Usar o Apache Hive como uma ferramenta ETL (Extrair, Transformar e Carregar)
Normalmente, você precisa limpar e transformar os dados recebidos antes de carregá-los em um destino adequado para análises. As operações ETL (Extract, Transform and Load) são usadas para preparar dados e carregá-los em um destino de dados. O Apache Hive no HDInsight pode ler dados não estruturados, processar os dados conforme necessário e, em seguida, carregá-los em um data warehouse relacional para sistemas de suporte à decisão. Nesta abordagem, os dados são extraídos da fonte. Em seguida, armazenado em armazenamento adaptável, como blobs de Armazenamento do Azure ou Armazenamento do Azure Data Lake. Os dados são então transformados usando uma sequência de consultas do Hive. Em seguida, preparado dentro do Hive em preparação para o carregamento em massa no armazenamento de dados de destino.
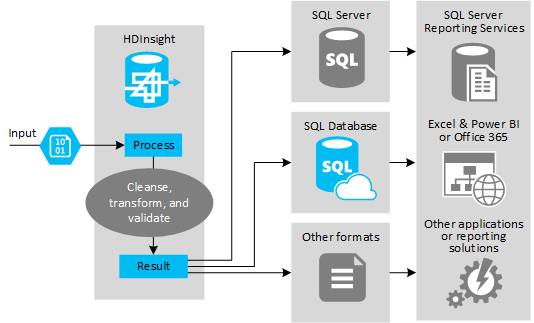
A figura a seguir mostra uma visão geral do caso de uso e do modelo para automação de ETL. Os dados de entrada são transformados para gerar a saída apropriada. Durante essa transformação, os dados mudam de forma, tipo de dados e até mesmo idioma. Os processos ETL podem converter Imperial em métrica, alterar fusos horários e melhorar a precisão para se alinhar adequadamente com os dados existentes no destino. Os processos de ETL também podem combinar novos dados com dados existentes para manter os relatórios atualizados ou para fornecer mais informações sobre os dados existentes. Aplicativos como ferramentas e serviços de relatórios podem consumir esses dados no formato desejado.
O Hadoop é normalmente usado em processos ETL que importam um grande número de arquivos de texto (como CSVs). Ou um número menor, mas que muda frequentemente de arquivos de texto, ou ambos. O Hive é uma ótima ferramenta para preparar os dados antes de carregá-los no destino dos dados. O Hive permite criar um esquema sobre o CSV e usar uma linguagem semelhante ao SQL para gerar programas MapReduce que interagem com os dados.
As etapas típicas para usar o Hive para fazer ETL são as seguintes:
Carregue dados no Armazenamento Azure Data Lake ou no Armazenamento de Blobs do Azure.
Crie um banco de dados do Repositório de Metadados (usando o Banco de Dados SQL do Azure) para uso pelo Hive no armazenamento de seus esquemas.
Crie um cluster HDInsight e conecte o armazenamento de dados.
Defina o esquema a ser aplicado em tempo de leitura sobre os dados no armazenamento de dados:
DROP TABLE IF EXISTS hvac; --create the hvac table on comma-separated sensor data stored in Azure Storage blobs CREATE EXTERNAL TABLE hvac(`date` STRING, time STRING, targettemp BIGINT, actualtemp BIGINT, system BIGINT, systemage BIGINT, buildingid BIGINT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION 'wasbs://{container}@{storageaccount}.blob.core.windows.net/HdiSamples/SensorSampleData/hvac/';Transforme os dados e carregue-os no destino. Há várias maneiras de usar o Hive durante a transformação e o carregamento:
- Consulte e prepare dados usando o Hive e salve-os como um CSV no Armazenamento Azure Data Lake ou no armazenamento de blobs do Azure. Em seguida, use uma ferramenta como o SQL Server Integration Services (SSIS) para adquirir esses CSVs e carregar os dados em um banco de dados relacional de destino, como o SQL Server.
- Consulte os dados diretamente do Excel ou C# usando o driver ODBC do Hive.
- Use o Apache Sqoop para ler os arquivos CSV simples preparados e carregá-los no banco de dados relacional de destino.
Normalmente, as fontes de dados são dados externos que podem ser correspondidos aos dados existentes no seu armazenamento de dados, por exemplo:
- Dados de redes sociais, ficheiros de registo, sensores e aplicações que geram ficheiros de dados.
- Conjuntos de dados obtidos de fornecedores de dados, tais como estatísticas meteorológicas ou números de vendas de fornecedores.
- Streaming de dados capturados, filtrados e processados através de uma ferramenta ou estrutura adequada.
Você pode usar o Hive para gerar dados para diferentes tipos de destinos, incluindo:
- Um banco de dados relacional, como o SQL Server ou o Banco de Dados SQL do Azure.
- Um armazém de dados, como o Azure Synapse Analytics.
- Excel.
- Armazenamento de tabela e blob do Azure.
- Aplicativos ou serviços que exigem que os dados sejam processados em formatos específicos ou como arquivos que contêm tipos específicos de estrutura de informações.
- Um Repositório de Documentos JSON como o Azure Cosmos DB.
O modelo ETL é normalmente usado quando você deseja:
* Carregue dados de fluxo ou grandes volumes de dados semiestruturados ou não estruturados de fontes externas para um banco de dados ou sistema de informação existente.
* Limpe, transforme e valide os dados antes de carregá-los, talvez usando mais de uma passagem de transformação pelo cluster.
* Gere relatórios e visualizações que são atualizados regularmente. Por exemplo, se o relatório demorar muito para ser gerado durante o dia, você poderá programá-lo para ser executado à noite. Para executar automaticamente uma consulta do Hive, você pode usar os Aplicativos Lógicos do Azure e o PowerShell.
Se o destino dos dados não for um banco de dados, você poderá gerar um arquivo no formato apropriado dentro da consulta, por exemplo, um CSV. Esse arquivo pode ser importado para o Excel ou Power BI.
Se você precisar executar várias operações nos dados como parte do processo de ETL, considere como gerenciá-las. Com operações controladas por um programa externo, em vez de como um fluxo de trabalho dentro da solução, decida se algumas operações podem ser executadas em paralelo. E para detetar quando cada trabalho é concluído. Usar um mecanismo de fluxo de trabalho como o Oozie no Hadoop pode ser mais fácil do que tentar orquestrar uma sequência de operações usando scripts externos ou programas personalizados.