Monitorizar o desempenho do cluster no Azure HDInsight
Monitorar a integridade e o desempenho de um cluster HDInsight é essencial para manter o desempenho ideal e a utilização de recursos. O monitoramento também pode ajudá-lo a detetar e resolver erros de configuração de cluster e problemas de código do usuário.
As seções a seguir descrevem como monitorar e otimizar a carga em seus clusters, filas do Apache Hadoop YARN e detetar problemas de limitação de armazenamento.
Monitorar a carga do cluster
Os clusters Hadoop podem oferecer o desempenho ideal quando a carga no cluster é distribuída uniformemente em todos os nós. Isso permite que as tarefas de processamento sejam executadas sem serem restringidas por recursos de RAM, CPU ou disco em nós individuais.
Para obter uma visão de alto nível dos nós do cluster e seu carregamento, entre na interface do usuário da Web do Ambari e selecione a guia Hosts. Os seus anfitriões estão listados pelos seus nomes de domínio totalmente qualificados. O status operacional de cada host é mostrado por um indicador de integridade colorido:
| Cor | Description |
|---|---|
| Vermelho | Pelo menos um componente mestre no host está inativo. Passe o cursor para ver uma dica de ferramenta que lista os componentes afetados. |
| Orange | Pelo menos um componente secundário no host está inativo. Passe o cursor para ver uma dica de ferramenta que lista os componentes afetados. |
| Yellow | Ambari Server não recebeu um batimento cardíaco do anfitrião por mais de 3 minutos. |
| Verde | Estado normal de execução. |
Você também verá colunas mostrando o número de núcleos e a quantidade de RAM para cada host, bem como o uso do disco e a média de carga.
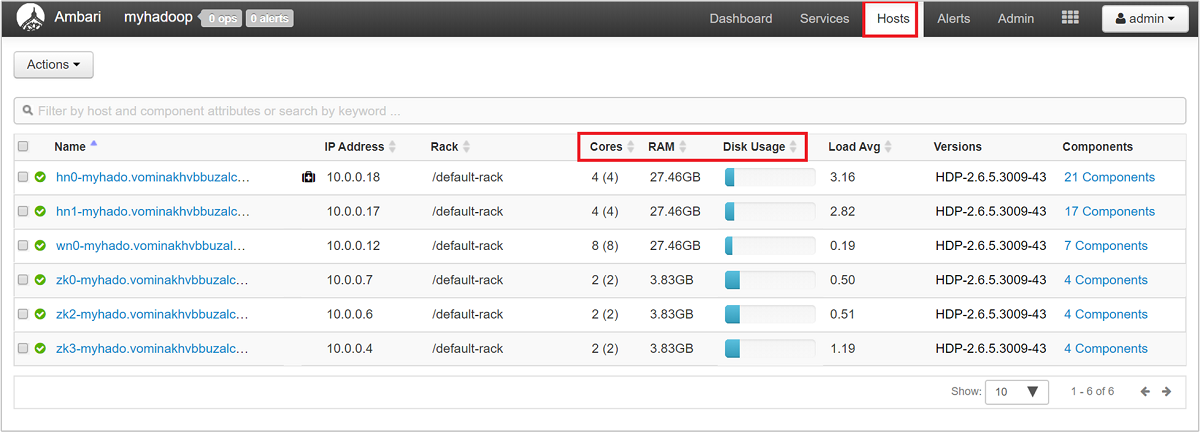
Selecione qualquer um dos nomes de host para obter uma visão detalhada dos componentes em execução nesse host e suas métricas. As métricas são mostradas como uma linha do tempo selecionável de uso da CPU, carga, uso de disco, uso de memória, uso de rede e números de processos.
