Dimensionar automaticamente os clusters do Azure HDInsight
O recurso gratuito de dimensionamento automático do Azure HDInsight pode aumentar ou diminuir automaticamente o número de nós de trabalho em seu cluster com base nas métricas de cluster e na política de dimensionamento adotada pelos clientes. O recurso Autoscale funciona dimensionando o número de nós dentro de limites predefinidos com base em métricas de desempenho ou em um cronograma definido de operações de expansão e redução.
Como funciona
O recurso Autoscale usa dois tipos de condições para disparar eventos de dimensionamento: limites para várias métricas de desempenho de cluster (chamado dimensionamento baseado em carga) e gatilhos baseados em tempo (chamado dimensionamento baseado em agenda). O dimensionamento baseado em carga altera o número de nós no cluster, dentro de um intervalo definido, para garantir o uso ideal da CPU e minimizar o custo de execução. O dimensionamento baseado em cronograma altera o número de nós em seu cluster com base em um cronograma de operações de expansão e redução.
O vídeo a seguir fornece uma visão geral dos desafios, que o Autoscale resolve e como ele pode ajudá-lo a controlar os custos com o HDInsight.
Escolhendo o dimensionamento baseado em carga ou agendamento
O dimensionamento baseado em programação pode ser usado:
- Quando se espera que seus trabalhos sejam executados em horários fixos e por uma duração previsível ou Quando você prevê baixo uso durante horários específicos do dia. Por exemplo, ambientes de teste e desenvolvimento em horas pós-trabalho, trabalhos de fim de dia.
O dimensionamento baseado em carga pode ser usado:
- Quando os padrões de carga flutuam substancialmente e de forma imprevisível durante o dia. Por exemplo, processamento de dados de pedidos com flutuações aleatórias nos padrões de carga com base em vários fatores.
Métricas de cluster
O dimensionamento automático monitora continuamente o cluster e coleta as seguintes métricas:
| Métrico | Description |
|---|---|
| Total de CPU pendente | O número total de núcleos necessários para iniciar a execução de todos os contêineres pendentes. |
| Total de memória pendente | A memória total (em MB) necessária para iniciar a execução de todos os contêineres pendentes. |
| CPU livre total | A soma de todos os núcleos não utilizados nos nós de trabalho ativos. |
| Memória livre total | A soma da memória não utilizada (em MB) nos nós de trabalho ativos. |
| Memória usada por nó | A carga em um nó de trabalho. Um nó de trabalho no qual 10 GB de memória é usado é considerado sob mais carga do que um trabalhador com 2 GB de memória usada. |
| Número de Mestres de Aplicação por Nó | O número de contêineres do Mestre de Aplicativo (AM) em execução em um nó de trabalho. Um nó de trabalho que está hospedando dois contêineres AM é considerado mais importante do que um nó de trabalho que está hospedando contêineres AM zero. |
As métricas acima são verificadas a cada 60 segundos. O dimensionamento automático toma decisões de aumento e redução de escala com base nessas métricas.
Condições de escala baseadas em carga
Quando as seguintes condições são detetadas, o Autoscale emite uma solicitação de escala:
| Aumento vertical | Redução de escala |
|---|---|
| O total de CPU pendente é maior do que o total de CPU livre por mais de 3-5 minutos. | O total de CPU pendente é inferior ao total de CPU livre por mais de 3-5 minutos. |
| O total de memória pendente é maior do que o total de memória livre por mais de 3-5 minutos. | O total de memória pendente é menor do que o total de memória livre por mais de 3-5 minutos. |
Para aumentar a escala, o Autoscale emite uma solicitação de expansão para adicionar o número necessário de nós. A expansão é baseada em quantos novos nós de trabalho são necessários para atender aos requisitos atuais de CPU e memória.
Para redução de escala, o Autoscale emite uma solicitação para remover alguns nós. A redução de escala é baseada no número de contêineres do Mestre de Aplicativos (AM) por nó. E os requisitos atuais de CPU e memória. O serviço também deteta quais nós são candidatos para remoção com base na execução atual do trabalho. A operação de redução de escala primeiro descomissiona os nós e, em seguida, os remove do cluster.
