Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Data Factory em Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA incorporada e novas funcionalidades. Se és novo na integração de dados, começa pelo Fabric Data Factory. As cargas de trabalho existentes do ADF podem atualizar para o Fabric para aceder a novas capacidades em ciência de dados, análise em tempo real e relatórios.
Neste tutorial, usa o Azure PowerShell para criar um pipeline de Data Factory que copia dados de uma base de dados do SQL Server para o armazenamento Azure Blob. Cria e utiliza um runtime de integração autogerido, que move dados entre repositórios de dados locais e na cloud.
Nota
Este artigo não disponibiliza uma introdução detalhada do serviço Data Factory. Para mais informações, veja Introdução à Azure Data Factory.
Neste tutorial, vai executar os seguintes passos:
- Criar uma fábrica de dados.
- Criar um runtime de integração auto-hospedado.
- Criar serviços ligados ao SQL Server e ao Azure Storage.
- Criar conjuntos de dados SQL Server e Azure Blob.
- Criar um pipeline com uma atividade de cópia para transferir os dados.
- Iniciar uma execução de pipeline.
- Monitorizar a execução do pipeline.
Pré-requisitos
subscrição do Azure
Antes de começar, se ainda não tiver uma subscrição Azure, crie uma conta gratuita.
Funções do Azure
Para criar instâncias de fábrica de dados, a conta de utilizador que usa para iniciar sessão no Azure deve ser atribuída a um papel Contribuidor ou Proprietário ou deve ser um administrador da subscrição Azure.
Para ver as permissões que tem na subscrição, vá ao portal Azure, selecione o seu nome de utilizador no canto superior direito e depois selecione Permissões. Se tiver acesso a várias subscrições, selecione a subscrição apropriada. Para instruções de exemplo sobre como adicionar um utilizador a uma função, consulte o artigo Atribuir Azure papéis usando o portal Azure.
SQL Server 2014, 2016 e 2017
Neste tutorial, utilizas uma base de dados SQL Server como repositório de dados fonte. O pipeline na fábrica de dados que crias neste tutorial copia dados desta base de dados SQL Server (fonte) para o armazenamento Azure Blob (sink). Depois crias uma tabela chamada emp na tua base de dados de SQL Server e inseres algumas entradas de exemplo na tabela.
Inicie o SQL Server Management Studio. Se ainda não estiver instalado na sua máquina, vá a Download SQL Server Management Studio.
Ligue-se à sua instância do SQL Server usando as suas credenciais.
Crie uma base de dados de exemplo. Na vista de árvore, clique com o botão direito do rato em Bases de Dados e selecione Nova Base de Dados.
Na janela Nova Base de Dados, introduza um nome para a base de dados e selecione OK.
Para criar a tabela emp e inserir alguns dados de exemplo na mesma, execute o script de consulta seguinte na base de dados. Na vista de árvore, clique com o botão direito do rato na base de dados que criou e selecione Nova Consulta.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe') INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe') GO
conta de armazenamento do Azure
Neste tutorial, utilizas uma conta de armazenamento de uso geral do Azure (especificamente, armazenamento Azure Blob) como um repositório de dados de destino/sumidouro. Se não tiver uma conta de armazenamento de Azure de uso geral, veja Criar uma conta de armazenamento. O pipeline na fábrica de dados que crias neste tutorial copia dados da base de dados do SQL Server (fonte) para este armazenamento Azure Blob (sink).
Obter o nome e a chave da conta de armazenamento
Neste tutorial, utiliza o nome e a chave da sua conta de armazenamento Azure. Obtenha o nome e a chave da sua conta de armazenamento da seguinte forma:
Inicie sessão no portal Azure com o seu nome de utilizador Azure e palavra-passe.
No painel do lado esquerdo, selecione Mais Serviços, utilize a palavra-chave Armazenamento para filtrar e selecione Contas de Armazenamento.
