Ingerir dados do Azure Cosmos DB no Azure Data Explorer
O Azure Data Explorer dá suporte a de ingestão de dados do Azure Cosmos DB para NoSql usando um feed de alterações de . A conexão de dados do feed de alterações do Cosmos DB é um pipeline de ingestão que escuta o feed de alterações do Cosmos DB e ingere os dados na tabela do Data Explorer. O feed de alterações escuta documentos novos e atualizados, mas não registra exclusões. Para obter informações gerais sobre a ingestão de dados no Azure Data Explorer, consulte Visão geral da ingestão de dados do Azure Data Explorer.
Cada conexão de dados escuta um contentor específico do Cosmos DB e ingere dados numa tabela especificada (mais de uma conexão pode ingerir dados numa única tabela). O método de ingestão suporta ingestão por streaming (quando habilitada) e ingestão em fila.
Os dois cenários principais para usar a conexão de dados do feed de alterações do Cosmos DB são:
- Replicando um contêiner do Cosmos DB para fins analíticos. Para obter mais informações, consulte Obter versões mais recentes dos documentos do Azure Cosmos DB.
- Analisando as alterações de documento em um contêiner do Cosmos DB. Para obter mais informações, consulte Considerações.
Neste artigo, irá aprender a configurar uma ligação de dados de fluxo de alterações do Cosmos DB para ingerir dados no Azure Data Explorer com a Identidade Gerida pelo Sistema. Reveja as considerações antes de começar.
Use as seguintes etapas para configurar um conector:
Etapa 1: escolher uma tabela do Azure Data Explorer e configurar seu mapeamento de tabela
Etapa 2: criar uma conexão de dados do Cosmos DB
Etapa 3: Testar a conexão de dados
Pré-requisitos
- Uma assinatura do Azure. Crie uma conta gratuita do Azure .
- Um cluster e um banco de dados do Azure Data Explorer. Criar um cluster e um banco de dados.
- Um contentor de uma conta Cosmos DB para NoSQL.
- Se sua conta do Cosmos DB bloquear o acesso à rede, por exemplo, usando um ponto de extremidade privado , você deverá criar um de ponto de extremidade privado gerenciado para a conta do Cosmos DB. Isso é necessário para que o cluster invoque a API do feed de alterações.
Etapa 1: escolher uma tabela do Azure Data Explorer e configurar seu mapeamento de tabela
Antes de criar uma conexão de dados, crie uma tabela onde armazenará os dados ingeridos e aplique um mapeamento que corresponda ao esquema no contêiner do Cosmos DB de origem. Se o seu cenário exigir mais do que um simples mapeamento de campos, poderá utilizar as políticas de atualização para transformar e mapear dados ingeridos do seu feed de alterações.
A seguir mostra um esquema de exemplo de um item no contêiner do Cosmos DB:
{
"id": "17313a67-362b-494f-b948-e2a8e95e237e",
"name": "Cousteau",
"_rid": "pL0MAJ0Plo0CAAAAAAAAAA==",
"_self": "dbs/pL0MAA==/colls/pL0MAJ0Plo0=/docs/pL0MAJ0Plo0CAAAAAAAAAA==/",
"_etag": "\"000037fc-0000-0700-0000-626a44110000\"",
"_attachments": "attachments/",
"_ts": 1651131409
}
Use as seguintes etapas para criar uma tabela e aplicar um mapeamento de tabela:
Na interface Web do Azure Data Explorer, no menu de navegação à esquerda, selecione Consultae, em seguida, escolha a base de dados onde pretende criar a tabela.
Execute o seguinte comando para criar uma tabela chamada TestTable.
.create table TestTable(Id:string, Name:string, _ts:long, _timestamp:datetime)Execute o seguinte comando para criar o mapeamento de tabela.
O comando mapeia propriedades personalizadas de um documento JSON do Cosmos DB para colunas na tabela TestTable
, da seguinte maneira: Propriedade Cosmos DB Coluna da tabela Transformação id Id Nenhum nome Nome Nenhum _ts _ts Nenhum _ts _timestamp Usa DateTimeFromUnixSecondspara transformar_ts (segundos UNIX) em _timestamp (datetime))Observação
Recomendamos a utilização das seguintes colunas de data/hora:
- _ts: Use esta coluna para reconciliar dados com o Cosmos DB.
- _timestamp: Use esta coluna para executar filtros de tempo eficientes em suas consultas Kusto. Para obter mais informações, consulte Melhores práticas de consulta.
.create table TestTable ingestion json mapping "DocumentMapping" ``` [ {"column":"Id","path":"$.id"}, {"column":"Name","path":"$.name"}, {"column":"_ts","path":"$._ts"}, {"column":"_timestamp","path":"$._ts", "transform":"DateTimeFromUnixSeconds"} ] ```
Transforme e mapeie dados com políticas de atualização
Se o seu cenário exigir mais do que um simples mapeamento de campos, você poderá usar políticas de atualização para transformar e mapear dados ingeridos do seu feed de alterações.
Políticas de atualização são uma forma de transformar dados quando são introduzidos na sua tabela. Eles são escritos em Kusto Query Language e são executados no pipeline de ingestão. Eles podem ser usados para transformar dados de uma ingestão de um feed de alterações do Cosmos DB, como nos seguintes cenários:
- Seus documentos contêm matrizes que seriam mais fáceis de consultar se fossem transformadas em várias linhas usando o operador
mv-expand. - Você deseja filtrar documentos. Por exemplo, você pode filtrar documentos por tipo usando o operador
where. - Você tem uma lógica complexa que não pode ser representada em um mapeamento de tabela.
Para obter informações sobre como criar e gerenciar políticas de atualização, consulte Visão geral da política de atualização.
Etapa 2: Criar uma conexão de dados do Cosmos DB
Você pode usar os seguintes métodos para criar o conector de dados:
No portal do Azure, vá para a página de visão geral do cluster e selecione a guia Introdução.
No bloco Ingestão de dados, selecione Criar conexão de dados>Cosmos DB.
No painel Criar conexão de dados do Cosmos DB
, preencha o formulário com as informações na tabela: 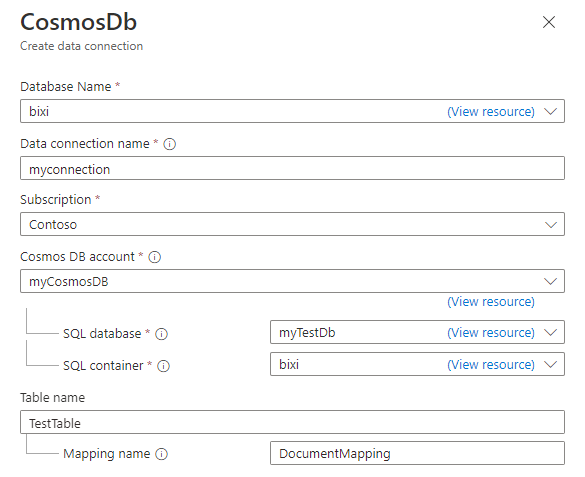
Campo Descrição Nome do banco de dados Escolha o banco de dados do Azure Data Explorer no qual você deseja ingerir dados. Nome da conexão de dados Especifique um nome para a conexão de dados. Subscrição Selecione a assinatura que contém sua conta NoSQL do Cosmos DB. conta do Cosmos DB Escolha a conta do Cosmos DB a partir da qual você deseja ingerir dados. base de dados SQL Escolha o banco de dados do Cosmos DB do qual você deseja ingerir dados. contêiner SQL Escolha o contêiner do Cosmos DB a partir do qual você deseja ingerir dados. Nome da tabela Especifique o nome da tabela do Azure Data Explorer à qual pretende ingerir dados. Nome do mapeamento Opcionalmente, especifique o nome de mapeamento a usar para a conexão de dados. Opcionalmente, na seção Configurações avançadas, faça o seguinte:
Especifique a data de início da recuperação do evento . Este é o momento a partir do qual o conector começará a ingerir dados. Se você não especificar uma hora, o conector começará a ingerir dados a partir do momento em que você criar a conexão de dados. O formato de data recomendado é a norma ISO 8601 UTC, especificada da seguinte forma:
yyyy-MM-ddTHH:mm:ss.fffffffZ.Selecione atribuído pelo usuário e, em seguida, selecione a identidade. Por padrão, a identidade gerenciada atribuída ao sistema é usada pela conexão. Se necessário, pode-se utilizar uma identidade atribuída pelo usuário .
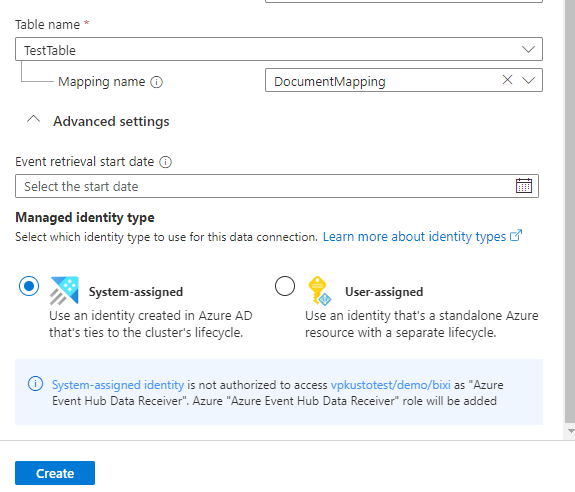
Selecione Criar para criar a conexão de dados.
Etapa 3: Testar a conexão de dados
No contêiner do Cosmos DB, insira o seguinte documento:
{ "name":"Cousteau" }Na interface do usuário da Web do Azure Data Explorer, execute a seguinte consulta:
TestTableO conjunto de resultados deve ser semelhante à seguinte imagem:

Observação
O Azure Data Explorer tem uma política de agregação (loteamento) para ingestão de dados em fila projetada para otimizar o processo de ingestão. A política de lote padrão é configurada para selar um lote quando uma das seguintes condições for verdadeira para o lote: um tempo máximo de atraso de 5 minutos, tamanho total de um GB ou 1000 blobs. Portanto, poderá experimentar uma latência. Para obter mais informações, consulte política de envio em lote. Para reduzir a latência, configure sua tabela para oferecer suporte a streaming. Consulte política de streaming.
Considerações
As seguintes considerações se aplicam ao feed de alterações do Cosmos DB:
O feed de alterações não expõe exclusão eventos.
O feed de alterações do Cosmos DB inclui apenas documentos novos e atualizados. Se você precisar saber sobre documentos excluídos, poderá configurar seu feed usando um marcador suave para marcar um documento do Cosmos DB como excluído. Uma propriedade é adicionada para atualizar eventos que indicam se um documento foi excluído. Em seguida, você pode usar o operador
whereem suas consultas para filtrá-las.Por exemplo, se você mapear a propriedade excluída para uma coluna de tabela chamada IsDeleted, poderá filtrar documentos excluídos com a seguinte consulta:
TestTable | where not(IsDeleted)O feed de alterações expõe apenas a atualização mais recente de um documento.
Para compreender a ramificação da segunda consideração, examine o seguinte cenário:
Um contêiner do Cosmos DB contém documentos A e B. As alterações em uma propriedade chamada foo são mostradas na tabela a seguir:
ID do documento Propriedade foo Evento Data e hora do documento (_ts) A Vermelho Criação 10 B Azul Criação 20 Um Laranja Atualizar 30 UM Rosa Atualização 40 B Violeta Atualizar 50 Um Carmim Atualizar 50 B NeonBlue Atualizar 70 A API de alimentação de alterações é pesquisada pelo conector de dados em intervalos regulares, geralmente a cada alguns segundos. Cada inquérito contém alterações que ocorreram no repositório entre as chamadas, mas apenas a alteração mais recente por documento.
Para ilustrar o problema, considere uma sequência de chamadas de API com carimbos de data/hora: 15, 35, 55e 75, conforme mostrado na tabela a seguir.
Carimbo de data/hora da chamada de API ID do documento Propriedade foo Carimbo de data/hora do documento (_ts) 15 Um Vermelho 10 35 B Azul 20 35 Um Laranja 30 55 B Violeta 50 55 Um Carmim 60 75 B NeonBlue 70 Comparando os resultados da API com a lista de alterações feitas no documento do Cosmos DB, você notará que elas não correspondem. O evento de atualização para o documento A, destacado na tabela de alterações no timestamp 40, não aparece nos resultados da chamada de API.
Para entender por que o evento não aparece, iremos examinar as alterações no documento A entre as chamadas da API nos instantes de tempo 35 e 55. Entre estas duas chamadas, o documento A foi alterado duas vezes, da seguinte forma:
ID do documento Propriedade foo Evento Carimbo de data/hora do documento (_ts) Um cor-de-rosa Atualizar 40 Um Carmim Atualizar 50 Quando a invocação da API com o carimbo de tempo 55 é feita, a API de alterações retorna a versão mais recente do documento. Neste caso, a versão mais recente do documento A é a atualização com o carimbo de data/hora 50, que corresponde à alteração da propriedade foo de Pink para Carmine.
Devido a esse cenário, o conector de dados pode perder algumas alterações intermediárias do documento. Por exemplo, alguns eventos podem ser perdidos se o serviço de conexão de dados estiver inativo por alguns minutos ou se a frequência de alterações no documento for maior do que a frequência de sondagem da API. No entanto, captura-se o estado mais recente de cada documento.
Não há suporte para exclusão e recriação de um contêiner do Cosmos DB
O Azure Data Explorer controla o feed de alterações verificando a "posição" em que ele está no feed. Isso é feito usando o token de continuação em cada partição física do contêiner. Quando um contêiner é excluído/recriado, o token de continuação é inválido e não é redefinido. Nesse caso, você deve excluir e recriar a conexão de dados.
Estimativa de custos
Quanto o uso da conexão de dados do Cosmos DB afeta o uso das Unidades de Solicitação de
O conector invoca a API Change Feed do Cosmos DB em cada partição física do contêiner, até uma vez por segundo. A estas invocações estão associados os seguintes custos:
| Custo | Descrição |
|---|---|
| Custos fixos | Os custos fixos são de cerca de 2 RUs por partição física a cada segundo. |
| Custos variáveis | Os custos variáveis são cerca de 2% das RUs usadas para escrever documentos, embora isto possa variar conforme o seu cenário. Por exemplo, se você escrever 100 documentos em um contêiner do Cosmos DB, o custo de escrever esses documentos será de 1.000 RUs. O custo correspondente para usar o conector para ler aqueles documentos é cerca de 2% do custo para escrevê-los, aproximadamente 20 RUs. |