Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
O Azure Monitor recolhe e agrega métricas e registos do seu sistema para monitorizar a disponibilidade, o desempenho e a resiliência e notificá-lo de problemas que afetam o seu sistema. Você pode usar o portal do Azure, PowerShell, CLI do Azure, API REST ou bibliotecas de cliente para configurar e exibir dados de monitoramento.
Diferentes métricas e logs estão disponíveis para diferentes tipos de recursos. Este artigo descreve os tipos de dados de monitoramento que você pode coletar para esse serviço e maneiras de analisar esses dados.
Coletar dados com o Azure Monitor
Esta tabela descreve como você pode coletar dados para monitorar seu serviço e o que você pode fazer com os dados depois de coletados:
| Dados a recolher | Descrição | Como recolher e encaminhar os dados | Onde visualizar os dados | Dados suportados |
|---|---|---|---|---|
| Dados métricos | As métricas são valores numéricos que descrevem um aspeto de um sistema em um determinado momento. Agregue métricas usando algoritmos, compare métricas com outras métricas e analise métricas para detetar tendências ao longo do tempo. | - Recolhido automaticamente a intervalos regulares.
- Você pode rotear algumas métricas da plataforma para um espaço de trabalho do Log Analytics para consultar outros dados. Verifique a configuração de exportação do DS para cada métrica para ver se você pode usar uma configuração de diagnóstico para rotear os dados da métrica. |
Explorador de Métricas | métricas do Azure Data Explorer suportadas pelo Azure Monitor |
| Dados do log de recursos | Os logs são eventos do sistema gravados com um carimbo de data/hora. Os logs podem conter diferentes tipos de dados e ser texto estruturado ou de forma livre. Você pode rotear dados de log de recursos para espaços de trabalho do Log Analytics para consulta e análise. | Criar uma configuração de diagnóstico para coletar e rotear dados de log de recursos. | Análise de logs | dados de log de recursos do Azure Data Explorer suportados pelo Azure Monitor |
| Dados do registo de atividades | O log de atividades do Azure Monitor fornece informações sobre eventos no nível de assinatura. O log de atividades inclui informações como quando um recurso é modificado ou uma máquina virtual é iniciada. | - Recolhido automaticamente.
- Crie uma configuração de diagnóstico para um espaço de trabalho do Log Analytics gratuitamente. |
Registo de atividades |
Para obter a lista de todos os dados suportados pelo Azure Monitor, consulte:
Monitorização incorporada para Azure Data Explorer
O Azure Data Explorer oferece métricas e logs para monitorar o serviço.
Monitorize o desempenho, a saúde e a utilização do Azure Data Explorer utilizando métricas
As métricas do Azure Data Explorer fornecem indicadores-chave sobre a saúde e o desempenho dos recursos do cluster Azure Data Explorer. Use as métricas para monitorar o uso, a integridade e o desempenho do cluster do Azure Data Explorer em seu cenário específico como métricas autônomas. Você também pode usar métricas como base para operacionais
Para usar métricas para monitorar seus recursos do Azure Data Explorer no portal do Azure:
- Inicie sessão no portal do Azure.
- No painel esquerdo do cluster do Azure Data Explorer, pesquise métricas .
- Selecione Métricas para abrir o painel de métricas e iniciar a análise do seu cluster.
No painel de métricas, selecione métricas específicas para acompanhar, escolha como agregar seus dados e crie gráficos de métricas para exibir em seu painel.
Os seletores de Recursos e Namespace de Métricas estão pré-selecionados para o seu cluster do Azure Data Explorer. Os números na imagem seguinte correspondem à lista numerada. Eles guiam você por diferentes opções na configuração e visualização de suas métricas.

- Para criar um gráfico de métricas, selecione nome da métrica e agregação relevantes por métrica. Para obter mais informações sobre métricas diferentes, consulte métricas suportadas do Azure Data Explorer.
- Selecione Adicionar métrica para ver várias métricas plotadas no mesmo gráfico.
- Selecione + Novo gráfico para ver vários gráficos em uma visualização.
- Use o seletor de tempo para alterar o intervalo de tempo (padrão: últimas 24 horas).
- Use Adicionar filtro e Aplicar divisão para métricas que tenham dimensões.
- Selecione Fixar no dashboard para adicionar a configuração do gráfico aos dashboards para que possa visualizá-la novamente.
- Defina uma nova regra de alerta para visualizar as suas métricas usando os critérios definidos. A nova regra de alerta inclui o recurso de destino, a métrica, a fragmentação, e as dimensões de filtro do gráfico. Modifique essas configurações no painel de criação de regras de alerta .
Monitorar a ingestão, comandos, consultas e tabelas do Azure Data Explorer usando logs de diagnóstico
O Azure Data Explorer é um serviço de análise de dados rápido e totalmente gerenciado para análise em tempo real de grandes volumes de streaming de dados de aplicativos, sites, dispositivos IoT e muito mais. Os registos de recursos Azure Monitor fornecem dados sobre o funcionamento dos recursos Azure. O Azure Data Explorer usa logs de diagnóstico para obter informações sobre ingestão, comandos, consultas e tabelas. Você pode exportar logs de operação para o Armazenamento do Azure, hub de eventos ou Log Analytics para monitorar a ingestão, os comandos e o status da consulta. Os logs do Armazenamento do Azure e dos Hubs de Eventos do Azure podem ser roteados para uma tabela no cluster do Azure Data Explorer para análise adicional.
Importante
Os dados de registo de diagnóstico podem conter dados sensíveis. Restrinja as permissões do destino dos logs de acordo com suas necessidades de monitoramento.
Observação
No portal do Azure, os dados brutos de métricas para as páginas Metrics e Insights são armazenados no Azure Monitor. As consultas nessas páginas consultam os dados brutos de métricas diretamente para fornecer os resultados mais precisos. Ao usar o recurso de configurações de diagnóstico, você pode migrar os dados brutos de métricas para o espaço de trabalho do Log Analytics. Durante a migração, alguma precisão de dados pode ser perdida devido a arredondamentos; portanto, os resultados da consulta podem variar ligeiramente dos dados originais. A margem de erro é inferior a um por cento.
Pode usar registos de diagnóstico para configurar a recolha dos seguintes dados de registo:
Observação
- Os registos de ingestão suportam a ingestão em fila para o URI de ingestão de dados utilizando bibliotecas de cliente Kusto e conectores de dados.
- Os registos de ingestão não suportam ingestão em streaming, ingestão direta para o URI do Cluster, ingestão a partir de consulta ou
.set-or-appendcomandos.
Observação
Registos de falhas de ingestão reportam apenas o estado final de uma operação de ingestão, ao contrário da métrica de resultado de ingestão, que é emitida para falhas transitórias que são tentadas novamente internamente.
- Operações de ingestão bem-sucedidas: Estes registos contêm informações sobre operações de ingestão concluídas com sucesso.
- Operações de ingestão falhadas: Estes registos contêm informações detalhadas sobre operações de ingestão falhadas, incluindo detalhes de erros.
- Operações de processamento em lote: Estes registos contêm estatísticas detalhadas de lotes prontos para ingestão, como duração, tamanho do lote, contagem de blobs e tipos de loteamento.
Pode enviar os dados do log para um espaço de trabalho de Log Analytics, uma conta de armazenamento ou transmiti-los para um hub de eventos.
Os logs de diagnóstico são desabilitados por padrão. Use as seguintes etapas para habilitar os logs de diagnóstico para o cluster:
No portal Azure, selecione o recurso de cluster que pretende monitorizar.
Em Monitorização, selecione Configurações de Diagnóstico.
Selecione Adicionar configuração de diagnóstico.
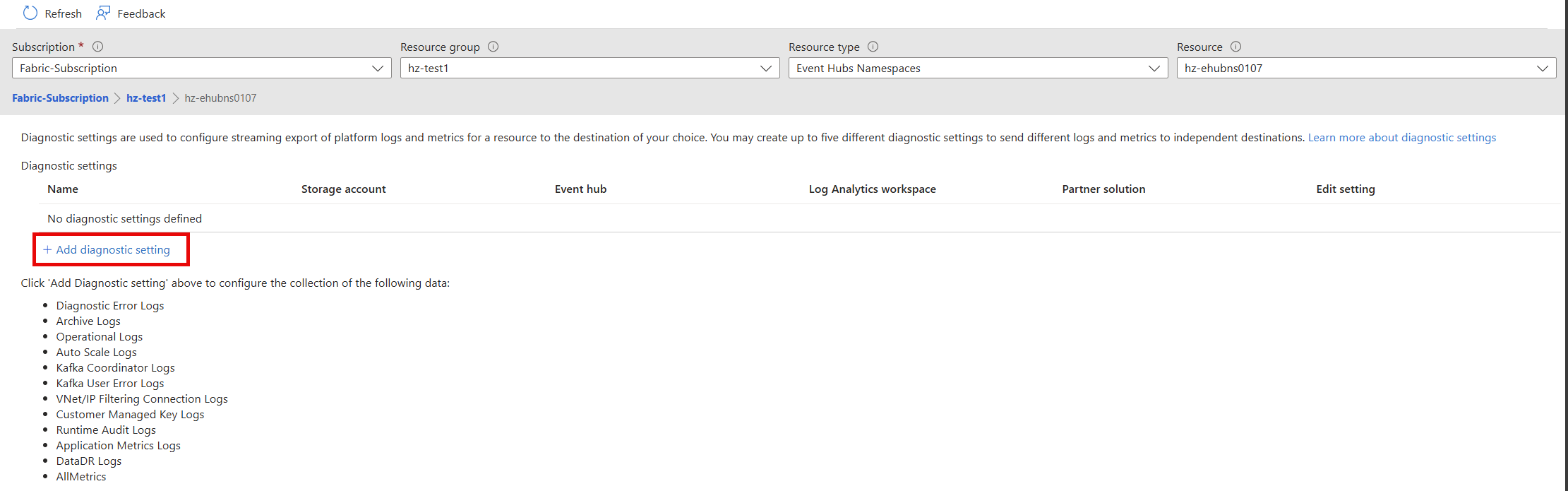
Na janela
Configurações de diagnóstico: 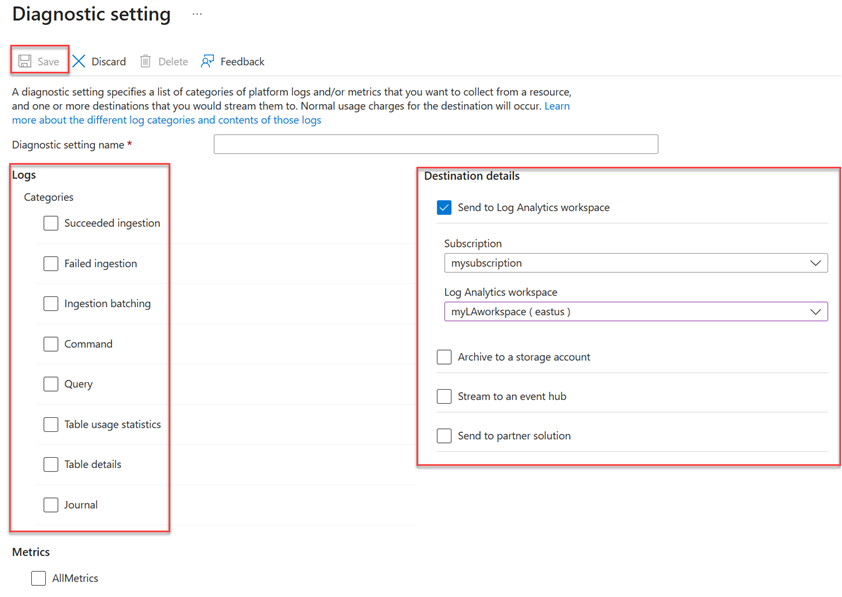
- Insira um nome de configuração de diagnóstico .
- Selecione um ou mais destinos de destino: um espaço de trabalho do Log Analytics, uma conta de armazenamento ou um hub de eventos.
- Selecione registos a recolher: Ingestão bem-sucedida, Ingestão falhada, Lote de ingestão, Comando, Consulta, Estatísticas de utilização da Tabela, Detalhes da Tabela ou Diário.
- Selecione métricas para recolher (opcional).
- Selecione Guardar para guardar as novas configurações e métricas de registos de diagnóstico.



Depois de criar as definições, os registos começam a aparecer nos destinos configurados: uma conta de armazenamento, um hub de eventos ou um espaço de trabalho de Log Analytics.
Observação
Se você enviar logs para um espaço de trabalho do Log Analytics, os logs SucceededIngestion, FailedIngestion, IngestionBatching, Command, Query, TableUsageStatistics, TableDetailse Journal serão armazenados em tabelas do Log Analytics denominadas: SucceededIngestion, FailedIngestion, ADXIngestionBatching, ADXCommand, ADXQuery, ADXTableUsageStatistics, ADXTableDetailse ADXJournal respectivamente.
Usar as ferramentas do Azure Monitor para analisar os dados
Estas ferramentas do Azure Monitor estão disponíveis no portal do Azure para ajudá-lo a analisar dados de monitoramento:
Alguns serviços do Azure têm um painel de monitoramento interno no portal do Azure. Esses painéis são chamados de
insights , e você pode encontrá-los na seção doInsights do Azure Monitor no portal do Azure. explorador de métricas permite exibir e analisar métricas para recursos do Azure. Para obter mais informações, consulte Analisar métricas com o explorador de métricas do Azure Monitor.
do Log Analytics permite consultar e analisar dados de log usando a linguagem de consulta Kusto (KQL). Para obter mais informações, consulte Introdução às consultas de log no Azure Monitor.
O portal do Azure tem uma interface de usuário para exibição e pesquisas básicas do log de atividades . Para fazer uma análise mais aprofundada, encaminhe os dados para os logs do Azure Monitor e execute consultas mais complexas no Log Analytics.
Application Insights monitora a disponibilidade, o desempenho e o uso de seus aplicativos Web, para que você possa identificar e diagnosticar erros sem esperar que um usuário os relate.
Application Insights inclui pontos de conexão para várias ferramentas de desenvolvimento e integra-se ao Visual Studio para dar suporte aos seus processos de DevOps. Para obter mais informações, consulte monitoramento de aplicativos para o Serviço de Aplicativo.
As ferramentas que permitem uma visualização mais complexa incluem:
- Painéis que permitem combinar diferentes tipos de dados em um único painel no portal do Azure.
- Livros de Trabalho, relatórios personalizáveis que pode criar no portal do Azure. Os cadernos podem incluir texto, métricas e consultas de log.
- Grafana, uma ferramenta de plataforma aberta que se destaca em dashboards operacionais. Você pode usar o Grafana para criar painéis que incluem dados de várias fontes diferentes do Azure Monitor.
- o Power BI, um serviço de análise de negócios que fornece visualizações interativas em várias fontes de dados. Você pode configurar o Power BI para importar automaticamente dados de log do Azure Monitor para aproveitar essas visualizações.
Exportar dados do Azure Monitor
Você pode exportar dados do Azure Monitor para outras ferramentas usando:
Métricas: Utilize a API REST para métricas para extrair dados de métricas da base de dados de métricas do Azure Monitor. Para obter mais informações, consulte referência da API REST do Azure Monitor.
Logs: Utilize a API REST ou as bibliotecas de cliente associadas.
A exportação de dados do espaço de trabalho do Log Analytics.
Para começar a usar a API REST do Azure Monitor, consulte passo a passo da API REST de monitoramento do Azure.
Utilize consultas Kusto para analisar dados de log
Você pode analisar os dados do Log do Azure Monitor usando a linguagem de consulta Kusto (KQL). Para mais informações, consulte Log queries no Azure Monitor.
Usar alertas do Azure Monitor para notificá-lo sobre problemas
Os alertas do Azure Monitor permitem que identifique e aborde problemas no seu sistema, notificando-o proativamente quando condições específicas são encontradas nos seus dados de monitorização antes que os seus clientes as percebam. Você pode alertar sobre qualquer fonte de dados de métrica ou log na plataforma de dados do Azure Monitor. Há tipos diferentes de alertas do Azure Monitor dependendo dos serviços que você está monitorando e dos dados de monitoramento que está coletando. Consulte Escolher o tipo certo de regra de alerta.
Para obter exemplos de alertas comuns para recursos do Azure, consulte Consultas de alerta de log de exemplo.
Implementação de alertas em escala
Para alguns serviços, você pode monitorar em escala aplicando a mesma regra de alerta de métrica a vários recursos do mesmo tipo que existem na mesma região do Azure. Alertas de Linha de Base do Azure Monitor (AMBA) fornece um método semiautomatizado para implementar, à escala, alertas métricos importantes da plataforma, painéis de controlo e diretrizes.
Obtenha recomendações personalizadas usando o Azure Advisor
Para alguns serviços, se ocorrerem condições críticas ou alterações iminentes durante as operações de recursos, um alerta será exibido na página Visão geral do serviço no portal. Pode encontrar mais informações e correções recomendadas para o alerta em Recomendações do Advisor, sob Monitorização no menu à esquerda. Durante as operações normais, nenhuma recomendação do consultor é exibida.
Para obter mais informações sobre o Azure Advisor, consulte visão geral do Azure Advisor.