Dimensionar manualmente clusters do Azure HDInsight
O HDInsight fornece elasticidade com opções para aumentar e reduzir o número de nós de trabalho em seus clusters. Essa elasticidade permite reduzir um cluster após o expediente ou nos fins de semana. E expandi-lo durante o pico de demandas de negócios.
Aumente a escala do cluster antes do processamento periódico em lote para que o cluster tenha recursos adequados. Depois que o processamento for concluído e o uso diminuir, reduza o cluster HDInsight para menos nós de trabalho.
Você pode dimensionar um cluster manualmente usando um dos seguintes métodos. Você também pode usar as opções de dimensionamento automático para aumentar e diminuir automaticamente a escala em resposta a determinadas métricas.
Nota
Apenas clusters com HDInsight versão 3.1.3 ou superior são suportados. Se não tiver certeza da versão do cluster, verifique a página Propriedades.
Utilitários para dimensionar clusters
A Microsoft fornece os seguintes utilitários para dimensionar clusters:
| Utilitário | Description |
|---|---|
| PowerShell Az | Set-AzHDInsightClusterSize -ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE |
| PowerShell AzureRM | Set-AzureRmHDInsightClusterSize -ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE |
| CLI do Azure | az hdinsight resize --resource-group RESOURCEGROUP --name CLUSTERNAME --workernode-count NEWSIZE |
| CLI clássica do Azure | azure hdinsight cluster resize CLUSTERNAME NEWSIZE |
| Portal do Azure | Abra o painel de cluster HDInsight, selecione Tamanho do cluster no menu esquerdo e, em seguida, no painel Tamanho do cluster, digite o número de nós de trabalho e selecione Salvar. |
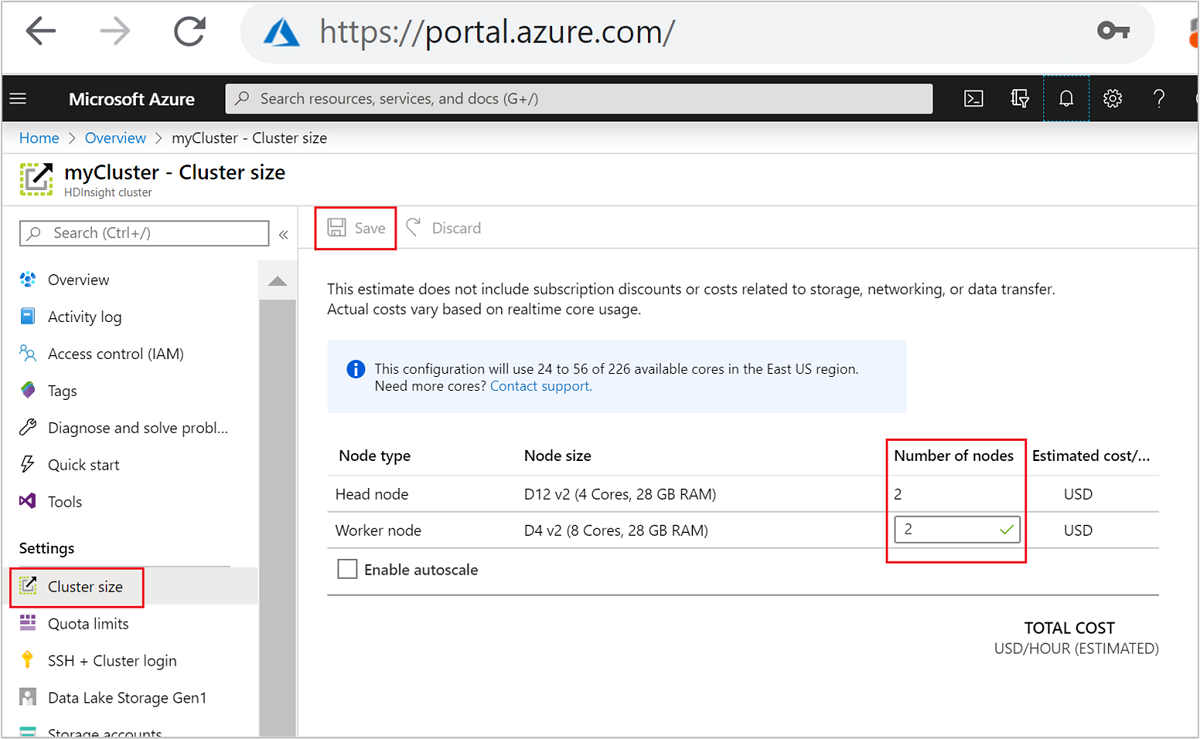
Usando qualquer um desses métodos, você pode dimensionar o cluster HDInsight para cima ou para baixo em poucos minutos.
Importante
- A CLI clássica do Azure foi preterida e só deve ser usada com o modelo de implantação clássico. Relativamente a todas as outras implementações, utilize a CLI do Azure.
- O módulo AzureRM do PowerShell foi preterido. Por favor, use o módulo Az sempre que possível.
Impacto das operações de dimensionamento
Quando você adiciona nós ao cluster HDInsight em execução (escalonamento), os trabalhos não são afetados. Novos trabalhos podem ser enviados com segurança enquanto o processo de dimensionamento está em execução. Se a operação de dimensionamento falhar, a falha deixará o cluster em um estado funcional.
Se você remover nós (reduzir a escala), os trabalhos pendentes ou em execução falharão quando a operação de dimensionamento for concluída. Essa falha ocorre devido à reinicialização de alguns dos serviços durante o processo de dimensionamento. O cluster pode ficar preso no modo de segurança durante uma operação de dimensionamento manual.
O impacto da alteração do número de nós de dados varia para cada tipo de cluster suportado pelo HDInsight:
Apache Hadoop
Você pode aumentar perfeitamente o número de nós de trabalho em um cluster Hadoop em execução sem afetar nenhum trabalho. Novos trabalhos também podem ser enviados enquanto a operação está em andamento. As falhas em uma operação de dimensionamento são tratadas normalmente. O cluster é sempre deixado em um estado funcional.
Quando um cluster Hadoop é reduzido com menos nós de dados, alguns serviços são reiniciados. Esse comportamento faz com que todos os trabalhos em execução e pendentes falhem na conclusão da operação de dimensionamento. No entanto, você pode reenviar os trabalhos assim que a operação for concluída.
Apache HBase
Você pode adicionar ou remover facilmente nós ao cluster HBase enquanto ele está em execução. Os Servidores Regionais são automaticamente balanceados em poucos minutos após a conclusão da operação de dimensionamento. No entanto, você pode equilibrar manualmente os servidores regionais. Faça login no nó principal do cluster e execute os seguintes comandos:
pushd %HBASE_HOME%\bin hbase shell balancerPara obter mais informações sobre como usar o shell do HBase, consulte Introdução a um exemplo do Apache HBase no HDInsight.
Nota
Não é aplicável aos clusters de Kafka.
LLAP do Apache Hive
Depois de dimensionar para
Nnós de trabalho, o HDInsight define automaticamente as seguintes configurações e reinicia o Hive.- Total máximo de consultas simultâneas:
hive.server2.tez.sessions.per.default.queue = min(N, 32) - Número de nós usados pelo LLAP do Hive:
num_llap_nodes = N - Número de nó(s) para executar o daemon LLAP do Hive:
num_llap_nodes_for_llap_daemons = N
- Total máximo de consultas simultâneas:
Como reduzir um cluster com segurança
Reduzir a escala de um cluster com trabalhos em execução
Para evitar que seus trabalhos em execução falhem durante uma operação de redução de escala, você pode tentar três coisas:
- Aguarde a conclusão dos trabalhos antes de reduzir o cluster.
- Termine manualmente os trabalhos.
- Reenvie os trabalhos após a conclusão da operação de dimensionamento.
Para ver uma lista de trabalhos pendentes e em execução, você pode usar a interface do usuário do YARN Resource Manager, seguindo estas etapas:
No portal do Azure, selecione o seu cluster. O cluster é aberto numa página nova do portal.
Na visualização principal, navegue até Painéis de>cluster Ambari home. Insira suas credenciais de cluster.
Na interface do usuário do Ambari, selecione YARN na lista de serviços no menu à esquerda.
Na página YARN, selecione Links Rápidos, passe o mouse sobre o nó principal ativo e, em seguida, selecione Interface do usuário do Gerenciador de Recursos.
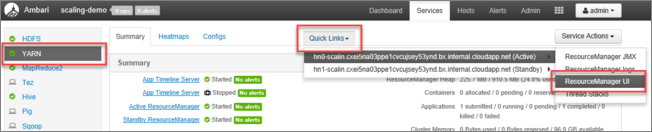
Você pode acessar diretamente a interface do usuário do Gerenciador de Recursos com https://<HDInsightClusterName>.azurehdinsight.net/yarnui/hn/clustero .
Você verá uma lista de trabalhos, juntamente com seu estado atual. Na captura de tela, há um trabalho em execução no momento:
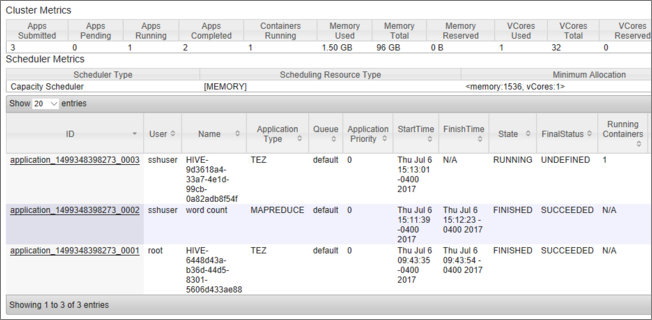
Para matar manualmente esse aplicativo em execução, execute o seguinte comando do shell SSH:
yarn application -kill <application_id>
Por exemplo:
yarn application -kill "application_1499348398273_0003"
Bloqueado no modo seguro
Quando você reduz a escala de um cluster, o HDInsight usa interfaces de gerenciamento do Apache Ambari para primeiro desativar os nós de trabalho extras. Os nós replicam seus blocos HDFS para outros nós de trabalho online. Depois disso, o HDInsight reduz o cluster com segurança. O HDFS entra em modo de segurança durante a operação de dimensionamento. O HDFS deve sair assim que o dimensionamento for concluído. Em alguns casos, no entanto, o HDFS fica preso no modo de segurança durante uma operação de dimensionamento devido à sub-replicação do bloco de arquivos.
Por padrão, o HDFS é configurado com uma dfs.replication configuração de 1, que controla quantas cópias de cada bloco de arquivo estão disponíveis. Cada cópia de um bloco de arquivo é armazenada em um nó diferente do cluster.
Quando o número esperado de cópias de bloco não está disponível, o HDFS entra no modo de segurança e o Ambari gera alertas. O HDFS pode entrar no modo de segurança para uma operação de dimensionamento. O cluster pode ficar preso no modo de segurança se o número necessário de nós não for detetado para replicação.
Exemplos de erros quando o modo de segurança está ativado
org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /tmp/hive/hive/819c215c-6d87-4311-97c8-4f0b9d2adcf0. Name node is in safe mode.
org.apache.http.conn.HttpHostConnectException: Connect to active-headnode-name.servername.internal.cloudapp.net:10001 [active-headnode-name.servername. internal.cloudapp.net/1.1.1.1] failed: Connection refused
Você pode revisar os logs do nó de nome da /var/log/hadoop/hdfs/ pasta, perto da hora em que o cluster foi dimensionado, para ver quando ele entrou no modo de segurança. Os arquivos de log são nomeados Hadoop-hdfs-namenode-<active-headnode-name>.*.
A causa raiz foi que o Hive depende de arquivos temporários no HDFS durante a execução de consultas. Quando o HDFS entra no modo de segurança, o Hive não pode executar consultas porque não pode gravar no HDFS. Os arquivos temporários no HDFS estão localizados na unidade local montada nas VMs individuais do nó de trabalho. Os arquivos são replicados entre outros nós de trabalho em três réplicas, no mínimo.
Como evitar que o HDInsight fique preso no modo de segurança
Há várias maneiras de evitar que o HDInsight seja deixado no modo de segurança:
- Pare todos os trabalhos do Hive antes de reduzir o HDInsight. Como alternativa, agende o processo de redução de escala para evitar conflitos com a execução de trabalhos do Hive.
- Limpe manualmente os arquivos do diretório de rascunho
tmpdo Hive no HDFS antes de reduzir a escala. - Reduza apenas o HDInsight para três nós de trabalho, no mínimo. Evite ir tão baixo quanto um nó de trabalho.
- Execute o comando para sair do modo de segurança, se necessário.
As seções a seguir descrevem essas opções.
Parar todos os trabalhos do Hive
Pare todos os trabalhos do Hive antes de reduzir para um nó de trabalho. Se a carga de trabalho estiver agendada, execute a redução da escala após a conclusão do trabalho do Hive.
Parar os trabalhos do Hive antes de dimensionar, ajuda a minimizar o número de arquivos de trabalho na pasta tmp (se houver).
Limpe manualmente os arquivos de rascunho do Hive
Se o Hive tiver deixado para trás arquivos temporários, você poderá limpá-los manualmente antes de reduzir a escala para evitar o modo de segurança.
Verifique qual local está sendo usado para arquivos temporários do Hive examinando a
hive.exec.scratchdirpropriedade de configuração. Este parâmetro é definido em/etc/hive/conf/hive-site.xml:<property> <name>hive.exec.scratchdir</name> <value>hdfs://mycluster/tmp/hive</value> </property>Pare os serviços do Hive e certifique-se de que todas as consultas e trabalhos foram concluídos.
Liste o conteúdo do diretório scratch encontrado acima,
hdfs://mycluster/tmp/hive/para ver se ele contém algum arquivo:hadoop fs -ls -R hdfs://mycluster/tmp/hive/hiveAqui está uma saída de exemplo quando existem arquivos:
sshuser@scalin:~$ hadoop fs -ls -R hdfs://mycluster/tmp/hive/hive drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/_tmp_space.db -rw-r--r-- 3 hive hdfs 27 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.info -rw-r--r-- 3 hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.lck drwx------ - hive hdfs 0 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699 -rw-r--r-- 3 hive hdfs 26 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699/inuse.infoSe você sabe que o Hive terminou com esses arquivos, você pode removê-los. Certifique-se de que o Hive não tenha consultas em execução procurando na página da interface do usuário do Yarn Resource Manager.
Exemplo de linha de comando para remover arquivos do HDFS:
hadoop fs -rm -r -skipTrash hdfs://mycluster/tmp/hive/
Dimensionar o HDInsight para três ou mais nós de trabalho
Se os clusters ficarem presos no modo de segurança com freqüência ao reduzir para menos de três nós de trabalho, mantenha pelo menos três nós de trabalho.
Ter três nós de trabalho é mais caro do que reduzir para apenas um nó de trabalho. No entanto, essa ação impede que o cluster fique preso no modo de segurança.
Dimensione o HDInsight para um nó de trabalho
Mesmo quando o cluster é reduzido para um nó, o nó de trabalho 0 ainda sobrevive. O nó de trabalhador 0 nunca pode ser desativado.
Execute o comando para sair do modo de segurança
A opção final é executar o comando leave safe mode. Se o HDFS entrou no modo de segurança devido à sub-replicação do arquivo Hive, execute o seguinte comando para sair do modo de segurança:
hdfs dfsadmin -D 'fs.default.name=hdfs://mycluster/' -safemode leave
Reduzir a escala de um cluster Apache HBase
Os servidores de região são balanceados automaticamente em poucos minutos após a conclusão de uma operação de dimensionamento. Para equilibrar manualmente os servidores de região, conclua as seguintes etapas:
Conecte-se ao cluster HDInsight usando SSH. Para obter mais informações, veja Use SSH with HDInsight (Utilizar SSH com o HDInsight).
Inicie o shell do HBase:
hbase shellUse o seguinte comando para equilibrar manualmente os servidores de região:
balancer
Próximos passos
Para obter informações específicas sobre como dimensionar o cluster HDInsight, consulte:
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários