Criar um cluster Apache Flink® no HDInsight no AKS com o portal do Azure
Importante
O Azure HDInsight no AKS foi desativado em 31 de janeiro de 2025. Saiba mais com este anúncio.
Você precisa migrar suas cargas de trabalho para Microsoft Fabric ou um produto equivalente do Azure para evitar o encerramento abrupto de suas cargas de trabalho.
Importante
Esta funcionalidade está atualmente em pré-visualização. Os Termos de Utilização Suplementares para Pré-visualizações do Microsoft Azure incluem mais termos legais que se aplicam a funcionalidades do Azure que estão em versão beta, em pré-visualização ou não lançadas para o público em geral. Para obter informações sobre essa pré-visualização específica, consulte Azure HDInsight no AKS informações sobre a pré-visualização. Para perguntas ou sugestões de recursos, envie uma solicitação no AskHDInsight com os detalhes e siga-nos para obter mais atualizações sobre da Comunidade do Azure HDInsight.
Conclua as etapas a seguir para criar um cluster Apache Flink no portal do Azure.
Pré-requisitos
Preencha os pré-requisitos nas seguintes seções:
Importante
- Para criar um cluster em um novo pool de clusters, atribua a função "Operador de Identidade Gerenciada" MSI do AKS agentpool na identidade gerenciada atribuída pelo usuário criada como parte do pré-requisito de recurso. Caso você tenha as permissões necessárias, esta etapa é automatizada durante a criação.
- A identidade gerida do pool de agentes AKS é criada durante a criação do cluster. Você pode identificar a identidade gerida do agentpool do AKS por (o nome do seu clusterpool)-agentpool. Siga os seguintes passos para atribuir a função.
Criar um Apache Flink cluster
Os clusters Flink podem ser criados assim que a implantação do pool de clusters for concluída, deixe-nos examinar as etapas caso você esteja começando com um pool de clusters existente
No portal do Azure, digite pools de cluster HDInsight/HDInsight/HDInsight no AKS e selecione "Azure HDInsight em Pools de Clusters AKS" para ir para a página dos pools de clusters. Na página Pools de clusters do HDInsight no AKS, selecione o pool de clusters no qual você deseja criar um novo cluster Flink.

Na página específica do pool de clusters, clique em + Novo cluster e forneça as seguintes informações:
Propriedade Descrição Subscrição Este campo é preenchido automaticamente com a assinatura do Azure que foi registrada para o Pool de Clusters. Grupo de Recursos Este campo é preenchido automaticamente e mostra o grupo de recursos no pool de clusters. Região Este campo é preenchido automaticamente e mostra a região selecionada no pool de clusters. Pool de clusters Este campo é preenchido automaticamente e mostra o nome do pool de clusters no qual o cluster está sendo criado. Para criar um cluster em um pool diferente, localize esse pool de clusters no portal e clique em + Novo cluster. HDInsight na versão do pool AKS Este campo é preenchido automaticamente e mostra a versão do pool de clusters na qual o cluster está sendo criado. HDInsight na versão AKS Selecione a versão secundária ou a versão de patch do HDInsight no AKS do novo cluster. Tipo de cluster Na lista suspensa, selecione Flink. Nome do cluster Insira o nome do novo cluster. Identidade gerenciada atribuída pelo usuário Na lista suspensa, selecione a identidade gerenciada a ser usada com o cluster. Se você for o proprietário da Identidade de Serviço Gerenciado (MSI) e o MSI não tiver a função de Operador de Identidade Gerenciada no cluster, clique no link abaixo da caixa para atribuir a permissão necessária do MSI do pool de agentes do AKS. Se o MSI já tiver as permissões corretas, nenhum link será mostrado. Consulte o Pré-requisito para outras atribuições de função necessárias para o MSI. Conta de armazenamento Na lista suspensa, selecione a conta de armazenamento a ser associada ao cluster Flink e especifique o nome do contêiner. A identidade gerenciada também recebe acesso à conta de armazenamento especificada, usando a função 'Proprietário de Dados de Blob de Armazenamento' durante a criação do cluster. Rede virtual A rede virtual para o cluster. Sub-rede A sub-rede virtual para o cluster. Ativação do catálogo do Hive para o Flink SQL.