Considerações de dimensionamento do Ambari DB para dimensionamento automático
Recomenda-se que o Ambari DB seja dimensionado corretamente para colher os benefícios do dimensionamento automático. Os clientes devem usar a camada de banco de dados correta e usar o banco de dados Ambari personalizado para clusters de tamanho grande. Por favor, leia as recomendações de dimensionamento de banco de dados e headnode.
Compatibilidade de cluster
Importante
A funcionalidade de Dimensionamento Automático do Azure HDInsight foi lançada para disponibilidade geral a 7 de novembro de 2019 para os clusters do Spark e do Hadoop com melhorias não disponíveis na versão de pré-visualização da funcionalidade. Se você criou um cluster do Spark antes de 7 de novembro de 2019 e deseja usar o recurso Dimensionamento automático no cluster, o caminho recomendado é criar um novo cluster e enable Autoscale no novo cluster.
O Autoscale for Interactive Query (LLAP) foi lançado para disponibilidade geral para HDI 4.0 em 27 de agosto de 2020. O dimensionamento automático só está disponível em clusters Spark, Hadoop e Interactive Query
A tabela a seguir descreve os tipos e versões de cluster compatíveis com o recurso Autoscale.
| Versão | Spark | Ramo de registo | Interactive Query | HBase | Kafka |
|---|---|---|---|---|---|
| HDInsight 4.0 sem ESP | Sim | Sim | Sim* | No | Não |
| HDInsight 4.0 com ESP | Sim | Sim | Sim* | No | Não |
| HDInsight 5.0 sem ESP | Sim | Sim | Sim* | No | Não |
| HDInsight 5.0 com ESP | Sim | Sim | Sim* | No | Não |
* Os clusters de consulta interativa só podem ser configurados para dimensionamento baseado em agenda, não baseado em carga.
Começar agora
Criar um cluster com Autoscaling baseado em carga
Para habilitar o recurso Autoscale com dimensionamento baseado em carga, conclua as seguintes etapas como parte do processo normal de criação de cluster:
Na guia Configuração + preço, marque a caixa de
Enable autoscaleseleção.Selecione Baseado em carga em Tipo de escala automática.
Insira os valores pretendidos para as seguintes propriedades:
- Número inicial de nós para o nó Trabalhador.
- Número mínimo de nós de trabalho.
- Número máximo de nós de trabalho.
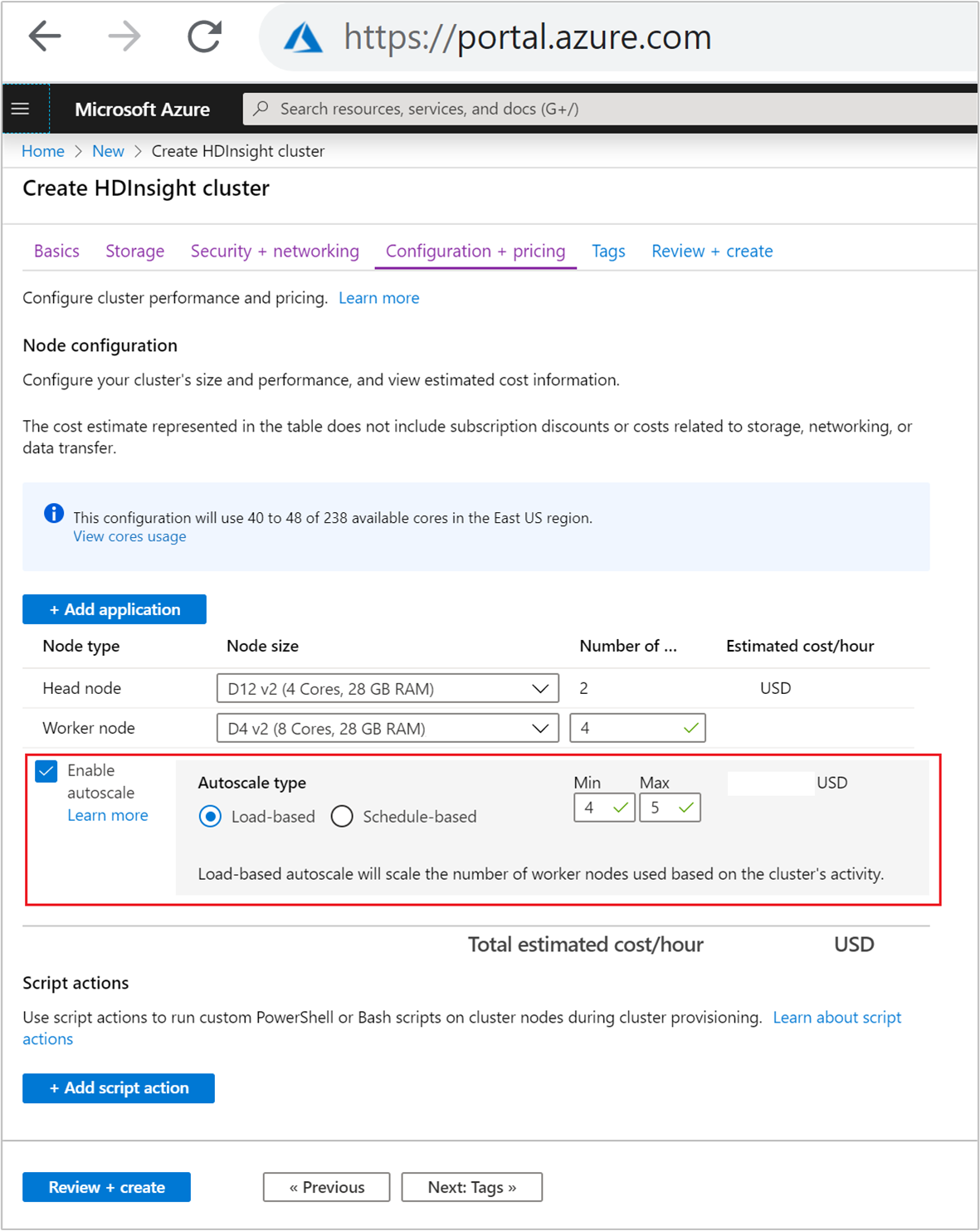
O número inicial de nós de trabalho deve situar-se entre o mínimo e o máximo, inclusive. Esse valor define o tamanho inicial do cluster quando ele é criado. O número mínimo de nós de trabalho deve ser definido como três ou mais. Dimensionar o cluster para menos de três nós pode resultar em que ele fique preso no modo de segurança devido à replicação insuficiente de arquivos. Para obter mais informações, consulte Ficar preso no modo de segurança.
Criar um cluster com dimensionamento automático baseado em agendamento
Para habilitar o recurso Autoscale com dimensionamento baseado em agendamento, conclua as seguintes etapas como parte do processo normal de criação de cluster:
Na guia Configuração + preço, marque a caixa de
Enable autoscaleseleção.Insira o Número de nós para o nó Trabalhador, que controla o limite para dimensionar o cluster.
Selecione a opção Baseado em programação em Tipo de escala automática.
Selecione Configurar para abrir a janela de configuração do Autodimension.
Selecione o seu fuso horário e, em seguida, clique em + Adicionar condição
Selecione os dias da semana aos quais a nova condição deve ser aplicada.
Edite a hora em que a condição deve entrar em vigor e o número de nós para os quais o cluster deve ser dimensionado.
Adicione mais condições, se necessário.