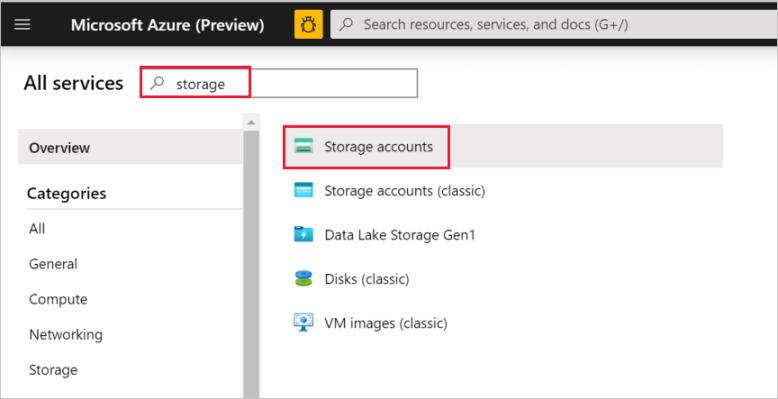
Na lista das contas de armazenamento, filtre para encontrar a sua conta de armazenamento (se necessário) e selecione-a.
Na janela Conta de armazenamento, selecione Chaves de acesso.
Nas caixas Nome da conta de armazenamento e key1, copie os valores e cole-os no Bloco de notas ou noutro editor, para utilizar mais adiante no tutorial.
Criar um container adftutorial
Nesta secção, crias um contentor de blob chamado adftutorial no teu armazenamento de Azure Blob.
Na janela Conta de armazenamento, mude para a Descrição Geral e selecione Blobs.
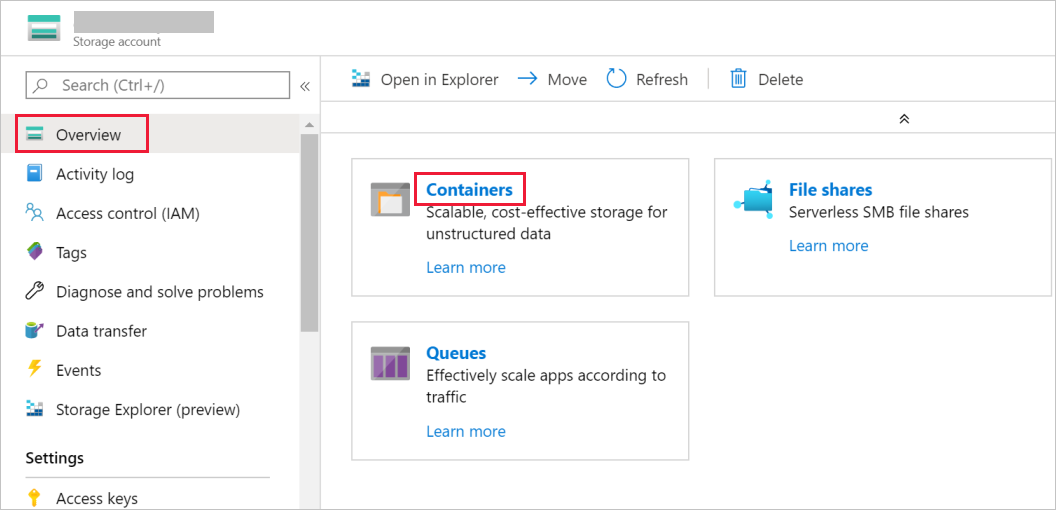
Na janela Serviço de Blob, selecione Contentor.
Na janela Novo Contentor, na caixa Nome, introduza adftutorial e selecione OK.
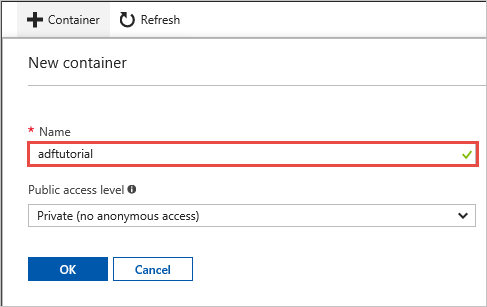
Na lista de contentores, clique em adftutorial.
Mantenha a janela do contentor de adftutorial aberta. Vai utilizá-la para verificar o resultado no final deste tutorial. O Data Factory cria automaticamente a pasta de saída neste contentor, pelo que não precisa de a criar.
PowerShell do Windows
Instalar o Azure PowerShell
Nota
Recomendamos que utilize o módulo PowerShell do Azure Az para interagir com o Azure. Para começar, consulte Install Azure PowerShell. Para saber como migrar para o módulo Az PowerShell, veja Migrar Azure PowerShell do AzureRM para o Az.
Instala a versão mais recente do Azure PowerShell se ainda não a tiveres na tua máquina. Para instruções detalhadas, veja Como instalar e configurar Azure PowerShell.
Iniciar sessão no PowerShell
Inicie o PowerShell no seu computador e mantenha-o aberto até concluir este tutorial de início rápido. Se fechar e reabrir, terá de executar esses comandos novamente.
Execute o seguinte comando e depois introduza o nome de utilizador e a palavra-passe do Azure que usa para iniciar sessão no portal Azure:
Connect-AzAccountSe tiver várias subscrições do Azure, execute o seguinte comando para selecionar a subscrição com que pretende trabalhar. Substitua SubscriptionId pelo ID da sua subscrição Azure:
Select-AzSubscription -SubscriptionId "<SubscriptionId>"
Criar uma fábrica de dados
Defina uma variável para o nome do grupo de recursos que vai utilizar mais tarde nos comandos do PowerShell. Copie o comando seguinte para o PowerShell, especifique um nome para o grupo de recursos Azure (incluído entre aspas duplas; por exemplo,
"adfrg"), e depois execute o comando.$resourceGroupName = "ADFTutorialResourceGroup"Para criar o grupo de recursos do Azure, execute o seguinte comando:
New-AzResourceGroup $resourceGroupName -location 'East US'Se o grupo de recursos já existir, talvez não queira sobrescrevê-lo. Atribua outro valor à variável
$resourceGroupNamee execute novamente o comando.Defina uma variável para o nome da fábrica de dados que possa utilizar em comandos do PowerShell mais tarde. O nome tem de começar com uma letra ou um número e só pode conter letras, números e o traço (-).
Importante
Atualize o nome da fábrica de dados com um que seja globalmente exclusivo. Por exemplo, ADFTutorialFactorySP1127.
$dataFactoryName = "ADFTutorialFactory"Defina uma variável para a localização da fábrica de dados:
$location = "East US"Para criar a fábrica de dados, execute o cmdlet
Set-AzDataFactoryV2:Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Nota
- O nome da fábrica de dados tem de ser globalmente exclusivo. Se receber o erro seguinte, altere o nome e tente novamente.
The specified data factory name 'ADFv2TutorialDataFactory' is already in use. Data factory names must be globally unique. - Para criar instâncias do Data Factory, a conta de utilizador que usa para iniciar sessão no Azure deve ter o papel de contribuidor ou proprietário ou deve ser um administrador da subscrição do Azure.
- Para uma lista das regiões do Azure em que o Data Factory está disponível atualmente, selecione as regiões que lhe interessam na página seguinte e depois expanda Analytics para localizar Data Factory: Produtos disponíveis por região. Os repositórios de dados (Azure Storage, Azure SQL Database, e assim por diante) e os computadores (Azure HDInsight, entre outros) usados pela data factory podem estar noutras regiões.
Criar um runtime de integração autogerido
Nesta secção, cria um runtime de integração auto-hospedado e associa-o a uma máquina local com a base de dados do SQL Server. O runtime de integração auto-hospedado é o componente que copia dados da base de dados do SQL Server na sua máquina para o armazenamento Azure Blob.
Crie uma variável para o nome do integration runtime. Utilize um nome exclusivo e anote o nome. Vai utilizá-lo mais tarde no tutorial.
$integrationRuntimeName = "ADFTutorialIR"Criar um runtime de integração auto-hospedado.
Set-AzDataFactoryV2IntegrationRuntime -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $integrationRuntimeName -Type SelfHosted -Description "selfhosted IR description"Segue-se o resultado do exemplo:
Name : ADFTutorialIR Type : SelfHosted ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Description : selfhosted IR description Id : /subscriptions/<subscription ID>/resourceGroups/<resourceGroupName>/providers/Microsoft.DataFactory/factories/<dataFactoryName>/integrationruntimes/<integrationRuntimeName>Para obter o estado do integration runtime criado, execute o comando seguinte:
Get-AzDataFactoryV2IntegrationRuntime -name $integrationRuntimeName -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -StatusSegue-se o resultado do exemplo:
State : NeedRegistration Version : CreateTime : 9/10/2019 3:24:09 AM AutoUpdate : On ScheduledUpdateDate : UpdateDelayOffset : LocalTimeZoneOffset : InternalChannelEncryption : Capabilities : {} ServiceUrls : {eu.frontend.clouddatahub.net} Nodes : {} Links : {} Name : <Integration Runtime name> Type : SelfHosted ResourceGroupName : <resourceGroup name> DataFactoryName : <dataFactory name> Description : selfhosted IR description Id : /subscriptions/<subscription ID>/resourceGroups/<resourceGroupName>/providers/Microsoft.DataFactory/factories/<dataFactoryName>/integrationruntimes/<integrationRuntimeName>Para obter as chaves de autenticação para registar o integration runtime autoalojado no serviço Data Factory na cloud, execute o comando seguinte. Copie uma das chaves (excluindo as aspas) para registar o runtime de integração auto-hospedado que instalará no computador no passo seguinte.
Get-AzDataFactoryV2IntegrationRuntimeKey -Name $integrationRuntimeName -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName | ConvertTo-JsonSegue-se o resultado do exemplo:
{ "AuthKey1": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx=", "AuthKey2": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy=" }
Instalar o runtime de integração
Descarrega Azure Data Factory Integration Runtime numa máquina Windows local e depois executa a instalação.
No assistente Bem-vindo ao Microsoft Integration Runtime Setup, selecione Next.
Na janea Contrato de Licença do Utilizador Final, aceite os termos e o contrato de licença e selecione Seguinte.
Na janela Pasta de Destino, selecione Seguinte.
Na janela Pronto para instalar Microsoft Integration Runtime, selecione Instalar.
No assistente Concluir a configuração do Microsoft Integration Runtime, selecione Concluir.
Na janela Register Integration Runtime (Auto-hospedado), cole a chave que tinha guardado na secção anterior e, em seguida, selecione Registar.
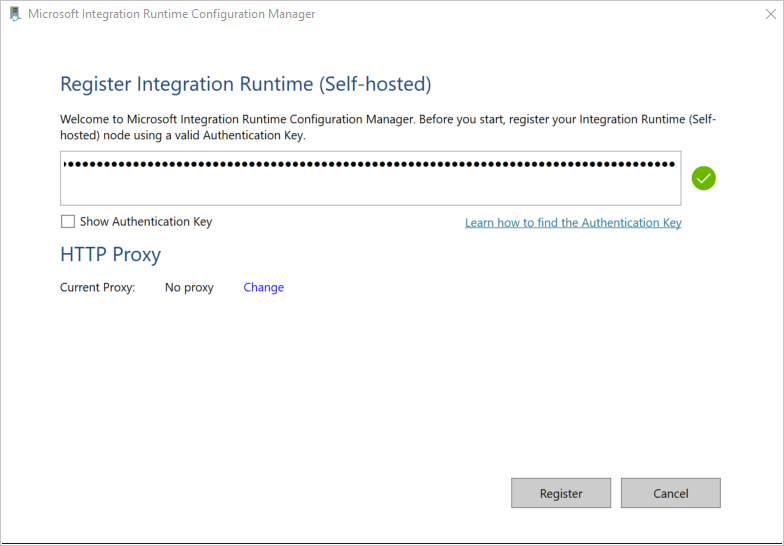
Na janela New Integration Runtime (Auto-hospedado), selecione Terminar.
Quando o runtime de integração alojado localmente for registado com êxito, a mensagem seguinte é apresentada:
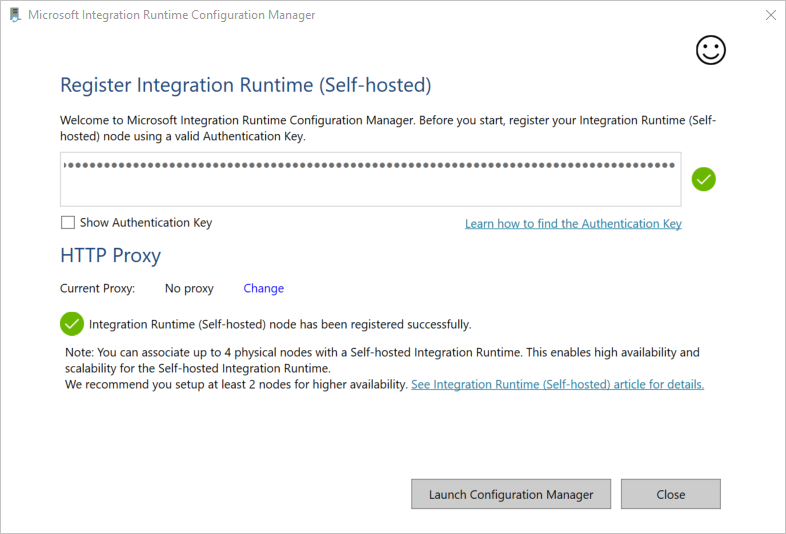
Na janela Register Integration Runtime (Auto-hospedado), selecione Launch Configuration Manager.
