de sistema reservada que contém a timestamp da última modificação do documento.
Acompanhe o progresso do índice
A versão 3.6+ do Azure Cosmos DB com o MongoDB suporta o comando currentOp() para acompanhar o progresso do índice numa instância de base de dados. Este comando retorna um documento que contém informações sobre operações em andamento em uma instância de banco de dados. Você usa o currentOp comando para rastrear todas as operações em andamento no MongoDB nativo. No Azure Cosmos DB para MongoDB, esse comando dá suporte apenas ao controle da operação de índice.
Aqui estão alguns exemplos que mostram como usar o comando para acompanhar o progresso do currentOp índice:
Obtenha o progresso do índice de uma coleção:
db.currentOp({"command.createIndexes": <collectionName>, "command.$db": <databaseName>})Obtenha o progresso do índice para todas as coleções em um banco de dados:
db.currentOp({"command.$db": <databaseName>})Obtenha o progresso do índice para todos os bancos de dados e coleções em uma conta do Azure Cosmos DB:
db.currentOp({"command.createIndexes": { $exists : true } })
Exemplos de resultados de progresso do índice
Os detalhes de progresso do índice mostram a porcentagem de progresso para a operação de índice atual. Aqui está um exemplo que mostra o formato do documento de saída para diferentes estágios do progresso do índice:
Uma operação de índice em uma coleção "foo" e banco de dados "bar" que esteja 60 por cento concluída terá o seguinte documento de saída. O
Inprog[0].progress.totalcampo mostra 100 como a porcentagem de conclusão do alvo.{ "inprog" : [ { ………………... "command" : { "createIndexes" : foo "indexes" :[ ], "$db" : bar }, "msg" : "Index Build (background) Index Build (background): 60 %", "progress" : { "done" : 60, "total" : 100 }, …………..….. } ], "ok" : 1 }Se uma operação de índice tiver acabado de ser iniciada numa coleção "foo" e na base de dados "bar", o documento de saída pode mostrar 0% de progresso até atingir um nível mensurável.
{ "inprog" : [ { ………………... "command" : { "createIndexes" : foo "indexes" :[ ], "$db" : bar }, "msg" : "Index Build (background) Index Build (background): 0 %", "progress" : { "done" : 0, "total" : 100 }, …………..….. } ], "ok" : 1 }Quando a operação de índice em curso termina, o documento de saída apresenta operações vazias
inprog.{ "inprog" : [], "ok" : 1 }
Atualizações de índice em segundo plano
Independentemente do valor especificado para a propriedade Background index, as atualizações de índice são sempre feitas em segundo plano. Como as atualizações de índice consomem Unidades de Solicitação (RUs) com uma prioridade menor do que outras operações de banco de dados, as alterações de índice não resultarão em nenhum tempo de inatividade para gravações, atualizações ou exclusões.
Não há impacto na disponibilidade de leitura ao adicionar um novo índice. As consultas só utilizarão novos índices quando a transformação do índice estiver concluída. Durante a transformação do índice, o mecanismo de consulta continuará a usar índices existentes, portanto, você observará um desempenho de leitura semelhante durante a transformação de indexação ao que você observou antes de iniciar a alteração de indexação. Ao adicionar novos índices, também não há risco de resultados de consulta incompletos ou inconsistentes.
Ao remover índices e executar imediatamente consultas com filtros nos índices descartados, os resultados podem ser inconsistentes e incompletos até que a transformação do índice seja concluída. Se você remover índices, o mecanismo de consulta não fornecerá resultados consistentes ou completos quando as consultas filtrarem esses índices recém-removidos. A maioria dos desenvolvedores não descarta índices e, em seguida, imediatamente tenta consultá-los, portanto, na prática, essa situação é improvável.
Nota
Você pode acompanhar o progresso do índice.
Comando ReIndex
O reIndex comando recriará todos os índices em uma coleção. Em alguns casos raros, o desempenho da consulta ou outros problemas de índice em sua coleção podem ser resolvidos executando o reIndex comando. Se você estiver enfrentando problemas com a indexação, recriar os índices com o reIndex comando é uma abordagem recomendada.
Você pode executar o reIndex comando usando a seguinte sintaxe:
db.runCommand({ reIndex: <collection> })
Você pode usar a sintaxe abaixo para verificar se a execução do comando melhoraria o desempenho da reIndex consulta em sua coleção:
db.runCommand({"customAction":"GetCollection",collection:<collection>, showIndexes:true})
Saída de exemplo:
{
"database" : "myDB",
"collection" : "myCollection",
"provisionedThroughput" : 400,
"indexes" : [
{
"v" : 1,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "myDB.myCollection",
"requiresReIndex" : true
},
{
"v" : 1,
"key" : {
"b.$**" : 1
},
"name" : "b.$**_1",
"ns" : "myDB.myCollection",
"requiresReIndex" : true
}
],
"ok" : 1
}
Se reIndex melhorar o desempenho da consulta, requiresReIndex será true. Se reIndex não melhorar o desempenho da consulta, essa propriedade será omitida.
Migrar coleções com índices
Atualmente, você só pode criar índices exclusivos quando a coleção não contém documentos. As ferramentas de migração populares do MongoDB tentam criar os índices exclusivos depois de importar os dados. Para contornar esse problema, você pode criar manualmente as coleções correspondentes e índices exclusivos em vez de permitir que a ferramenta de migração tente. (Você pode obter esse comportamento usando mongorestore o --noIndexRestore sinalizador na linha de comando.)
Indexação para MongoDB versão 3.2
Os recursos e padrões de indexação disponíveis são diferentes para contas do Azure Cosmos DB que são compatíveis com a versão 3.2 do protocolo de conexão MongoDB. Pode verificar a versão da sua conta e atualizar para a versão 3.6.
Se você estiver usando a versão 3.2, esta seção descreve as principais diferenças com as versões 3.6+.
Descartando índices padrão (versão 3.2)
Ao contrário das versões 3.6+ do Azure Cosmos DB para MongoDB, a versão 3.2 indexa todas as propriedades por padrão. Você pode usar o seguinte comando para descartar esses índices padrão para uma coleção (coll):
> db.coll.dropIndexes()
{ "_t" : "DropIndexesResponse", "ok" : 1, "nIndexesWas" : 3 }
Depois de descartar os índices padrão, você pode adicionar mais índices como faria na versão 3.6+.
Índices compostos (versão 3.2)
Os índices compostos contêm referências a vários campos de um documento. Se você quiser criar um índice composto, atualize para a versão 3.6 ou 4.0.
Índices curinga (versão 3.2)
Se você quiser criar um índice curinga, atualize para a versão 4.0 ou 3.6.
Próximos passos
- Indexação no Azure Cosmos DB
- Expirar dados no Azure Cosmos DB automaticamente com tempo de vida
- Para saber mais sobre a relação entre particionamento e indexação, consulte o artigo Como consultar um contêiner do Azure Cosmos DB.
- Tentando fazer o planejamento de capacidade para uma migração para o Azure Cosmos DB? Você pode usar informações sobre seu cluster de banco de dados existente para planejamento de capacidade.
- Se tudo o que você sabe é o número de vCores e servidores em seu cluster de banco de dados existente, leia sobre como estimar unidades de solicitação usando vCores ou vCPUs
- Se você souber as taxas de solicitação típicas para sua carga de trabalho de banco de dados atual, leia sobre como estimar unidades de solicitação usando o planejador de capacidade do Azure Cosmos DB