Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
A ingestão de dados é o processo de carregar dados de uma ou mais fontes para uma tabela no Azure Data Explorer. Uma vez ingeridos, os dados ficam disponíveis para consulta. Neste artigo, você aprenderá como obter dados de um arquivo local em uma tabela nova ou existente.
Para obter informações gerais sobre ingestão de dados, consulte Visão geral da ingestão de dados do Azure Data Explorer .
Pré-requisitos
- Uma conta Microsoft ou uma identidade de utilizador do Microsoft Entra. Uma assinatura do Azure não é necessária.
- Entre na interface do usuário da Web do Azure Data Explorer.
- Um cluster e um banco de dados do Azure Data Explorer. Crie um cluster e um banco de dados.
Obter dados
No painel de navegação à esquerda, selecione Consulta.
Clique com o botão direito do rato na base de dados onde pretende ingerir os dados. Selecione Obter dados.
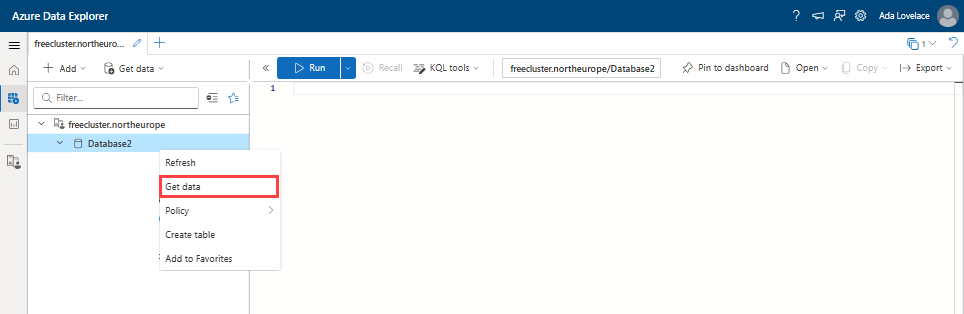

Fonte de dados selecionada
Na janela Obter Dados, a aba Fonte está selecionada.
Selecione a fonte de dados na lista disponível. Neste exemplo, está a ingerir dados de um ficheiro Local.

Observação
A ingestão suporta um tamanho máximo de ficheiro de 6 GB. A recomendação é ingerir arquivos entre 100 MB e 1 GB.
Configurar a ingestão de dados
Selecione um banco de dados e uma tabela de destino. Para ingerir dados numa nova tabela, selecione + Nova tabela e introduza o nome da tabela.
Observação
Os nomes das tabelas podem ter até 1.024 caracteres, incluindo espaços, caracteres alfanuméricos, hífens e sublinhados. Não há suporte para caracteres especiais.
Arrasta ficheiros para a janela ou seleciona Procurar ficheiros.
Observação
Você pode adicionar até 1.000 arquivos. Cada ficheiro pode ter no máximo 1 GB não comprimido.
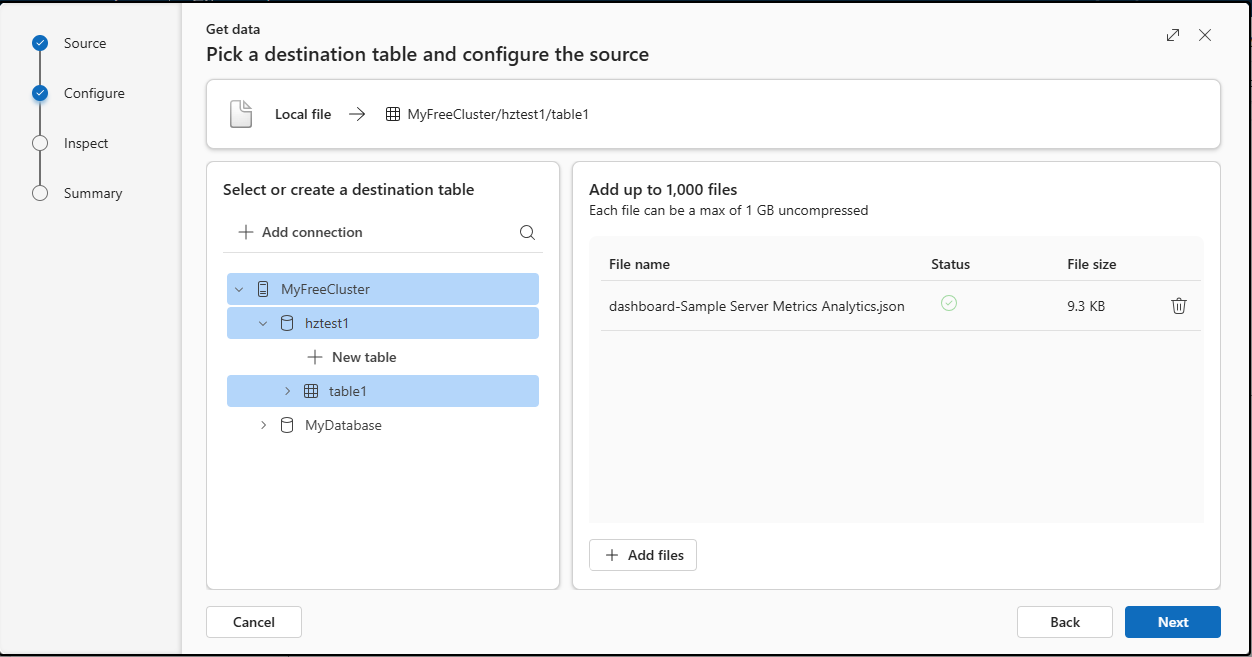
Selecione Avançar.

Inspecionar
A guia Inspecionar é aberta com uma pré-visualização dos dados.
Para concluir o processo de ingestão, selecione Concluir.

Opcionalmente:
- Altere o formato de dados que foi inferido automaticamente selecionando, a partir do menu pendente, o formato desejado. Consulte Formatos de dados suportados pelo Azure Data Explorer para ingestão.
- Editar colunas.
- Explore Opções Avançadas com base no Tipo de Dados.
Editar colunas
Observação
- Para formatos tabulares (CSV, TSV, PSV), não é possível mapear uma coluna duas vezes. Para mapear para uma coluna existente, primeiro exclua a nova coluna.
- Não é possível alterar um tipo de coluna existente. Se você tentar mapear para uma coluna com um formato diferente, você pode acabar com colunas vazias.
As alterações que você pode fazer em uma tabela dependem dos seguintes parâmetros:
- O tipo de tabela é novo ou existente
- Tipo de mapeamento é novo ou existente

Mapeando transformações
Alguns mapeamentos de formato de dados (Parquet, JSON e Avro) suportam transformações simples durante a ingestão. Para aplicar transformações de mapeamento, crie ou atualize uma coluna na janela Editar colunas .
As transformações de mapeamento podem ser executadas em uma coluna do tipo string ou datetime, com a fonte tendo o tipo de dados int ou long. As transformações de mapeamento suportadas são:
- Date_Hora_De_Segundos_Unix
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds (DataHoraAPartirDeNanosegundosUnix)
Opções avançadas com base no tipo de dados
Tabela (CSV, TSV, PSV):
Se estiver a ingerir formatos tabulares numa tabela existente, pode selecionar o menu suspenso de mapeamento de tabela e selecionar Usar mapeamento existente. Os dados tabulares não incluem necessariamente os nomes das colunas usadas para mapear os dados de origem para as colunas existentes. Quando essa opção é marcada, o mapeamento é feito por ordem e o esquema da tabela permanece o mesmo.
Caso contrário, crie um novo mapeamento.
Para usar a primeira linha como nomes de coluna, selecione Cabeçalho da primeira linha.
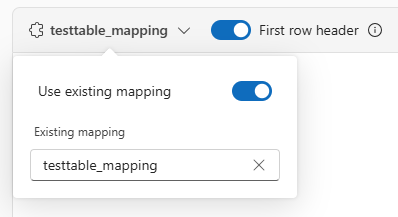
JSON:
- Para determinar a divisão de colunas dos dados JSON, selecione Níveis aninhados, de 1 a 100.
Resumo
Na janela de preparação de dados , os três passos mostram marcas verdes quando a ingestão de dados termina com sucesso. Pode visualizar os comandos que cada passo utilizou, ou selecionar um cartão para consultar, visualizar ou eliminar os dados ingeridos.