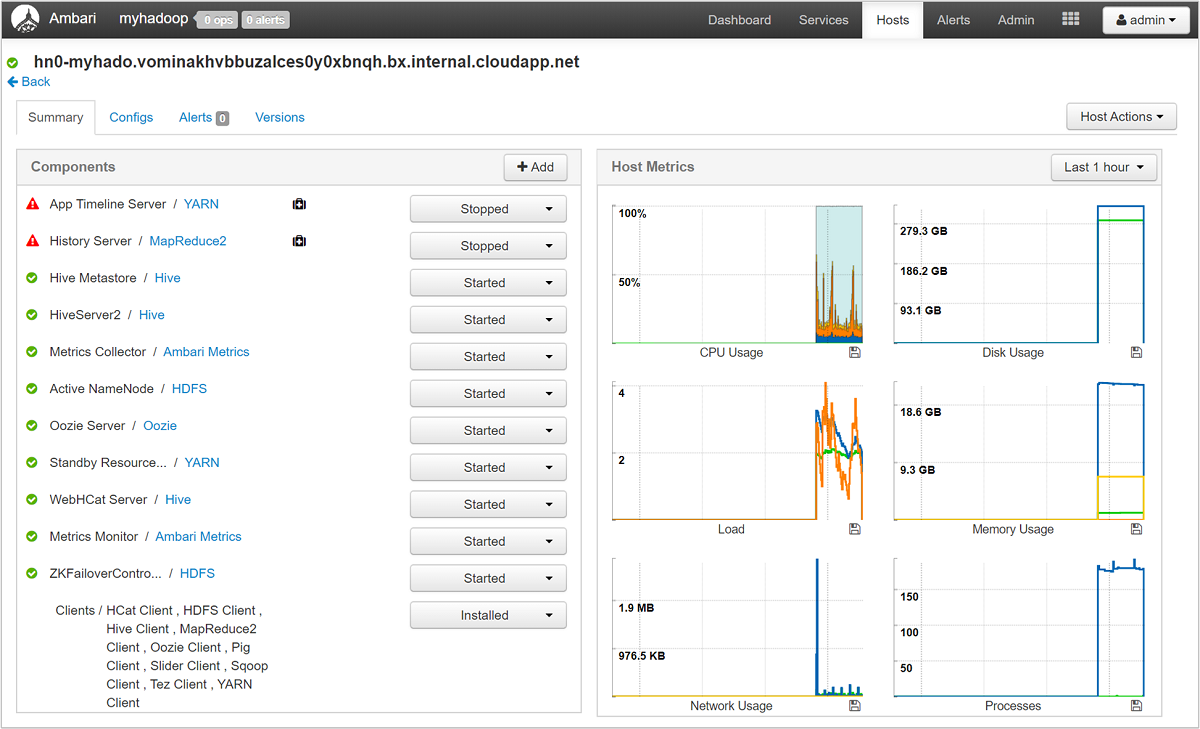
Consulte Gerenciar clusters HDInsight usando a interface do usuário da Web do Apache Ambari para obter detalhes sobre como definir alertas e visualizar métricas.
Configuração da fila YARN
O Hadoop tem vários serviços em execução em sua plataforma distribuída. O YARN (Yet Another Resource Negotiator) coordena esses serviços e aloca recursos de cluster para garantir que qualquer carga seja distribuída uniformemente pelo cluster.
O YARN divide as duas responsabilidades do JobTracker, gerenciamento de recursos e agendamento/monitoramento de tarefas, em dois daemons: um Resource Manager global e um ApplicationMaster (AM) por aplicativo.
O Resource Manager é um agendador puro e arbitra exclusivamente os recursos disponíveis entre todos os aplicativos concorrentes. O Resource Manager garante que todos os recursos estejam sempre em uso, otimizando para várias constantes, como SLAs, garantias de capacidade e assim por diante. O ApplicationMaster negocia recursos do Resource Manager e trabalha com o(s) NodeManager(s) para executar e monitorar os contêineres e seu consumo de recursos.
Quando vários locatários compartilham um cluster grande, há concorrência pelos recursos do cluster. O CapacityScheduler é um agendador conectável que auxilia no compartilhamento de recursos enfileirando solicitações. O CapacityScheduler também oferece suporte a filas hierárquicas para garantir que os recursos sejam compartilhados entre as subfilas de uma organização, antes que as filas de outros aplicativos tenham permissão para usar recursos gratuitos.
O YARN nos permite alocar recursos para essas filas e mostra se todos os recursos disponíveis estão atribuídos. Para exibir informações sobre suas filas, entre na interface do usuário da Web do Ambari e selecione Gerenciador de filas do YARN no menu superior.
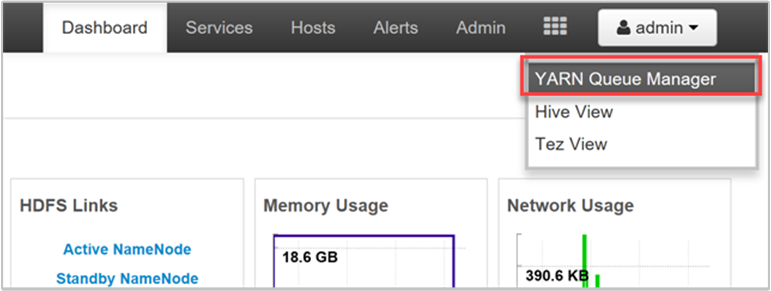
A página Gerenciador de filas do YARN mostra uma lista de suas filas à esquerda, juntamente com a porcentagem de capacidade atribuída a cada uma.
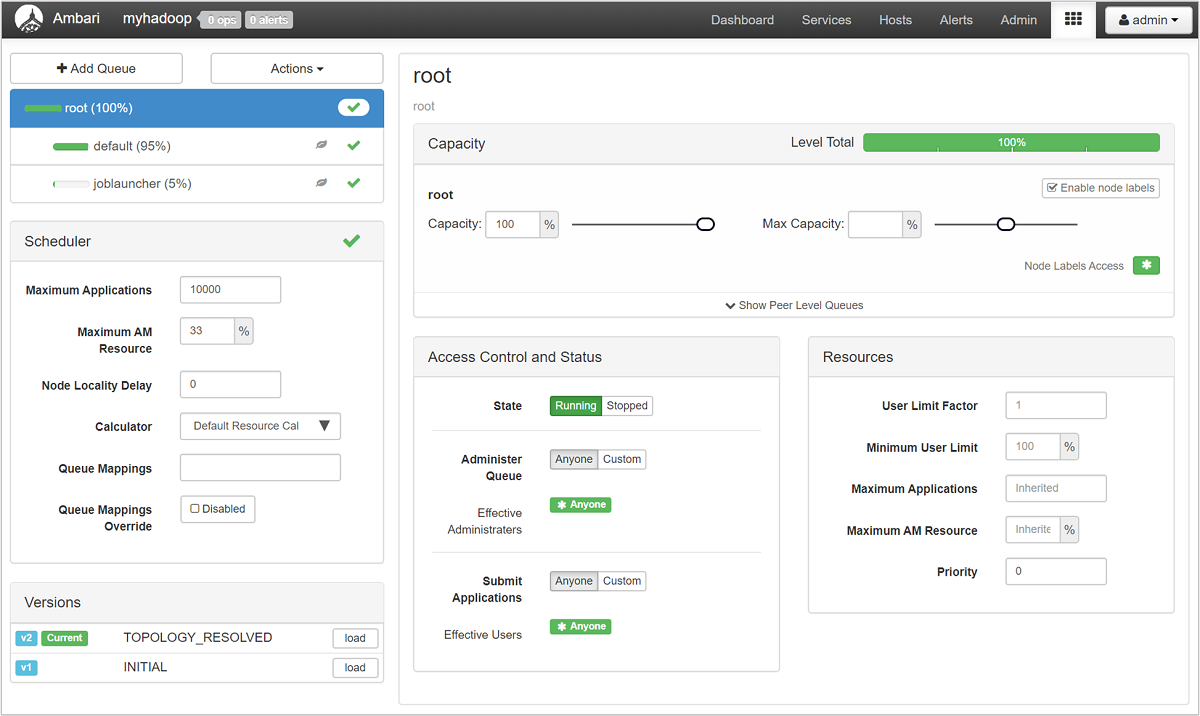
Para uma visão mais detalhada de suas filas, no painel Ambari, selecione o serviço YARN na lista à esquerda. Em seguida, no menu suspenso Links Rápidos , selecione Interface do usuário do Gerenciador de Recursos abaixo do nó ativo.
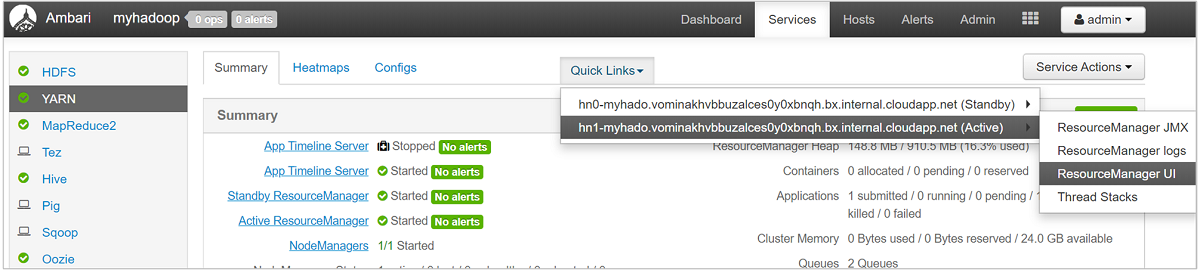
Na interface do usuário do Gerenciador de Recursos, selecione Agendador no menu à esquerda. Você verá uma lista de suas filas abaixo de Filas de aplicativos. Aqui você pode ver a capacidade usada para cada uma de suas filas, quão bem os trabalhos estão distribuídos entre eles e se algum trabalho está com restrição de recursos.
