Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Importante
O Autoscaling Lakebase está disponível nas seguintes regiões: eastus, eastus2, centralus, southcentralus, westus, westus2, canadacentral, brazilsouth, northeurope, uksouth, westeurope, australiaeast, centralindia, southeastasia.
O Autoscaling do Lakebase é a versão mais recente do Lakebase, com computação autoescalável, escala até zero, ramificação e restauração instantânea. Se é utilizador do Lakebase Provisioned, consulte Lakebase Provisioned.
As tabelas sincronizadas permitem-lhe fornecer dados de lakehouse através do Lakebase Postgres. As tabelas do Unity Catalog sincronizam-se no Postgres para que as aplicações possam consultar diretamente os dados do lakehouse com baixa latência. Este processo é vulgarmente conhecido como ETL inverso. O Lakehouse está otimizado para análises e enriquecimento, enquanto o Lakebase foi concebido para cargas de trabalho operacionais que requerem consultas rápidas tipo lookup e consistência transacional.
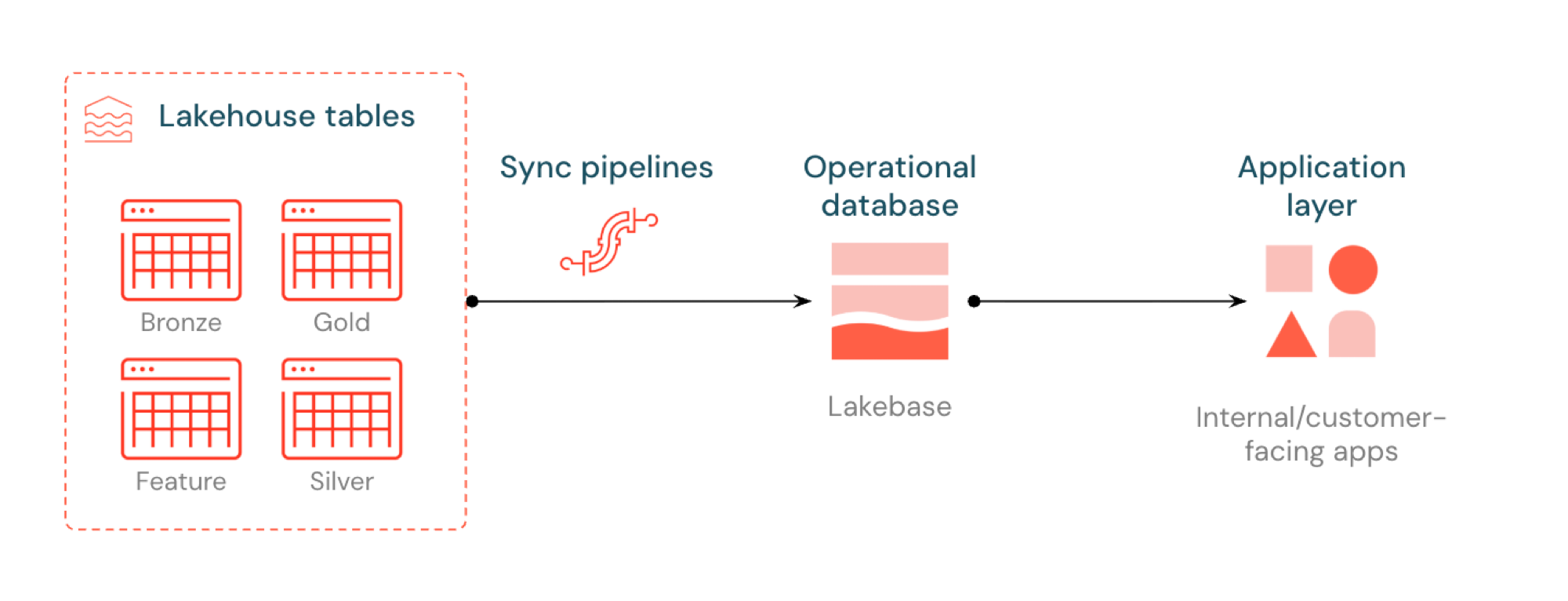
O que são tabelas sincronizadas?
As tabelas sincronizadas permitem-lhe fornecer dados de nível analítico do Unity Catalog através do Lakebase Postgres, tornando-os disponíveis para aplicações que necessitem de consultas de baixa latência (abaixo de 10ms) e transações ACID completas. Eles fazem a ponte entre o armazenamento analítico e os sistemas operacionais, mantendo os seus dados prontos para serem usados em aplicações em tempo real.
Fontes suportadas
As tabelas sincronizadas suportam os seguintes tipos de fonte do Catálogo Unity:
- Tabelas Delta geridas e externas
- Tabelas Iceberg geridas pelo sistema e externas
- Opiniões e pontos de vista materializados
Como funciona
Tabelas sincronizadas Databricks criam uma cópia gerida dos seus dados do Catálogo Unity no Lakebase. Quando crias uma tabela sincronizada, obtém:
- Uma tabela sincronizada no Unity Catalog que faz referência ao pipeline de sincronização
- Uma tabela Postgres no Lakebase (apenas leitura, consultável pelas suas aplicações)
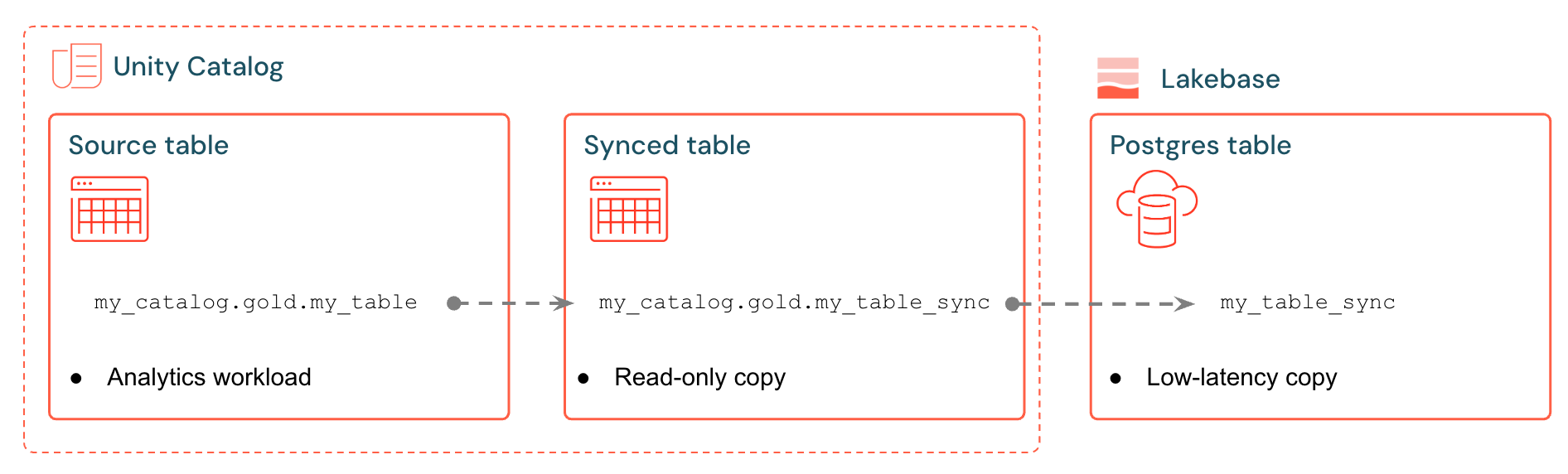
Por exemplo, pode sincronizar tabelas de ouro, funcionalidades projetadas ou saídas de ML de analytics.gold.user_profiles numa nova tabela analytics.gold.user_profiles_synced sincronizada. No Postgres, o nome do esquema do Catálogo Unity torna-se o nome do esquema Postgres, pelo que isto aparece como "gold"."user_profiles_synced":
SELECT * FROM "gold"."user_profiles_synced" WHERE "user_id" = 12345;
As aplicações ligam-se aos drivers Postgres padrão e consultam os dados sincronizados juntamente com o seu próprio estado operacional.
Advertência
Embora seja possível modificar uma tabela sincronizada diretamente no Postgres, o Azure Databricks recomenda estritamente executar apenas consultas de leitura para proteger a integridade dos dados com a fonte. Para operações suportadas em tabelas sincronizadas, veja Operações suportadas.
Os pipelines de sincronização usam os Lakeflow Spark Declarative Pipelines geridos para atualizar continuamente tanto a tabela sincronizada do Unity Catalog como a tabela Postgres com as alterações provenientes da tabela de origem. Cada sincronização pode usar até 16 ligações à sua base de dados Lakebase.
O Lakebase Postgres suporta até 1.000 ligações concorrentes com garantias transacionais, para que as aplicações possam ler dados enriquecidos enquanto também tratam de inserções, atualizações e eliminações na mesma base de dados.
Modos de sincronização
Escolha o modo de sincronização certo com base nas necessidades da sua aplicação:
| Mode | Descrição | Quando utilizar | Desempenho |
|---|---|---|---|
| Instantâneo | Cópia única de todos os dados | A fonte altera >10% das linhas por ciclo, ou a fonte não suporta CDF (views, tabelas Iceberg) | 10 vezes mais eficiente se modificar >10% de dados fonte |
| Acionado | Atualizações agendadas que correm sob demanda ou em intervalos | As linhas de origem mudam numa cadência conhecida. Inserções, atualizações e eliminações são propagadas a cada atualização. | Bom equilíbrio custo/atraso. É caro se funcionar <em intervalos de 5 minutos |
| Contínuo | Streaming em tempo real com segundos de latência | As alterações têm de aparecer no Lakebase quase em tempo real | Menor atraso, maior custo. Intervalos mínimos de 15 segundos |
Os modos Triggered e Continuous requerem que o Change Data Feed (CDF) esteja ativado na sua tabela de origem. Se o CDF não estiver ativado, vais ver um aviso na interface com o comando exato ALTER TABLE para executar. Para mais detalhes sobre o Feed de Dados de Alteração, consulte Usar o feed de dados de alterações do Delta Lake nos Databricks.
Exemplos de casos de uso
Pode usar tabelas sincronizadas para casos de uso de serviço de dados como:
- Motores de personalização que servem perfis de utilizador frescos às aplicações Databricks
- Aplicações que servem previsões de modelos ou valores de atributos calculados na arquitetura de dados lakehouse
- Dashboards voltados para o cliente que servem KPIs em tempo real
- Serviços de deteção de fraude que atribuem pontuações de risco para ação imediata
- Ferramentas de suporte que disponibilizam registos de clientes enriquecidos a partir de dados de lakehouse
Criar uma tabela sincronizada (UI)
O fluxo de trabalho da interface está descrito abaixo.
Pré-requisitos
Precisas:
- Um espaço de trabalho Databricks com o Lakebase ativado.
- Um projeto Lakebase (ver Criar um projeto).
- Uma tabela do Unity Catalog para sincronizar.
- Permissões para criar tabelas sincronizadas. Precisas USE_SCHEMA e CREATE_TABLE em qualquer esquema que usares. As opções de catálogo e esquema no Create synced table flow listam apenas esquemas onde a sua identidade tem estes privilégios.
Para planeamento de capacidade e compatibilidade de tipos de dados, consulte Tipos de dados e compatibilidade e Planeamento de capacidade.
Passo 1: Selecione a sua tabela de origem
Vai a Catálogo na barra lateral do espaço de trabalho e seleciona a tabela do Catálogo Unity que queres sincronizar.
Passo 2: Ativar o Feed de Alteração de Dados (se necessário)
Se planeia usar os modos de sincronização Desencadeada ou Contínua , a sua tabela de origem precisa de ativar o Change Data Feed. Verifica se a tua tabela já tem o CDF ativado, ou executa este comando num editor SQL ou caderno:
ALTER TABLE your_catalog.your_schema.your_table
SET TBLPROPERTIES (delta.enableChangeDataFeed = true)
Substitui your_catalog.your_schema.your_table pelo nome real da tua mesa.
Passo 3: Criar tabela sincronizada
Clique em Criar>tabela sincronizada na vista de detalhes da tabela.
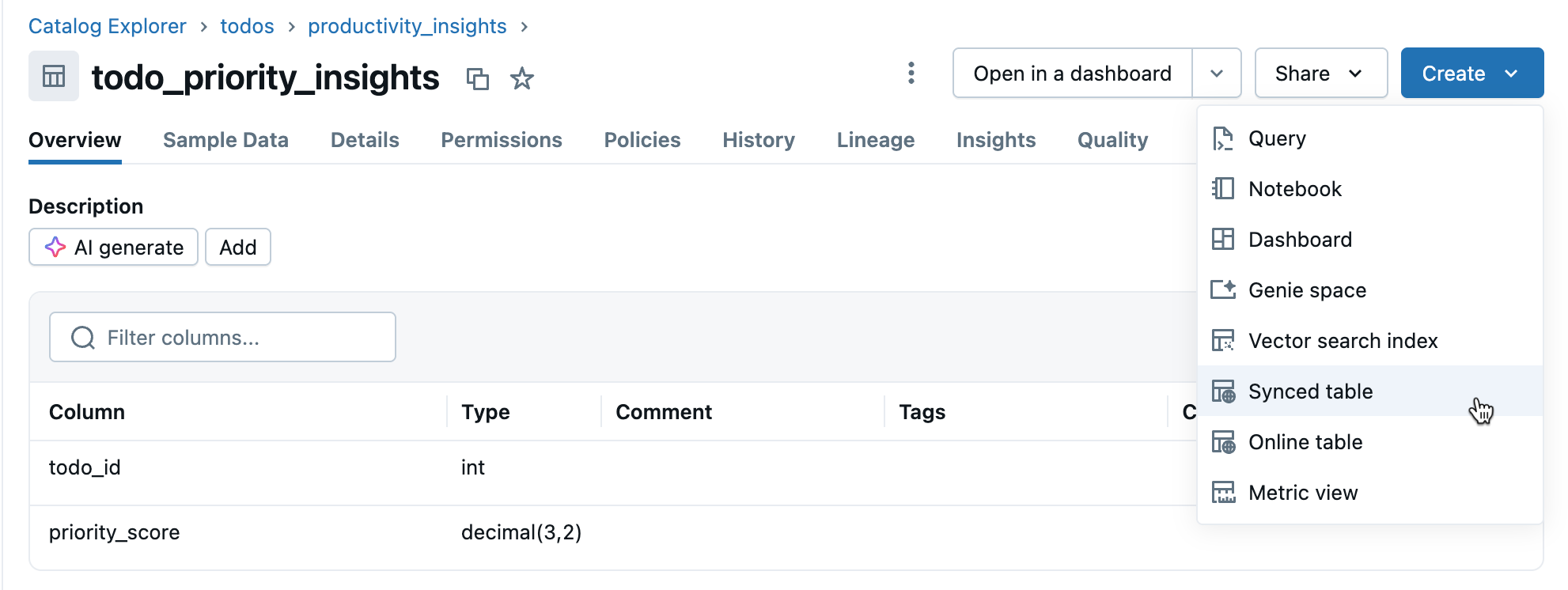
Passo 4: Configurar
No diálogo Criar tabela sincronizada :
As listas de catálogo e de esquemas incluem apenas esquemas do Catálogo Unity onde o utilizador atual tem privilégios de USE_SCHEMA e CREATE_TABLE . Se não vires um esquema que esperas, confirma as tuas permissões com o administrador do catálogo.
- Nome da tabela: Introduza um nome para a sua tabela sincronizada (é criada no mesmo catálogo e esquema que a sua tabela de origem). Isto cria tanto uma tabela sincronizada do Unity Catalog como uma tabela Postgres que pode consultar.
- Tipo de base de dados: Escolha Lakebase Serverless (Autoscaling).
- Modo de sincronização: Escolha Snapshot, Triggered ou Contínuo conforme as suas necessidades (veja modos de sincronização acima).
- Configura as escolhas do teu projeto, branch e base de dados.
- Verifica se a chave primária está correta (normalmente detetada automaticamente).
Se escolheste o modo Triggered ou Continuous e ainda não ativaste o Change Data Feed, vais ver um aviso com o comando exato para executar. Para questões de compatibilidade de tipos de dados, consulte Tipos de dados e compatibilidade.
Clique em Criar para criar a tabela sincronizada.
Passo 5: Monitorizar
Após a criação, monitorize a tabela sincronizada no Catálogo. O separador Visão Geral mostra o estado da sincronização, a configuração, o estado do pipeline e o carimbo temporal da última sincronização. Usa o Sync Now para atualização manual.
Agendar ou acionar sincronizações subsequentes
O instantâneo inicial é executado automaticamente no momento da criação. Para os modos Snapshot e Triggered , as sincronizações subsequentes devem ser disparadas explicitamente. O modo contínuo é autogestivo.
Tarefa de Sincronização de Tabela de Dados no Pipeline
A tarefa do pipeline de sincronização de tabelas da base de dados no Lakeflow Jobs executa o pipeline de uma tabela sincronizada como um passo do fluxo de trabalho. Configura o trabalho com um gatilho de atualização de tabela ou um agendamento.
Trigger nas atualizações da tabela de origem
O trabalho é acionado quando a tabela do Catálogo Unity de origem é atualizada. Com o modo Triggered , apenas novas alterações são aplicadas de forma incremental, proporcionando uma frescura quase em tempo real sem o custo sempre ativo do modo Contínuo.
- Na barra lateral, clique em Fluxos de Trabalho.
- Clica em Criar emprego ou abre um emprego existente.
- No separador Tarefas, clique + Adicionar outro tipo de tarefa.
- Em Ingestão e Transformação, selecione Pipeline de Sincronização de Tabela de Base de Dados.
- No campo Pipeline , selecione o pipeline associado à sua tabela sincronizada.
- Em Horários e Gatilhos, clique em Adicionar gatilho.
- Selecione a atualização da tabela como tipo de gatilho.
- Em Tabelas, selecione a tabela fonte do Catálogo Unity para monitorizar.
- Clique em Salvar.
Ativar por agendamento
Executa a sincronização a uma cadência fixa. Ideal para o modo Snapshot , onde uma atualização completa noturna ou semanal é tipicamente o padrão mais eficiente.
- Siga os passos 1–5 acima para adicionar uma tarefa de uma pipeline de sincronização de Tabela de Bases de Dados a um trabalho.
- Em Horários e Gatilhos, clique em Adicionar gatilho.
- Selecione Agendado como tipo de disparador.
- Define o teu cron schedule e fuso horário, depois clica em Guardar.
Usando o SDK
Desencadeie uma sincronização programaticamente, por exemplo, no final de um caderno ou pipeline precedente.
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Get the pipeline ID from the synced table
table = w.database.get_synced_database_table(name="catalog.schema.synced_table")
pipeline_id = table.data_synchronization_status.pipeline_id
# Trigger a sync run
w.pipelines.start_update(pipeline_id=pipeline_id)
Tipos de dados e compatibilidade
Os tipos de dados do Unity Catalog são mapeados para tipos Postgres ao criar tabelas sincronizadas. Os tipos complexos (ARRAY, MAP, STRUCT) são armazenados como JSONB no Postgres.
| Tipo de coluna de origem | Tipo de coluna Postgres |
|---|---|
| BIGINT | BIGINT |
| BINARY | BYTEA |
| BOOLEANO | BOOLEANO |
| DATE | DATE |
| DECIMAL(p,s) | NUMÉRICO |
| DUPLO | Double Precision |
| FLOAT | REAL |
| INT | INTEIRO |
| INTERVALO | INTERVALO |
| SMALLINT | SMALLINT |
| STRING | TEXTO |
| DATA E HORA | CARIMBO DE DATA/HORA COM FUSO HORÁRIO |
| TIMESTAMP_NTZ | MARCA TEMPORAL SEM ZONA HORÁRIA |
| TINYINT | SMALLINT |
| ARRAY<tipoDeElemento> | JSONB |
| MAPA<keyType,valueType> | JSONB |
| STRUCT<nomeCampo:tipoCampo[, ...]> | JSONB |
Observação
GEOGRAFIA, GEOMETRIA, VARIANTES e tipos de OBJETO não são suportados.
Lidar com caracteres inválidos
Certos caracteres como bytes nulos (0x00) são permitidos nas colunas STRING, ARRAY, MAP ou STRUCT do Unity Catalog, mas não suportados em colunas Postgres TEXT ou JSONB. Isto pode causar falhas de sincronização com erros como:
ERROR: invalid byte sequence for encoding "UTF8": 0x00
ERROR: unsupported Unicode escape sequence DETAIL: \u0000 cannot be converted to text
Soluções:
Sanitizar campos de strings: Remover caracteres não suportados antes de sincronizar. Para bytes nulos nas colunas STRING:
SELECT REPLACE(column_name, CAST(CHAR(0) AS STRING), '') AS cleaned_column FROM your_tableConverter para BINARY: Para colunas STRING onde é necessário preservar bytes brutos, converta para o tipo BINARY.
Planeamento de capacidade
Ao planear a implementação das tabelas sincronizadas, considere estes requisitos de recursos:
- Utilização da ligação: Cada tabela sincronizada utiliza até 16 ligações à sua base de dados Lakebase, que contam para o limite de ligação da instância.
- Limites de tamanho: O limite total de tamanho lógico dos dados em todas as tabelas sincronizadas é de 8 TB. As tabelas individuais não têm limites, mas o Databricks recomenda não ultrapassar 1 TB para tabelas que requerem atualizações.
-
Requisitos de nomenclatura: Os nomes de bases de dados, esquemas e tabelas podem conter apenas caracteres alfanuméricos e sublinhados (
[A-Za-z0-9_]+). - Evolução do esquema: Apenas as alterações aditivas do esquema (como adicionar colunas) são suportadas para os modos Triggered e Contínuo.
- Taxa de atualização: Para o Autoscaling do Lakebase, o pipeline de sincronização suporta escritas contínuas e acionadas a aproximadamente 150 linhas por segundo por Unidade de Capacidade (UC) e escritas instantâneas até 2.000 linhas por segundo por Unidade de Capacidade (UC).
Operações permitidas em tabelas sincronizadas no Postgres
O Azure Databricks recomenda realizar apenas as seguintes operações no Postgres para tabelas sincronizadas, para evitar sobrescrições acidentais ou inconsistências de dados:
- Consultas somente leitura
- Criação de índices
- Soltar a tabela (para liberar espaço depois de remover a tabela sincronizada do Unity Catalog)
Embora seja possível modificar tabelas sincronizadas no Postgres de outras formas, isso interfere com o pipeline de sincronização.
Eliminar uma tabela sincronizada
Para eliminar uma tabela sincronizada, deve removê-la tanto do Unity Catalog como do Postgres:
Apagar do Catálogo Unity: No Catálogo, encontre a sua tabela sincronizada, clique no
 menu e selecione Eliminar. Isto impede a atualização dos dados, mas deixa a tabela no Postgres.
menu e selecione Eliminar. Isto impede a atualização dos dados, mas deixa a tabela no Postgres.Remover do Postgres: Ligue-se à sua base de dados Lakebase e remova a tabela para libertar espaço:
DROP TABLE your_database.your_schema.your_table;
Podes usar o editor SQL ou ferramentas externas para te ligares ao Postgres.
Mais informações
| Tarefa | Descrição |
|---|---|
| Criar um projeto | Criar um projeto Lakebase |
| Conecte-se ao seu banco de dados | Aprenda as opções de ligação para Lakebase |
| Base de dados de registos no Unity Catalog | Torne os seus dados do Lakebase visíveis no Unity Catalog para governação unificada e consultas entre fontes |
| Integração com o Catálogo Unity | Compreender a governação e as permissões |
Outras opções
Para sincronizar dados em sistemas não-Databricks, consulte as soluções Partner Connect reverse ETL como Census e Hightouch.