Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este artigo detalha como você pode se preparar para uma interrupção regional do Azure replicando seus recursos, gerenciamento e ingestão do Azure Data Explorer em diferentes regiões do Azure. É dado um exemplo de ingestão de dados com os Hubs de Eventos do Azure. A otimização de custos também é discutida para diferentes configurações de arquitetura. Para obter uma visão mais aprofundada das considerações de arquitetura e soluções de recuperação, consulte a visão geral da continuidade de negócios.
Prepare-se para a interrupção regional do Azure para proteger seus dados
O Azure Data Explorer não oferece suporte à proteção automática contra a interrupção de uma região inteira do Azure. Esta perturbação pode acontecer durante uma catástrofe natural, como um terramoto. Se você precisar de uma solução para uma situação de recuperação de desastres, execute as etapas a seguir para garantir a continuidade dos negócios. Nestas etapas, você replicará seus clusters, gerenciamento e ingestão de dados em duas regiões emparelhadas do Azure.
- Crie dois ou mais clusters independentes em duas regiões emparelhadas do Azure.
- Replique todas as atividades de gerenciamento , como a criação de novas tabelas ou o gerenciamento de funções de usuário em cada cluster.
- Ingerir dados em cada cluster em paralelo.
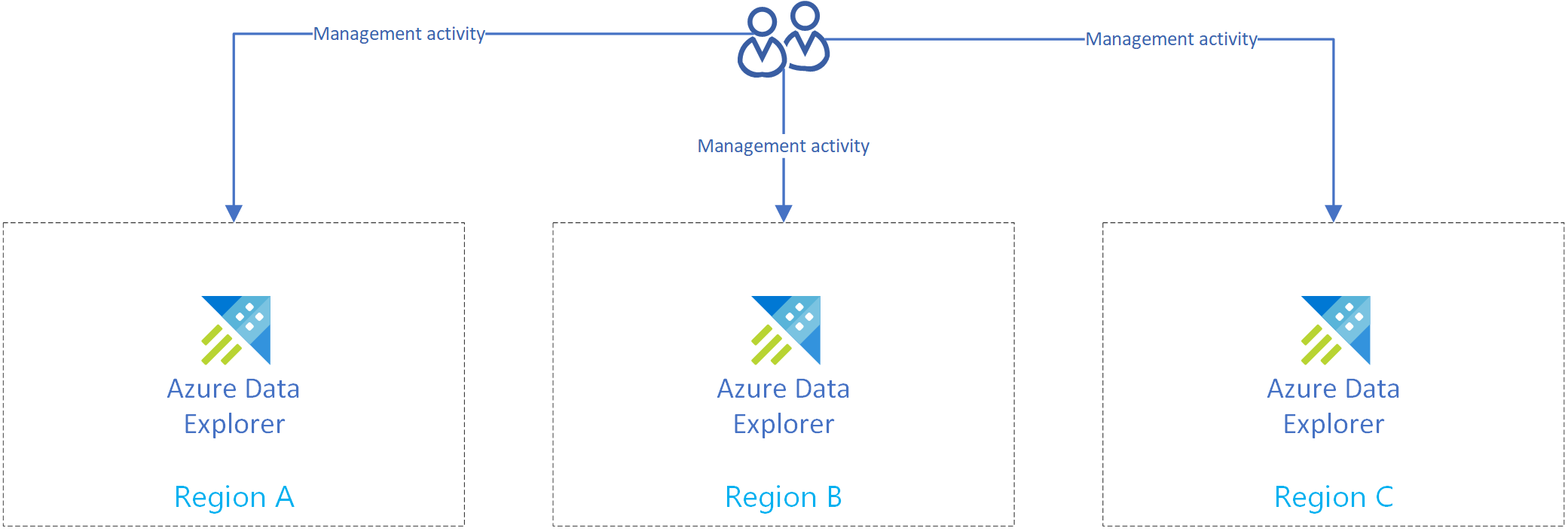
Criar vários clusters independentes
Crie mais de um cluster do Azure Data Explorer em mais de uma região. Certifique-se de que pelo menos dois desses clusters sejam criados em regiões emparelhadas do Azure.
