Escreva mensagens no Apache HBase® com a API Apache Flink® DataStream
Importante
Esta funcionalidade está atualmente em pré-visualização. Os Termos de Utilização Suplementares para Pré-visualizações do Microsoft Azure incluem mais termos legais que se aplicam a funcionalidades do Azure que estão em versão beta, em pré-visualização ou ainda não disponibilizadas para disponibilidade geral. Para obter informações sobre essa visualização específica, consulte Informações de visualização do Azure HDInsight no AKS. Para perguntas ou sugestões de recursos, envie uma solicitação no AskHDInsight com os detalhes e siga-nos para obter mais atualizações na Comunidade do Azure HDInsight.
Neste artigo, saiba como escrever mensagens no HBase com a API Apache Flink DataStream.
Descrição geral
Apache Flink oferece conector HBase como um coletor, com este conector com Flink você pode armazenar a saída de um aplicativo de processamento em tempo real no HBase. Saiba como processar dados de streaming no HDInsight Kafka como origem, realizar transformações e, em seguida, afundar na tabela HBase do HDInsight.
Em um cenário do mundo real, este exemplo é uma camada de análise de fluxo para obter valor da análise da Internet das Coisas (IOT), que usa dados de sensores ao vivo. O Flink Stream pode ler dados do artigo de Kafka e escrevê-los na tabela HBase. Se houver um aplicativo IOT de streaming em tempo real, as informações podem ser coletadas, transformadas e otimizadas.
Pré-requisitos
- Cluster Apache Flink no HDInsight no AKS
- Cluster Apache Kafka no HDInsight
- Cluster Apache HBase 2.4.11 no HDInsight
- É necessário garantir que o HDInsight no cluster AKS possa se conectar ao cluster HDInsight com a mesma rede virtual.
- Projeto Maven no IntelliJ IDEA para desenvolvimento em uma VM do Azure na mesma VNet
Passos de Implementação
Use pipeline para produzir o tópico Kafka (tópico do evento de clique do usuário)
weblog.py
import json
import random
import time
from datetime import datetime
user_set = [
'John',
'XiaoMing',
'Mike',
'Tom',
'Machael',
'Zheng Hu',
'Zark',
'Tim',
'Andrew',
'Pick',
'Sean',
'Luke',
'Chunck'
]
web_set = [
'https://github.com',
'https://www.bing.com/new',
'https://kafka.apache.org',
'https://hbase.apache.org',
'https://flink.apache.org',
'https://spark.apache.org',
'https://trino.io',
'https://hadoop.apache.org',
'https://stackoverflow.com',
'https://docs.python.org',
'https://azure.microsoft.com/products/category/storage',
'/azure/hdinsight/hdinsight-overview',
'https://azure.microsoft.com/products/category/storage'
]
def main():
while True:
if random.randrange(13) < 4:
url = random.choice(web_set[:3])
else:
url = random.choice(web_set)
log_entry = {
'userName': random.choice(user_set),
'visitURL': url,
'ts': datetime.now().strftime("%m/%d/%Y %H:%M:%S")
}
print(json.dumps(log_entry))
time.sleep(0.05)
if __name__ == "__main__":
main()
Use pipeline para produzir o tópico Apache Kafka
Vamos usar click_events para o tópico Kafka
python weblog.py | /usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --bootstrap-server wn0-contsk:9092 --topic click_events
Exemplos de comandos no Kafka
-- create topic (replace with your Kafka bootstrap server)
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 3 --topic click_events --bootstrap-server wn0-contsk:9092
-- delete topic (replace with your Kafka bootstrap server)
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic click_events --bootstrap-server wn0-contsk:9092
-- produce topic (replace with your Kafka bootstrap server)
python weblog.py | /usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --bootstrap-server wn0-contsk:9092 --topic click_events
-- consume topic
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server wn0-contsk:9092 --topic click_events --from-beginning
{"userName": "Luke", "visitURL": "https://azure.microsoft.com/products/category/storage", "ts": "07/11/2023 06:39:43"}
{"userName": "Sean", "visitURL": "https://www.bing.com/new", "ts": "07/11/2023 06:39:43"}
{"userName": "XiaoMing", "visitURL": "https://hbase.apache.org", "ts": "07/11/2023 06:39:43"}
{"userName": "Machael", "visitURL": "https://www.bing.com/new", "ts": "07/11/2023 06:39:43"}
{"userName": "Andrew", "visitURL": "https://github.com", "ts": "07/11/2023 06:39:43"}
{"userName": "Zark", "visitURL": "https://kafka.apache.org", "ts": "07/11/2023 06:39:43"}
{"userName": "XiaoMing", "visitURL": "https://trino.io", "ts": "07/11/2023 06:39:43"}
{"userName": "Zark", "visitURL": "https://flink.apache.org", "ts": "07/11/2023 06:39:43"}
{"userName": "Mike", "visitURL": "https://kafka.apache.org", "ts": "07/11/2023 06:39:43"}
{"userName": "Zark", "visitURL": "https://docs.python.org", "ts": "07/11/2023 06:39:44"}
{"userName": "John", "visitURL": "https://www.bing.com/new", "ts": "07/11/2023 06:39:44"}
{"userName": "Mike", "visitURL": "https://hadoop.apache.org", "ts": "07/11/2023 06:39:44"}
{"userName": "Tim", "visitURL": "https://www.bing.com/new", "ts": "07/11/2023 06:39:44"}
.....