Propriedade Descrição Usar o catálogo do Hive Habilite essa opção para usar um metastore externo do Hive. Banco de dados SQL para Hive Na lista suspensa, selecione a Base de Dados SQL onde deve adicionar tabelas de metastore de Hive. Nome de usuário do administrador do SQL Insira o nome de usuário do administrador do SQL Server. Essa conta é usada pelo metastore para se comunicar com o banco de dados SQL. Cofre de chaves Na lista suspensa, selecione o Cofre da Chave, que contém um segredo com senha para o nome de usuário do administrador do SQL Server. É necessário configurar uma política de acesso com todas as permissões necessárias, como permissões de chave, permissões secretas e permissões de certificado para o MSI, que está sendo usado para a criação do cluster. O MSI precisa de uma função de Administrador do Cofre de Chaves, adicione as permissões necessárias usando o IAM. Nome do segredo da palavra-passe SQL Digite o nome secreto do Cofre de Chaves onde a senha do banco de dados SQL está armazenada. 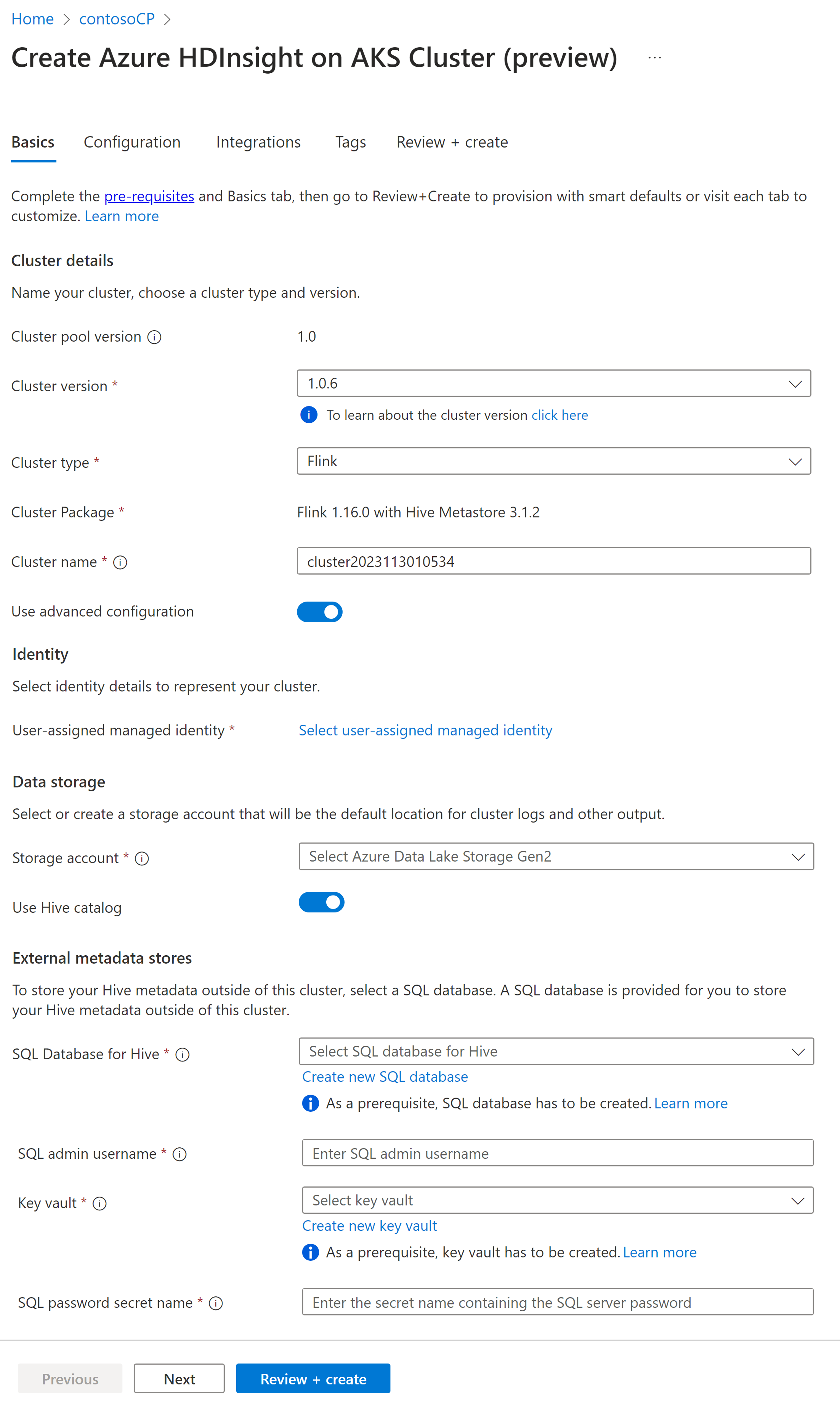
Observação
Por padrão, usamos a conta de armazenamento do para o catálogo do Hive, da mesma maneira que a conta de armazenamento e o contêiner usados durante a criação do cluster.
Selecione Próximo: Configuração para continuar.
Na página Configuration, forneça as seguintes informações:
Propriedade Descrição Tamanho do nó Selecione o tamanho a usar para os nós Flink, tanto os principais como os de trabalho. Número de nós Selecione o número de nós para o cluster Flink; Por padrão, os nós principais são dois. O dimensionamento dos nós de trabalho ajuda a determinar as configurações do gerenciador de tarefas para o Flink. O gerenciador de tarefas e o servidor de histórico estão nos nós principais. Na seção de Configuração do Serviço, forneça as seguintes informações:
Propriedade Descrição CPU do gestor de tarefas Inteiro. Insira o tamanho das CPUs do gerenciador de tarefas (em núcleos). Memória do gestor de tarefas em MB Introduza o tamanho da memória do Gestor de tarefas em MB. Mínimo de 1800 MB. CPU do gerenciador de tarefas Inteiro. Insira o número de CPUs para o gerenciador de tarefas (em núcleos). Memória do gestor de tarefas em MB Insira o tamanho da memória em MB. Mínimo de 1800 MB. CPU do servidor de histórico Inteiro. Insira o número de CPUs para o gerenciador de tarefas (em núcleos). Memória do servidor de histórico em MB Insira o tamanho da memória em MB. Mínimo de 1800 MB. 
Observação
- O servidor de histórico pode ser ativado/desativado conforme necessário.
- A escala automática baseada em programação é suportada no Flink. Você pode definir o número de nós de computação conforme necessário. Por exemplo, um dimensionamento automático agendado é ativado, com o número padrão de nós de trabalho fixado em 3. E durante os dias úteis, das 9:00 às 20:00 UTC, o número de nós de trabalho está configurado para ser 10. Mais tarde, ele precisa ser padronizado para 3 nós (entre 20:00 UTC e 09:00 UTC do dia seguinte). Durante os fins de semana, das 9:00 UTC às 20:00 UTC, existem 4 nós de trabalho.
Na seção Auto Scale & SSH, atualize o seguinte:
Propriedade Descrição Dimensionamento automático Após a seleção, você poderá escolher a escala automática baseada em cronograma para configurar a agenda para operações de dimensionamento. Ativar SSH Após a seleção, você pode optar pelo número total de nós SSH necessários, que são os pontos de acesso para a CLI do Flink usando o Secure Shell. O máximo de nós SSH permitidos é 5. 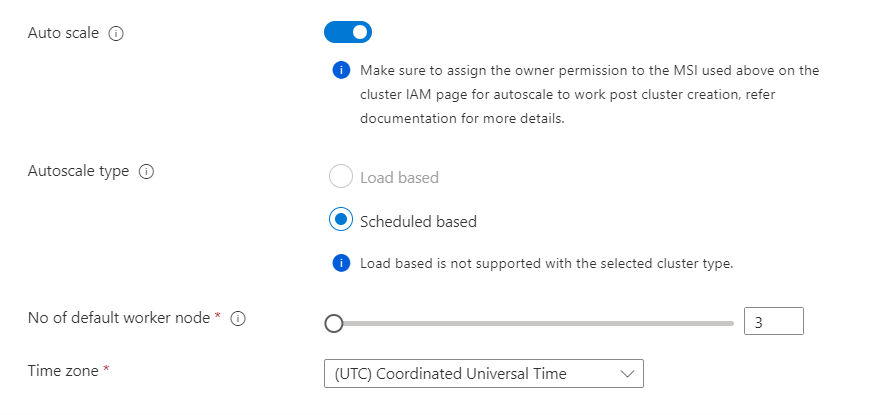

Clique no botão "Seguinte: Integração" para continuar para a próxima página.
Na página Integração , forneça as seguintes informações:
Propriedade Descrição Análise de logs Esse recurso estará disponível somente se o pool de clusters tiver um espaço de trabalho de análise de log associado, uma vez habilitado, os logs a serem coletados poderão ser selecionados. Azure Prometheus Esse recurso é para exibir Insights e Logs diretamente em seu cluster enviando métricas e logs para o espaço de trabalho do Azure Monitor. 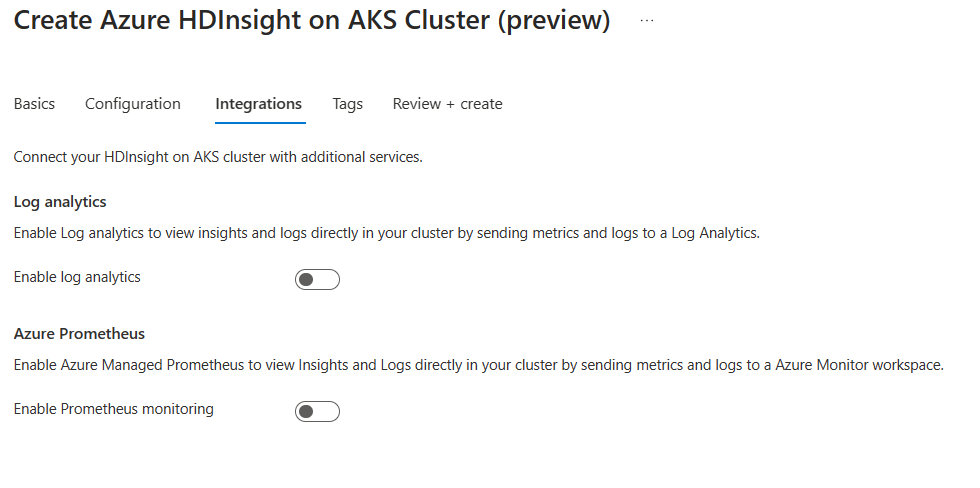
Clique no botão Next: Tags para continuar para a próxima página.
Na página Tags, forneça as seguintes informações:
Propriedade Descrição Nome Opcional. Insira um nome como HDInsight no AKS para identificar facilmente todos os recursos associados aos recursos do cluster. Valor Você pode deixar isso em branco. Recurso Selecione Todos os recursos selecionados. Selecione Seguinte: Rever + criar para continuar.
Na página Revisar e criar, procure a mensagem Validação bem-sucedida no topo da página e, em seguida, clique em Criar.
O Deployment está em processo, e a página é exibida onde o cluster é criado. Leva de 5 a 10 minutos para criar o cluster. Depois que o cluster é criado, a mensagem "Sua implantação está concluída" é exibida. Se você sair da página, poderá verificar suas Notificações para saber o status atual.
Observação
Apache, Apache Flink, Flink e nomes de projetos de código aberto associados são marcas comerciais da Apache Software Foundation (ASF).