Ingerir dados do Apache Kafka para o Azure Data Explorer
O Apache Kafka é uma plataforma de transmissão em fluxo distribuída para criar pipelines de dados de transmissão em fluxo em tempo real que movem dados de forma fiável entre sistemas ou aplicações. O Kafka Connect é uma ferramenta para transmissão em fluxo dimensionável e fiável de dados entre o Apache Kafka e outros sistemas de dados. O Sink do Kusto Kafka serve como conector do Kafka e não requer a utilização de código. Transfira o jar do conector sink a partir do repositório Git ou do Hub do Conector do Confluent.
Este artigo mostra como ingerir dados com o Kafka, através de uma configuração autónoma do Docker para simplificar o cluster do Kafka e a configuração do cluster do conector kafka.
Para obter mais informações, veja o repositório Git do conector e as especificações da versão.
Pré-requisitos
- Uma subscrição do Azure. Crie uma conta gratuita do Azure.
- Um cluster e uma base de dados do Azure Data Explorer com as políticas de cache e retenção predefinidas ou uma base de dados KQL no Microsoft Fabric.
- CLI do Azure.
- Docker e Docker Compose.
Criar um principal de serviço Microsoft Entra
O principal de serviço Microsoft Entra pode ser criado através do portal do Azure ou programaticamente, como no exemplo seguinte.
Este principal de serviço será a identidade utilizada pelo conector para escrever dados na sua tabela no Kusto. Mais tarde, irá conceder permissões para este principal de serviço aceder aos recursos do Kusto.
Inicie sessão na sua subscrição do Azure através da CLI do Azure. Em seguida, autentique-se no browser.
az loginEscolha a subscrição para alojar o principal. Este passo é necessário quando tem várias subscrições.
az account set --subscription YOUR_SUBSCRIPTION_GUIDCrie o principal de serviço. Neste exemplo, o principal de serviço chama-se
my-service-principal.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}A partir dos dados JSON devolvidos, copie ,
appIdpasswordetenantpara utilização futura.{ "appId": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn", "displayName": "my-service-principal", "name": "my-service-principal", "password": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn", "tenant": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn" }
Criou a sua aplicação Microsoft Entra e principal de serviço.
Criar uma tabela de destino
A partir do ambiente de consulta, crie uma tabela chamada
Stormscom o seguinte comando:.create table Storms (StartTime: datetime, EndTime: datetime, EventId: int, State: string, EventType: string, Source: string)Crie o mapeamento
Storms_CSV_Mappingde tabela correspondente para dados ingeridos com o seguinte comando:.create table Storms ingestion csv mapping 'Storms_CSV_Mapping' '[{"Name":"StartTime","datatype":"datetime","Ordinal":0}, {"Name":"EndTime","datatype":"datetime","Ordinal":1},{"Name":"EventId","datatype":"int","Ordinal":2},{"Name":"State","datatype":"string","Ordinal":3},{"Name":"EventType","datatype":"string","Ordinal":4},{"Name":"Source","datatype":"string","Ordinal":5}]'Crie uma política de criação de batches de ingestão na tabela para uma latência de ingestão em fila configurável.
Dica
A política de criação de batches de ingestão é um otimizador de desempenho e inclui três parâmetros. A primeira condição satisfeita aciona a ingestão na tabela de Data Explorer do Azure.
.alter table Storms policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:15", "MaximumNumberOfItems": 100, "MaximumRawDataSizeMB": 300}'Utilize o principal de serviço de Criar um principal de serviço Microsoft Entra para conceder permissão para trabalhar com a base de dados.
.add database YOUR_DATABASE_NAME admins ('aadapp=YOUR_APP_ID;YOUR_TENANT_ID') 'AAD App'
Executar o laboratório
O laboratório seguinte foi concebido para lhe dar a experiência de começar a criar dados, configurar o conector kafka e transmitir estes dados para o Azure Data Explorer com o conector. Em seguida, pode ver os dados ingeridos.
Clonar o repositório git
Clone o repositório git do laboratório.
Crie um diretório local no seu computador.
mkdir ~/kafka-kusto-hol cd ~/kafka-kusto-holClone o repositório.
cd ~/kafka-kusto-hol git clone https://github.com/Azure/azure-kusto-labs cd azure-kusto-labs/kafka-integration/dockerized-quickstart
Conteúdo do repositório clonado
Execute o seguinte comando para listar os conteúdos do repositório clonado:
cd ~/kafka-kusto-hol/azure-kusto-labs/kafka-integration/dockerized-quickstart
tree
Este resultado desta pesquisa é:
├── README.md
├── adx-query.png
├── adx-sink-config.json
├── connector
│ └── Dockerfile
├── docker-compose.yaml
└── storm-events-producer
├── Dockerfile
├── StormEvents.csv
├── go.mod
├── go.sum
├── kafka
│ └── kafka.go
└── main.go
Rever os ficheiros no repositório clonado
As secções seguintes explicam as partes importantes dos ficheiros na árvore de ficheiros acima.
adx-sink-config.json
Este ficheiro contém o ficheiro de propriedades do sink do Kusto, onde irá atualizar detalhes de configuração específicos:
{
"name": "storm",
"config": {
"connector.class": "com.microsoft.azure.kusto.kafka.connect.sink.KustoSinkConnector",
"flush.size.bytes": 10000,
"flush.interval.ms": 10000,
"tasks.max": 1,
"topics": "storm-events",
"kusto.tables.topics.mapping": "[{'topic': 'storm-events','db': '<enter database name>', 'table': 'Storms','format': 'csv', 'mapping':'Storms_CSV_Mapping'}]",
"aad.auth.authority": "<enter tenant ID>",
"aad.auth.appid": "<enter application ID>",
"aad.auth.appkey": "<enter client secret>",
"kusto.ingestion.url": "https://ingest-<name of cluster>.<region>.kusto.windows.net",
"kusto.query.url": "https://<name of cluster>.<region>.kusto.windows.net",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter"
}
}
Substitua os valores dos seguintes atributos de acordo com a configuração do Azure Data Explorer: aad.auth.authority, aad.auth.appid, aad.auth.appkey, kusto.tables.topics.mapping (o nome da base de dados), kusto.ingestion.urle kusto.query.url.
Conector - Dockerfile
Este ficheiro tem os comandos para gerar a imagem do Docker para a instância do conector. Inclui a transferência do conector a partir do diretório de versão do repositório git.
Diretório storm-events-producer
Este diretório tem um programa Go que lê um ficheiro "StormEvents.csv" local e publica os dados num tópico do Kafka.
docker-compose.yaml
version: "2"
services:
zookeeper:
image: debezium/zookeeper:1.2
ports:
- 2181:2181
kafka:
image: debezium/kafka:1.2
ports:
- 9092:9092
links:
- zookeeper
depends_on:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
kusto-connect:
build:
context: ./connector
args:
KUSTO_KAFKA_SINK_VERSION: 1.0.1
ports:
- 8083:8083
links:
- kafka
depends_on:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=adx
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
events-producer:
build:
context: ./storm-events-producer
links:
- kafka
depends_on:
- kafka
environment:
- KAFKA_BOOTSTRAP_SERVER=kafka:9092
- KAFKA_TOPIC=storm-events
- SOURCE_FILE=StormEvents.csv
Iniciar os contentores
Num terminal, inicie os contentores:
docker-compose upA aplicação de produtor começará a enviar eventos para o
storm-eventstópico. Deverá ver registos semelhantes aos seguintes registos:.... events-producer_1 | sent message to partition 0 offset 0 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 00:00:00.0000000,13208,NORTH CAROLINA,Thunderstorm Wind,Public events-producer_1 | events-producer_1 | sent message to partition 0 offset 1 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 05:00:00.0000000,23358,WISCONSIN,Winter Storm,COOP Observer ....Para verificar os registos, execute o seguinte comando num terminal separado:
docker-compose logs -f | grep kusto-connect
Iniciar o conector
Utilize uma chamada REST do Kafka Connect para iniciar o conector.
Num terminal separado, inicie a tarefa de sink com o seguinte comando:
curl -X POST -H "Content-Type: application/json" --data @adx-sink-config.json http://localhost:8083/connectorsPara verificar o estado, execute o seguinte comando num terminal separado:
curl http://localhost:8083/connectors/storm/status
O conector iniciará os processos de ingestão de em fila para o Azure Data Explorer.
Nota
Se tiver problemas com o conector de registos, crie um problema.
Consultar e rever dados
Confirmar a ingestão de dados
Aguarde que os dados cheguem à
Stormstabela. Para confirmar a transferência de dados, verifique a contagem de linhas:Storms | countConfirme que não existem falhas no processo de ingestão:
.show ingestion failuresAssim que vir os dados, experimente algumas consultas.
Consultar os dados
Para ver todos os registos, execute a seguinte consulta:
StormsUtilize
whereeprojectpara filtrar dados específicos:Storms | where EventType == 'Drought' and State == 'TEXAS' | project StartTime, EndTime, Source, EventIdUtilize o
summarizeoperador :Storms | summarize event_count=count() by State | where event_count > 10 | project State, event_count | render columnchart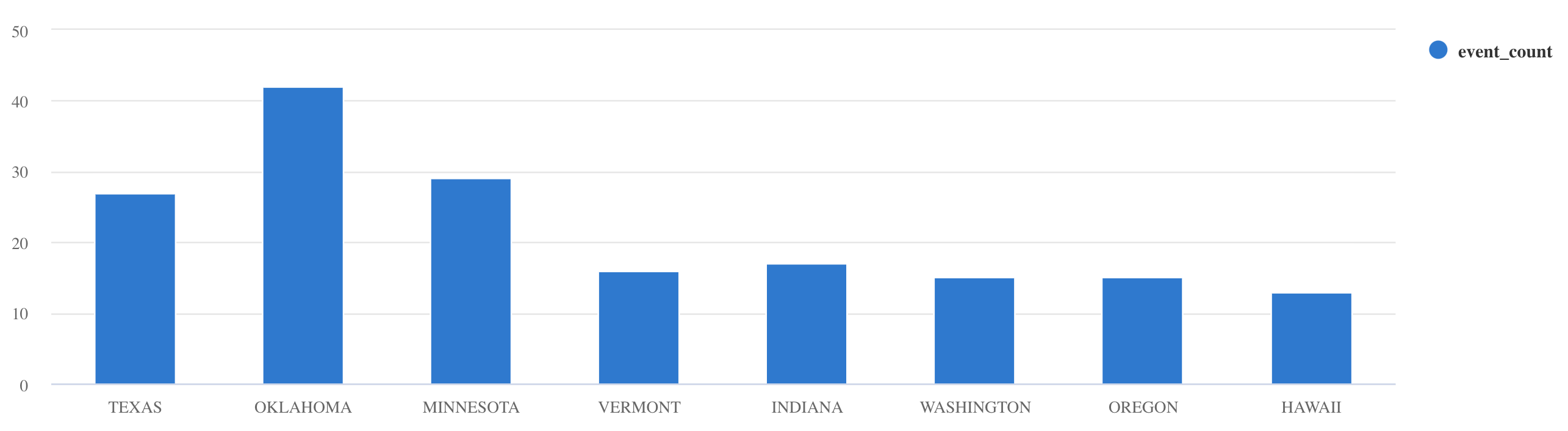
Para obter mais exemplos de consulta e documentação de orientação, veja Escrever consultas na KQL e Linguagem de Pesquisa Kusto documentação.
Repor
Para repor, siga os seguintes passos:
- Parar os contentores (
docker-compose down -v) - Eliminar (
drop table Storms) - Recriar a
Stormstabela - Recriar o mapeamento de tabelas
- Reiniciar contentores (
docker-compose up)
Limpar os recursos
Para eliminar os recursos do Azure Data Explorer, utilize az cluster delete ou az Kusto database delete:
az kusto cluster delete -n <cluster name> -g <resource group name>
az kusto database delete -n <database name> --cluster-name <cluster name> -g <resource group name>
Otimizar o conector Sink do Kafka
Ajuste o conector Sink do Kafka para trabalhar com a política de criação de batches de ingestão:
- Ajuste o limite de tamanho do Sink
flush.size.bytesdo Kafka a partir de 1 MB, aumentando em incrementos de 10 MB ou 100 MB. - Ao utilizar o Sink do Kafka, os dados são agregados duas vezes. Os dados do lado do conector são agregados de acordo com as definições de descarregamento e no lado do serviço do Azure Data Explorer de acordo com a política de criação de batches. Se o tempo de criação de batches for demasiado curto e não for possível ingerir dados pelo conector e pelo serviço, o tempo de criação de batches tem de ser aumentado. Defina o tamanho da criação de lotes em 1 GB e aumente ou diminua em incrementos de 100 MB, conforme necessário. Por exemplo, se o tamanho da cache for de 1 MB e o tamanho da política de criação de batches for de 100 MB, depois de um lote de 100 MB ser agregado pelo conector Sink do Kafka, um lote de 100 MB será ingerido pelo serviço de Data Explorer do Azure. Se o tempo da política de criação de batches for de 20 segundos e o conector Sink do Kafka esvaziar 50 MB num período de 20 segundos, o serviço irá ingerir um lote de 50 MB.
- Pode dimensionar ao adicionar instâncias e partições do Kafka. Aumente
tasks.maxpara o número de partições. Crie uma partição se tiver dados suficientes para produzir um blob do tamanho daflush.size.bytesdefinição. Se o blob for menor, o lote é processado quando atinge o limite de tempo, pelo que a partição não receberá débito suficiente. Um grande número de partições significa mais sobrecarga de processamento.
Conteúdo relacionado
- Saiba mais sobre a arquitetura de macrodados.
- Saiba como ingerir dados de exemplo formatados JSON no Azure Data Explorer.
- Para laboratórios kafka adicionais:
- Hands on lab for ingestion from Confluent Cloud Kafka in distributed mode (Laboratório prático para ingestão do Confluent Cloud Kafka no modo distribuído)
- Hands on lab for ingestion from HDInsight Kafka in distributed mode (Laboratório prático para ingestão do HDInsight Kafka no modo distribuído)
- Hands on lab for ingestion from Confluent IaaS Kafka on AKS in distributed mode (Laboratório prático para ingestão do Confluent IaaS Kafka no AKS no modo distribuído)
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários