Resolver problemas de um trabalho lento ou com falhas num cluster HDInsight
Se um aplicativo que processa dados em um cluster HDInsight estiver sendo executado lentamente ou falhar com um código de erro, você terá várias opções de solução de problemas. Se os trabalhos estiverem demorando mais para serem executados do que o esperado ou se você estiver vendo tempos de resposta lentos em geral, pode haver falhas a montante do cluster, como os serviços nos quais o cluster é executado. No entanto, a causa mais comum dessas desacelerações é o escalonamento insuficiente. Ao criar um novo cluster HDInsight, selecione os tamanhos de máquina virtual apropriados.
Para diagnosticar um cluster lento ou com falha, reúna informações sobre todos os aspetos do ambiente, como Serviços do Azure associados, configuração de cluster e informações de execução de trabalho. Um diagnóstico útil é tentar reproduzir o estado de erro em outro cluster.
- Passo 1: Reúna dados sobre o problema.
- Etapa 2: Validar o ambiente de cluster HDInsight.
- Etapa 3: Visualize a integridade do cluster.
- Etapa 4: Revise a pilha e as versões do ambiente.
- Etapa 5: Examine os arquivos de log do cluster.
- Passo 6: Verifique as definições de configuração.
- Etapa 7: Reproduzir a falha em um cluster diferente.
Etapa 1: coletar dados sobre o problema
O HDInsight fornece muitas ferramentas que você pode usar para identificar e solucionar problemas com clusters. As etapas a seguir guiam você por essas ferramentas e fornecem sugestões para identificar o problema.
Identificar o problema
Para ajudar a identificar o problema, considere as seguintes perguntas:
- O que eu esperava que acontecesse? O que aconteceu em vez disso?
- Quanto tempo demorou a decorrer o processo? Quanto tempo deveria ter corrido?
- As minhas tarefas são sempre executadas lentamente neste cluster? Eles rodaram mais rápido em um cluster diferente?
- Quando é que este problema ocorreu pela primeira vez? Quantas vezes isso aconteceu desde então?
- Mudou alguma coisa na minha configuração de cluster?
Detalhes do cluster
Informações importantes sobre clusters incluem:
- Nome do cluster.
- Região do cluster - verifique se há interrupções na região.
- Tipo e versão do cluster HDInsight.
- Tipo e número de instâncias do HDInsight especificadas para os nós principal e de trabalho.
O portal do Azure pode fornecer estas informações:

Você também pode usar a CLI do Azure:
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
Outra opção é usar o PowerShell. Para obter mais informações, consulte Gerenciar clusters Apache Hadoop no HDInsight com o Azure PowerShell.
Etapa 2: Validar o ambiente de cluster HDInsight
Cada cluster HDInsight depende de vários serviços do Azure e de software de código aberto, como Apache HBase e Apache Spark. Os clusters HDInsight também podem chamar outros serviços do Azure, como as Redes Virtuais do Azure. Uma falha de cluster pode ser causada por qualquer um dos serviços em execução no cluster ou por um serviço externo. Uma alteração na configuração do serviço de cluster também pode fazer com que o cluster falhe.
Detalhes do serviço
- Verifique as versões de lançamento da biblioteca de código aberto.
- Verifique se há interrupções de serviço do Azure.
- Verifique os limites de uso do Serviço do Azure.
- Verifique a configuração da sub-rede da Rede Virtual do Azure.
Exibir definições de configuração de cluster com a interface do usuário do Ambari
O Apache Ambari fornece gerenciamento e monitoramento de um cluster HDInsight com uma interface do usuário da Web e uma API REST. O Ambari está incluído em clusters HDInsight baseados em Linux. Selecione o painel Painel de Cluster na página HDInsight do portal do Azure. Selecione o painel do painel do cluster HDInsight para abrir a interface do usuário do Ambari e insira as credenciais de login do cluster.
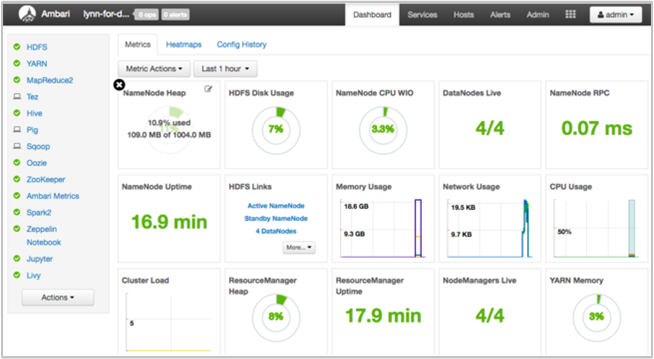
Para abrir uma lista de modos de exibição de serviço, selecione Modos de Exibição Ambari na página do portal do Azure. Essa lista depende de quais bibliotecas estão instaladas. Por exemplo, você pode ver o Gerenciador de filas do YARN, o modo de exibição do Hive e o modo de exibição Tez. Selecione um link de serviço para ver as informações de configuração e serviço.
Verificar interrupções de serviço do Azure
O HDInsight depende de vários serviços do Azure. Ele executa servidores virtuais no Azure HDInsight, armazena dados e scripts no armazenamento de Blob do Azure ou no Armazenamento do Azure Data Lake e indexa arquivos de log no armazenamento de Tabela do Azure. Interrupções nesses serviços, embora raras, podem causar problemas no HDInsight. Se você tiver lentidão ou falhas inesperadas em seu cluster, verifique o Painel de Status do Azure. O status de cada serviço é listado por região. Verifique a região do cluster e também as regiões para quaisquer serviços relacionados.
Verifique os limites de uso do serviço do Azure
Se você estiver iniciando um cluster grande ou tiver iniciado vários clusters simultaneamente, um cluster poderá falhar se você tiver excedido um limite de serviço do Azure. Os limites de serviço variam, dependendo da sua assinatura do Azure. Para obter mais informações, veja Subscrição do Azure e limites, quotas e restrições do serviço. Você pode solicitar que a Microsoft aumente o número de recursos do HDInsight disponíveis (como núcleos de VM e instâncias de VM) com uma solicitação de aumento de cota principal do Gerenciador de Recursos.
Verifique a versão de lançamento
Compare a versão do cluster com a versão mais recente do HDInsight. Cada versão do HDInsight inclui melhorias, como novos aplicativos, recursos, patches e correções de bugs. O problema que está afetando o cluster pode ter sido corrigido na versão mais recente. Se possível, execute novamente o cluster usando a versão mais recente do HDInsight e bibliotecas associadas, como Apache HBase, Apache Spark e outros.
Reinicie os serviços de cluster
Se você estiver enfrentando lentidão em seu cluster, considere reiniciar seus serviços por meio da interface do usuário do Ambari ou da CLI Clássica do Azure. O cluster pode estar enfrentando erros transitórios, e reiniciar é a maneira mais rápida de estabilizar seu ambiente e, possivelmente, melhorar o desempenho.
Etapa 3: Exibir a integridade do cluster
Os clusters HDInsight são compostos por diferentes tipos de nós em execução em instâncias de máquinas virtuais. Cada nó pode ser monitorado quanto à falta de recursos, problemas de conectividade de rede e outros problemas que podem tornar o cluster mais lento. Cada cluster contém dois nós principais, e a maioria dos tipos de cluster contém uma combinação de nós de trabalho e de borda.
Para obter uma descrição dos vários nós que cada tipo de cluster usa, consulte Configurar clusters no HDInsight com Apache Hadoop, Apache Spark, Apache Kafka e muito mais.
As seções a seguir descrevem como verificar a integridade de cada nó e do cluster geral.
Obtenha um instantâneo da integridade do cluster usando o painel da interface do usuário do Ambari
O painel Ambari UI (https://<clustername>.azurehdinsight.net) fornece uma visão geral da integridade do cluster, como tempo de atividade, memória, uso de rede e CPU, uso de disco HDFS e assim por diante. Use a seção Hosts do Ambari para exibir recursos em um nível de host. Você também pode parar e reiniciar os serviços.
Verifique o seu serviço WebHCat
Um cenário comum para trabalhos Apache Hive, Apache Pig ou Apache Sqoop falharem é uma falha com o serviço WebHCat (ou Templeton). WebHCat é uma interface REST para execução de trabalho remoto, como Hive, Pig, Scoop e MapReduce. O WebHCat converte as solicitações de envio de trabalho em aplicativos Apache Hadoop YARN e retorna um status derivado do status do aplicativo YARN. As seções a seguir descrevem códigos de status HTTP WebHCat comuns.
BadGateway (código de status 502)
Esse código é uma mensagem genérica de nós de gateway e é o código de status de falha mais comum. Uma possível causa para isso é o serviço WebHCat estar inativo no nó principal ativo. Para verificar essa possibilidade, use o seguinte comando CURL:
curl -u admin:{HTTP PASSWD} https://{CLUSTERNAME}.azurehdinsight.net/templeton/v1/status?user.name=admin
Ambari exibe um alerta mostrando os hosts nos quais o serviço WebHCat está inativo. Você pode tentar trazer o serviço WebHCat de volta reiniciando o serviço em seu host.
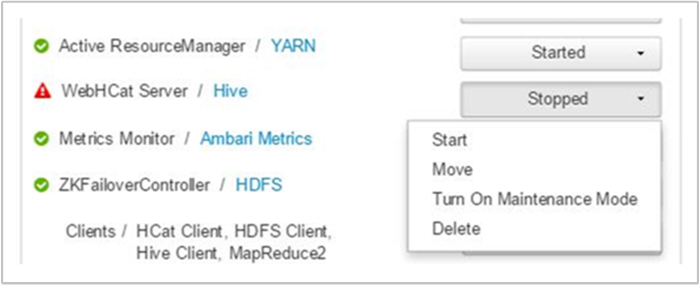
Se um servidor WebHCat ainda não aparecer, verifique se há mensagens de falha no log de operações. Para obter informações mais detalhadas, verifique os arquivos e stdout referenciados stderr no nó.
WebHCat expira
Um Gateway HDInsight expira respostas que levam mais de dois minutos, retornando 502 BadGateway. O WebHCat consulta os serviços YARN para obter status de trabalho e, se o YARN demorar mais de dois minutos para responder, essa solicitação poderá atingir o tempo limite.
Nesse caso, revise os /var/log/webhcat seguintes logs no diretório:
- webhcat.log é o log log4j no qual o servidor grava logs
- webhcat-console.log é o stdout do servidor quando iniciado
- webhcat-console-error.log é o stderr do processo do servidor
Nota
Cada webhcat.log um é rolado diariamente, gerando arquivos chamados webhcat.log.YYYY-MM-DD. Selecione o arquivo apropriado para o intervalo de tempo que você está investigando.
As seções a seguir descrevem algumas causas possíveis para os tempos limite do WebHCat.
Tempo limite de nível WebHCat
Quando o WebHCat está sob carga, com mais de 10 soquetes abertos, leva mais tempo para estabelecer novas conexões de soquete, o que pode resultar em um tempo limite. Para listar as conexões de rede de e para WebHCat, use netstat no headnode ativo atual:
netstat | grep 30111
30111 é a porta em que o WebHCat escuta. O número de tomadas abertas deve ser inferior a 10.
Se não houver soquetes abertos, o comando anterior não produzirá um resultado. Para verificar se o Templeton está ativo e ouvindo na porta 30111, use:
netstat -l | grep 30111
Tempo limite de nível YARN
Templeton chama YARN para executar trabalhos, e a comunicação entre Templeton e YARN pode causar um tempo limite.
No nível YARN, existem dois tipos de tempos limites:
Enviar um trabalho YARN pode levar tempo suficiente para causar um tempo limite.
Se você abrir o
/var/log/webhcat/webhcat.logarquivo de log e procurar por "trabalho em fila", você pode ver várias entradas onde o tempo de execução é excessivamente longo (>2000 ms), com entradas mostrando tempos de espera crescentes.O tempo para os trabalhos em fila continua a aumentar porque a taxa na qual novos trabalhos são enviados é maior do que a taxa na qual os trabalhos antigos são concluídos. Uma vez que a memória YARN é 100% usada, a fila do joblauncher não pode mais emprestar capacidade da fila padrão. Portanto, não é possível aceitar mais novos trabalhos na fila do joblauncher. Esse comportamento pode fazer com que o tempo de espera se torne cada vez maior, causando um erro de tempo limite que geralmente é seguido por muitos outros.
A imagem a seguir mostra a fila do joblauncher em 714,4% de uso excessivo. Isso é aceitável desde que ainda haja capacidade livre na fila padrão para pedir emprestado. No entanto, quando o cluster é totalmente utilizado e a memória YARN está com 100% da capacidade, novos trabalhos devem esperar, o que eventualmente causa tempos limites.

Há duas maneiras de resolver esse problema: reduzir a velocidade de novos trabalhos sendo enviados ou aumentar a velocidade de consumo de trabalhos antigos ampliando o cluster.
O processamento de fios pode levar muito tempo, o que pode causar tempos limites.
Listar todos os trabalhos: Esta é uma chamada demorada. Esta chamada enumera os aplicativos do YARN ResourceManager e, para cada aplicativo concluído, obtém o status do YARN JobHistoryServer. Com um número maior de trabalhos, essa chamada pode expirar.
Listar trabalhos com mais de sete dias: o HDInsight YARN JobHistoryServer está configurado para reter informações de trabalho concluídas por sete dias (
mapreduce.jobhistory.max-age-msvalor). Tentar enumerar trabalhos limpos resulta em um tempo limite.
Para diagnosticar esses problemas:
- Determinar o intervalo de tempo UTC para solucionar problemas
- Selecione o(s) arquivo(s) apropriado
webhcat.log(s) - Procure mensagens WARN e ERROR durante esse tempo
Outras falhas do WebHCat
Código de status HTTP 500
Na maioria dos casos em que WebHCat retorna 500, a mensagem de erro contém detalhes sobre a falha. Caso contrário, procure por
webhcat.logmensagens WARN e ERROR.Falhas em trabalhos
Pode haver casos em que as interações com o WebHCat são bem-sucedidas, mas os trabalhos estão falhando.
O Templeton coleta a saída do console de trabalho como
stderrnostatusdir, que geralmente é útil para a solução de problemas.stderrcontém o identificador de aplicativo YARN da consulta real.
Etapa 4: Revisar a pilha e as versões do ambiente
A página Ambari UI Stack and Version fornece informações sobre a configuração dos serviços de cluster e o histórico de versões do serviço. Versões incorretas da biblioteca de serviço Hadoop podem ser uma causa de falha de cluster. Na interface do usuário do Ambari, selecione o menu Admin e, em seguida, Pilhas e Versões. Selecione a guia Versões na página para ver as informações de versão do serviço:
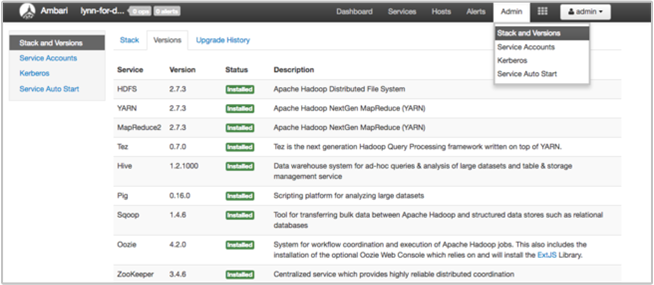
Etapa 5: Examinar os arquivos de log
Há muitos tipos de logs que são gerados a partir dos muitos serviços e componentes que compõem um cluster HDInsight. Os arquivos de log WebHCat são descritos anteriormente. Há vários outros arquivos de log úteis que você pode investigar para reduzir os problemas com seu cluster, conforme descrito nas seções a seguir.
Os clusters HDInsight consistem em vários nós, a maioria dos quais é encarregada de executar trabalhos enviados. Os trabalhos são executados simultaneamente, mas os arquivos de log só podem exibir resultados linearmente. O HDInsight executa novas tarefas, encerrando outras que não são concluídas primeiro. Toda essa atividade é registrada nos
stderrarquivos esyslog.Os arquivos de log de ação de script mostram erros ou alterações de configuração inesperadas durante o processo de criação do cluster.
Os logs de etapas do Hadoop identificam trabalhos do Hadoop iniciados como parte de uma etapa que contém erros.
Verifique os logs de ação do script
As ações de script do HDInsight executam scripts no cluster manualmente ou quando especificado. Por exemplo, as ações de script podem ser usadas para instalar software adicional no cluster ou para alterar as definições de configuração dos valores padrão. A verificação dos logs de ação de script pode fornecer informações sobre erros que ocorreram durante a instalação e configuração do cluster. Você pode exibir o status de uma ação de script selecionando o botão ops na interface do usuário do Ambari ou acessando os logs da conta de armazenamento padrão.
Os logs de ação de \STORAGE_ACCOUNT_NAME\DEFAULT_CONTAINER_NAME\custom-scriptaction-logs\CLUSTER_NAME\DATE script residem no diretório.
Exibir logs do HDInsight usando o Ambari Quick Links
A interface do usuário do HDInsight Ambari inclui várias seções de Links Rápidos . Para acessar os links de log de um serviço específico no cluster HDInsight, abra a interface do usuário do Ambari para o cluster e selecione o link de serviço na lista à esquerda. Selecione a lista suspensa Links Rápidos , o nó de interesse do HDInsight e selecione o link para seu log associado.
Por exemplo, para logs HDFS:
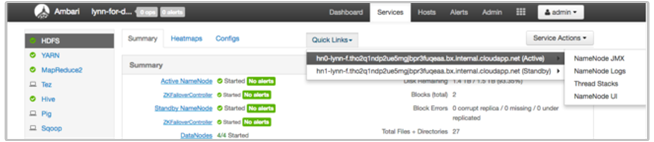
Exibir arquivos de log gerados pelo Hadoop
Um cluster HDInsight gera logs que são gravados em tabelas do Azure e no armazenamento de Blob do Azure. O YARN cria seus próprios logs de execução. Para obter mais informações, consulte Gerenciar logs para um cluster HDInsight.
Rever despejos de pilha
Os despejos de pilha contêm um instantâneo da memória do aplicativo, incluindo os valores das variáveis naquele momento, que são úteis para diagnosticar problemas que ocorrem em tempo de execução. Para obter mais informações, consulte Habilitar despejos de heap para serviços Apache Hadoop no HDInsight baseado em Linux.
Etapa 6: Verificar as definições de configuração
Os clusters HDInsight são pré-configurados com configurações padrão para serviços relacionados, como Hadoop, Hive, HBase e assim por diante. Dependendo do tipo de cluster, sua configuração de hardware, seu número de nós, os tipos de trabalhos que você está executando e os dados com os quais você está trabalhando (e como esses dados estão sendo processados), talvez seja necessário otimizar sua configuração.
Para obter instruções detalhadas sobre como otimizar configurações de desempenho para a maioria dos cenários, consulte Otimizar configurações de cluster com o Apache Ambari. Ao usar o Spark, consulte Otimizar trabalhos do Apache Spark para desempenho.
Etapa 7: Reproduzir a falha em um cluster diferente
Para ajudar a diagnosticar a origem de um erro de cluster, inicie um novo cluster com a mesma configuração e, em seguida, reenvie as etapas do trabalho com falha, uma a uma. Verifique os resultados de cada etapa antes de processar a próxima. Esse método oferece a oportunidade de corrigir e executar novamente uma única etapa com falha. Este método também tem a vantagem de carregar apenas os dados de entrada uma vez.
- Crie um novo cluster de teste com a mesma configuração do cluster com falha.
- Envie a primeira etapa do trabalho para o cluster de teste.
- Quando a etapa concluir o processamento, verifique se há erros nos arquivos de log da etapa. Conecte-se ao nó mestre do cluster de teste e visualize os arquivos de log lá. Os arquivos de log de etapas só aparecem depois que a etapa é executada por algum tempo, termina ou falha.
- Se a primeira etapa for bem-sucedida, execute a próxima etapa. Se houver erros, investigue o erro nos arquivos de log. Se foi um erro no seu código, faça a correção e execute novamente a etapa.
- Continue até que todas as etapas sejam executadas sem erros.
- Quando terminar de depurar o cluster de teste, exclua-o.
Próximos passos
- Manage HDInsight clusters by using the Apache Ambari Web UI (Gerir clusters do HDInsight através da IU da Web do Apache Ambari)
- Analisar logs do HDInsight
- Acesse o login do aplicativo Apache Hadoop YARN no HDInsight baseado em Linux
- Habilitar despejos de heap para serviços Apache Hadoop no HDInsight baseado em Linux
- Problemas conhecidos do cluster Apache Spark no HDInsight