Criar tabela HBase no cluster HDInsight
root@hn0-contos:/home/sshuser# hbase shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/hdp/5.1.1.3/hadoop/lib/slf4j-reload4j-1.7.35.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/hdp/5.1.1.3/hbase/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Reload4jLoggerFactory]
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For more information, see, http://hbase.apache.org/2.0/book.html#shell
Version 2.4.11.5.1.1.3, rUnknown, Thu Apr 20 12:31:07 UTC 2023
Took 0.0032 seconds
hbase:001:0> create 'user_click_events','user_info'
Created table user_click_events
Took 5.1399 seconds
=> Hbase::Table - user_click_events
hbase:002:0>
Desenvolver o projeto para submissão de jar no Flink
Crie um projeto Maven com os seguintes pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>contoso.example</groupId>
<artifactId>FlinkHbaseDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<hbase.version>2.4.11</hbase.version>
<kafka.version>3.2.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-hbase-base -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hbase-base</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-base -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Código fonte
Escrevendo o programa HBase Sink
HBaseWriterSink
package contoso.example;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseWriterSink extends RichSinkFunction<Tuple3<String,String,String>> {
String hbase_zk = "<update-hbasezk-ip>:2181,<update-hbasezk-ip>:2181,<update-hbasezk-ip>:2181";
Connection hbase_conn;
Table tb;
int i = 0;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
org.apache.hadoop.conf.Configuration hbase_conf = HBaseConfiguration.create();
hbase_conf.set("hbase.zookeeper.quorum", hbase_zk);
hbase_conf.set("zookeeper.znode.parent", "/hbase-unsecure");
hbase_conn = ConnectionFactory.createConnection(hbase_conf);
tb = hbase_conn.getTable(TableName.valueOf("user_click_events"));
}
@Override
public void invoke(Tuple3<String,String,String> value, Context context) throws Exception {
byte[] rowKey = Bytes.toBytes(String.format("%010d", i++));
Put put = new Put(rowKey);
put.addColumn(Bytes.toBytes("user_info"), Bytes.toBytes("userName"), Bytes.toBytes(value.f0));
put.addColumn(Bytes.toBytes("user_info"), Bytes.toBytes("visitURL"), Bytes.toBytes(value.f1));
put.addColumn(Bytes.toBytes("user_info"), Bytes.toBytes("ts"), Bytes.toBytes(value.f2));
tb.put(put);
};
public void close() throws Exception {
if (null != tb) tb.close();
if (null != hbase_conn) hbase_conn.close();
}
}
principal:KafkaSinkToHbase
Escrevendo um Kafka Sink para o programa HBase
package contoso.example;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class KafkaSinkToHbase {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
String kafka_brokers = "10.0.0.38:9092,10.0.0.39:9092,10.0.0.40:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(kafka_brokers)
.setTopics("click_events")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> kafka = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source").setParallelism(1);
DataStream<Tuple3<String,String,String>> dataStream = kafka.map(line-> {
String[] fields = line.toString().replace("{","").replace("}","").
replace("\"","").split(",");
Tuple3<String, String,String> tuple3 = Tuple3.of(fields[0].substring(10),fields[1].substring(11),fields[2].substring(5));
return tuple3;
}).returns(Types.TUPLE(Types.STRING,Types.STRING,Types.STRING));
dataStream.addSink(new HBaseWriterSink());
env.execute("Kafka Sink To Hbase");
}
}
Submeter tarefa
Carregue o Jar de trabalho para a Conta de Armazenamento associada ao Cluster.

