Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Este bloco de anotações demonstra como analisar dados de log usando uma biblioteca personalizada com o Apache Spark no HDInsight. A biblioteca personalizada que usamos é uma biblioteca Python chamada iislogparser.py.
Pré-requisitos
Um cluster do Apache Spark no HDInsight. Para obter instruções, veja Criar clusters do Apache Spark no Azure HDInsight.
Salvar dados brutos como um RDD
Nesta seção, usamos o Jupyter Notebook associado a um cluster Apache Spark no HDInsight para executar trabalhos que processam seus dados de amostra brutos e os salvam como uma tabela do Hive. Os dados de exemplo são um arquivo de .csv (hvac.csv) disponível em todos os clusters por padrão.
Depois que seus dados forem salvos como uma tabela do Apache Hive, na próxima seção, nos conectaremos à tabela do Hive usando ferramentas de BI, como o Power BI e o Tableau.
Em um navegador da Web, navegue até
https://CLUSTERNAME.azurehdinsight.net/jupyter, ondeCLUSTERNAMEé o nome do cluster.Crie um novo bloco de notas. Selecione Novo e, em seguida, PySpark.
É criado e aberto um novo bloco de notas com o nome Untitled.pynb. Selecione o nome do bloco de notas na parte superior e introduza um nome amigável.
Como você criou um bloco de anotações usando o kernel do PySpark, não precisa criar nenhum contexto explicitamente. Os contextos Spark e Hive serão criados automaticamente para você quando você executar a primeira célula de código. Você pode começar importando os tipos necessários para esse cenário. Cole o seguinte trecho em uma célula vazia e pressione Shift + Enter.
from pyspark.sql import Row from pyspark.sql.types import *Crie um RDD usando os dados de log de exemplo já disponíveis no cluster. Você pode acessar os dados na conta de armazenamento padrão associada ao cluster em
\HdiSamples\HdiSamples\WebsiteLogSampleData\SampleLog\909f2b.log. Execute o seguinte código:logs = sc.textFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b.log')Recupere um conjunto de logs de exemplo para verificar se a etapa anterior foi concluída com êxito.
logs.take(5)Deverá ver uma saída semelhante ao seguinte texto:
[u'#Software: Microsoft Internet Information Services 8.0', u'#Fields: date time s-sitename cs-method cs-uri-stem cs-uri-query s-port cs-username c-ip cs(User-Agent) cs(Cookie) cs(Referer) cs-host sc-status sc-substatus sc-win32-status sc-bytes cs-bytes time-taken', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step4.png X-ARR-LOG-ID=4bea5b3d-8ac9-46c9-9b8c-ec3e9500cbea 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 72177 871 47']
Analise dados de log usando uma biblioteca Python personalizada
Na saída acima, as primeiras linhas incluem as informações do cabeçalho e cada linha restante corresponde ao esquema descrito nesse cabeçalho. Analisar esses logs pode ser complicado. Assim, usamos uma biblioteca Python personalizada (iislogparser.py) que torna a análise desses logs muito mais fácil. Por padrão, essa biblioteca está incluída no cluster do Spark no HDInsight em
/HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py.No entanto, essa biblioteca não está no
PYTHONPATHportanto, não podemos usá-la usando uma instrução de importação comoimport iislogparser. Para usar esta biblioteca, devemos distribuí-la por todos os nós de trabalho. Execute o seguinte trecho.sc.addPyFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py')iislogparserfornece uma funçãoparse_log_lineque retornaNonese uma linha de log for uma linha de cabeçalho, e retorna uma instância da classeLogLinese encontrar uma linha de log. Use aLogLineclasse para extrair apenas as linhas de log do RDD:def parse_line(l): import iislogparser return iislogparser.parse_log_line(l) logLines = logs.map(parse_line).filter(lambda p: p is not None).cache()Recupere algumas linhas de log extraídas para verificar se a etapa foi concluída com êxito.
logLines.take(2)A saída deve ser semelhante ao seguinte texto:
[2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46, 2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32]A
LogLineclasse, por sua vez, tem alguns métodos úteis, comois_error(), que retorna se uma entrada de log tem um código de erro. Use essa classe para calcular o número de erros nas linhas de log extraídas e, em seguida, registre todos os erros em um arquivo diferente.errors = logLines.filter(lambda p: p.is_error()) numLines = logLines.count() numErrors = errors.count() print 'There are', numErrors, 'errors and', numLines, 'log entries' errors.map(lambda p: str(p)).saveAsTextFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b-2.log')A saída deve indicar
There are 30 errors and 646 log entries.Você também pode usar Matplotlib para construir uma visualização dos dados. Por exemplo, se você quiser isolar a causa das solicitações que são executadas por um longo tempo, talvez queira encontrar os arquivos que levam mais tempo para servir em média. O trecho abaixo recupera os 25 principais recursos que levaram mais tempo para atender a uma solicitação.
def avgTimeTakenByKey(rdd): return rdd.combineByKey(lambda line: (line.time_taken, 1), lambda x, line: (x[0] + line.time_taken, x[1] + 1), lambda x, y: (x[0] + y[0], x[1] + y[1]))\ .map(lambda x: (x[0], float(x[1][0]) / float(x[1][1]))) avgTimeTakenByKey(logLines.map(lambda p: (p.cs_uri_stem, p))).top(25, lambda x: x[1])Você deve ver uma saída semelhante ao texto seguinte:
[(u'/blogposts/mvc4/step13.png', 197.5), (u'/blogposts/mvc2/step10.jpg', 179.5), (u'/blogposts/extractusercontrol/step5.png', 170.0), (u'/blogposts/mvc4/step8.png', 159.0), (u'/blogposts/mvcrouting/step22.jpg', 155.0), (u'/blogposts/mvcrouting/step3.jpg', 152.0), (u'/blogposts/linqsproc1/step16.jpg', 138.75), (u'/blogposts/linqsproc1/step26.jpg', 137.33333333333334), (u'/blogposts/vs2008javascript/step10.jpg', 127.0), (u'/blogposts/nested/step2.jpg', 126.0), (u'/blogposts/adminpack/step1.png', 124.0), (u'/BlogPosts/datalistpaging/step2.png', 118.0), (u'/blogposts/mvc4/step35.png', 117.0), (u'/blogposts/mvcrouting/step2.jpg', 116.5), (u'/blogposts/aboutme/basketball.jpg', 109.0), (u'/blogposts/anonymoustypes/step11.jpg', 109.0), (u'/blogposts/mvc4/step12.png', 106.0), (u'/blogposts/linq8/step0.jpg', 105.5), (u'/blogposts/mvc2/step18.jpg', 104.0), (u'/blogposts/mvc2/step11.jpg', 104.0), (u'/blogposts/mvcrouting/step1.jpg', 104.0), (u'/blogposts/extractusercontrol/step1.png', 103.0), (u'/blogposts/sqlvideos/sqlvideos.jpg', 102.0), (u'/blogposts/mvcrouting/step21.jpg', 101.0), (u'/blogposts/mvc4/step1.png', 98.0)]Você também pode apresentar essas informações na forma de gráfico. Como primeiro passo para criar um gráfico, vamos primeiro criar uma tabela temporária AverageTime. A tabela agrupa os logs por tempo para ver se houve picos de latência incomuns em algum momento específico.
avgTimeTakenByMinute = avgTimeTakenByKey(logLines.map(lambda p: (p.datetime.minute, p))).sortByKey() schema = StructType([StructField('Minutes', IntegerType(), True), StructField('Time', FloatType(), True)]) avgTimeTakenByMinuteDF = sqlContext.createDataFrame(avgTimeTakenByMinute, schema) avgTimeTakenByMinuteDF.registerTempTable('AverageTime')Em seguida, você pode executar a seguinte consulta SQL para obter todos os registros na tabela AverageTime .
%%sql -o averagetime SELECT * FROM AverageTimeA
%%sqlcomposição mágica seguida por-o averagetimegarante que a saída da consulta seja mantida localmente no servidor Jupyter (normalmente o nó principal do cluster). A saída é armazenada como um dataframe Pandas com o nome especificado averagetime.Deve ver um resultado como o da imagem seguinte.
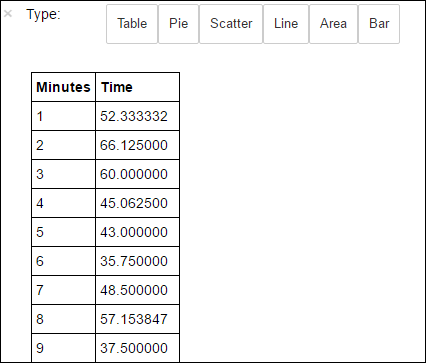 yter sql query output" border="true":::
yter sql query output" border="true":::Para obter mais informações sobre a
%%sqlmagia, consulte Parâmetros suportados com a magia %%sql.Agora você pode usar Matplotlib, uma biblioteca usada para construir visualização de dados, para criar um gráfico. Como o gráfico deve ser gerado a partir do dataframe de tempo médio persistido localmente, o trecho de código deve começar com o
%%localcomando mágico. Isso garante que o código seja executado localmente no servidor Jupyter.%%local %matplotlib inline import matplotlib.pyplot as plt plt.plot(averagetime['Minutes'], averagetime['Time'], marker='o', linestyle='--') plt.xlabel('Time (min)') plt.ylabel('Average time taken for request (ms)')Deve ver um resultado semelhante à imagem seguinte.
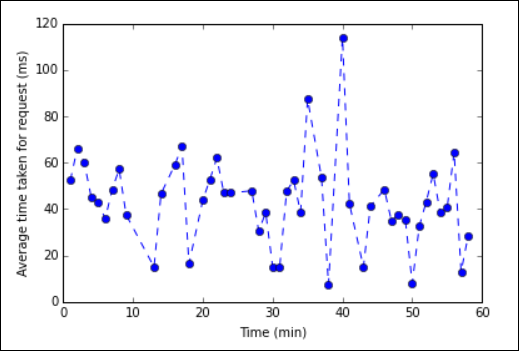 eb log analysis plot" border="true":::
eb log analysis plot" border="true":::Depois de terminar de executar o aplicativo, você deve desligar o bloco de anotações para liberar os recursos. Para tal, no menu File (Ficheiro) do bloco de notas, selecione Close and Halt (Fechar e Parar). Esta ação irá desligar e fechar o bloco de notas.
Próximos passos
Explore os seguintes artigos: