Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
A continuidade do negócio e a recuperação de desastres no Azure Data Explorer permitem que o seu negócio continue a operar perante uma disrupção. Este artigo detalha múltiplas configurações de recuperação de desastres dependendo dos requisitos de recuperação (RPO e RTO), do esforço necessário e do custo.
Para mais informações sobre as opções de fiabilidade disponíveis para Azure Data Explorer, incluindo suporte em zonas de disponibilidade, backup e proteção contra alguns tipos de erro humano, consulte Fiabilidade em Azure Data Explorer.
Configurações de recuperação de desastres
O RTO (Recovery Time Objetive, objetivo de tempo de recuperação) refere-se ao tempo de recuperação de uma interrupção. Por exemplo, RTO de 2 horas significa que o aplicativo tem que estar pronto e funcionando dentro de duas horas após uma interrupção. O RPO (Recovery Point Objetive, objetivo de ponto de recuperação) refere-se ao intervalo de tempo que pode passar durante uma interrupção antes que a quantidade de dados perdidos durante esse período seja maior do que o limite permitido. Por exemplo, se o RPO for de 24 horas e um aplicativo tiver dados de 15 anos atrás, eles ainda estarão dentro dos parâmetros do RPO acordado.
Os processos de ingestão, processamento e curadoria precisam de um design diligente inicial ao planejar a recuperação de desastres. Ingestão refere-se a dados integrados no Azure Data Explorer de várias fontes; processamento refere-se a transformações e atividades semelhantes; curadoria refere-se a visualizações materializadas, exportações para o data lake, e assim por diante.
A seguir estão as configurações populares de recuperação de desastres:
- Configuração Active-Active-Active (sempre ativa)
- Configuração Active-Active
- Configuração de standby ativo-hot
- Configuração de cluster de recuperação de dados sob demanda
Configuração ativo-ativo-ativo
Essa configuração também é chamada always-on. Para implementações de aplicações críticas sem tolerância a interrupções, deve usar múltiplos clusters do Azure Data Explorer em regiões emparelhadas do Azure. Configure a ingestão, o processamento e a curadoria em paralelo a todos os clusters. A SKU do cluster deve ser a mesma entre as regiões. O Azure garante que as atualizações são implementadas e escalonadas por regiões emparelhadas com o Azure. Uma falha na região do Azure não causa uma falha na aplicação. Você pode enfrentar alguma latência ou degradação de desempenho.
| Configuration | RPO | RTO | Esforço | Cost |
|---|---|---|---|---|
| Active-Active-Active-n | 0 horas | 0 horas | Mais baixo | Máximo |
Configuração Active-Active
Esta configuração é idêntica à configuração ativo-ativo-ativo, mas envolve apenas duas regiões Azure emparelhadas. Configure a ingestão, o processamento e a curadoria em modo duplo. Os usuários são encaminhados para a região mais próxima. A SKU do cluster deve ser a mesma entre as regiões.
| Configuration | RPO | RTO | Esforço | Cost |
|---|---|---|---|---|
| Ativo-Activo | 0 horas | 0 horas | Mais baixo | High |
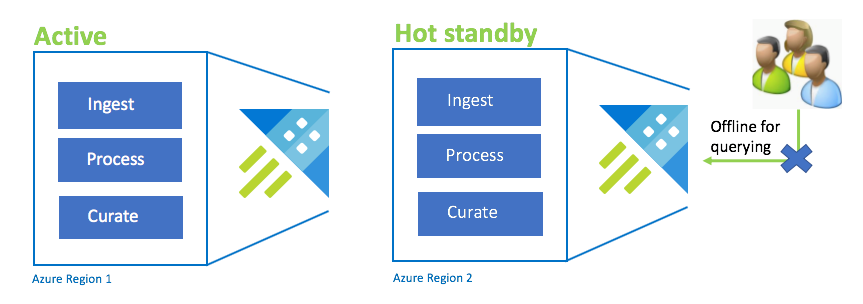
Active-Hot Standby configuração
A configuração Active-Hot é semelhante à configuração Active-Active na ingestão dupla, processamento e curadoria. Embora o cluster em espera esteja online para ingestão, processamento e curadoria, não está disponível para interrogação. O cluster em espera não precisa estar na mesma SKU que o cluster primário. Pode ser de um SKU e escala menores, o que pode resultar em um desempenho menor. Em um cenário de desastre, os usuários são redirecionados para o cluster em espera, que opcionalmente pode ser dimensionado para aumentar o desempenho.
| Configuration | RPO | RTO | Esforço | Cost |
|---|---|---|---|---|
| Active-Hot Standby | 0 horas | Low | Médio | Médio |
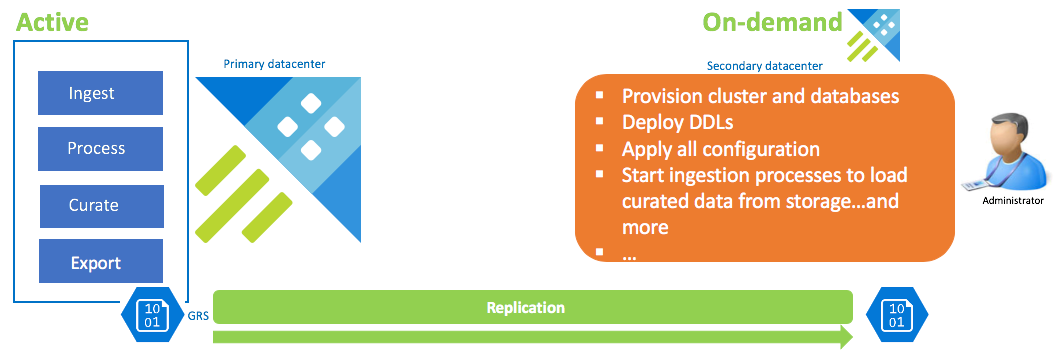
Configuração de recuperação de dados sob demanda
Esta solução oferece a menor capacidade de recuperação (maior RPO e RTO), é a mais baixa em custo e a mais grande em esforço. Nessa configuração, não há cluster de recuperação de dados. Configure a exportação contínua de dados selecionados (a menos que dados brutos e intermediários também sejam necessários) para uma conta de armazenamento configurada GRS (Geo Redundant Storage). Um cluster de recuperação de dados é iniciado se houver um cenário de recuperação de desastres. Neste ponto, as linguagens de definição de dados (DDLs), configurações, políticas e processos são aplicados. Os dados são ingeridos do armazenamento com a propriedade de ingestão kustoCreationTime para substituir o tempo de ingestão padrão pelo tempo do sistema.
| Configuration | RPO | RTO | Esforço | Cost |
|---|---|---|---|---|
| Cluster de recuperação de dados sob demanda | Máximo | Máximo | Máximo | Mais baixo |
Resumo das opções de configuração de recuperação de desastres
| Configuration | Recuperabilidade | RPO | RTO | Esforço | Cost |
|---|---|---|---|---|---|
| Active-Active-Active-n | Máximo | 0 horas | 0 horas | Mais baixo | Máximo |
| Ativo-Activo | High | 0 horas | 0 horas | Mais baixo | High |
| Active-Hot Standby | Médio | 0 horas | Low | Médio | Médio |
| Cluster de recuperação de dados sob demanda | Mais baixo | Máximo | Máximo | Máximo | Mais baixo |
Melhores práticas
Independentemente da configuração de recuperação de desastres escolhida, siga estas práticas recomendadas:
- Todos os objetos, políticas e configurações de banco de dados devem ser mantidos no controle do código-fonte para que possam ser liberados para o cluster a partir da sua ferramenta de automação de versão. Para mais informações, consulte Azure DevOps suporte para Azure Data Explorer.
- Projete, desenvolva e implemente rotinas de validação para garantir que todos os clusters estejam sincronizados de uma perspetiva de dados. Azure Data Explorer suporta cross cluster joins. Uma contagem simples de linhas entre tabelas pode ajudar a validar.
- Os procedimentos de liberação devem envolver verificações e equilíbrios de governança que garantam o espelhamento dos clusters.
- Esteja plenamente ciente do que é necessário para construir um cluster a partir do zero.
- Crie uma lista de verificação de unidades de implantação. Sua lista é exclusiva para suas necessidades, mas deve incluir: scripts de implantação, conexões de ingestão, ferramentas de BI e outras configurações importantes.