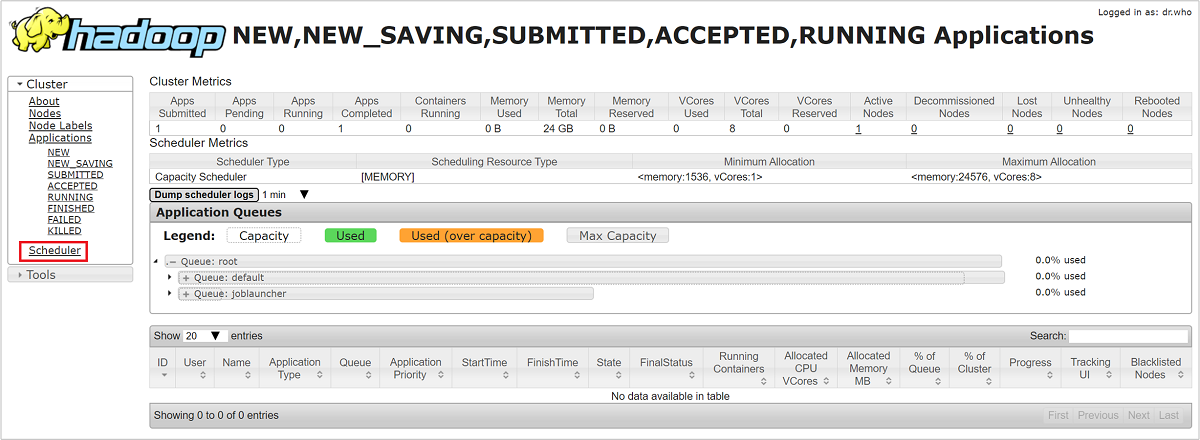
Limitação de armazenamento
O gargalo de desempenho de um cluster pode ocorrer no nível de armazenamento. Esse tipo de gargalo geralmente se deve ao bloqueio de operações de entrada/saída (E/S), que acontecem quando suas tarefas em execução enviam mais E/S do que o serviço de armazenamento pode lidar. Esse bloqueio cria uma fila de solicitações de E/S aguardando para serem processadas até que as E/S atuais sejam processadas. Os bloqueios se devem à limitação de armazenamento, que não é um limite físico, mas sim um limite imposto pelo serviço de armazenamento por um contrato de nível de serviço (SLA). Esse limite garante que nenhum cliente ou locatário possa monopolizar o serviço. O SLA limita o número de IOs por segundo (IOPS) para o Armazenamento do Azure - para obter detalhes, consulte Metas de escalabilidade e desempenho para contas de armazenamento padrão.
Se você estiver usando o Armazenamento do Azure, para obter informações sobre como monitorar problemas relacionados ao armazenamento, incluindo limitação, consulte Monitorar, diagnosticar e solucionar problemas do Armazenamento do Microsoft Azure.
Se o armazenamento de suporte do cluster for o Azure Data Lake Storage (ADLS), sua limitação provavelmente se deve aos limites de largura de banda. A limitação, neste caso, pode ser identificada pela observação de erros de limitação nos logs de tarefas. Para ADLS, consulte a seção de limitação para o serviço apropriado nestes artigos:
- Diretrizes de ajuste de desempenho para o Apache Hive no HDInsight e no Armazenamento Azure Data Lake
- Diretrizes de ajuste de desempenho para MapReduce no HDInsight e no Armazenamento Azure Data Lake
Solucionar problemas de desempenho lento do nó
Em alguns casos, poderá ocorrer lentidão devido a espaço em disco reduzido no cluster. Investigue com estas etapas:
Use o comando ssh para se conectar a cada um dos nós.
Verifique o uso do disco executando um dos seguintes comandos:
df -h du -h --max-depth=1 / | sort -hRevise a saída e verifique a presença de arquivos grandes na
mntpasta ou em outras pastas. Normalmente, asusercachepastas , eappcache(mnt/resource/hadoop/yarn/local/usercache/hive/appcache/) contêm arquivos grandes.Se houver arquivos grandes, um trabalho atual está causando o crescimento do arquivo ou um trabalho anterior com falha pode ter contribuído para esse problema. Para verificar se este comportamento é causado por uma tarefa atual, execute o seguinte comando:
sudo du -h --max-depth=1 /mnt/resource/hadoop/yarn/local/usercache/hive/appcache/Se este comando indicar uma tarefa específica, poderá escolher terminar a tarefa ao utilizar um comando semelhante ao seguinte:
yarn application -kill -applicationId <application_id>Substitua
application_idpelo ID do aplicativo. Se não forem indicadas tarefas especificas, avance para o passo seguinte.Depois que o comando acima for concluído, ou se nenhum trabalho específico for indicado, exclua os arquivos grandes identificados executando um comando semelhante ao seguinte:
rm -rf filecache usercache
Para obter mais informações sobre problemas de espaço em disco, consulte Sem espaço em disco.
Nota
Se você tiver arquivos grandes que deseja manter, mas está contribuindo para o problema de pouco espaço em disco, será necessário aumentar a escala do cluster HDInsight e reiniciar os serviços. Depois de concluir este procedimento e aguardar alguns minutos, você notará que o armazenamento é liberado e o desempenho normal do nó é restaurado.
Próximos passos
Visite os links a seguir para obter mais informações sobre como solucionar problemas e monitorar seus clusters:
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários