Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Importante
A Lakebase Autoscaling está em Beta nas seguintes regiões: eastus2, westeurope, westus.
O Autoscaling do Lakebase é a versão mais recente do Lakebase com computação automática, escala até zero, ramificação e restauração instantânea. Para comparação de funcionalidades com o Lakebase Provisioned, veja a escolha entre versões.
Comece a funcionar com o Lakebase Postgres em minutos. Crie o seu primeiro projeto, ligue-se à sua base de dados e explore funcionalidades chave, incluindo a integração com o Unity Catalog.
Crie o seu primeiro projeto
Abre a aplicação Lakebase a partir do comutador de apps.
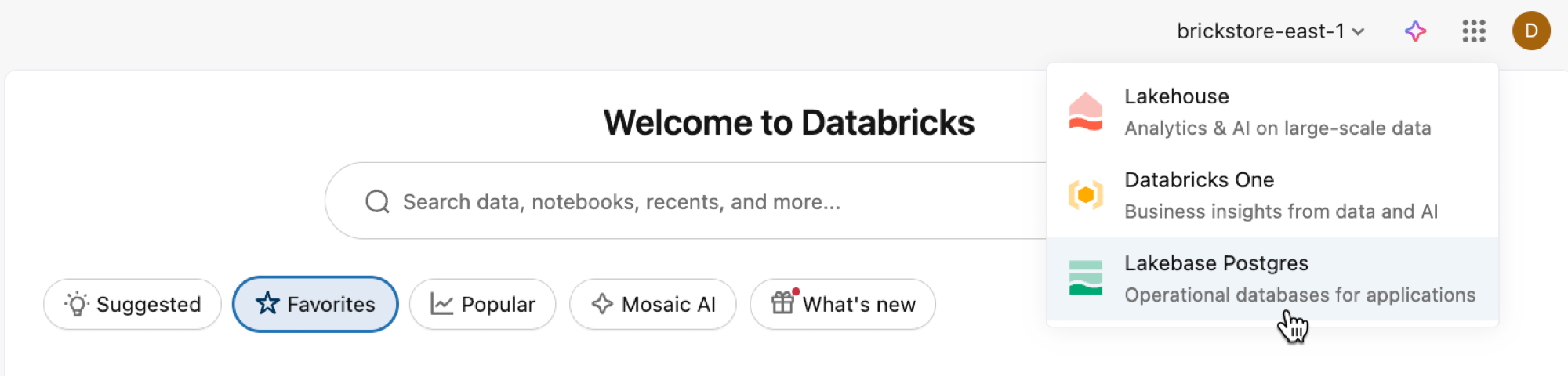
Selecione Autoscaling para aceder à interface de Autoscaling do Lakebase.
Clique em Novo projeto. Dá um nome ao teu projeto e seleciona a versão do Postgres. O seu projeto é criado com um único production branch, uma base de dados padrão databricks_postgres e recursos de computação configurados para o branch.
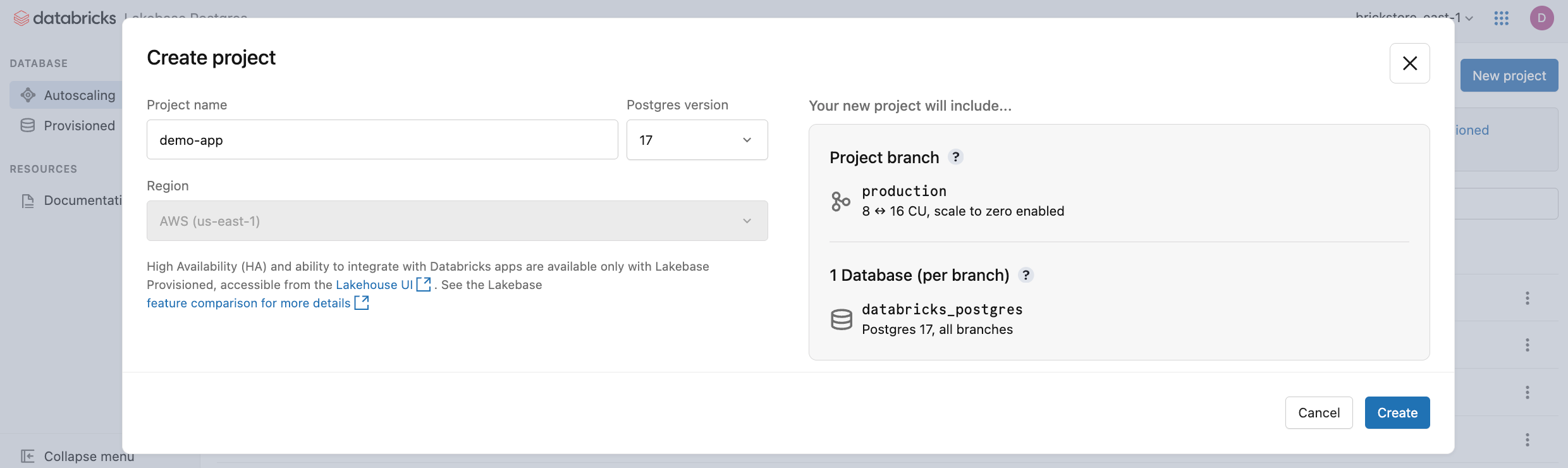
Pode demorar alguns momentos para o teu computador iniciar. O cálculo para o production ramo está sempre ativado por padrão (o "scale-to-zero" está desativado), mas poderá configurar esta definição se necessário.
A região do seu projeto é automaticamente definida para a região do seu espaço de trabalho. Para opções de configuração detalhadas, veja Criar um projeto.
Ligar à sua base de dados
A partir do seu projeto, selecione o ramo de produção e clique em Conectar. Pode ligar-se usando a sua identidade Databricks com autenticação OAuth, ou criar uma função de palavra-passe nativa do Postgres. As strings de ligação funcionam com clientes Postgres padrão como psql, pgAdmin ou qualquer ferramenta compatível com Postgres.
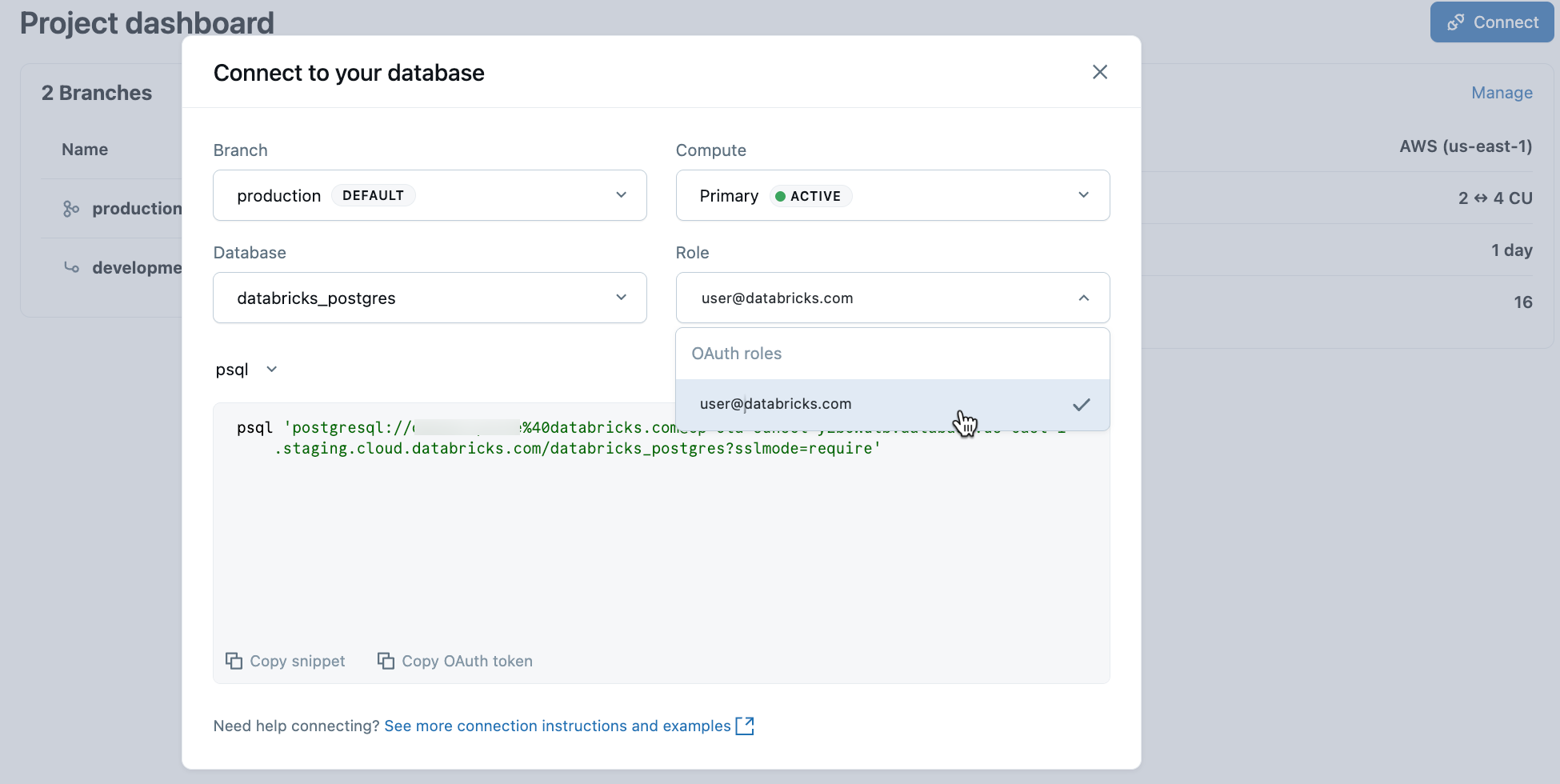
Quando cria um projeto, um papel Postgres para a sua identidade Databricks (por exemplo, user@databricks.com) é criado automaticamente. Este papel detém a base de dados padrão databricks_postgres e é membro de databricks_superuser, conferindo-lhe amplos privilégios para gerir objetos da base de dados.
Para se ligar usando a identidade do Databricks com o OAuth, copie o psql excerto de ligação do diálogo de ligação.
psql 'postgresql://your-email@databricks.com@ep-abc-123.databricks.com/databricks_postgres?sslmode=require'
Depois de introduzir o psql comando de ligação no seu terminal, será solicitado a fornecer um token OAuth. Obtenha o seu token clicando na opção Copiar token OAuth no diálogo de ligação.
Para detalhes de ligação e opções de autenticação, consulte Quickstart.
Crie a sua primeira tabela
O Lakebase SQL Editor vem pré-carregado com SQL de exemplo para te ajudar a começar. A partir do seu projeto, selecione o ramo de produção , abra o SQL Editor e execute as instruções fornecidas para criar uma playing_with_lakebase tabela e inserir dados de exemplo. Também pode usar o Editor de Tabelas para gestão visual de dados ou ligar-se a clientes Postgres externos.
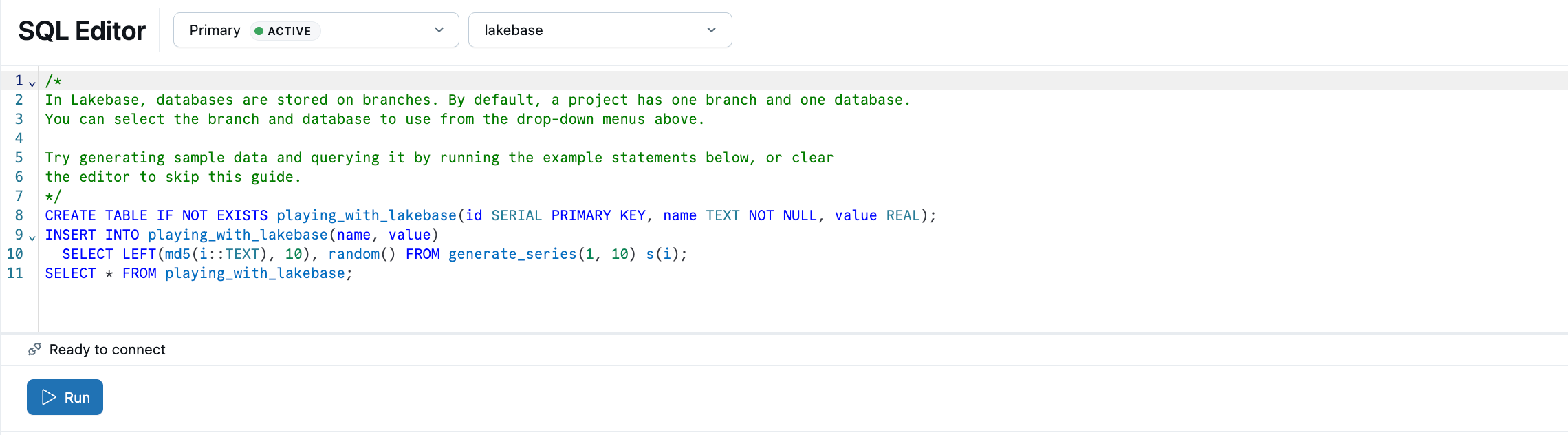
Saiba mais sobre opções de consulta: Editor SQL | Editor de Tabelas | Clientes Postgres
Registar-se no Catálogo Unity
Agora que criaste uma tabela no teu ramo de produção, vamos registar a base de dados no Unity Catalog para que possas consultar esses dados no Editor SQL do Databricks.
- Usa o seletor de aplicações para navegar até Lakehouse.
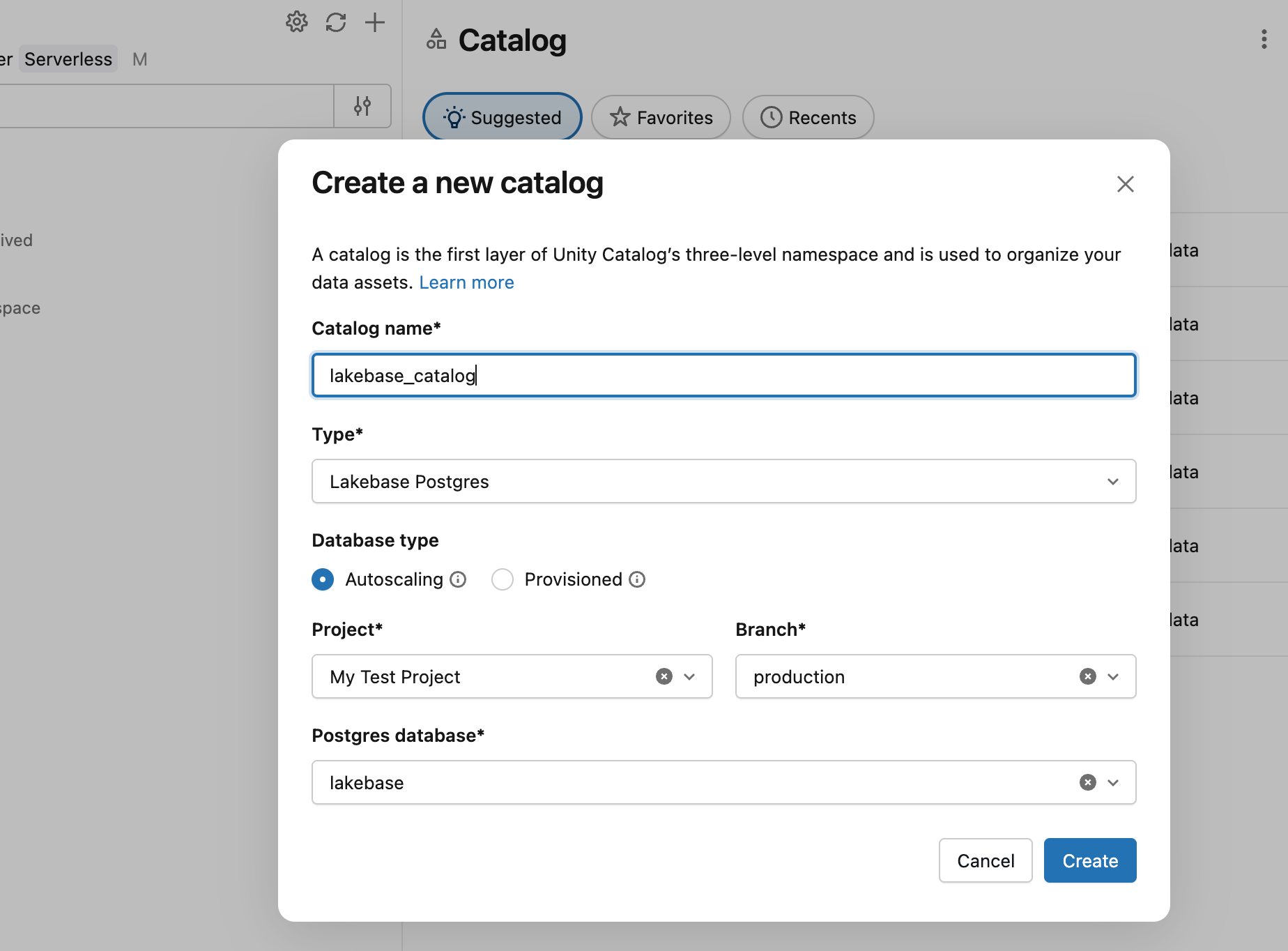
- No Explorador de Catálogos, clique no ícone mais e crie um catálogo.
- Insira um nome de catálogo (por exemplo,
lakebase_catalog). - Selecione Lakebase Postgres como tipo de catálogo e ative a opção de Autoscaling .
- Selecione o seu projeto, o
productionramo, e a base de dadosdatabricks_postgres. - Clique em Criar.
Agora pode consultar a playing_with_lakebase tabela que acabou de criar a partir do Databricks SQL Editor usando um SQL warehouse:
SELECT * FROM lakebase_catalog.public.playing_with_lakebase;
Isto permite consultas federadas que unem os seus dados transacionais Lakebase com a análise de Lakehouse. Para mais detalhes, consulte Registar-se no Catálogo Unity.
Sincronizar dados com Reverse ETL
Acabaste de ver como tornar os dados do Lakebase consultáveis no Unity Catalog. O Lakebase também funciona no sentido inverso: trazendo dados analíticos curados DO Unity Catalog PARA a tua base de dados Lakebase. Isto é útil quando tem dados enriquecidos, funcionalidades de ML ou métricas agregadas calculadas no seu lakehouse que precisam de ser servidas por aplicações com consultas transacionais de baixa latência.
Primeiro, crie uma tabela no Unity Catalog que represente dados analíticos. Abra um armazém SQL ou caderno e execute:
CREATE TABLE main.default.user_segments AS
SELECT * FROM VALUES
(1001, 'premium', 2500.00, 'high'),
(1002, 'standard', 450.00, 'medium'),
(1003, 'premium', 3200.00, 'high'),
(1004, 'basic', 120.00, 'low')
AS segments(user_id, tier, lifetime_value, engagement);
Agora sincronize esta tabela com a sua base de dados Lakebase:
- No Explorador de Catálogos Lakehouse, navegue até principal>padrão>user_segments.
- Clique em Criar>tabela sincronizada.
- Configure a sincronização:
-
Nome da tabela: Introduza
user_segments_synced. - Tipo de base de dados: Selecione Lakebase Serverless (Autoscaling).