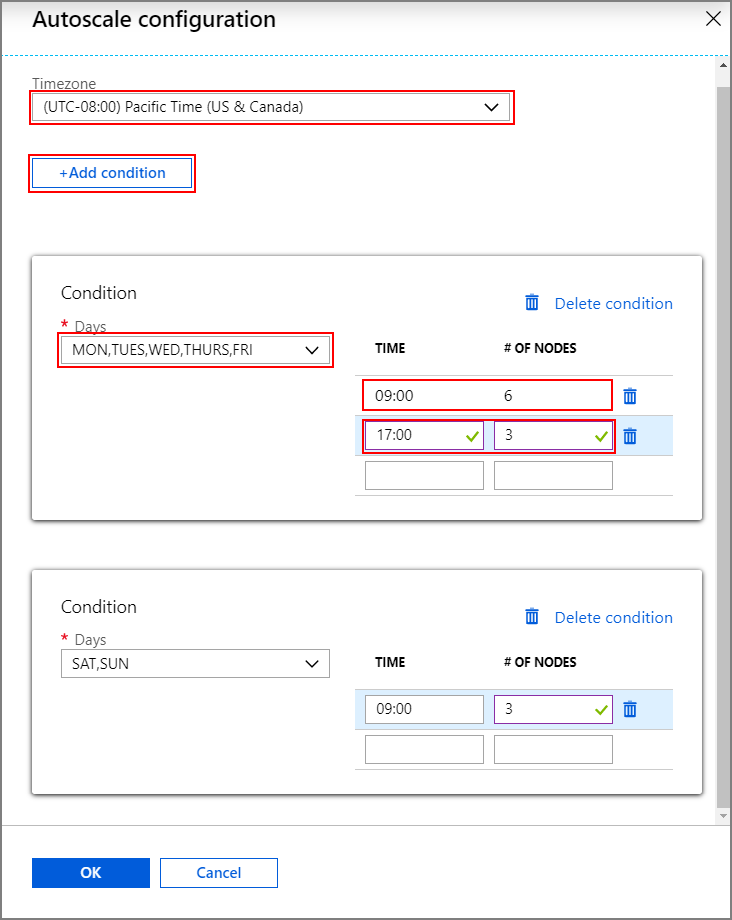
O número de nós deve estar entre 3 e o número máximo de nós de trabalho que você inseriu antes de adicionar condições.
Etapas finais de criação
Selecione o tipo de VM para nós de trabalho selecionando uma VM na lista suspensa em Tamanho do nó. Depois de escolher o tipo de VM para cada tipo de nó, você pode ver o intervalo de custo estimado para todo o cluster. Ajuste os tipos de VM para se adequarem ao seu orçamento.
A sua subscrição tem uma quota de capacidade para cada região. O número total de núcleos dos nós principais e o máximo de nós de trabalho não podem exceder a cota de capacidade. No entanto, esta quota é um limite suave; Você sempre pode criar um tíquete de suporte para aumentá-lo facilmente.
Nota
Se você exceder o limite total da cota principal, receberá uma mensagem de erro dizendo "o nó máximo excedeu os núcleos disponíveis nesta região, escolha outra região ou entre em contato com o suporte para aumentar a cota".
Para obter mais informações sobre a criação de clusters HDInsight usando o portal do Azure, consulte Criar clusters baseados em Linux no HDInsight usando o portal do Azure.
Criar um cluster com um modelo do Resource Manager
Dimensionamento automático baseado em carga
Você pode criar um cluster HDInsight com dimensionamento automático baseado em carga de um modelo do Azure Resource Manager, adicionando um autoscale nó à computeProfileworkernode>seção com as propriedades minInstanceCount e maxInstanceCount conforme mostrado no trecho json. Para obter um modelo completo do Resource Manager, consulte Modelo de início rápido: implantar o Spark Cluster com o dimensionamento automático baseado em carga habilitado.
{
"name": "workernode",
"targetInstanceCount": 4,
"autoscale": {
"capacity": {
"minInstanceCount": 3,
"maxInstanceCount": 10
}
},
"hardwareProfile": {
"vmSize": "Standard_D13_V2"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
},
"virtualNetworkProfile": null,
"scriptActions": []
}
Dimensionamento automático baseado em programação
Você pode criar um cluster HDInsight com dimensionamento automático baseado em agendamento de um modelo do Azure Resource Manager, adicionando um autoscale nó à computeProfile>workernode seção. O autoscale nó contém um recurrence que tem um timezone e schedule que descreve quando a alteração ocorre. Para obter um modelo completo do Resource Manager, consulte Implantar o Spark Cluster com o Autoscale baseado em agendamento habilitado.
{
"autoscale": {
"recurrence": {
"timeZone": "Pacific Standard Time",
"schedule": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"timeAndCapacity": {
"time": "11:00",
"minInstanceCount": 10,
"maxInstanceCount": 10
}
}
]
}
},
"name": "workernode",
"targetInstanceCount": 4
}
Habilitar e desabilitar o dimensionamento automático para um cluster em execução
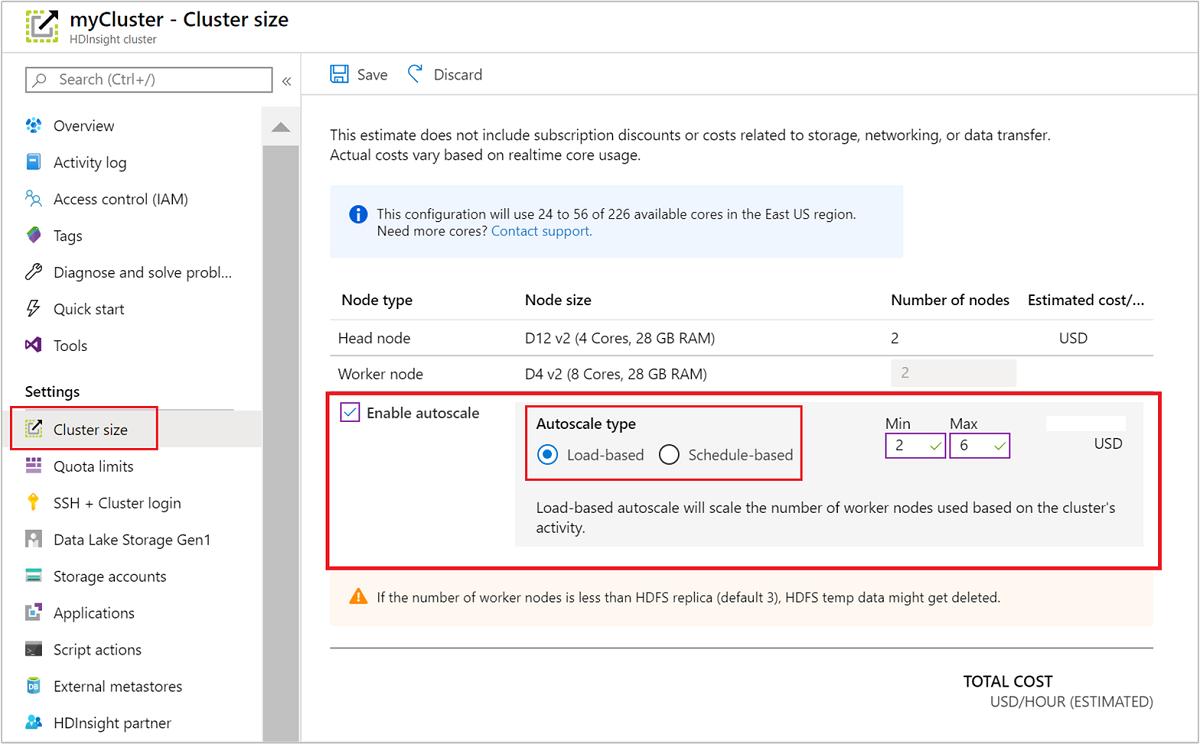
Utilizar o portal do Azure
Para habilitar o dimensionamento automático em um cluster em execução, selecione Tamanho do cluster em Configurações. Em seguida, selecione Enable autoscale. Selecione o tipo de dimensionamento automático desejado e insira as opções de dimensionamento baseado em carga ou agenda. Por último, selecione Guardar.
Utilizar a API REST
Para habilitar ou desabilitar o Autoscale em um cluster em execução usando a API REST, faça uma solicitação POST para o ponto de extremidade Autoscale:
https://management.azure.com/subscriptions/{subscription Id}/resourceGroups/{resourceGroup Name}/providers/Microsoft.HDInsight/clusters/{CLUSTERNAME}/roles/workernode/autoscale?api-version=2018-06-01-preview
Use os parâmetros apropriados na carga útil da solicitação. A seguinte carga útil json pode ser usada para enable Autoscale. Use a carga {autoscale: null} útil para desativar o Autoscale.
{ "autoscale": { "capacity": { "minInstanceCount": 3, "maxInstanceCount": 5 } } }
Consulte a seção anterior sobre como habilitar o dimensionamento automático baseado em carga para obter uma descrição completa de todos os parâmetros de carga útil. Não é recomendável desativar o serviço de dimensionamento automático com força em um cluster em execução.
Monitoramento de atividades de dimensionamento automático
Estado do cluster
O status do cluster listado no portal do Azure pode ajudá-lo a monitorar as atividades de dimensionamento automático.
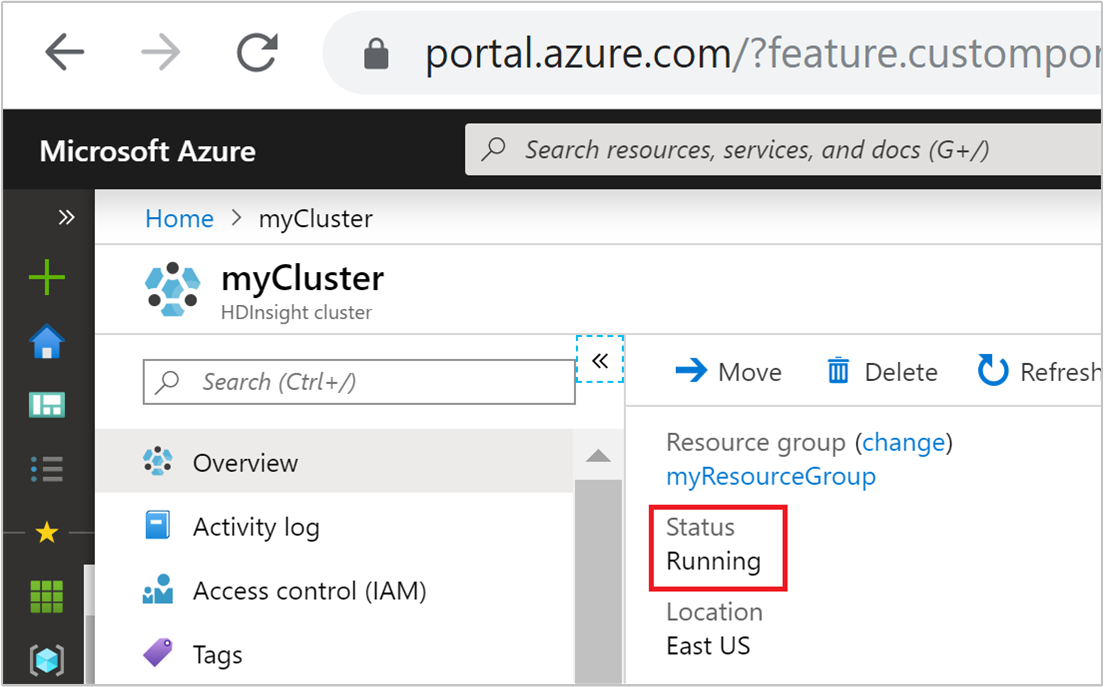
Todas as mensagens de status do cluster que você pode ver são explicadas na lista a seguir.
| Estado do cluster | Description |
|---|---|
| Em Execução | O cluster está funcionando normalmente. Todas as atividades anteriores do Autoscale foram concluídas com êxito. |
| Atualização | A configuração do cluster Autoscale está sendo atualizada. |
| Configuração do HDInsight | Uma operação de aumento ou redução de escala de cluster está em andamento. |
| Erro de atualização | O HDInsight enfrentou problemas durante a atualização de configuração do Autoscale. Os clientes podem optar por repetir a atualização ou desativar o dimensionamento automático. |
| Erro | Algo está errado com o cluster e ele não é utilizável. Exclua este cluster e crie um novo. |
Para exibir o número atual de nós no cluster, vá para o gráfico Tamanho do cluster na página Visão geral do cluster. Ou selecione Tamanho do cluster em Configurações.
Histórico de operações
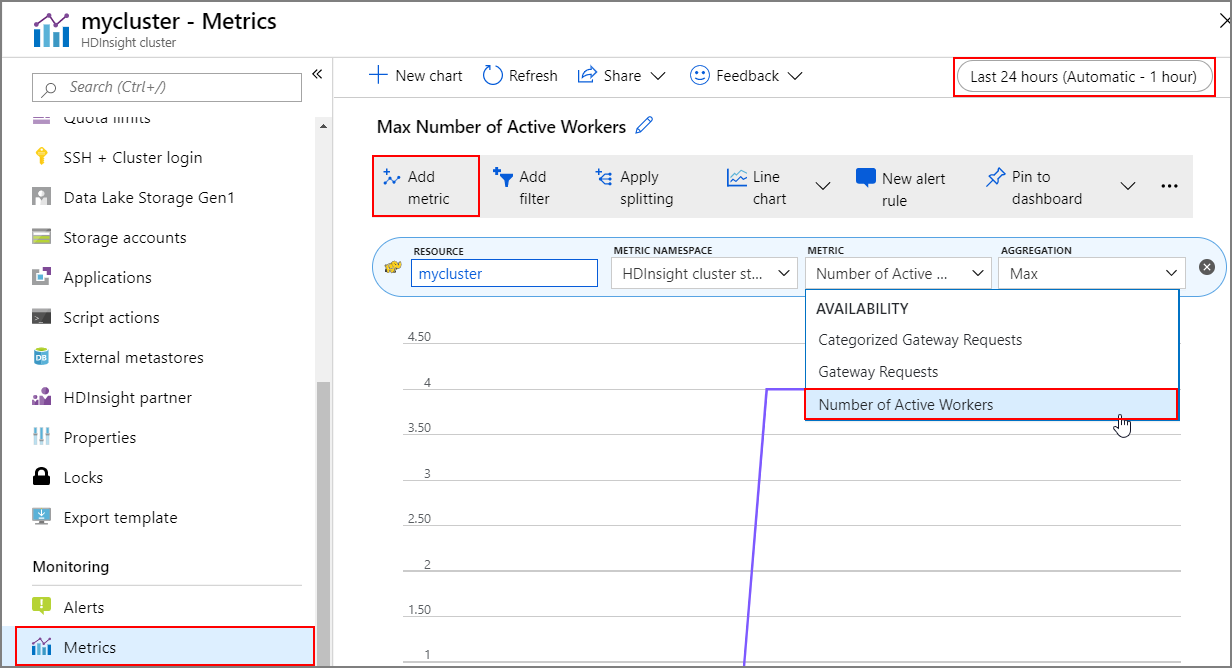
Você pode exibir o histórico de escalonamento e redução de escala do cluster como parte das métricas do cluster. Você também pode listar todas as ações de dimensionamento no último dia, semana ou outro período de tempo.
Selecione Métricas em Monitoramento. Em seguida, selecione Adicionar métrica e Número de Trabalhadores Ativos na caixa suspensa Métrica . Selecione o botão no canto superior direito para alterar o intervalo de tempo.
Melhores práticas
Considere a latência das operações de aumento e redução de escala
Pode levar de 10 a 20 minutos para que a operação de dimensionamento geral seja concluída. Ao configurar um cronograma personalizado, planeje-se para esse atraso. Por exemplo, se você precisar que o tamanho do cluster seja 20 às 9h00, defina o gatilho de agendamento para um horário anterior, como 8h30 ou anterior, para que a operação de dimensionamento seja concluída às 9h00.
Prepare-se para reduzir a escala
Durante o processo de redução do cluster, o Autoscale descomissiona os nós para atender ao tamanho de destino. No dimensionamento automático baseado em carga, se as tarefas estiverem sendo executadas nesses nós, o dimensionamento automático aguardará até que as tarefas sejam concluídas para clusters Spark e Hadoop. Como cada nó de trabalho também desempenha uma função no HDFS, os dados temporários são transferidos para os nós de trabalho restantes. Verifique se há espaço suficiente nos nós restantes para hospedar todos os dados temporários.
Nota
No caso de redução de escala automática baseada em programação, a desativação normal não é suportada. Isso pode causar falhas de trabalho durante uma operação de redução de escala, e é recomendável planejar agendas com base nos padrões de cronograma de trabalho previstos para incluir tempo suficiente para que os trabalhos em andamento sejam concluídos. Você pode definir os cronogramas observando a distribuição histórica dos tempos de conclusão para evitar falhas no trabalho.
Configurar o dimensionamento automático baseado em agendamento com base no padrão de uso
Você precisa entender o padrão de uso do cluster ao configurar o Autoscale baseado em agendamento. O painel do Grafana pode ajudá-lo a entender a carga de consulta e os slots de execução. Você pode obter os slots de executor disponíveis e os slots de executor total no painel.
Aqui está uma maneira de estimar quantos nós de trabalho necessários. Recomendamos dar outro buffer de 10% para lidar com a variação da carga de trabalho.
Número de slots de executor usados = Total de slots de executor – Total de slots de executor disponíveis.
Número de nós de trabalho necessários = Número de slots de executor realmente usados / (hive.llap.daemon.num.executors + hive.llap.daemon.task.scheduler.wait.queue.size).
*hive.llap.daemon.num.executors é configurável e o padrão é 4.
*hive.llap.daemon.task.scheduler.wait.queue.size é configurável e o padrão é 10.
Ações de Scripts Personalizados
As Ações de Script Personalizado são usadas principalmente para personalizar os nós (HeadNode / WorkerNodes) que permitem aos nossos clientes configurar determinadas bibliotecas e ferramentas, que estão sendo usadas por eles. Um caso de uso comum é que o(s) trabalho(s) executado(s) no cluster podem ter algumas dependências na biblioteca de terceiros, que pertence ao Cliente, e devem estar disponíveis em nós para que o trabalho seja bem-sucedido. Para o Autoscale, atualmente oferecemos suporte a ações de script personalizadas, que são persistentes, portanto, toda vez que os novos nós são adicionados ao cluster como parte da operação de expansão, essas ações de script persistentes são executadas e postam que os contêineres ou trabalhos seriam alocados neles. Embora ter ações de script personalizadas ajude a inicializar os novos nós, é aconselhável mantê-lo mínimo, pois isso aumentaria a latência geral e poderia causar impacto nos trabalhos agendados.
Esteja ciente do tamanho mínimo do cluster
Não reduza o cluster para menos de três nós. Dimensionar o cluster para menos de três nós pode resultar em que ele fique preso no modo de segurança devido à replicação insuficiente de arquivos. Para obter mais informações, consulte ficar preso no modo de segurança.
Serviços de Domínio do Microsoft Entra & Operações de Dimensionamento
Se você usar um cluster HDInsight com Pacote de Segurança Empresarial (ESP) que ingressou em um domínio gerenciado dos Serviços de Domínio Microsoft Entra, recomendamos limitar a carga nos Serviços de Domínio Microsoft Entra. Na sincronização de escopo de estruturas de diretório complexas, recomendamos evitar o impacto nas operações de dimensionamento.
Definir a configuração do Hive Total máximo de consultas simultâneas para o cenário de pico de uso
Os eventos de dimensionamento automático não alteram a configuração do Hive Total máximo de consultas simultâneas no Ambari. Isso significa que o Hive Server 2 Interactive Service pode lidar apenas com o número determinado de consultas simultâneas em qualquer momento, mesmo que a contagem de daemons do Interactive Query seja dimensionada para cima e para baixo com base na carga e na programação. A recomendação geral é definir essa configuração para o cenário de pico de uso para evitar a intervenção manual.
No entanto, você pode enfrentar uma falha de reinicialização do Hive Server 2 se houver apenas alguns nós de trabalho e o valor para o total máximo de consultas simultâneas estiver configurado muito alto. No mínimo, você precisa do número mínimo de nós de trabalho que podem acomodar o número determinado de (igual à configuração Total Máximo de Tez Ams Consultas Simultâneas).
Limitações
Contagem de Daemons de Consulta Interativa
Se houver clusters de Consulta Interativa habilitados para dimensionamento automático, um evento de aumento/redução de escala automática também aumentará ou reduzirá o número de daemons de Consulta Interativa para o número de nós de trabalho ativos. A mudança no número de daemons não é persistente na num_llap_nodes configuração no Ambari. Se os serviços do Hive forem reiniciados manualmente, o número de daemons de Consulta Interativa será redefinido de acordo com a configuração no Ambari.
Se o serviço de Consulta Interativa for reiniciado manualmente, você precisará alterar manualmente a num_llap_node configuração (o número de nós necessários para executar o daemon de Consulta Interativa do Hive) em Advanced hive-interactive-env para corresponder à contagem atual de nós de trabalho ativo. O Cluster de Consulta Interativo suporta apenas o dimensionamento automático baseado em agendamento.
Próximos passos
Leia sobre as diretrizes para dimensionar clusters manualmente em Diretrizes de dimensionamento.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários