Integração do Azure Data Explorer e Apache Flink®
O Azure Data Explorer é uma plataforma de análise de big data totalmente gerenciada e de alto desempenho que facilita a análise de grandes volumes de dados quase em tempo real.
O ADX ajuda os usuários na análise de grandes volumes de dados de aplicativos de streaming, sites, dispositivos IoT, etc. A integração do Apache Flink com o ADX ajuda você a processar dados em tempo real e analisá-los no ADX.
Pré-requisitos
Etapas para usar o Azure Data Explorer como coletor no Flink
Crie o cluster Flink.
Crie ADX com banco de dados e tabela conforme necessário.
Adicione permissões ingestor para a identidade gerenciada no Kusto.
.add database <DATABASE_NAME> ingestors ('aadapp=CLIENT_ID_OF_MANAGED_IDENTITY')Execute um programa de exemplo definindo o URI (Uniform Resource Identifier) do cluster Kusto, o banco de dados e a identidade gerenciada usados e a tabela na qual ele precisa ser gravado.
Clone o projeto flink-connector-kusto: https://github.com/Azure/flink-connector-kusto.git
Crie a tabela no ADX usando o seguinte comando
.create table CryptoRatesHeartbeatTimeBatch (processing_dttm: datetime, ['type']: string, last_trade_id: string, product_id: string, sequence: long, ['time']: datetime)Atualize o arquivo FlinkKustoSinkSample.java com o URI do cluster Kusto correto, o banco de dados e a identidade gerenciada usada.
String database = "sdktests"; //ADX database name String msiClientId = “xxxx-xxxx-xxxx”; //Provide the client id of the Managed identity which is linked to the Flink cluster String cluster = "https://trdp-1665b5eybxs0tbett.z8.kusto.fabric.microsoft.com/"; //Data explorer Cluster URI KustoConnectionOptions kustoConnectionOptions = KustoConnectionOptions.builder() .setManagedIdentityAppId(msiClientId).setClusterUrl(cluster).build(); String defaultTable = "CryptoRatesHeartbeatTimeBatch"; //Table where the data needs to be written KustoWriteOptions kustoWriteOptionsHeartbeat = KustoWriteOptions.builder() .withDatabase(database).withTable(defaultTable).withBatchIntervalMs(30000)Mais tarde, construa o projeto usando "mvn clean package"
Localize o arquivo JAR chamado 'samples-java-1.0-SNAPSHOT-shaded.jar' na pasta 'sample-java/target', carregue esse arquivo JAR na interface do usuário do Flink e envie o trabalho.
Consulte a tabela Kusto para verificar a saída
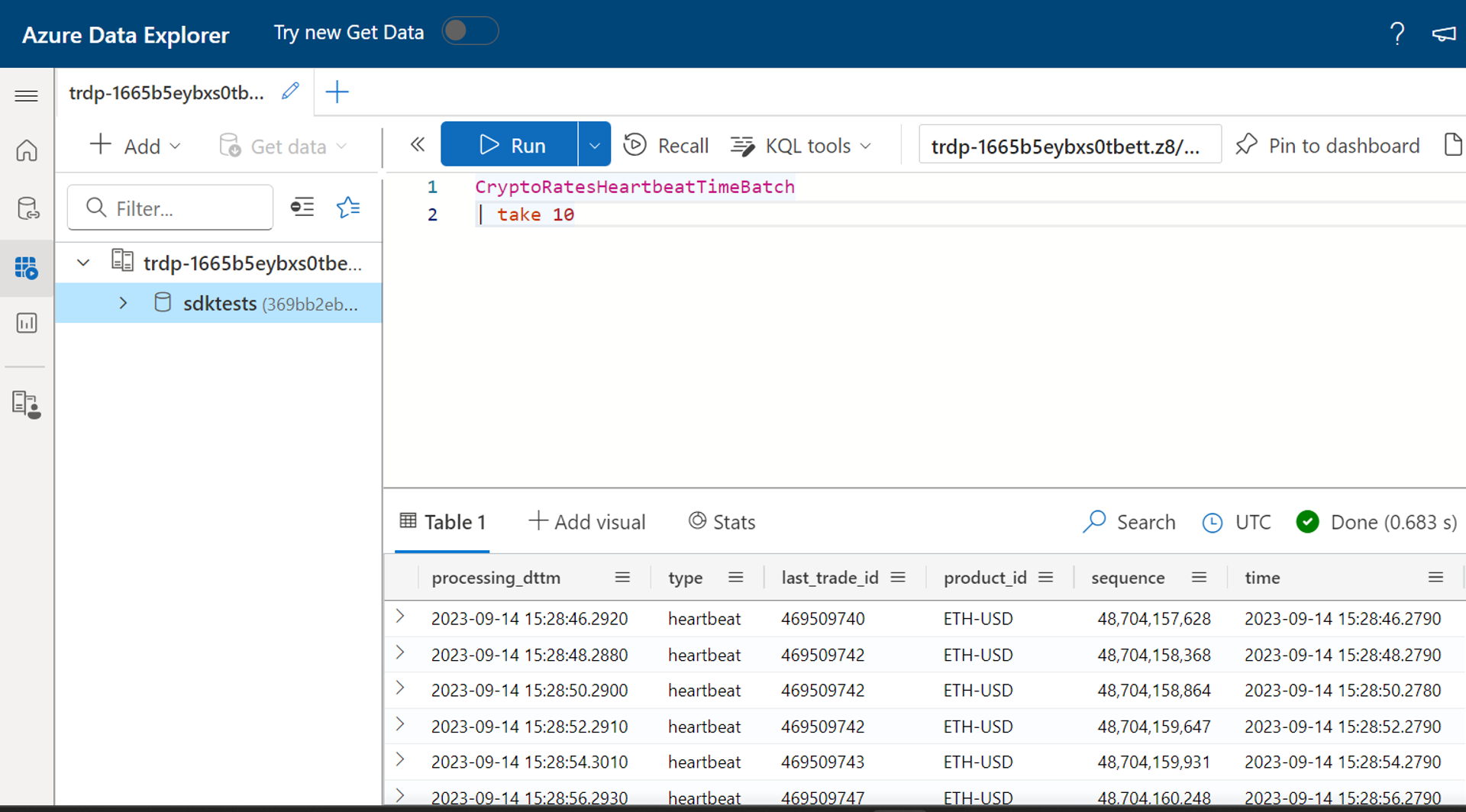
Não há atraso na gravação dos dados na tabela Kusto do Flink.

Referência
- Site do Apache Flink
- Apache, Apache Flink, Flink e nomes de projetos de código aberto associados são marcas comerciais da Apache Software Foundation (ASF).