- Modo de sincronização: Escolha Snapshot para uma sincronização de dados de uma única vez.
- Seleciona o teu projeto, o ramo de produção e a base de
databricks_postgresdados.
-
Nome da tabela: Introduza
- Clique em Criar.
Depois de a sincronização terminar, a tabela aparece na tua base de dados Lakebase. O processo de sincronização cria um default esquema em Postgres para igualar o esquema do Unity Catalog, de modo que main.default.user_segments_synced se torna default.user_segments_synced. Navegue de volta ao Lakebase usando o comutador de aplicações e consulte-o no Editor SQL do Lakebase:
SELECT * FROM "default"."user_segments_synced" WHERE "engagement" = 'high';
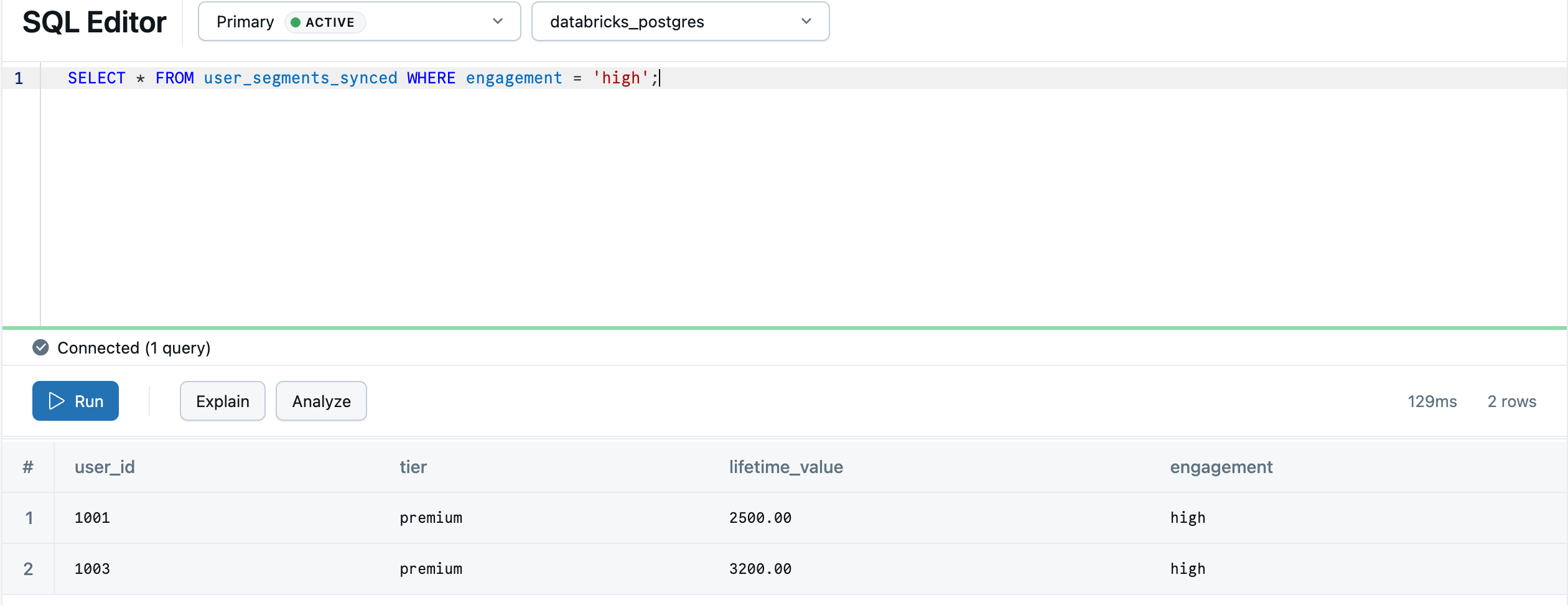
As suas análises de lakehouse estão agora disponíveis para processamento em tempo real na sua base de dados transacional. Para sincronização contínua, configurações avançadas e mapeamentos de tipos de dados, veja Reverse ETL.