A imagem seguinte mostra réplicas, três clusters em três regiões diferentes.

Replicar atividades de gerenciamento
Replique as atividades de gerenciamento para ter a mesma configuração de cluster em cada réplica.
Faça a mesma coisa em cada réplica.
- Bancos de dados: você pode usar o portal do Azure ou um de nossos SDKs para criar um novo banco de dados.
- Tabelas
- Mapeamentos
- Políticas
Gerencie a autenticação e a autorização em cada réplica.
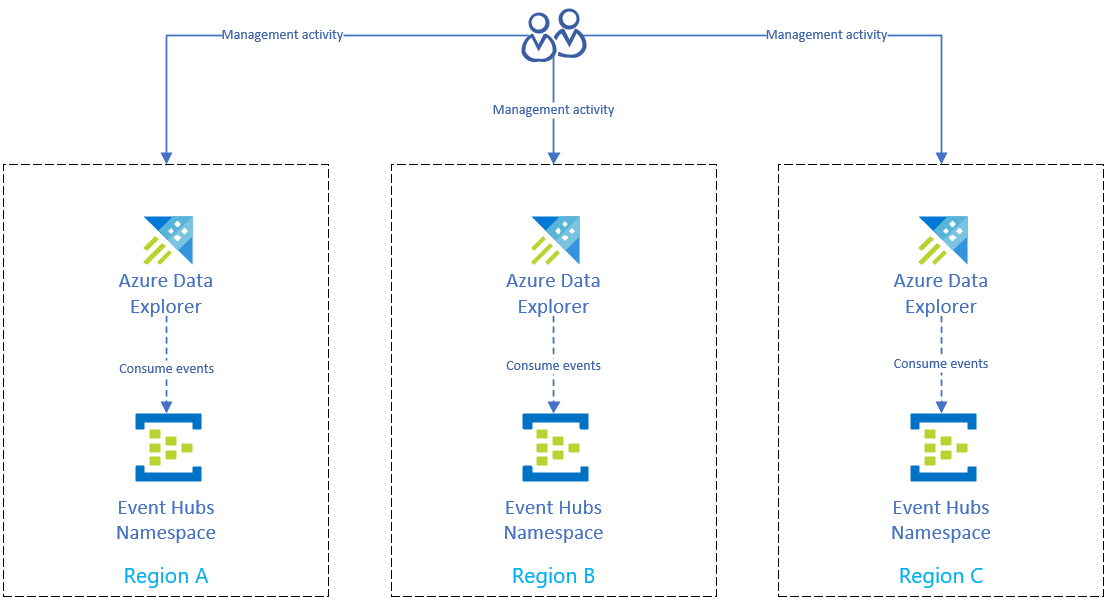
Solução de recuperação de desastres usando ingestão de hub de eventos
Depois de concluir Prepare-se para a interrupção regional do Azure para proteger seus dados, seus dados e gerenciamento serão distribuídos para várias regiões. Se houver uma interrupção em uma região, o Azure Data Explorer poderá usar as outras réplicas.
Configurar a ingestão de dados usando um hub de eventos
Para ingerir dados dos Hubs de Eventos do Azure no cluster do Azure Data Explorer de cada região, primeiro replique a configuração dos Hubs de Eventos do Azure em cada região. Em seguida, configure a réplica do Azure Data Explorer de cada região para ingerir dados de seus Hubs de Eventos correspondentes.
Observação
A ingestão através dos Hubs de Eventos do Azure/Hub IoT/Armazenamento é robusta. Se um cluster não estiver disponível por um período de tempo, ele se atualizará posteriormente e inserirá quaisquer mensagens ou blobs pendentes. Este processo depende de pontos de verificação.
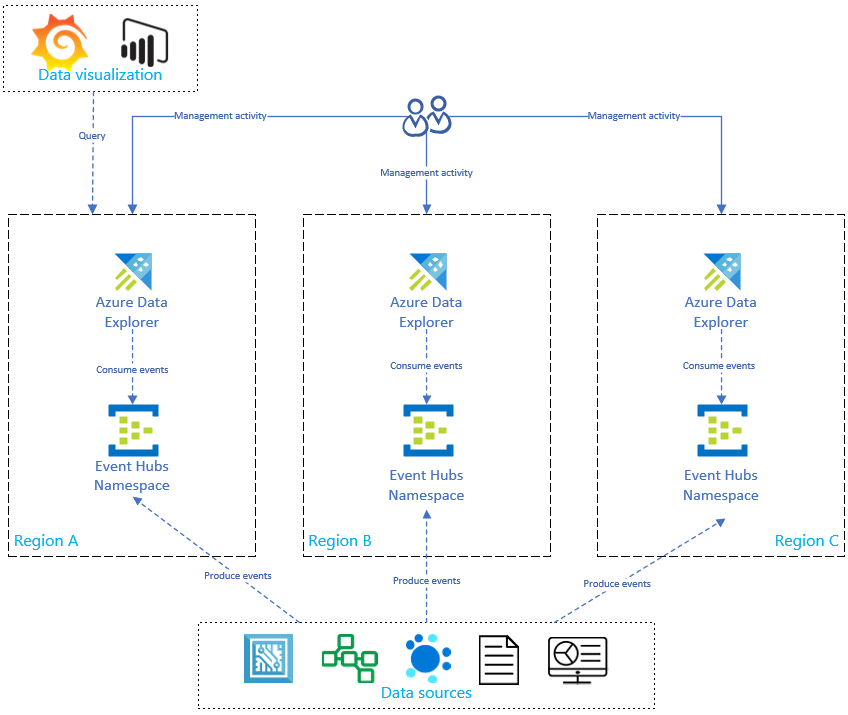
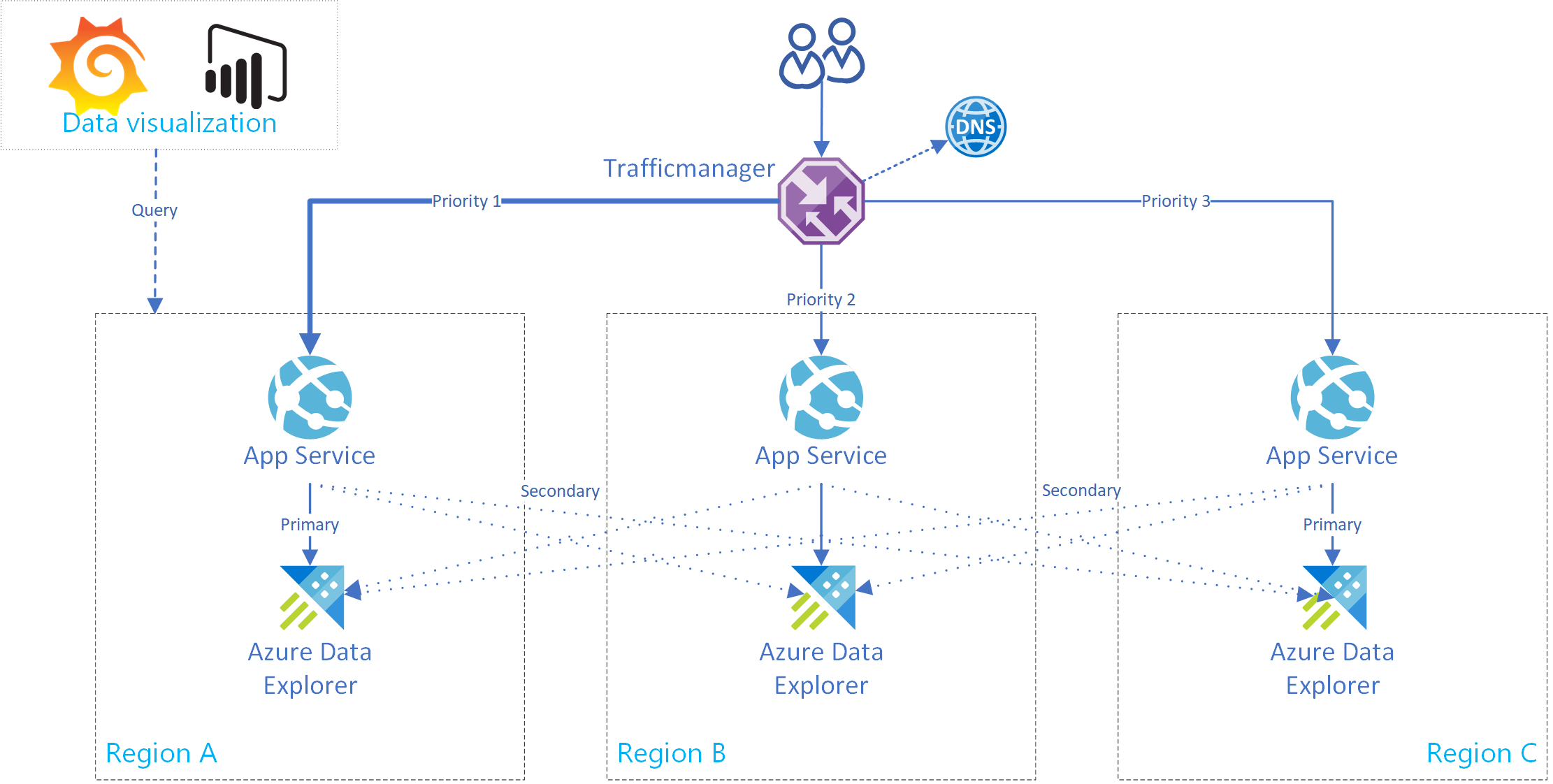
Conforme mostrado no diagrama abaixo, suas fontes de dados produzem eventos para hubs de eventos em todas as regiões, e cada réplica do Azure Data Explorer consome os eventos. Componentes de visualização de dados como Power BI, Grafana ou WebApps com SDK podem consultar uma das réplicas.
Otimizar custos
Agora você está pronto para otimizar suas réplicas usando alguns dos seguintes métodos:
- Criar uma configuração de recuperação de dados sob demanda
- Iniciar e parar as réplicas
- Implementar um serviço de aplicação de alta disponibilidade
- Otimize o custo em uma configuração ativo-ativo
Criar uma configuração de recuperação de dados sob demanda
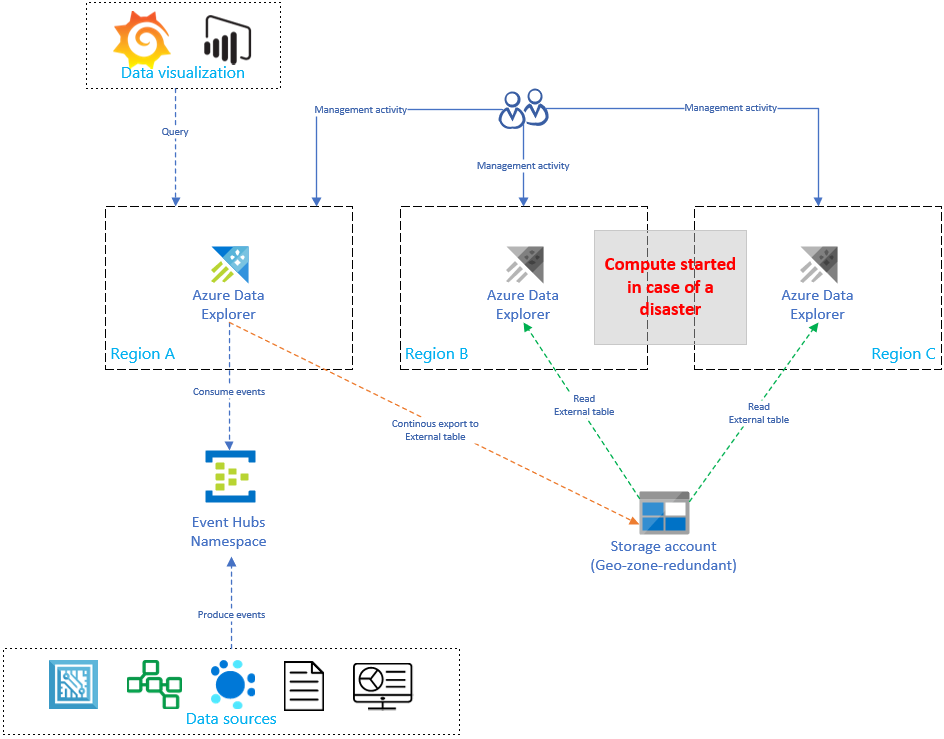
Replicar e atualizar a configuração do Azure Data Explorer aumentará linearmente o custo com o número de réplicas. Para otimizar o custo, pode-se implementar uma variante arquitetónica para equilibrar o tempo, o failover e o custo. Em uma configuração de recuperação de dados sob demanda, a otimização de