evento
31/03, 23 - 2/04, 23
O maior evento de aprendizagem de Malha, Power BI e SQL. 31 de março a 2 de abril. Use o código FABINSIDER para economizar $400.
Registe-se hoje mesmoEste browser já não é suportado.
Atualize para o Microsoft Edge para tirar partido das mais recentes funcionalidades, atualizações de segurança e de suporte técnico.
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Use os modelos para migrar petabytes de dados que consistem em centenas de milhões de arquivos do Amazon S3 para o Azure Data Lake Storage Gen2.
Nota
Se você quiser copiar um pequeno volume de dados do AWS S3 para o Azure (por exemplo, menos de 10 TB), é mais eficiente e fácil usar a ferramenta Azure Data Factory Copy Data. O modelo descrito neste artigo é mais do que o que você precisa.
A partição de dados é recomendada especialmente ao migrar mais de 10 TB de dados. Para particionar os dados, aproveite a configuração 'prefixo' para filtrar as pastas e arquivos no Amazon S3 por nome e, em seguida, cada trabalho de cópia do ADF pode copiar uma partição de cada vez. Você pode executar vários trabalhos de cópia do ADF simultaneamente para uma melhor taxa de transferência.
A migração de dados normalmente requer uma migração única de dados históricos, além da sincronização periódica das alterações do AWS S3 para o Azure. Há dois modelos abaixo, em que um modelo aborda a migração de dados históricos única e outro modelo aborda a sincronização das alterações do AWS S3 para o Azure.
Este modelo (nome do modelo: migrar dados históricos do AWS S3 para o Azure Data Lake Storage Gen2) pressupõe que você tenha escrito uma lista de partições em uma tabela de controle externo no Banco de Dados SQL do Azure. Assim, ele usará uma atividade de pesquisa para recuperar a lista de partições da tabela de controle externo, iterar sobre cada partição e fazer com que cada trabalho de cópia do ADF copie uma partição de cada vez. Uma vez concluído qualquer trabalho de cópia, ele usa a atividade de procedimento armazenado para atualizar o status de cópia de cada partição na tabela de controle.
O modelo contém cinco atividades:
O modelo contém dois parâmetros:
Esse modelo (nome do modelo: copiar dados delta do AWS S3 para o Azure Data Lake Storage Gen2) usa LastModifiedTime de cada arquivo para copiar os arquivos novos ou atualizados somente do AWS S3 para o Azure. Esteja ciente de que se seus arquivos ou pastas já foram particionados por tempo com informações de timelice como parte do nome do arquivo ou pasta no AWS S3 (por exemplo, /aaaa/mm/dd/file.csv), você pode ir para este tutorial para obter a abordagem mais eficiente para o carregamento incremental de novos arquivos. Este modelo pressupõe que você tenha escrito uma lista de partições em uma tabela de controle externo no Banco de Dados SQL do Azure. Assim, ele usará uma atividade de pesquisa para recuperar a lista de partições da tabela de controle externo, iterar sobre cada partição e fazer com que cada trabalho de cópia do ADF copie uma partição de cada vez. Quando cada trabalho de cópia começa a copiar os arquivos do AWS S3, ele depende da propriedade LastModifiedTime para identificar e copiar somente os arquivos novos ou atualizados. Uma vez concluído qualquer trabalho de cópia, ele usa a atividade de procedimento armazenado para atualizar o status de cópia de cada partição na tabela de controle.
O modelo contém sete atividades:
O modelo contém dois parâmetros:
Crie uma tabela de controle no Banco de Dados SQL do Azure para armazenar a lista de partições do AWS S3.
Nota
O nome da tabela é s3_partition_control_table. O esquema da tabela de controle é PartitionPrefix e SuccessOrFailure, onde PartitionPrefix é a configuração de prefixo no S3 para filtrar as pastas e arquivos no Amazon S3 por nome, e SuccessOrFailure é o status de copiar cada partição: 0 significa que essa partição não foi copiada para o Azure e 1 significa que essa partição foi copiada para o Azure com êxito. Existem 5 partições definidas na tabela de controle e o status padrão de copiar cada partição é 0.
CREATE TABLE [dbo].[s3_partition_control_table](
[PartitionPrefix] [varchar](255) NULL,
[SuccessOrFailure] [bit] NULL
)
INSERT INTO s3_partition_control_table (PartitionPrefix, SuccessOrFailure)
VALUES
('a', 0),
('b', 0),
('c', 0),
('d', 0),
('e', 0);
Crie um Procedimento Armazenado no mesmo Banco de Dados SQL do Azure para tabela de controle.
Nota
O nome do procedimento armazenado é sp_update_partition_success. Ele será invocado pela atividade SqlServerStoredProcedure em seu pipeline do ADF.
CREATE PROCEDURE [dbo].[sp_update_partition_success] @PartPrefix varchar(255)
AS
BEGIN
UPDATE s3_partition_control_table
SET [SuccessOrFailure] = 1 WHERE [PartitionPrefix] = @PartPrefix
END
GO
Vá para o modelo Migrar dados históricos do AWS S3 para o Azure Data Lake Storage Gen2 . Insira as conexões com sua tabela de controle externo, AWS S3 como o armazenamento de fonte de dados e Azure Data Lake Storage Gen2 como o armazenamento de destino. Lembre-se de que a tabela de controle externo e o procedimento armazenado são referência à mesma conexão.
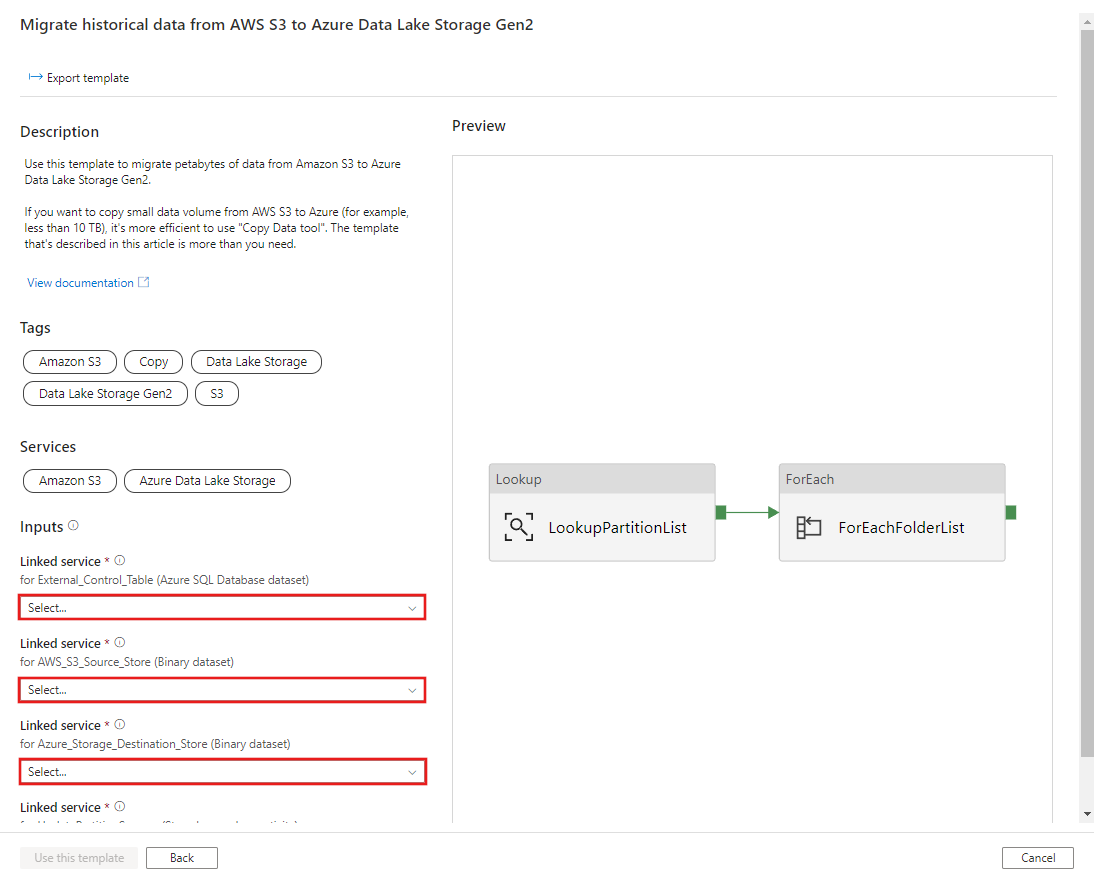
Selecione Utilizar este modelo.
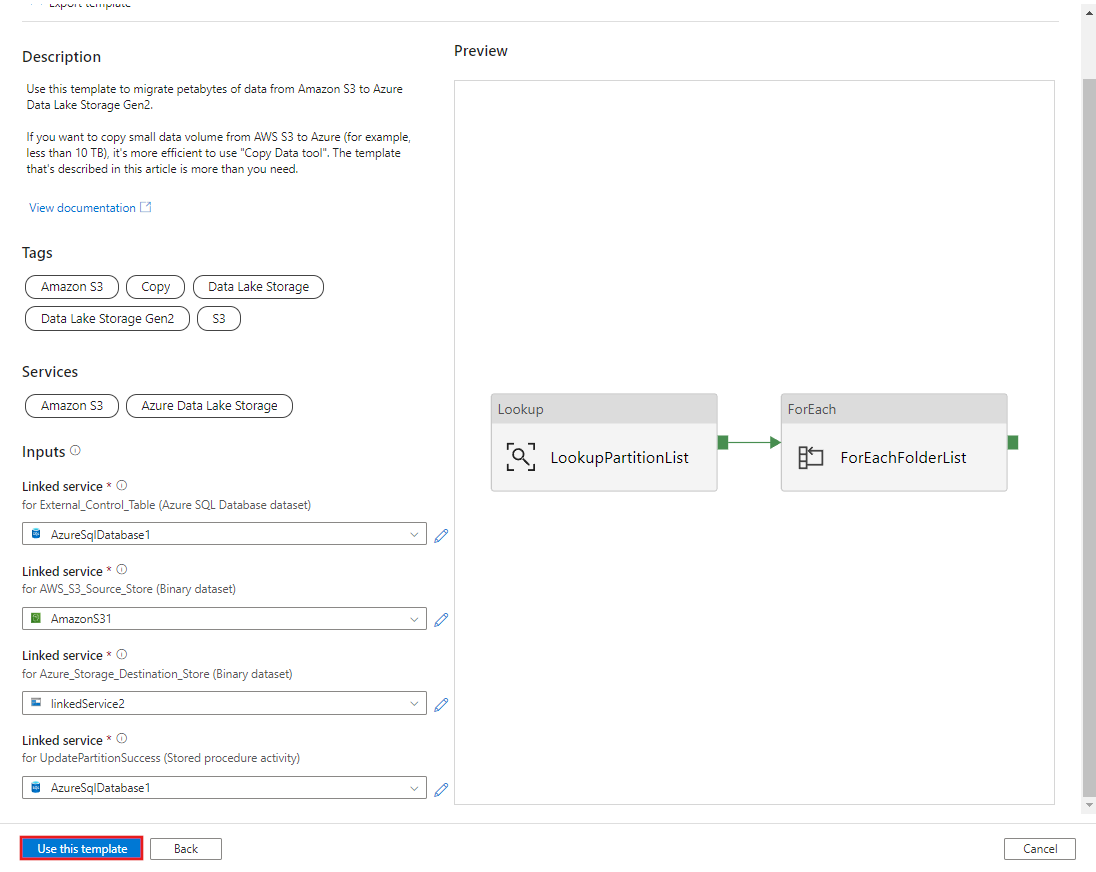
Você vê que os 2 pipelines e 3 conjuntos de dados foram criados, conforme mostrado no exemplo a seguir:
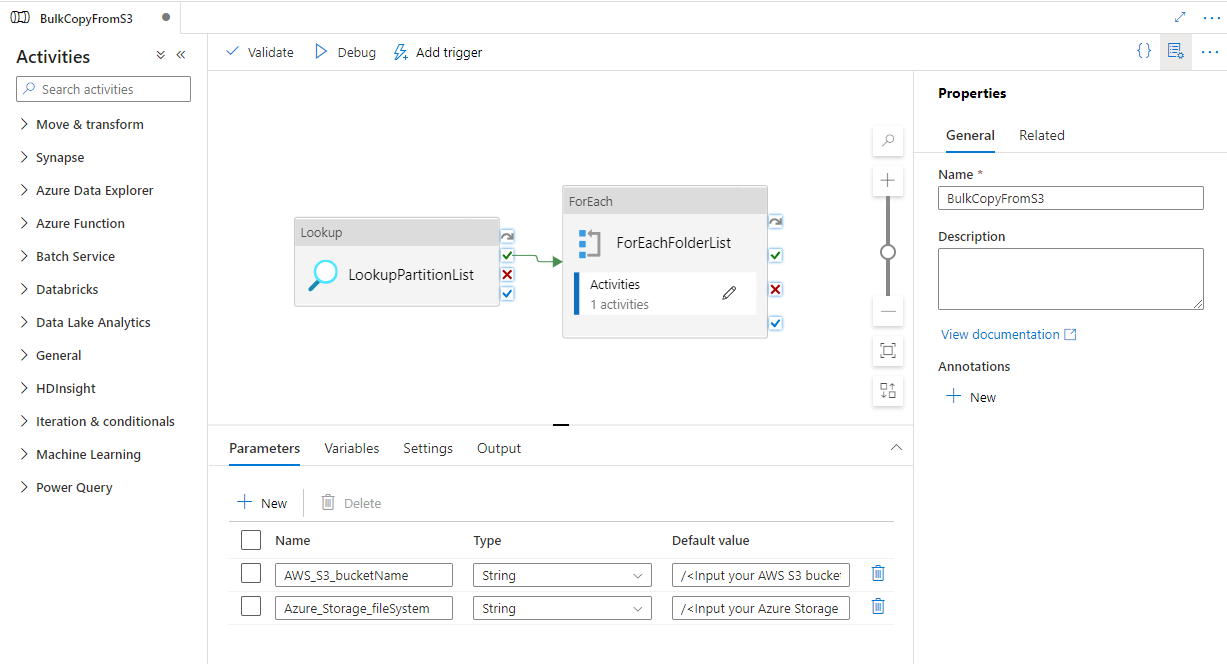
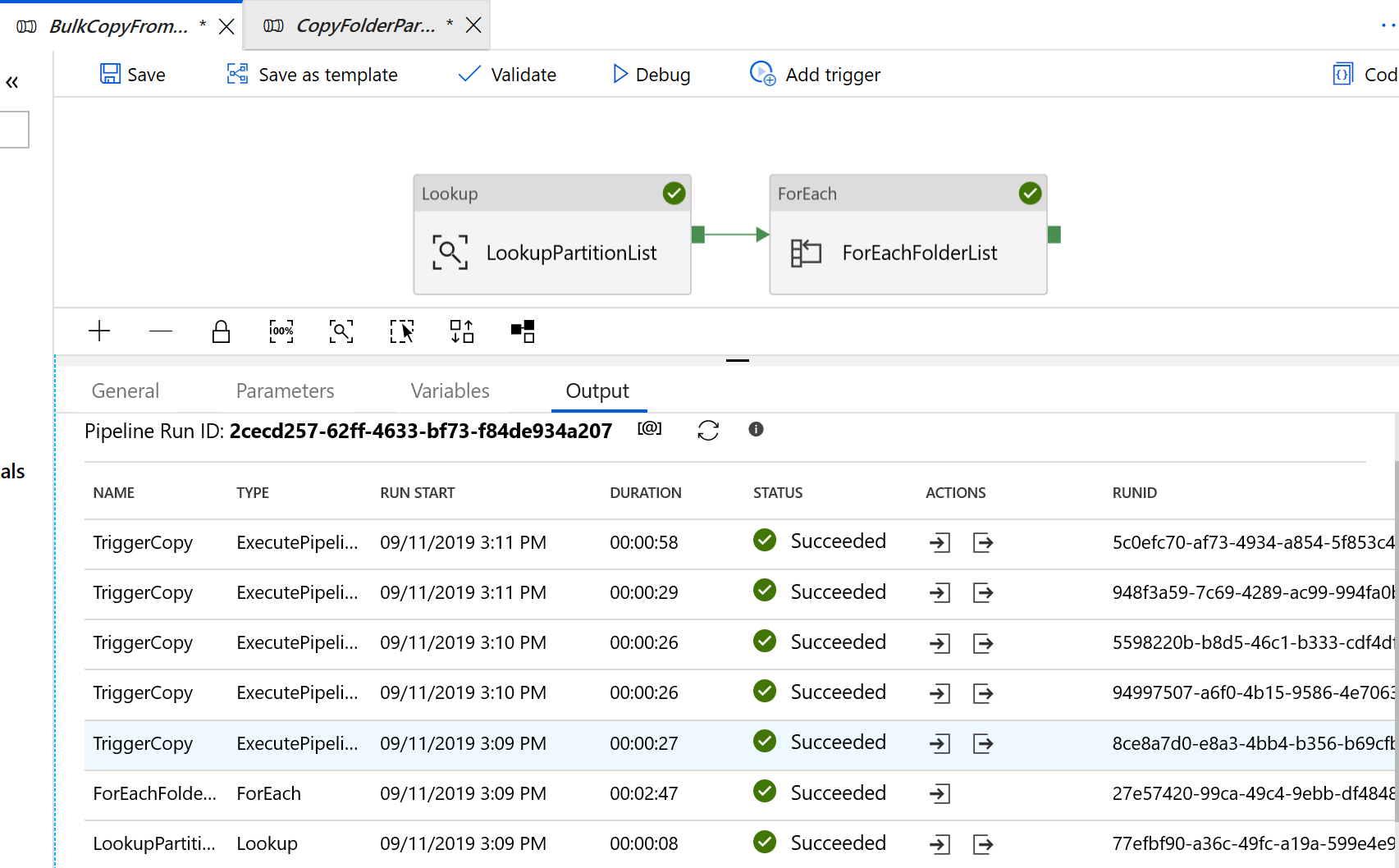
Vá para o pipeline "BulkCopyFromS3" e selecione Depurar, insira os parâmetros. Em seguida, selecione Concluir.
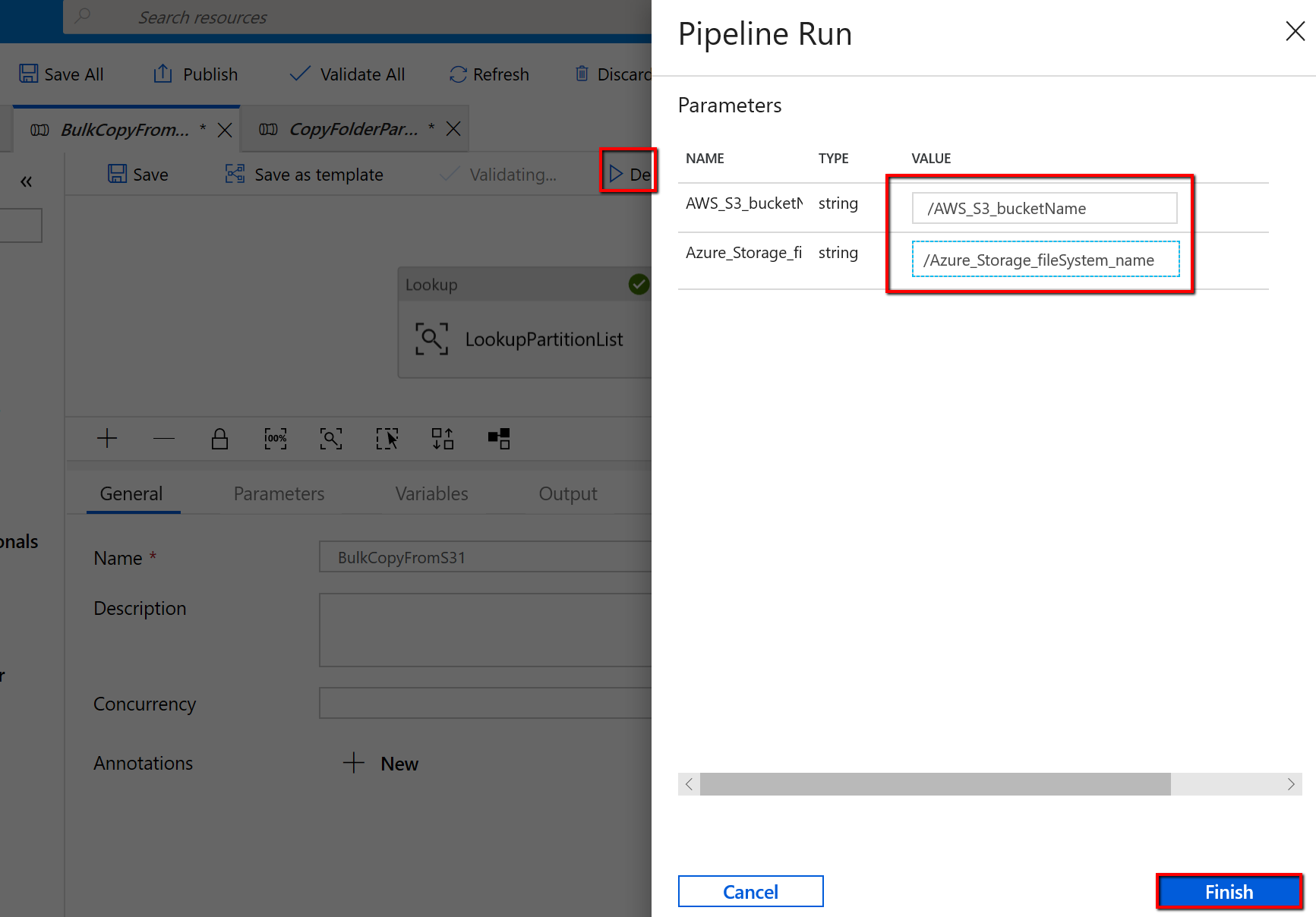
Você vê resultados semelhantes ao exemplo a seguir:
Crie uma tabela de controle no Banco de Dados SQL do Azure para armazenar a lista de partições do AWS S3.
Nota
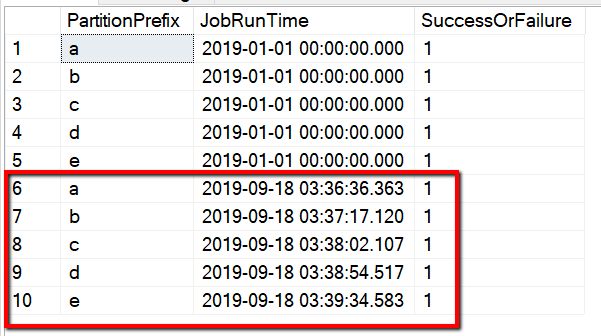
O nome da tabela é s3_partition_delta_control_table. O esquema da tabela de controle é PartitionPrefix, JobRunTime e SuccessOrFailure, onde PartitionPrefix é a configuração de prefixo no S3 para filtrar as pastas e arquivos no Amazon S3 por nome, JobRunTime é o valor datetime quando trabalhos de cópia são executados e SuccessOrFailure é o status de copiar cada partição: 0 significa que essa partição não foi copiada para o Azure e 1 significa que essa partição foi copiada para o Azure com êxito. Existem 5 partições definidas na tabela de controle. O valor padrão para JobRunTime pode ser o momento em que a migração de dados históricos única é iniciada. A atividade de cópia do ADF copiará os arquivos no AWS S3 que foram modificados pela última vez após esse período. O status padrão de copiar cada partição é 1.
CREATE TABLE [dbo].[s3_partition_delta_control_table](
[PartitionPrefix] [varchar](255) NULL,
[JobRunTime] [datetime] NULL,
[SuccessOrFailure] [bit] NULL
)
INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure)
VALUES
('a','1/1/2019 12:00:00 AM',1),
('b','1/1/2019 12:00:00 AM',1),
('c','1/1/2019 12:00:00 AM',1),
('d','1/1/2019 12:00:00 AM',1),
('e','1/1/2019 12:00:00 AM',1);
Crie um Procedimento Armazenado no mesmo Banco de Dados SQL do Azure para tabela de controle.
Nota
O nome do procedimento armazenado é sp_insert_partition_JobRunTime_success. Ele será invocado pela atividade SqlServerStoredProcedure em seu pipeline do ADF.
CREATE PROCEDURE [dbo].[sp_insert_partition_JobRunTime_success] @PartPrefix varchar(255), @JobRunTime datetime, @SuccessOrFailure bit
AS
BEGIN
INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure)
VALUES
(@PartPrefix,@JobRunTime,@SuccessOrFailure)
END
GO
Vá para o modelo Copiar dados delta do AWS S3 para o Azure Data Lake Storage Gen2 . Insira as conexões com sua tabela de controle externo, AWS S3 como o armazenamento de fonte de dados e Azure Data Lake Storage Gen2 como o armazenamento de destino. Lembre-se de que a tabela de controle externo e o procedimento armazenado são referência à mesma conexão.
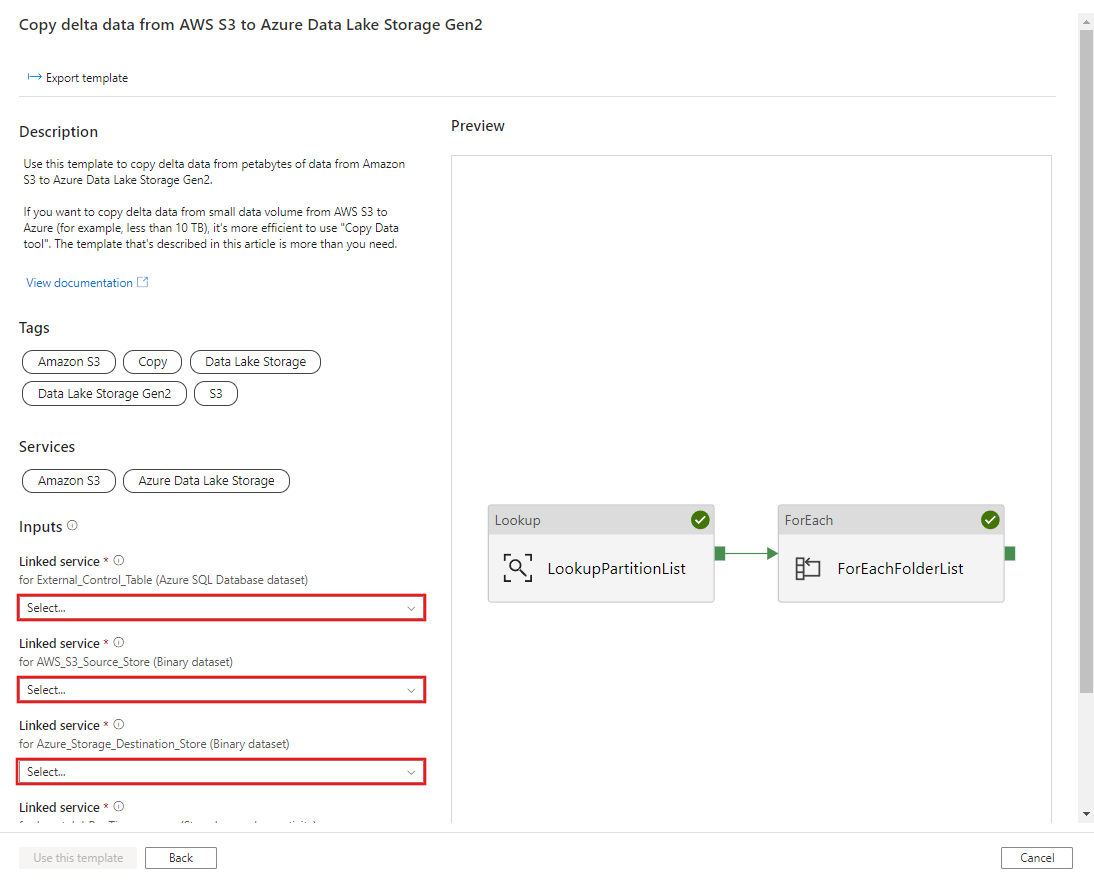
Selecione Utilizar este modelo.
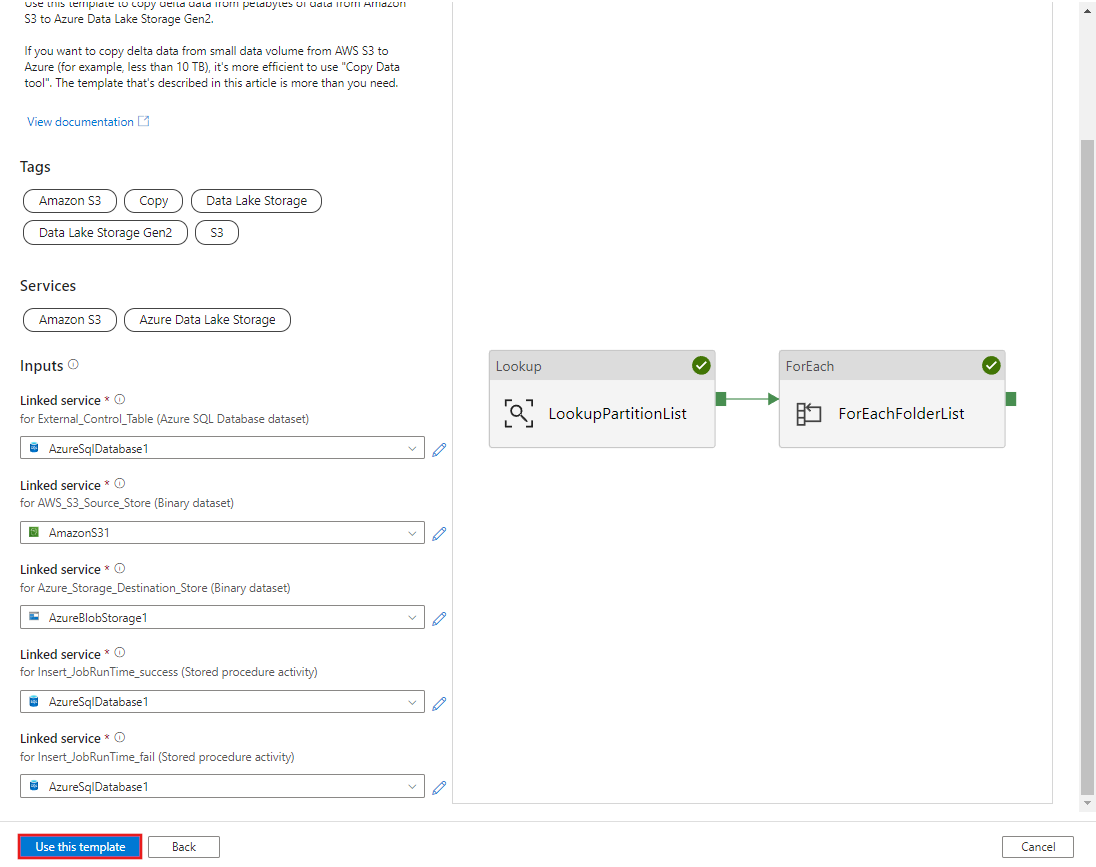
Você vê que os 2 pipelines e 3 conjuntos de dados foram criados, conforme mostrado no exemplo a seguir:

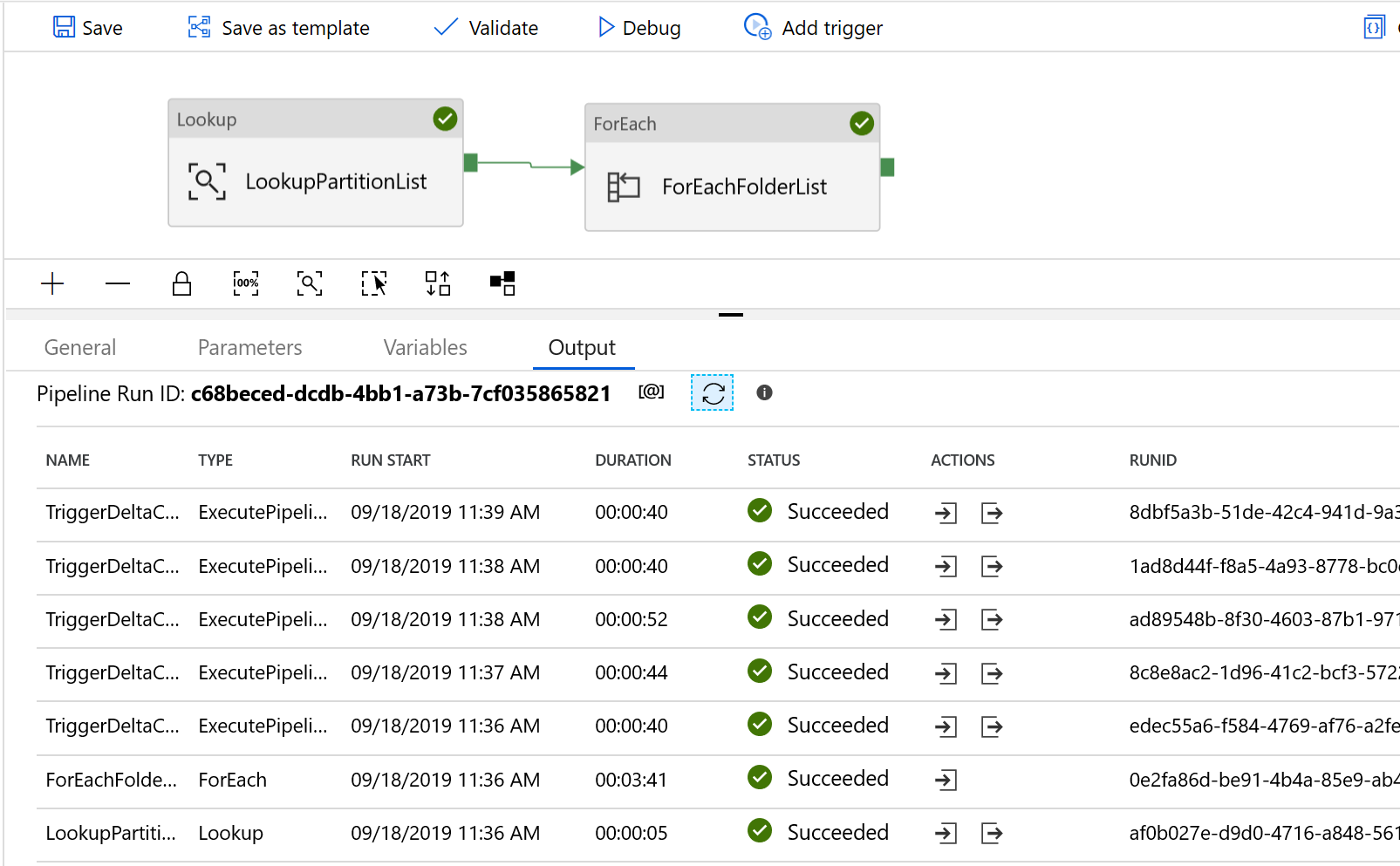
Vá para o pipeline "DeltaCopyFromS3", selecione Depurar e insira os Parâmetros. Em seguida, selecione Concluir.
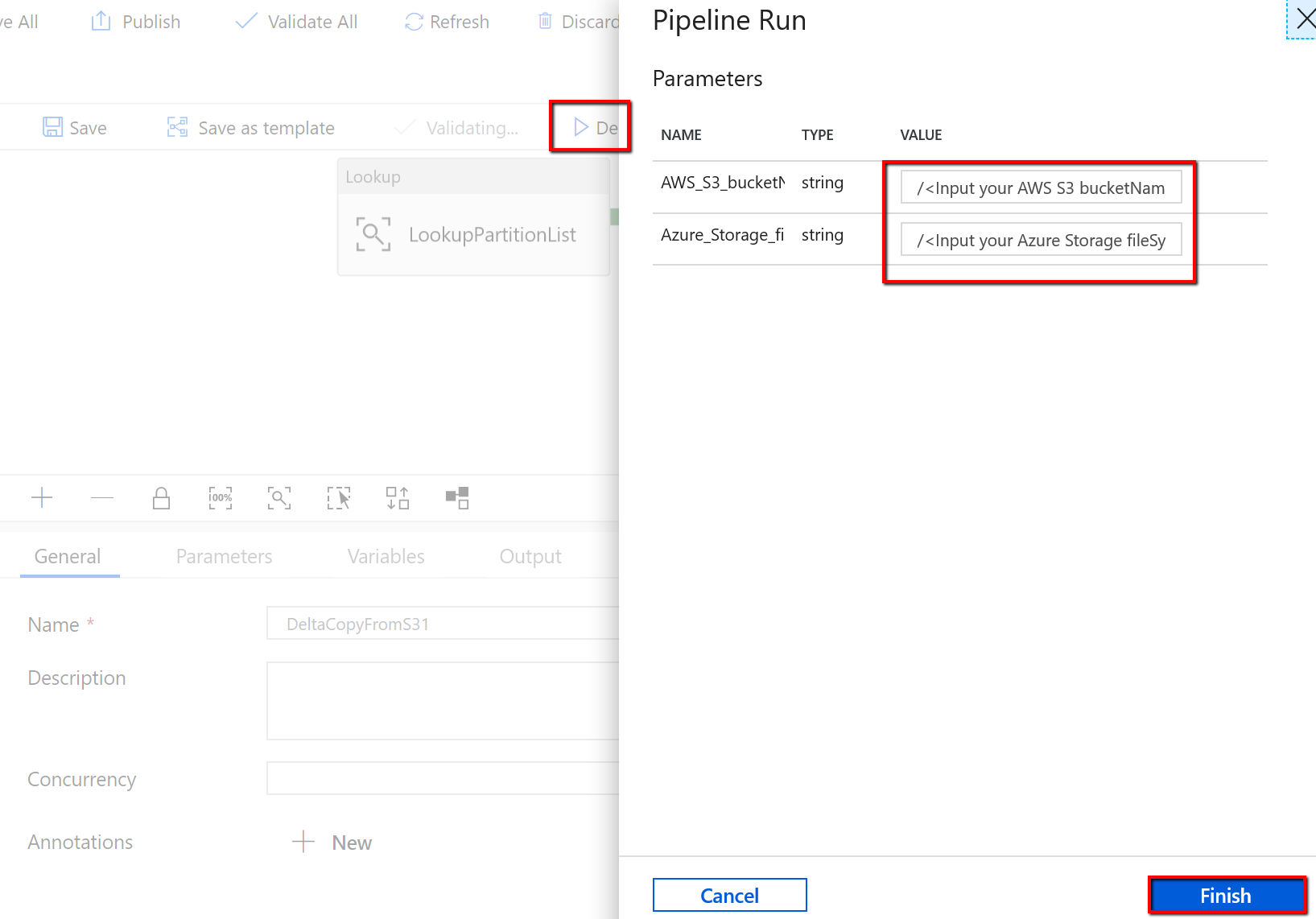
Você vê resultados semelhantes ao exemplo a seguir:
Você também pode verificar os resultados da tabela de controle por uma consulta "selecionar * de s3_partition_delta_control_table", você verá a saída semelhante ao exemplo a seguir:
evento
31/03, 23 - 2/04, 23
O maior evento de aprendizagem de Malha, Power BI e SQL. 31 de março a 2 de abril. Use o código FABINSIDER para economizar $400.
Registe-se hoje mesmoFormação
Percurso de aprendizagem
Integração de dados em escala do Azure Data Factory - Training
Integração de dados em escala com o Azure Data Factory ou o Pipeline do Azure Synapse
Certificação
Microsoft Certified: Azure Data Engineer Associate - Certifications
Demonstre a compreensão das tarefas comuns de engenharia de dados para implementar e gerenciar cargas de trabalho de engenharia de dados no Microsoft Azure, usando vários serviços do Azure.
Documentação
Migrar dados do Amazon S3 para o Armazenamento do Azure - Azure Data Factory
Use o Azure Data Factory para migrar dados do Amazon S3 para o Armazenamento do Azure.
Saiba como copiar dados do Amazon Simple Storage Service (S3) e transformar dados no Amazon Simple Storage Service (S3) usando o Azure Data Factory ou os pipelines do Azure Synapse Analytics.
Migrar dados do data lake e do data warehouse para o Azure - Azure Data Factory
Use o Azure Data Factory para migrar dados do seu data lake e data warehouse para o Azure.