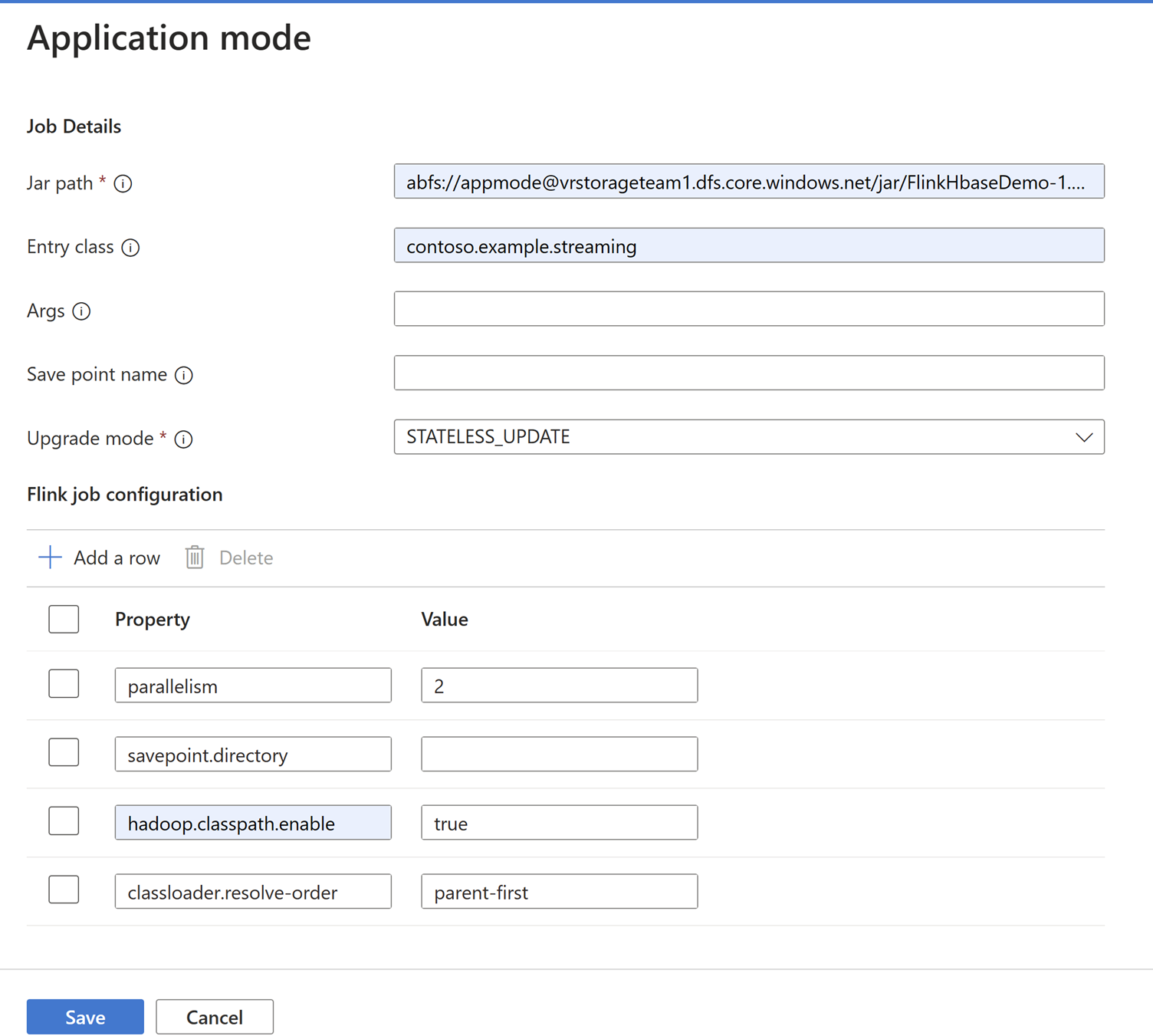
Adicione detalhes do trabalho na guia Modo de Aplicativo.
Nota
Certifique-se de adicionar
Hadoop.class.enableeclassloader.resolve-orderdefinir.Selecione Agregação de log de trabalho para armazenar logs no ABFS.
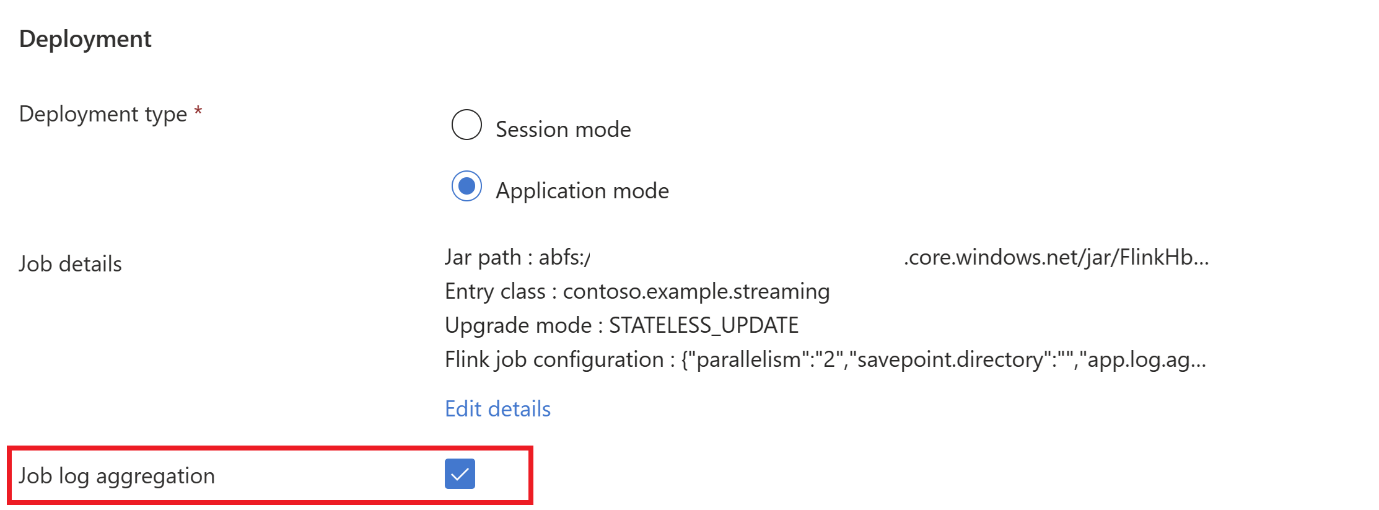
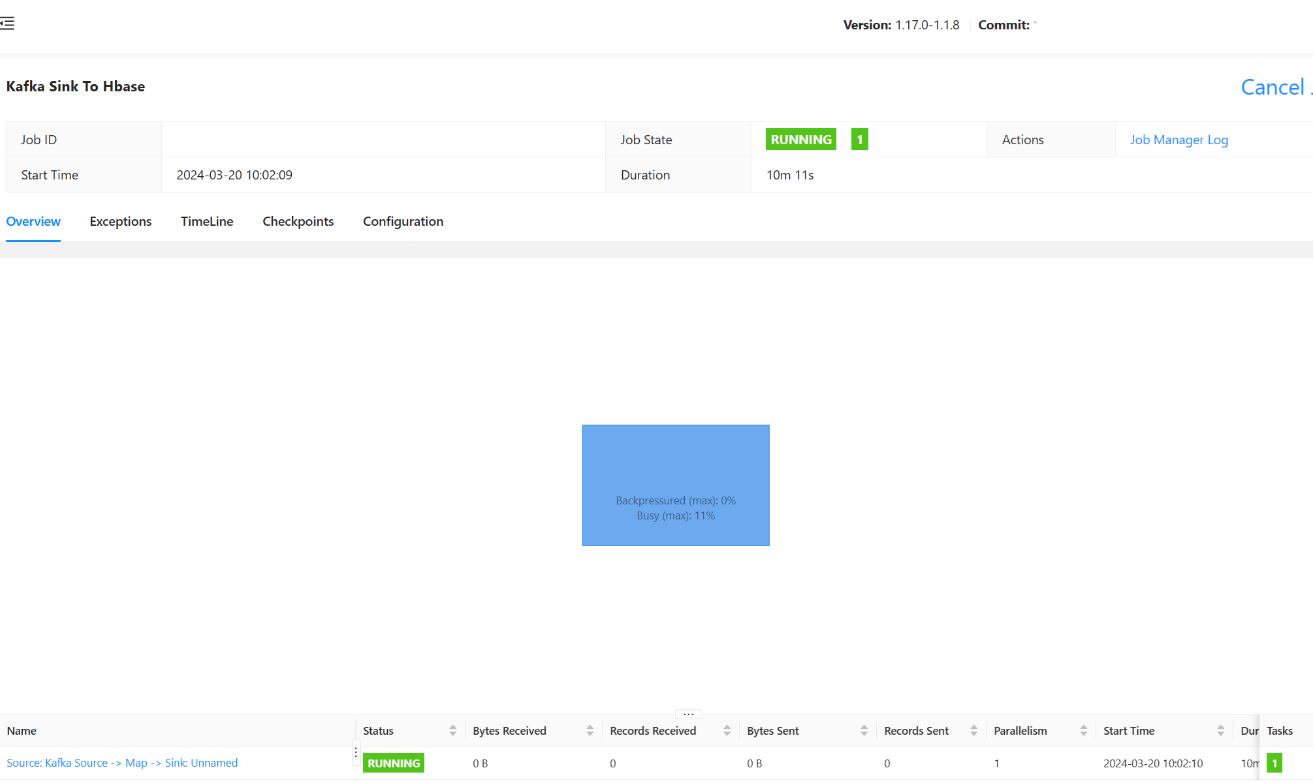
Envie o trabalho.
Você deve ser capaz de ver o status do trabalho enviado aqui.




Validar dados da tabela HBase
hbase:001:0> scan 'user_click_events',{LIMIT=>5}
ROW COLUMN+CELL
0000000000 column=user_info:ts, timestamp=2024-03-20T02:02:46.932, value=03/20/2024 02:02:43
0000000000 column=user_info:userName, timestamp=2024-03-20T02:02:46.932, value=Pick
0000000000 column=user_info:visitURL, timestamp=2024-03-20T02:02:46.932, value=
https://hadoop.apache.org
0000000001 column=user_info:ts, timestamp=2024-03-20T02:02:46.991, value=03/20/2024 02:02:43
0000000001 column=user_info:userName, timestamp=2024-03-20T02:02:46.991, value=Zheng Hu
0000000001 column=user_info:visitURL, timestamp=2024-03-20T02:02:46.991, value=/azure/hdinsight/hdinsight-overview
0000000002 column=user_info:ts, timestamp=2024-03-20T02:02:47.001, value=03/20/2024 02:02:43
0000000002 column=user_info:userName, timestamp=2024-03-20T02:02:47.001, value=Sean
0000000002 column=user_info:visitURL, timestamp=2024-03-20T02:02:47.001, value=
https://spark.apache.org
0000000003 column=user_info:ts, timestamp=2024-03-20T02:02:47.008, value=03/20/2024 02:02:43
0000000003 column=user_info:userName, timestamp=2024-03-20T02:02:47.008, value=Zheng Hu
0000000003 column=user_info:visitURL, timestamp=2024-03-20T02:02:47.008, value=
https://kafka.apache.org
0000000004 column=user_info:ts, timestamp=2024-03-20T02:02:47.017, value=03/20/2024 02:02:43
0000000004 column=user_info:userName, timestamp=2024-03-20T02:02:47.017, value=Chunck
0000000004 column=user_info:visitURL, timestamp=2024-03-20T02:02:47.017, value=
https://github.com
5 row(s)
Took 0.9269 seconds
Nota
- FlinkKafkaConsumer foi preterido e removido com Flink 1.17, use KafkaSource em vez disso.
- FlinkKafkaProducer é preterido e removido com Flink 1.15, use KafkaSink em vez disso.
Referências
- Conector Apache Kafka
- Baixar IntelliJ IDEA
- Apache, Apache Kafka, Kafka, Apache HBase, HBase, Apache Flink, Flink e nomes de projetos de código aberto associados são marcas comerciais da Apache Software Foundation (ASF).
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários