Serviços associados no Azure Data Factory e no Azure Synapse Analytics
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este artigo descreve o que são serviços vinculados, como eles são definidos no formato JSON e como são usados no Azure Data Factory e no Azure Synapse Analytics.
Para saber mais, leia o artigo introdutório do Azure Data Factory ou do Azure Synapse.
Descrição geral
O Azure Data Factory e o Azure Synapse Analytics podem ter um ou mais pipelines. Um pipeline é um agrupamento lógico de atividades que, juntas, executam uma tarefa. As atividades num pipeline definem as ações a executar nos seus dados. Por exemplo, você pode usar uma atividade de cópia para copiar dados do SQL Server para o armazenamento de Blob do Azure. Em seguida, você pode usar uma atividade do Hive que executa um script do Hive em um cluster do Azure HDInsight para processar dados do armazenamento de Blob para produzir dados de saída. Por fim, pode utilizar uma segunda atividade de cópia para copiar os dados de saída para o Azure Synapse Analytics sobre o qual são criadas soluções de relatórios de business intelligence (BI). Para obter mais informações sobre os pipelines e as atividades, veja Pipelines e atividades.
Agora, um conjunto de dados é uma exibição nomeada de dados que simplesmente aponta ou faz referência aos dados que você deseja usar em suas atividades como entradas e saídas.
Antes de criar um conjunto de dados, você deve criar um serviço vinculado para vincular seu armazenamento de dados ao Data Factory ou ao Synapse Workspace. Os serviços vinculados são muito parecidos com cadeias de conexão, que definem as informações de conexão necessárias para que o serviço se conecte a recursos externos. Pense da seguinte forma: o conjunto de dados representa a estrutura dos dados dentro dos armazenamentos de dados vinculados e o serviço vinculado define a conexão com a fonte de dados. Por exemplo, um serviço vinculado do Armazenamento do Azure vincula uma conta de armazenamento ao serviço. Um conjunto de dados de Blob do Azure representa o contêiner de blob e a pasta dentro dessa conta de Armazenamento do Azure que contém os blobs de entrada a serem processados.
Aqui está um cenário de exemplo. Para copiar dados do armazenamento de Blob para um Banco de Dados SQL, crie dois serviços vinculados: Armazenamento do Azure e Banco de Dados SQL do Azure. Em seguida, crie dois conjuntos de dados: o conjunto de dados Blob do Azure (que se refere ao serviço vinculado do Armazenamento do Azure) e o conjunto de dados da Tabela SQL do Azure (que se refere ao serviço vinculado do Banco de Dados SQL do Azure). Os serviços vinculados do Armazenamento do Azure e do Banco de Dados SQL do Azure contêm cadeias de conexão que o serviço usa em tempo de execução para se conectar ao Armazenamento do Azure e ao Banco de Dados SQL do Azure, respectivamente. O conjunto de dados de Blob do Azure especifica o contêiner de blob e a pasta de blob que contém os blobs de entrada em seu armazenamento de Blob. O conjunto de dados Tabela SQL do Azure especifica a tabela SQL em seu Banco de Dados SQL para a qual os dados devem ser copiados.
O diagrama a seguir mostra as relações entre pipeline, atividade, conjunto de dados e serviço vinculado no serviço:
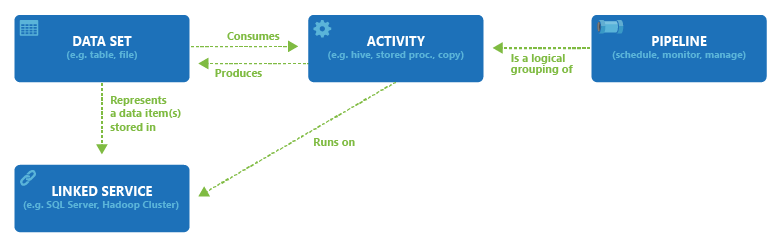
Serviço vinculado com interface do usuário
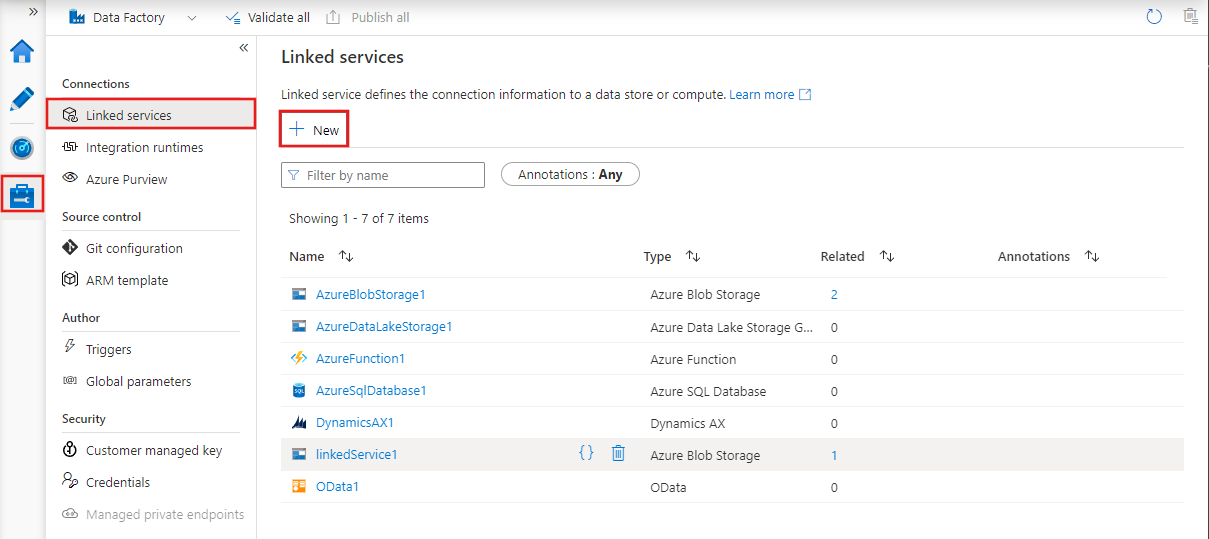
Para criar um novo serviço vinculado no Azure Data Factory Studio, selecione a guia Gerenciar e, em seguida, serviços vinculados, onde você pode ver todos os serviços vinculados existentes que você definiu. Selecione + Novo para criar um novo serviço vinculado.
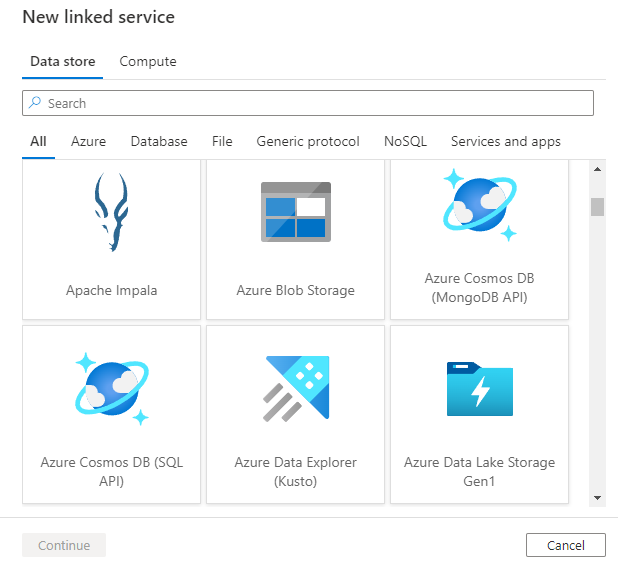
Depois de selecionar + Novo para criar um novo serviço vinculado, você pode escolher qualquer um dos conectores suportados e configurar seus detalhes de acordo. Depois disso, você pode usar o serviço vinculado em qualquer pipeline que criar.
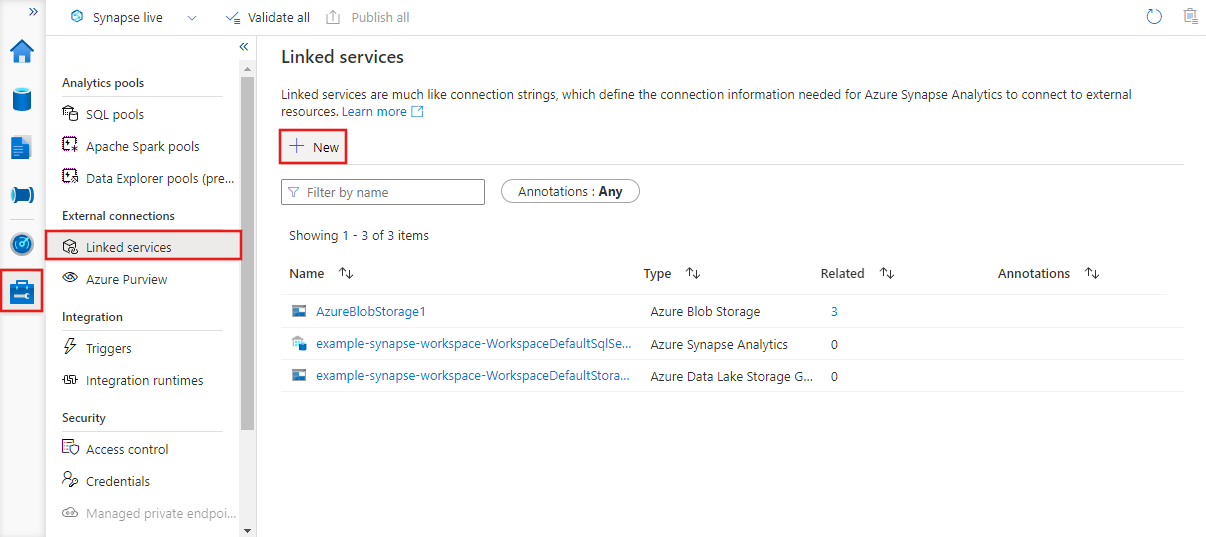
JSON de serviço vinculado
Um serviço vinculado é definido no formato JSON da seguinte forma:
{
"name": "<Name of the linked service>",
"properties": {
"type": "<Type of the linked service>",
"typeProperties": {
"<data store or compute-specific type properties>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
A tabela a seguir descreve as propriedades no JSON acima:
| Property | Descrição | Obrigatório |
|---|---|---|
| nome | Nome do serviço vinculado. Consulte Regras de nomenclatura. | Sim |
| tipo | Tipo de serviço vinculado. Por exemplo: AzureBlobStorage (armazenamento de dados) ou AzureBatch (computação). Consulte a descrição para typeProperties. | Sim |
| typeProperties | As propriedades de tipo são diferentes para cada armazenamento de dados ou computação. Para obter os tipos de armazenamento de dados suportados e suas propriedades de tipo, consulte o artigo de visão geral do conector. Navegue até o artigo do conector do armazenamento de dados para saber mais sobre as propriedades de tipo específicas de um armazenamento de dados. Para obter os tipos de computação suportados e suas propriedades de tipo, consulte Serviços vinculados de computação. |
Sim |
| ConecteVia | O tempo de execução de integração a ser usado para se conectar ao armazenamento de dados. Você pode usar o Azure Integration Runtime ou o Self-hosted Integration Runtime (se o armazenamento de dados estiver localizado em uma rede privada). Se não for especificado, ele usará o Tempo de Execução de Integração do Azure padrão. | Não |
Exemplo de serviço vinculado
O serviço vinculado a seguir é um serviço vinculado de armazenamento de Blob do Azure. Observe que o tipo está definido como armazenamento de Blob do Azure. As propriedades de tipo para o serviço vinculado de armazenamento de Blob do Azure incluem uma cadeia de conexão. O serviço usa essa cadeia de conexão para se conectar ao armazenamento de dados em tempo de execução.
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=<accountkey>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Criar serviços ligados
Os serviços vinculados podem ser criados na UX do Azure Data Factory por meio do hub de gerenciamento e de quaisquer atividades, conjuntos de dados ou fluxos de dados que os referenciam.
Você pode criar serviços vinculados usando uma destas ferramentas ou SDKs: API .NET, PowerShell, API REST, Modelo do Azure Resource Manager e Portal do Azure.
Ao criar um serviço vinculado, o usuário precisa de autorização apropriada para o serviço designado. Se o acesso suficiente não for concedido, o usuário não poderá ver os recursos disponíveis e precisará usar a opção de entrada manual.
Serviços vinculados ao armazenamento de dados
Você pode encontrar a lista de armazenamentos de dados suportados no artigo de visão geral do conector. Selecione um armazenamento de dados para saber as propriedades de conexão suportadas.
Serviços ligados de computação
Ambientes de computação de referência suportados para obter detalhes sobre diferentes ambientes de computação aos quais você pode se conectar a partir do seu serviço e as diferentes configurações.
Conteúdos relacionados
- Saiba como usar credenciais de uma identidade gerenciada atribuída pelo usuário em um serviço vinculado.
Consulte os tutoriais a seguir para obter instruções passo a passo para criar pipelines e conjuntos de dados usando uma dessas ferramentas ou SDKs.