Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
O Azure Data Factory fornece um mecanismo de desempenho, robusto e econômico para migrar dados em escala do Amazon S3 para o Armazenamento de Blobs do Azure ou para o Azure Data Lake Storage Gen2. Este artigo fornece as seguintes informações para engenheiros de dados e desenvolvedores:
- Desempenho
- Resiliência de cópia
- Segurança da rede
- Arquitetura de solução de alto nível
- Melhores práticas de implementação
Desempenho
O ADF oferece uma arquitetura sem servidor que permite paralelismo em diferentes níveis, o que permite que os desenvolvedores criem pipelines para utilizar totalmente a largura de banda da rede e as IOPS de armazenamento e a largura de banda para maximizar a taxa de transferência de movimentação de dados para seu ambiente.
Os clientes migraram com êxito petabytes de dados que consistem em centenas de milhões de arquivos do Amazon S3 para o Armazenamento de Blobs do Azure, com uma taxa de transferência sustentada de 2 GBps ou superior.
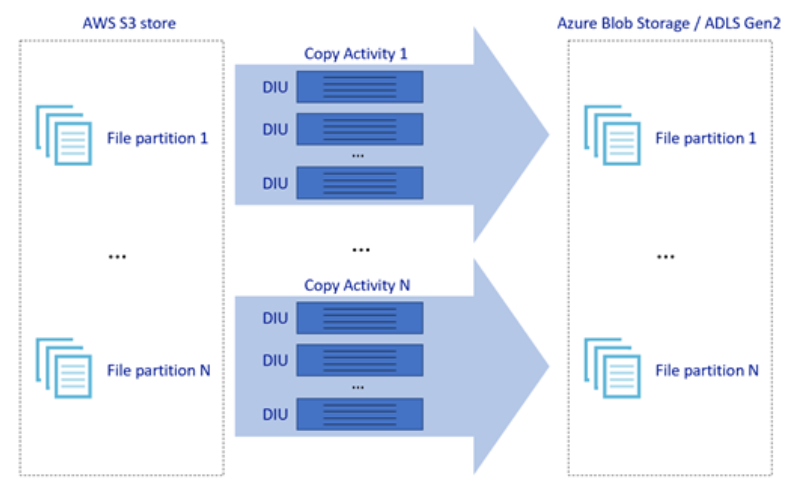
A imagem acima ilustra como você pode alcançar grandes velocidades de movimento de dados através de diferentes níveis de paralelismo:
- Uma única atividade de cópia pode tirar proveito dos recursos de computação escaláveis: ao usar o Tempo de Execução de Integração do Azure, você pode especificar até 256 DIUs para cada atividade de cópia de maneira sem servidor, ao usar o Tempo de Execução de Integração auto-hospedado, você pode escalar manualmente a máquina ou dimensionar para várias máquinas (até quatro nós), e uma única atividade de cópia particionará seu conjunto de arquivos em todos os nós.
- Uma única atividade de cópia lê e grava no armazenamento de dados usando vários threads.
- O fluxo de controle do ADF pode iniciar várias atividades de cópia em paralelo, por exemplo, usando For Each loop.
Resiliência
Dentro de uma única execução de atividade de cópia, o ADF tem mecanismo de repetição integrado para que possa lidar com um certo nível de falhas transitórias nos armazenamentos de dados ou na rede subjacente.
Ao fazer cópias binárias do S3 para o Blob e do S3 para o ADLS Gen2, o ADF executa automaticamente o checkpointing. Se a execução de uma atividade de cópia tiver falhado ou expirado, em uma nova tentativa subsequente, a cópia será retomada a partir do último ponto de falha em vez de começar do início.
Segurança da rede
Por padrão, o ADF transfere dados do Amazon S3 para o Armazenamento de Blobs do Azure ou para o Azure Data Lake Storage Gen2 usando conexão criptografada pelo protocolo HTTPS. O HTTPS fornece criptografia de dados em trânsito e evita escutas e ataques man-in-the-middle.
Como alternativa, se você não quiser que os dados sejam transferidos pela Internet pública, poderá obter maior segurança transferindo dados por meio de um link de emparelhamento privado entre o AWS Direct Connect e o Azure Express Route. Consulte a arquitetura da solução na próxima seção sobre como isso pode ser alcançado.
Arquitetura de soluções
Migrar dados pela Internet pública:
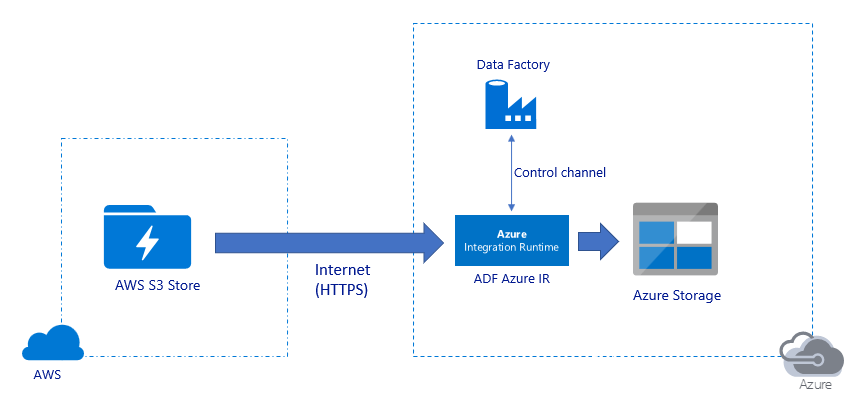
- Nessa arquitetura, os dados são transferidos com segurança usando HTTPS pela Internet pública.
- Tanto o Amazon S3 de origem quanto o Armazenamento de Blobs do Azure de destino ou o Azure Data Lake Storage Gen2 são configurados para permitir o tráfego de todos os endereços IP da rede. Consulte a segunda arquitetura mencionada mais adiante nesta página sobre como você pode restringir o acesso à rede a um intervalo de IP específico.
- Você pode facilmente aumentar a quantidade de potência sem servidor para utilizar totalmente sua rede e largura de banda de armazenamento para que você possa obter a melhor taxa de transferência para seu ambiente.
- Tanto a migração inicial de snapshot quanto a migração de dados delta podem ser obtidas usando essa arquitetura.
Migrar dados por link privado:
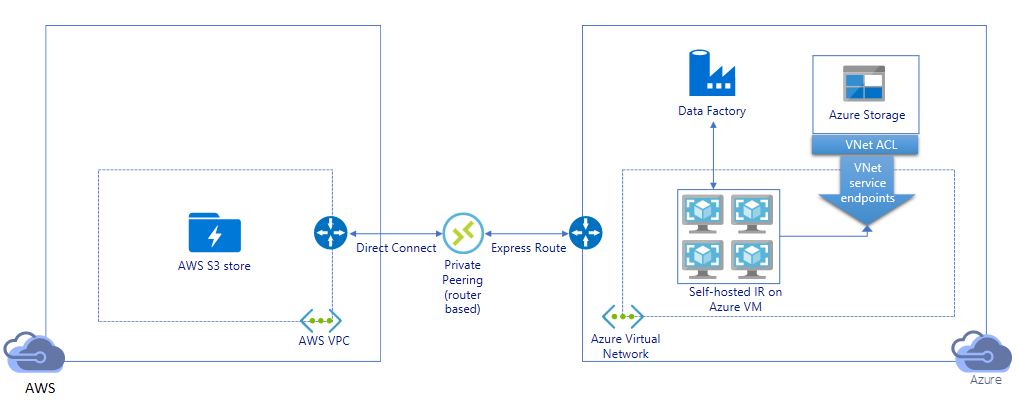
- Nessa arquitetura, a migração de dados é feita por meio de um link de emparelhamento privado entre o AWS Direct Connect e o Azure Express Route, de modo que os dados nunca atravessem a Internet pública. Requer o uso da AWS VPC e da rede virtual do Azure.
- Você precisa instalar o tempo de execução de integração auto-hospedado do ADF em uma máquina virtual Windows na sua rede virtual Azure para obter essa arquitetura. Você pode dimensionar manualmente suas VMs IR auto-hospedadas ou expandir para várias VMs (até quatro nós) para utilizar totalmente suas IOPS/largura de banda de rede e armazenamento.
- Tanto a migração inicial de dados de snapshot como a migração de dados delta podem ser realizadas utilizando esta arquitetura.
Melhores práticas de implementação
Autenticação e gerenciamento de credenciais
- Para autenticar na conta do Amazon S3, você deve usar a chave de acesso da conta do IAM.
- Há suporte para vários tipos de autenticação para se conectar ao Armazenamento de Blobs do Azure. O uso de identidades geridas para recursos do Azure é altamente recomendado: criado com base numa identidade ADF gerida automaticamente no ID do Microsoft Entra, permite configurar pipelines sem fornecer credenciais na definição de Serviço Ligado. Como alternativa, você pode autenticar no Armazenamento de Blobs do Azure usando a Entidade de Serviço, a assinatura de acesso compartilhado ou a chave da conta de armazenamento.
- Vários tipos de autenticação também são suportados para se conectar ao Azure Data Lake Storage Gen2. O uso de identidades geridas para recursos do Azure é altamente recomendado, embora principal de serviço ou chave da conta de armazenamento também possam ser utilizados.
- Quando você não estiver usando identidades gerenciadas para recursos do Azure, o armazenamento das credenciais no Cofre da Chave do Azure é altamente recomendado para facilitar o gerenciamento centralizado e a rotação de chaves sem modificar os serviços vinculados do ADF. Esta é também uma das melhores práticas para CI/CD.
Migração inicial de dados de snapshot
A partição de dados é recomendada especialmente ao migrar mais de 100 TB de dados. Para particionar os dados, use a configuração 'prefixo' para filtrar as pastas e arquivos no Amazon S3 pelo nome e, em seguida, cada trabalho de cópia do ADF pode copiar uma partição de cada vez. Pode executar vários trabalhos de cópia do ADF ao mesmo tempo para melhorar a taxa de transferência.
Se algum dos trabalhos de cópia falhar devido a um problema transitório de rede ou armazenamento de dados, você poderá executar novamente o trabalho de cópia com falha para recarregar essa partição específica novamente a partir do AWS S3. Todos os outros trabalhos de cópia que carregam outras partições não serão afetados.
Migração de dados Delta
A maneira mais eficiente de identificar arquivos novos ou alterados do AWS S3 é usando a convenção de nomenclatura particionada por tempo - quando seus dados no AWS S3 foram particionados por tempo com informações de fatia de tempo no nome do arquivo ou pasta (por exemplo, /aaaa/mm/dd/file.csv), seu pipeline pode identificar facilmente quais arquivos/pastas copiar incrementalmente.
Como alternativa, se seus dados no AWS S3 não estiverem particionados por tempo, o ADF poderá identificar arquivos novos ou alterados por LastModifiedDate. A maneira como funciona é que o ADF analisará todos os ficheiros do AWS S3 e copiará apenas os ficheiros novos e atualizados cujas marcas de tempo da última modificação sejam superiores a um determinado valor. Se você tiver um grande número de arquivos no S3, a verificação inicial do arquivo pode levar muito tempo, independentemente de quantos arquivos correspondem à condição do filtro. Neste caso, recomenda-se particionar os dados primeiro, usando a mesma configuração de 'prefixo' para a migração inicial de snapshots, para que a análise de ficheiros possa acontecer em paralelo.
Para cenários que exigem tempo de execução de integração auto-hospedado na VM do Azure
Se estiver a migrar dados através de link privado ou quiser permitir um intervalo de IP específico no firewall do Amazon S3, precisará instalar o runtime de integração auto-hospedado na máquina virtual (VM) Windows do Azure.
- A configuração recomendada para começar para cada VM do Azure é Standard_D32s_v3 com 32 vCPU e 128 GB de memória. Você pode continuar monitorando a utilização da CPU e da memória da VM IR durante a migração de dados para ver se precisa aumentar ainda mais a escala da VM para obter um melhor desempenho ou reduzir a VM para economizar custos.
- Você também pode expandir associando até quatro nós de VM a um único IR auto-hospedado. Um único trabalho de cópia em execução em um IR auto-hospedado particionará automaticamente o conjunto de arquivos e usará todos os nós da VM para copiar os arquivos em paralelo. Para alta disponibilidade, é recomendável começar com dois nós de VM para evitar um único ponto de falha durante a migração de dados.
Limitação de taxa
Como prática recomendada, conduza um POC de desempenho com um conjunto de dados de exemplo representativo, para que você possa determinar um tamanho de partição apropriado.
Comece com uma única partição e uma única atividade de cópia com a configuração DIU padrão. Aumente gradualmente a configuração de DIU até atingir o limite de largura de banda da sua rede ou o limite de IOPS/largura de banda dos armazenamentos de dados, ou até atingir o máximo de 256 DIU permitido em uma única atividade de cópia.
Em seguida, aumente gradualmente o número de atividades de cópia simultâneas até atingir os limites do seu ambiente.
Quando encontrar erros de limitação relatados pela atividade de cópia do ADF, reduza a simultaneidade ou a configuração de DIU no ADF, ou considere aumentar os limites de largura de banda/IOPS da rede e dos repositórios de dados.
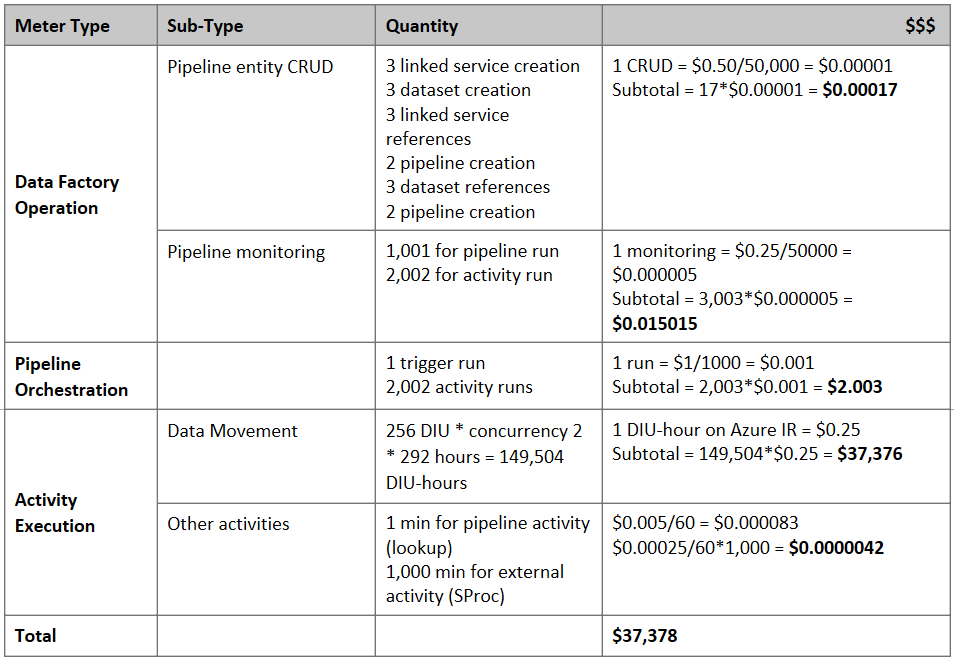
Estimativa de preço
Nota
Este é um exemplo hipotético de preços. Seu preço real depende da taxa de transferência real em seu ambiente.
Considere o seguinte pipeline construído para migrar dados do S3 para o Armazenamento de Blobs do Azure:
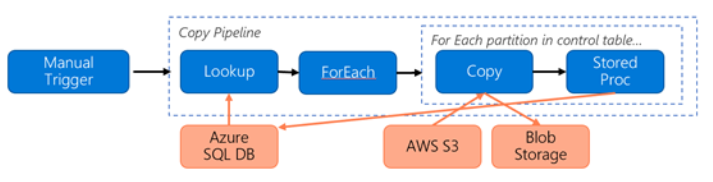
Suponhamos o seguinte:
- O volume total de dados é de 2 PB
- Migrando dados por HTTPS usando a primeira arquitetura de solução
- 2 PB é dividido em partições de 1 KB e cada cópia move uma partição
- Cada cópia é configurada com DIU=256 e atinge uma taxa de transferência de 1 GBps
- A simultaneidade ForEach é definida como 2 e a taxa de transferência agregada é de 2 GBps
- No total, leva 292 horas para concluir a migração
Aqui está o preço estimado com base nas suposições acima:
Referências adicionais
- Conector do Amazon Simple Storage Service
- Conector de armazenamento de Blob do Azure
- Conector do Azure Data Lake Storage Gen2
- Guia de ajuste de desempenho da atividade de cópia
- Criando e configurando o Runtime de Integração autohospedado
- HA e escalabilidade de tempo de execução de integração auto-hospedada
- Considerações sobre segurança de movimentação de dados
- Armazenar credenciais no Cofre da Chave do Azure
- Copie o arquivo incrementalmente com base no nome do arquivo particionado por tempo
- Copiar arquivos novos e alterados com base em LastModifiedDate
- Página de preços do ADF
Modelo
Aqui está o modelo para começar a migrar petabytes de dados que consistem em centenas de milhões de arquivos do Amazon S3 para o Azure Data Lake Storage Gen2.