custos foi implementada introduzindo réplicas passivas do Azure Data Explorer. Essas réplicas só são ativadas se houver um desastre na região primária (por exemplo, região A). As réplicas nas regiões B e C não precisam estar ativas 24 horas por dia, 7 dias por semana, reduzindo significativamente o custo. No entanto, na maioria dos casos, o desempenho dessas réplicas não será tão bom quanto o cluster principal. Para obter mais informações, consulte Configuração de recuperação de dados sob demanda.
Na imagem abaixo, apenas um cluster está ingerindo dados do hub de eventos. O cluster primário na Região A executa a exportação contínua de dados de todos os dados para uma conta de armazenamento. As réplicas secundárias têm acesso aos dados usando tabelas externas.
Iniciar e interromper as réplicas
Você pode iniciar e parar as réplicas secundárias usando um dos seguintes métodos:
Conector do Azure Data Explorer para Power Automate (pré-visualização)
O botão Parar na guia Visão geral no portal do Azure. Para obter mais informações, consulte Parar e reiniciar o cluster.
CLI do Azure:
az kusto cluster stop --name=<clusterName> --resource-group=<rgName> --subscription=<subscriptionId>"
Implementar um serviço de aplicativo altamente disponível
Criar o cliente BCDR do Serviço de Aplicativo do Azure
Esta seção mostra como criar um Serviço de Aplicativo do Azure que dá suporte a uma conexão com um único cluster primário e vários clusters secundários do Azure Data Explorer. A imagem a seguir ilustra a configuração do Serviço de Aplicativo do Azure.
Sugestão
Ter várias conexões entre réplicas no mesmo serviço proporciona maior disponibilidade. Essa configuração não é útil apenas em casos de interrupções regionais.
Use este código de exemplo para um serviço de aplicação. Para implementar um cliente multi-cluster, a classe AdxBcdrClient foi criada. Cada consulta executada usando esse cliente será enviada primeiro para o cluster primário. Caso ocorra uma falha, a consulta será enviada para réplicas secundárias.
Use métricas personalizadas do Application Insights para medir o desempenho e solicitar a distribuição para clusters primários e secundários.
Testar o cliente BCDR do Serviço de Aplicativo do Azure
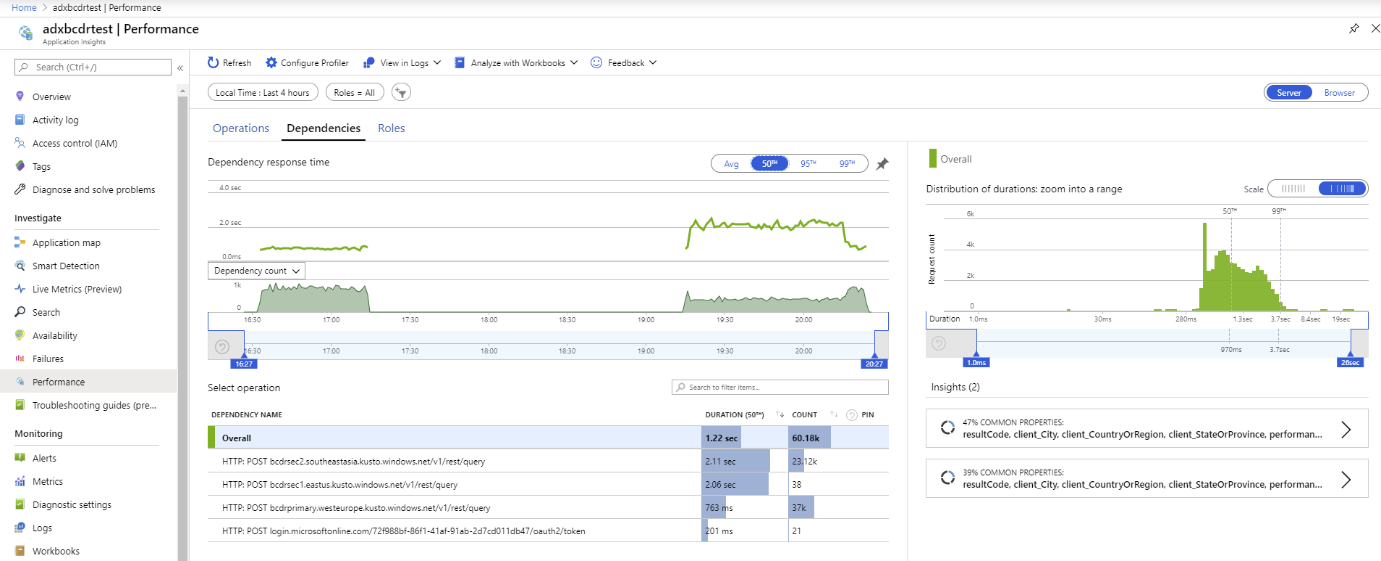
Executamos um teste usando várias réplicas do Azure Data Explorer. Após uma interrupção simulada dos clusters primários e secundários, pode-se observar que o cliente BCDR do serviço de aplicação está a comportar-se como esperado.
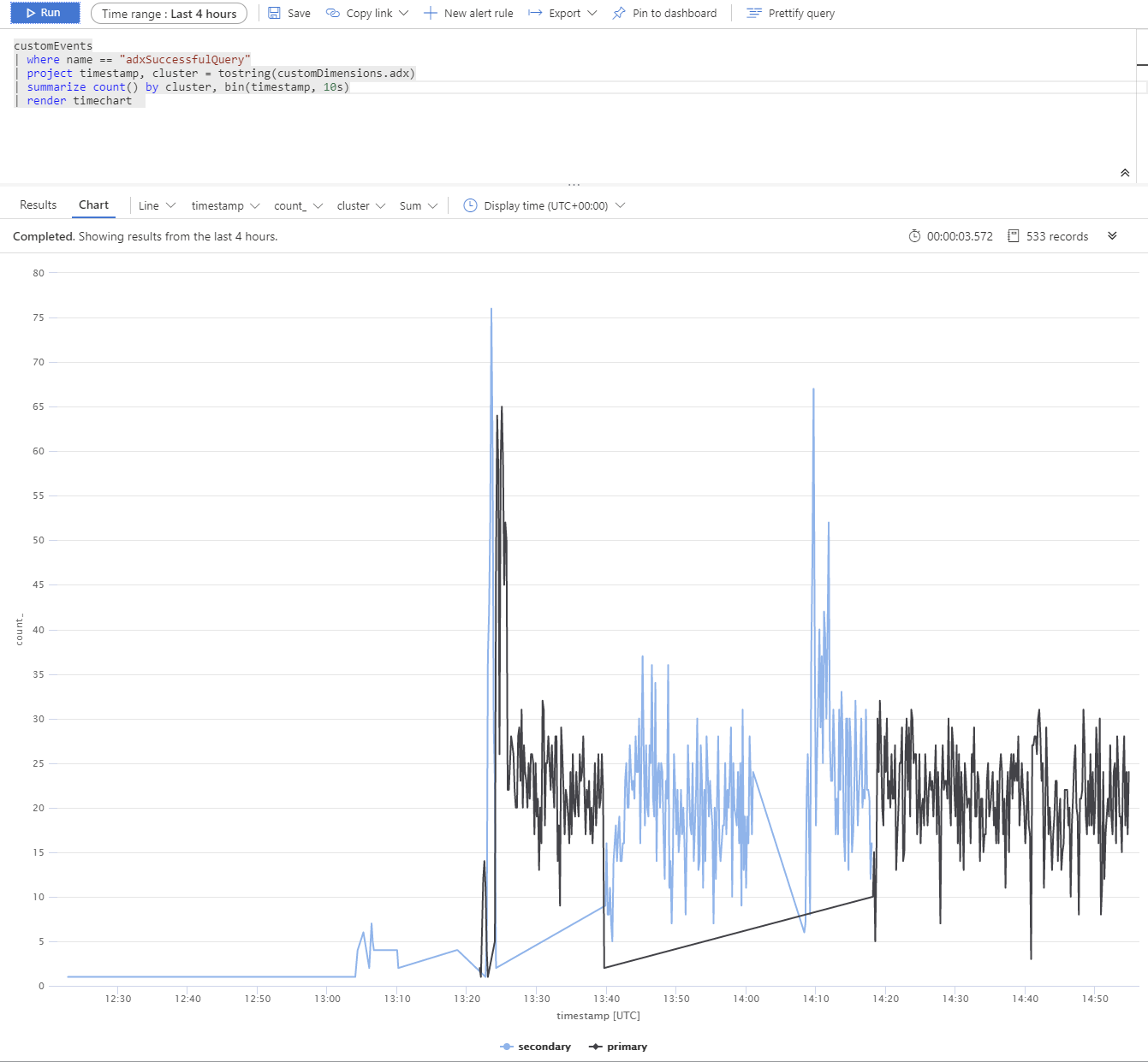
Os clusters do Azure Data Explorer são distribuídos pela Europa Ocidental (2xD14v2 principal), Sudeste Asiático e Leste dos EUA (2xD11v2).
Observação
Tempos de resposta mais lentos devem-se a diferentes SKUs e consultas interplanetárias.
Executar roteamento dinâmico ou estático
Use os métodos de roteamento do Azure Traffic Manager para roteamento dinâmico ou estático das solicitações. O Azure Traffic Manager é um balanceador de carga de tráfego baseado em DNS que permite distribuir o tráfego do serviço de aplicativo. Esse tráfego é otimizado para serviços em regiões globais do Azure, ao mesmo tempo em que fornece alta disponibilidade e capacidade de resposta.
Você também pode usar o roteamento baseado no Azure Front Door. Para comparar esses dois métodos, consulte Balanceamento de carga com o pacote de entrega de aplicativos do Azure.
Otimização de custos numa configuração ativa-ativa
O uso de uma configuração ativo-ativo para recuperação de desastres aumenta os custos de forma linear. O custo inclui nós, armazenamento, marcação e custo adicional de rede para largura de banda.
Use o dimensionamento automático otimizado para otimizar os custos
Use o recurso de dimensionamento automático otimizado para configurar o dimensionamento horizontal para os clusters secundários. Devem ser dimensionados de modo a poderem suportar a carga de ingestão. Quando o cluster primário não estiver acessível, os clusters secundários receberão mais tráfego e serão dimensionados de acordo com a configuração.
O uso da escala automática otimizada neste exemplo economizou aproximadamente 50% do custo em comparação com ter a mesma escala horizontal e vertical em todas as réplicas.