Quando o nó estiver conectado ao serviço de cloud, é apresentada a mensagem seguinte:
Teste a conectividade à sua base de dados SQL Server fazendo o seguinte:
a. Na janela Configuration Manager, mude para o separador Diagnostics.
b. Na caixa Tipo de origem de dados, selecione SqlServer.
c. Introduza o nome do servidor.
d. Introduza o nome da base de dados.
e. Selecione o modo de autenticação.
f. Introduza o nome de utilizador.
g. Introduza a palavra-passe que está associado ao nome de utilizador.
h. Para confirmar que o runtime de integração pode ligar-se ao SQL Server, selecione Test.
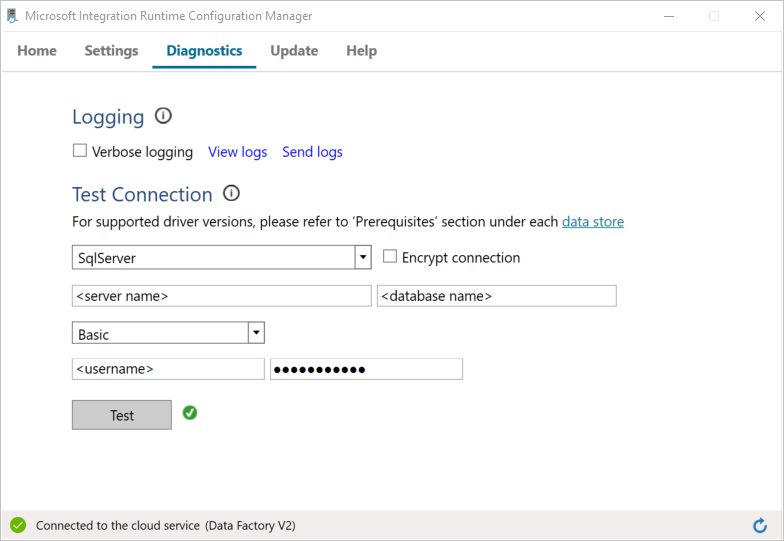
Se a ligação for bem-sucedida, é apresentada uma marca de verificação verde. Caso contrário, receberá uma mensagem de erro associada à falha. Corrige quaisquer problemas e assegure que o runtime de integração pode ligar-se à sua instância do SQL Server.
Registe todos os valores anteriores para utilizar mais adiante neste tutorial.
Criar serviços ligados
Para ligar os seus arquivos de dados e serviços de computação à fábrica de dados, crie serviços ligados na mesma. Neste tutorial, liga a sua conta de armazenamento Azure e a instância do SQL Server ao armazenamento de dados. Os serviços conectados têm as informações de ligação que o serviço do Data Factory utiliza em tempo de execução para estabelecer ligação com eles.
Criar um serviço ligado ao Azure Storage (destino/sink)
Neste passo, liga a sua conta de armazenamento Azure à fábrica de dados.
Crie um ficheiro JSON com o nome AzureStorageLinkedService.json na pasta C:\ADFv2Tutorial com o código seguinte. Se a pasta ADFv2Tutorial ainda não existir, crie-a.
Importante
Antes de guardar o ficheiro, substitua <NomeConta> e <ChaveConta> pelo nome e chave da sua conta de armazenamento Azure. Estas informações foram apontadas na secção Pré-requisitos.
{ "name": "AzureStorageLinkedService", "properties": { "annotations": [], "type": "AzureBlobStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>;EndpointSuffix=core.windows.net" } } }No PowerShell, navegue até à pasta C:\ADFv2Tutorial.
Set-Location 'C:\ADFv2Tutorial'Para criar o serviço ligado AzureStorageLinkedService, execute o cmdlet
Set-AzDataFactoryV2LinkedService:Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -Name "AzureStorageLinkedService" -File ".\AzureStorageLinkedService.json"Eis um resultado de exemplo:
LinkedServiceName : AzureStorageLinkedService ResourceGroupName : <resourceGroup name> DataFactoryName : <dataFactory name> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobStorageLinkedServiceSe receber o erro "Ficheiro não encontrado", execute o comando
dirpara confirmar que existe. Se o nome de ficheiro tiver a extensão .txt (por exemplo, AzureStorageLinkedService.json.txt), remove-a e execute novamente o comando do PowerShell.
Criar e encriptar um serviço ligado ao SQL Server (fonte)
Neste passo, liga a sua instância do SQL Server à fábrica de dados.
Crie um ficheiro JSON com o nom SqlServerLinkedService.json na pasta C:\ADFv2Tutorial, mediante o código seguinte:
Importante
Selecione a secção baseada na autenticação que usa para se ligar ao SQL Server.
Usando a autenticação SQL (sa):
{ "name":"SqlServerLinkedService", "type":"Microsoft.DataFactory/factories/linkedservices", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=False;data source=<serverName>;initial catalog=<databaseName>;user id=<userName>;password=<password>" }, "connectVia":{ "referenceName":"<integration runtime name> ", "type":"IntegrationRuntimeReference" } } }Usando autenticação do Windows:
{ "name":"SqlServerLinkedService", "type":"Microsoft.DataFactory/factories/linkedservices", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=True;data source=<serverName>;initial catalog=<databaseName>", "userName":"<username> or <domain>\\<username>", "password":{ "type":"SecureString", "value":"<password>" } }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Importante
- Selecione a secção baseada na autenticação que usa para se ligar à sua instância do SQL Server.
- Substitua <nome do tempo de execução de integração> pelo nome do seu tempo de execução de integração.
- Antes de guardar o ficheiro, substitua <nomedo do servidor>, <nome da base de dados>, <nome de utilizador> e <password> pelos valores da sua instância SQL Server.
- Se precisar usar uma barra invertida (\) na sua conta de utilizador ou nome de servidor, preceda-a com o caractere de escape (\). Por exemplo, use mydomain\\myuser.
Para encriptar os dados confidenciais (nome de utilizador, palavra-passe, etc.), execute o cmdlet
New-AzDataFactoryV2LinkedServiceEncryptedCredential.
Esta encriptação garante que as credenciais são encriptadas com a interface DPAPI (Data Protection Application Programming Interface). As credenciais encriptadas são armazenadas localmente no nó do runtime de integração auto-hospedado (computador local). O payload de saída pode ser redirecionado para outro ficheiro JSON (neste caso, encryptedLinkedService.json) que contém credenciais encriptadas.New-AzDataFactoryV2LinkedServiceEncryptedCredential -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -IntegrationRuntimeName $integrationRuntimeName -File ".\SQLServerLinkedService.json" > encryptedSQLServerLinkedService.jsonExecute o comando seguinte, que cria EncryptedSqlServerLinkedService:
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -Name "EncryptedSqlServerLinkedService" -File ".\encryptedSqlServerLinkedService.json"
Criar conjuntos de dados
Neste passo, vai criar conjuntos de dados de entrada e saída. Representam dados de entrada e saída para a operação de cópia, que copia dados da base de dados do SQL Server para o armazenamento Azure Blob.
Crie um conjunto de dados para a base de dados do SQL Server de origem
Neste passo, defines um conjunto de dados que representa dados na instância da base de dados do SQL Server. O conjunto de dados é do tipo SqlServerTable. Refere-se ao serviço ligado ao SQL Server que criou na etapa anterior. O serviço ligado tem a informação de ligação que o serviço Data Factory usa para se ligar à sua instância do SQL Server em tempo de execução. Este conjunto de dados especifica a tabela SQL na base de dados que contém os dados. Neste tutorial, a tabela emp contém a origem de dados.
Crie um ficheiro JSON com o nome SqlServerDataset.json na pasta C:\ADFv2Tutorial, com o código seguinte:
{ "name":"SqlServerDataset", "properties":{ "linkedServiceName":{ "referenceName":"EncryptedSqlServerLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"SqlServerTable", "schema":[ ], "typeProperties":{ "schema":"dbo", "table":"emp" } } }Para criar o conjunto de dados SqlServerDataset, execute o cmdlet
Set-AzDataFactoryV2Dataset.Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SqlServerDataset" -File ".\SqlServerDataset.json"Segue-se o resultado do exemplo:
DatasetName : SqlServerDataset ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerTableDataset
Criar um conjunto de dados para Azure Blob storage (sink)
Neste passo, defines um conjunto de dados que representa dados que serão copiados para o armazenamento Azure Blob. O conjunto de dados é do tipo AzureBlob. Refere-se ao serviço ligado ao Azure Storage que criaste anteriormente neste tutorial.
O serviço vinculado tem as informações de conexão que o Data Factory usa durante a execução para se ligar à conta de armazenamento do Azure. Este conjunto de dados especifica a pasta no armazenamento do Azure para onde os dados são copiados da base de dados do SQL Server. Neste tutorial, a pasta é adftutorial/fromonprem, em que adftutorial é o contentor de blobs e fromonprem é a pasta.
Crie um ficheiro JSON com o nome AzureBlobDataset.json na pasta C:\ADFv2Tutorial, com o código seguinte:
{ "name":"AzureBlobDataset", "properties":{ "linkedServiceName":{ "referenceName":"AzureStorageLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"DelimitedText", "typeProperties":{ "location":{ "type":"AzureBlobStorageLocation", "folderPath":"fromonprem", "container":"adftutorial" }, "columnDelimiter":",", "escapeChar":"\\", "quoteChar":"\"" }, "schema":[ ] }, "type":"Microsoft.DataFactory/factories/datasets" }Para criar o conjunto de dados AzureBlobDataset, execute o cmdlet
Set-AzDataFactoryV2Dataset.Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureBlobDataset" -File ".\AzureBlobDataset.json"Segue-se o resultado do exemplo:
DatasetName : AzureBlobDataset ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.DelimitedTextDataset
Criar um pipeline
Neste tutorial, vai criar um pipeline com uma atividade de cópia. A atividade de cópia utiliza SqlServerDataset como o conjunto de dados de entrada e AzureBlobDataset como o conjunto de dados de saída. O tipo de origem está definido como SqlSource e o tipo de sink como BlobSink.
Crie um ficheiro JSON com o nome SqlServerToBlobPipeline.json na pasta C:\ADFv2Tutorial, com o código seguinte:
{ "name":"SqlServerToBlobPipeline", "properties":{ "activities":[ { "name":"CopySqlServerToAzureBlobActivity", "type":"Copy", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource" }, "sink":{ "type":"DelimitedTextSink", "storeSettings":{ "type":"AzureBlobStorageWriteSettings" }, "formatSettings":{ "type":"DelimitedTextWriteSettings", "quoteAllText":true, "fileExtension":".txt" } }, "enableStaging":false }, "inputs":[ { "referenceName":"SqlServerDataset", "type":"DatasetReference" } ], "outputs":[ { "referenceName":"AzureBlobDataset", "type":"DatasetReference" } ] } ], "annotations":[ ] } }Para criar o pipeline SQLServerToBlobPipeline, execute o cmdlet
Set-AzDataFactoryV2Pipeline.Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SQLServerToBlobPipeline" -File ".\SQLServerToBlobPipeline.json"Segue-se o resultado do exemplo:
PipelineName : SQLServerToBlobPipeline ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Activities : {CopySqlServerToAzureBlobActivity} Parameters :
Criar uma execução do pipeline
Inicie uma execução do SQLServerToBlobPipeline e capture o ID dessa execução para monitoramento futuro.
$runId = Invoke-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineName 'SQLServerToBlobPipeline'
Monitorizar a execução do pipeline.
Para verificar continuamente o estado de execução do pipeline SQLServerToBlobPipeline, execute o script seguinte no PowerShell e imprima o resultado final:
while ($True) { $result = Get-AzDataFactoryV2ActivityRun -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineRunId $runId -RunStartedAfter (Get-Date).AddMinutes(-30) -RunStartedBefore (Get-Date).AddMinutes(30) if (($result | Where-Object { $_.Status -eq "InProgress" } | Measure-Object).count -ne 0) { Write-Host "Pipeline run status: In Progress" -foregroundcolor "Yellow" Start-Sleep -Seconds 30 } else { Write-Host "Pipeline 'SQLServerToBlobPipeline' run finished. Result:" -foregroundcolor "Yellow" $result break } }Eis o resultado da execução de exemplo:
ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> ActivityRunId : 24af7cf6-efca-4a95-931d-067c5c921c25 ActivityName : CopySqlServerToAzureBlobActivity ActivityType : Copy PipelineRunId : 7b538846-fd4e-409c-99ef-2475329f5729 PipelineName : SQLServerToBlobPipeline Input : {source, sink, enableStaging} Output : {dataRead, dataWritten, filesWritten, sourcePeakConnections...} LinkedServiceName : ActivityRunStart : 9/11/2019 7:10:37 AM ActivityRunEnd : 9/11/2019 7:10:58 AM DurationInMs : 21094 Status : Succeeded Error : {errorCode, message, failureType, target} AdditionalProperties : {[retryAttempt, ], [iterationHash, ], [userProperties, {}], [recoveryStatus, None]...}Pode obter o ID de execução do pipeline SQLServerToBlobPipeline e verificar o resultado detalhado da execução da atividade, executando o comando seguinte:
Write-Host "Pipeline 'SQLServerToBlobPipeline' run result:" -foregroundcolor "Yellow" ($result | Where-Object {$_.ActivityName -eq "CopySqlServerToAzureBlobActivity"}).Output.ToString()Eis o resultado da execução de exemplo:
{ "dataRead":36, "dataWritten":32, "filesWritten":1, "sourcePeakConnections":1, "sinkPeakConnections":1, "rowsRead":2, "rowsCopied":2, "copyDuration":18, "throughput":0.01, "errors":[ ], "effectiveIntegrationRuntime":"ADFTutorialIR", "usedParallelCopies":1, "executionDetails":[ { "source":{ "type":"SqlServer" }, "sink":{ "type":"AzureBlobStorage", "region":"CentralUS" }, "status":"Succeeded", "start":"2019-09-11T07:10:38.2342905Z", "duration":18, "usedParallelCopies":1, "detailedDurations":{ "queuingDuration":6, "timeToFirstByte":0, "transferDuration":5 } } ] }
Verificar a saída
O pipeline cria automaticamente a pasta de saída nomeada como fromonprem no contentor de blobs adftutorial. Confirme que consegue ver o ficheiro dbo.emp.txt na pasta de saída.
No portal Azure, na janela do contentor adftutorial, selecione Refresh para ver a pasta de saída.
Selecione
fromonpremna lista de pastas.Confirme que vê um ficheiro com o nome
dbo.emp.txt.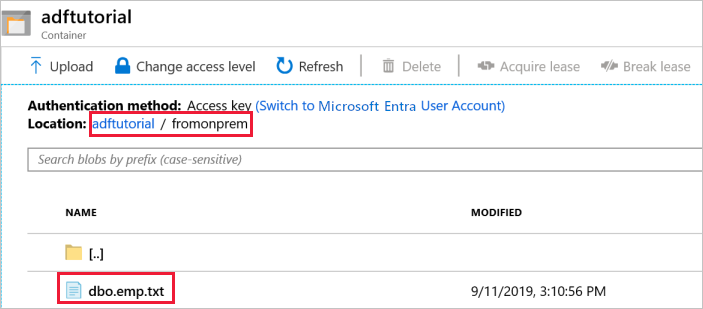
Conteúdos relacionados
O pipeline neste exemplo copia dados de um local para outro no armazenamento Azure Blob. Aprendeu a:
- Criar uma fábrica de dados.
- Criar um runtime de integração auto-hospedado.
- Criar serviços ligados ao SQL Server e ao Azure Storage.
- Criar conjuntos de dados SQL Server e Azure Blob.
- Criar um pipeline com uma atividade de cópia para transferir os dados.
- Iniciar uma execução de pipeline.
- Monitorizar a execução do pipeline.
Para obter uma lista dos arquivos de dados que o Data Factory suporta, veja Supported data stores (Arquivos de Dados suportados).
Para aprender a copiar dados em massa de uma origem para um destino, avance para o tutorial seguinte: