Comece a usar dados DICOM em cargas de trabalho de análise
Este artigo descreve como começar a usar dados DICOM® em cargas de trabalho de análise com o Azure Data Factory e o Microsoft Fabric.
Pré-requisitos
Antes de começar, conclua estas etapas:
- Crie uma conta de armazenamento com os recursos do Azure Data Lake Storage Gen2 habilitando um namespace hierárquico:
- Crie um contêiner para armazenar metadados DICOM, por exemplo, chamado
dicom.
- Crie um contêiner para armazenar metadados DICOM, por exemplo, chamado
- Implante uma instância do serviço DICOM.
- (Opcional) Implante o serviço DICOM com o Armazenamento Data Lake para permitir o acesso direto aos arquivos DICOM.
- Crie uma instância do Data Factory :
- Habilite uma identidade gerenciada atribuída ao sistema.
- Crie uma casa de lago no Fabric.
- Adicione atribuições de função à identidade gerenciada atribuída pelo sistema Data Factory para o serviço DICOM e a conta de armazenamento Data Lake Storage Gen2:
- Adicione a função Leitor de Dados DICOM para conceder permissão ao serviço DICOM.
- Adicione a função de Colaborador de Dados de Blob de Armazenamento para conceder permissão à conta do Data Lake Storage Gen2.
Configurar um pipeline do Data Factory para o serviço DICOM
Neste exemplo, um pipeline do Data Factory é usado para escrever atributos DICOM para instâncias, séries e estudos em uma conta de armazenamento em um formato de tabela Delta.
No portal do Azure, abra a instância do Data Factory e selecione Iniciar estúdio para começar.

Criar serviços ligados
Os pipelines do Data Factory leem de fontes de dados e gravam em coletores de dados, que normalmente são outros serviços do Azure. Essas conexões com outros serviços são gerenciadas como serviços vinculados.
O pipeline neste exemplo lê dados de um serviço DICOM e grava sua saída em uma conta de armazenamento, portanto, um serviço vinculado deve ser criado para ambos.
Criar um serviço vinculado para o serviço DICOM
No Azure Data Factory Studio, selecione Gerenciar no menu à esquerda. Em Conexões, selecione Serviços vinculados e, em seguida, selecione Novo.
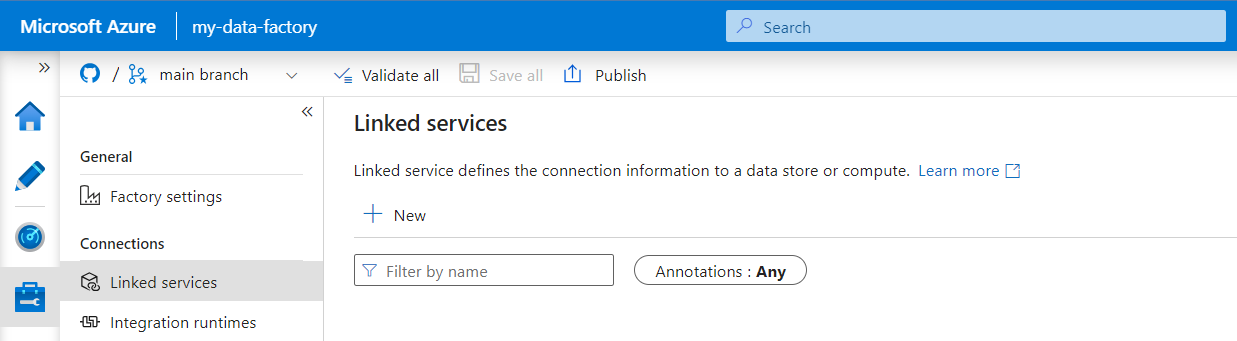
No painel Novo serviço vinculado, procure REST. Selecione o mosaico REST e, em seguida, selecione Continuar.
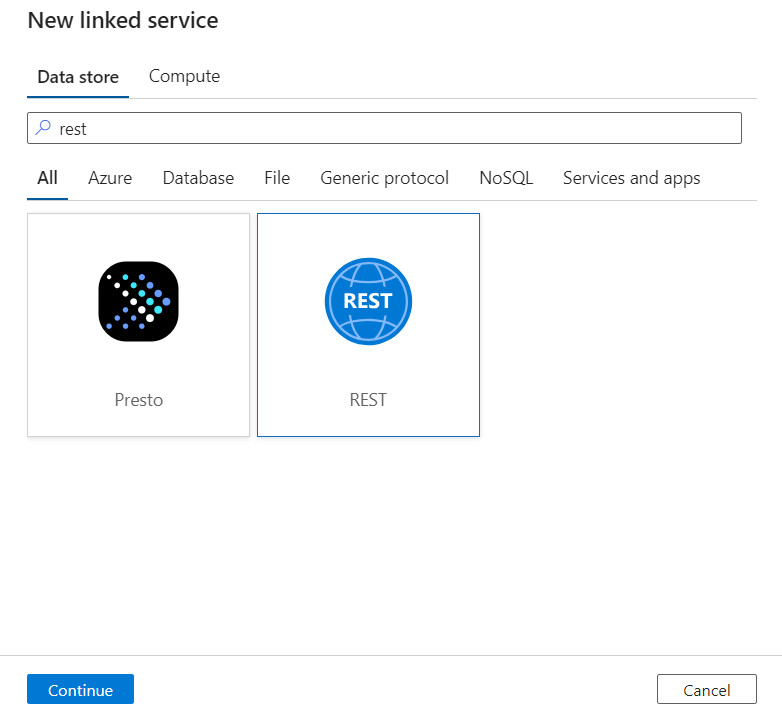
Insira um Nome e Descrição para o serviço vinculado.
No campo URL base, insira a URL do serviço DICOM. Por exemplo, um serviço DICOM nomeado
contosoclinicno espaço de trabalho tem acontosohealthURLhttps://contosohealth-contosoclinic.dicom.azurehealthcareapis.comdo serviço .Em Tipo de autenticação, selecione Identidade gerenciada atribuída pelo sistema.
Para o recurso do AAD, insira
https://dicom.healthcareapis.azure.com. Este URL é o mesmo para todas as instâncias de serviço DICOM.Depois de preencher os campos obrigatórios, selecione Testar conexão para garantir que as funções da identidade estejam configuradas corretamente.
Quando o teste de conexão for bem-sucedido, selecione Criar.



Criar um serviço vinculado para o Azure Data Lake Storage Gen2
No Data Factory Studio, selecione Gerenciar no menu à esquerda. Em Conexões, selecione Serviços vinculados e, em seguida, selecione Novo.
No painel Novo serviço vinculado, procure Azure Data Lake Storage Gen2. Selecione o bloco Azure Data Lake Storage Gen2 e selecione Continuar.
Insira um Nome e Descrição para o serviço vinculado.
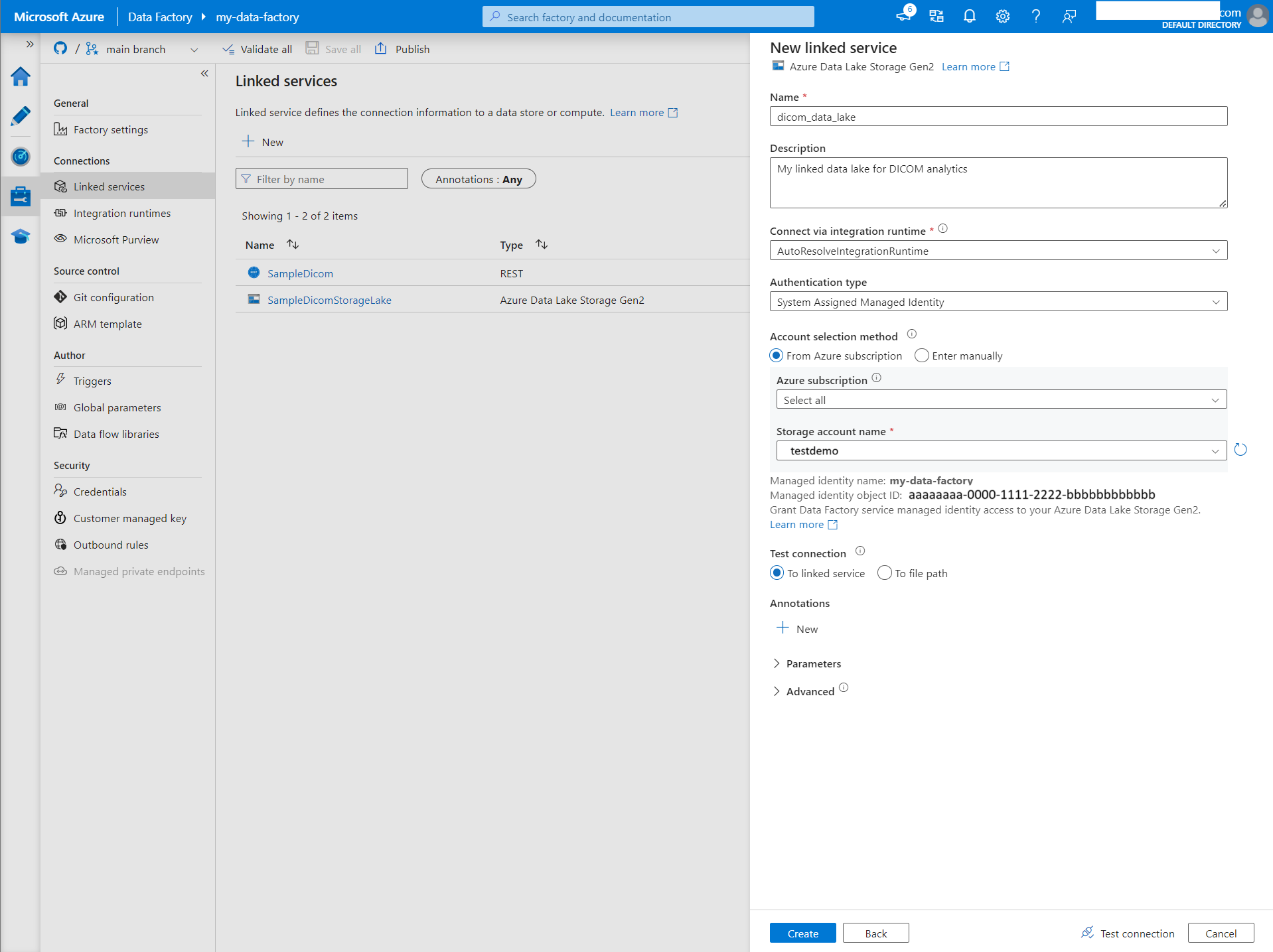
Em Tipo de autenticação, selecione Identidade gerenciada atribuída pelo sistema.
Insira os detalhes da conta de armazenamento inserindo o URL para a conta de armazenamento manualmente. Você também pode selecionar a assinatura do Azure e a conta de armazenamento nos menus suspensos.
Depois de preencher os campos obrigatórios, selecione Testar conexão para garantir que as funções da identidade estejam configuradas corretamente.
Quando o teste de conexão for bem-sucedido, selecione Criar.


Criar um pipeline para dados DICOM
Os pipelines do Data Factory são uma coleção de atividades que executam uma tarefa, como copiar metadados DICOM para tabelas Delta. Esta seção detalha a criação de um pipeline que sincroniza regularmente dados DICOM com tabelas Delta à medida que os dados são adicionados, atualizados e excluídos de um serviço DICOM.
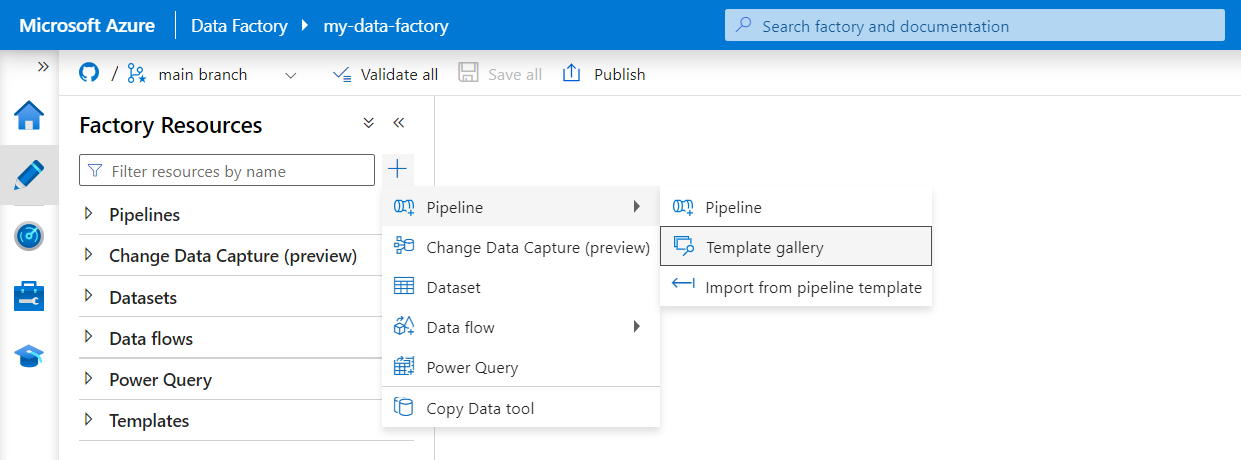
Selecione Autor no menu à esquerda. No painel Recursos de fábrica, selecione o sinal de adição (+) para adicionar um novo recurso. Selecione Pipeline e, em seguida, selecione Galeria de modelos no menu.
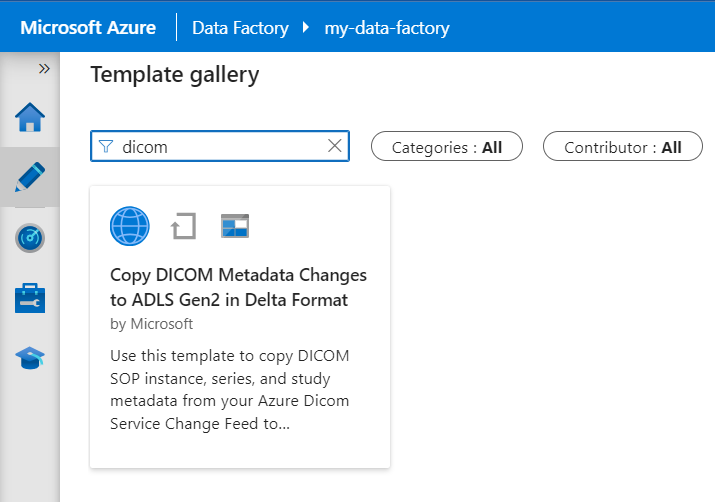
Na galeria de modelos, procure DICOM. Selecione o bloco Copiar alterações de metadados DICOM para ADLS Gen2 no formato delta e, em seguida, selecione Continuar.
Na seção Entradas, selecione os serviços vinculados criados anteriormente para o serviço DICOM e a conta Data Lake Storage Gen2.

Selecione Usar este modelo para criar o novo pipeline.



Criar um pipeline para dados DICOM
Se você criou o serviço DICOM com o Armazenamento Azure Data Lake, em vez de usar o modelo da galeria de modelos, precisará usar um modelo personalizado para incluir um novo fileName parâmetro no pipeline de metadados. Para configurar o pipeline, siga estas etapas.
Baixe o modelo do GitHub. O arquivo de modelo é uma pasta compactada (zipada). Você não precisa extrair os arquivos porque eles já foram carregados em formato compactado.
No Azure Data Factory, selecione Autor no menu à esquerda. No painel Recursos de fábrica, selecione o sinal de adição (+) para adicionar um novo recurso. Selecione Pipeline e, em seguida, selecione Importar do modelo de pipeline.
Na janela Abrir, selecione o modelo que você baixou. Selecione Abrir.
Na seção Entradas, selecione os serviços vinculados criados para o serviço DICOM e a conta do Azure Data Lake Storage Gen2.
Selecione Usar este modelo para criar o novo pipeline.
Agendar um pipeline
Os pipelines são agendados por gatilhos. Existem diferentes tipos de gatilhos. Os gatilhos de agendamento permitem que os pipelines sejam acionados para serem executados em horários específicos do dia, como a cada hora ou todos os dias à meia-noite. Os gatilhos manuais acionam pipelines sob demanda, o que significa que eles são executados sempre que você quiser.
Neste exemplo, um gatilho de janela de tombamento é usado para executar periodicamente o pipeline dado um ponto de partida e um intervalo de tempo regular. Para obter mais informações sobre gatilhos, consulte Execução de pipeline e gatilhos no Azure Data Factory ou Azure Synapse Analytics.
Criar um novo gatilho de janela de tombamento
Selecione Autor no menu à esquerda. Selecione o pipeline para o serviço DICOM e selecione Adicionar gatilho e Novo/Editar na barra de menus.
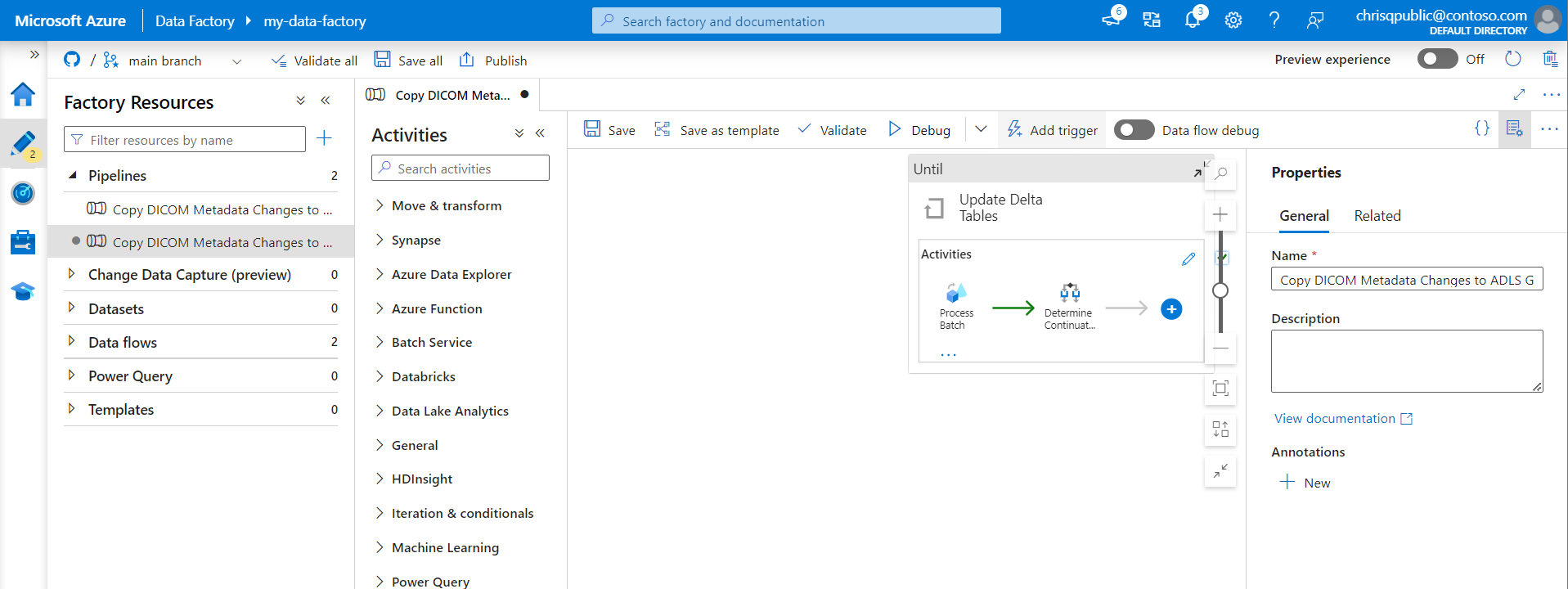
No painel Adicionar gatilhos, selecione a lista suspensa Escolher gatilho e, em seguida, selecione Novo.
Insira um Nome e Descrição para o gatilho.
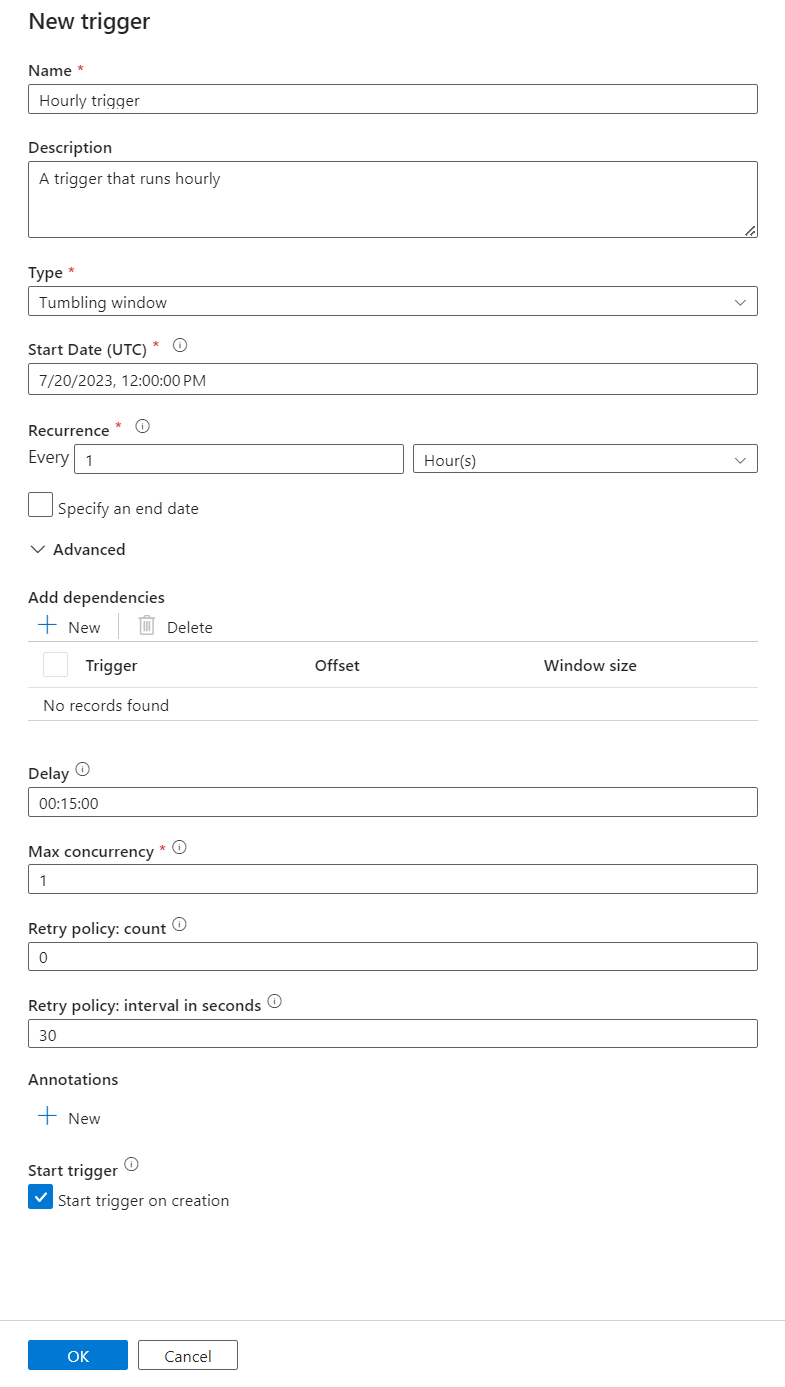
Selecione Janela de tombamento como o Tipo.
Para configurar um pipeline que é executado de hora em hora, defina a Recorrência como 1 hora.
Expanda a seção Avançado e insira um Atraso de 15 minutos. Essa configuração permite que todas as operações pendentes no final de uma hora sejam concluídas antes do processamento.
Defina a simultaneidade máxima como 1 para garantir a consistência entre as tabelas.
Selecione OK para continuar a configurar os parâmetros de execução do gatilho.


Configurar parâmetros de execução de gatilho
Os gatilhos definem quando um pipeline é executado. Eles também incluem parâmetros que são passados para a execução do pipeline. O modelo Copiar alterações de metadados DICOM para Delta define parâmetros descritos na tabela a seguir. Se nenhum valor for fornecido durante a configuração, o valor padrão listado será usado para cada parâmetro.
| Nome do parâmetro | Description | Default value |
|---|---|---|
| Tamanho do lote | O número máximo de alterações a recuperar de cada vez a partir do feed de alterações (máximo 200) | 200 |
| ApiVersion | A versão da API para o serviço DICOM do Azure (mínimo 2) | 2 |
| StartTime | A hora de início inclusiva para as alterações DICOM | 0001-01-01T00:00:00Z |
| EndTime | A hora de término exclusiva para as mudanças DICOM | 9999-12-31T23:59:59Z |
| ContainerName | O nome do contêiner para as tabelas Delta resultantes | dicom |
| InstanceTablePath | O caminho que contém a tabela Delta para instâncias DICOM SOP dentro do contêiner | instance |
| SeriesTablePath | O caminho que contém a tabela Delta para a série DICOM dentro do contêiner | series |
| StudyTablePath | O caminho que contém a tabela Delta para estudos DICOM dentro do contêiner | study |
| RetentionHours | A retenção máxima em horas para dados nas tabelas Delta | 720 |
No painel Parâmetros de Execução do Acionador, insira o valor ContainerName que corresponde ao nome do contêiner de armazenamento criado nos pré-requisitos.
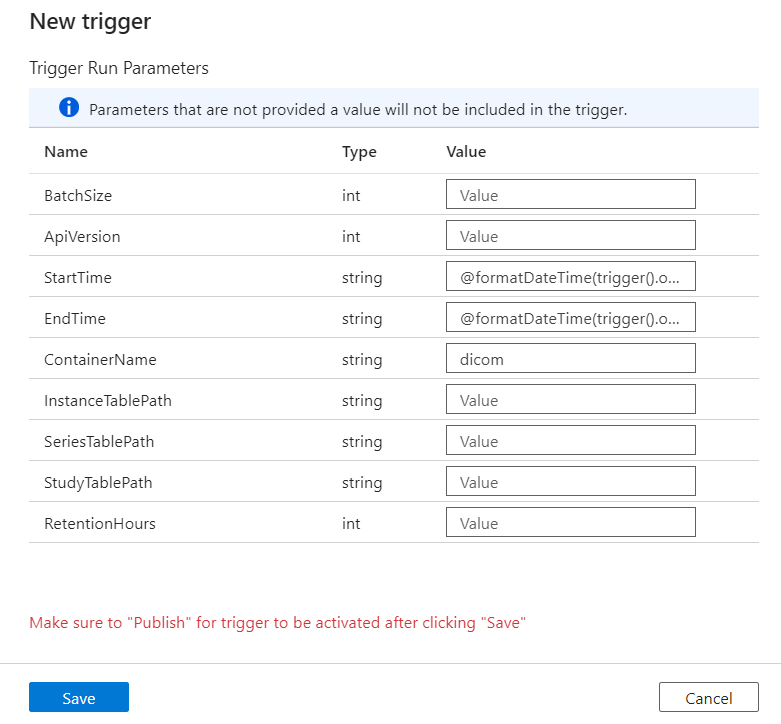
Para StartTime, use a variável
@formatDateTime(trigger().outputs.windowStartTime)de sistema .Para EndTime, use a variável
@formatDateTime(trigger().outputs.windowEndTime)de sistema .Nota
Apenas os gatilhos de janela de queda suportam as variáveis do sistema:
@trigger().outputs.windowStartTimee ainda@trigger().outputs.windowEndTime.
Os gatilhos de programação usam diferentes variáveis do sistema:
@trigger().scheduledTimee ainda@trigger().startTime.
Saiba mais sobre os tipos de gatilho.
Selecione Salvar para criar o novo gatilho. Selecione Publicar para iniciar a execução do gatilho na programação definida.


Depois que o gatilho for publicado, ele poderá ser acionado manualmente usando a opção Gatilho agora . Se a hora de início foi definida para um valor no passado, o pipeline começa imediatamente.
Monitorizar execuções de pipeline
Você pode monitorar execuções acionadas e suas execuções de pipeline associadas na guia Monitor . Aqui, você pode procurar quando cada pipeline foi executado e quanto tempo levou para ser executado. Você também pode potencialmente depurar quaisquer problemas que surgiram.

Microsoft Fabric
O Fabric é uma solução de análise tudo-em-um que fica no topo do Microsoft OneLake. Com o uso de um Fabric lakehouse, você pode gerenciar, estruturar e analisar dados no OneLake em um único local. Todos os dados fora do OneLake, gravados no Data Lake Storage Gen2, podem ser conectados ao OneLake usando atalhos para aproveitar o conjunto de ferramentas do Fabric.
Criar atalhos para tabelas de metadados
Vá para a casa do lago criada nos pré-requisitos. Na vista do Explorer, selecione o menu de reticências (...) junto à pasta Tabelas.
Selecione Novo atalho para criar um novo atalho para a conta de armazenamento que contém os dados de análise DICOM.
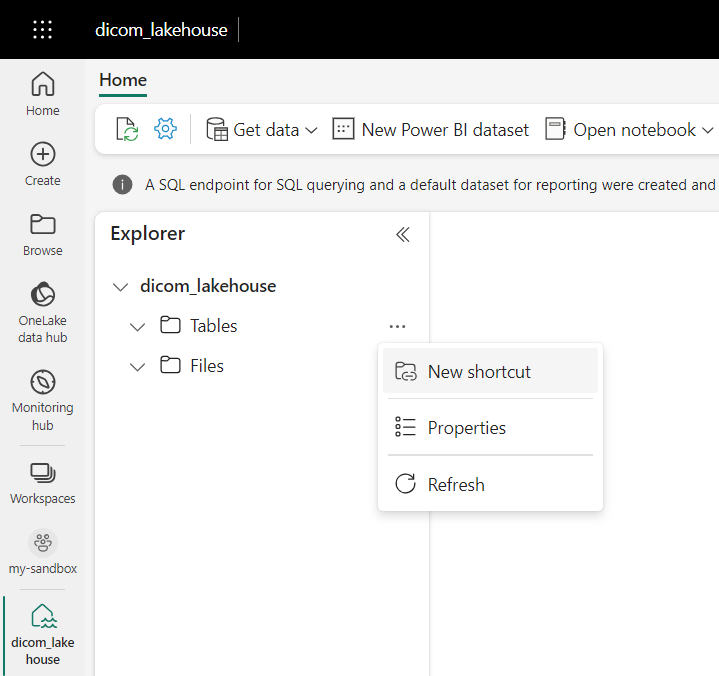
Selecione Azure Data Lake Storage Gen2 como a origem do atalho.
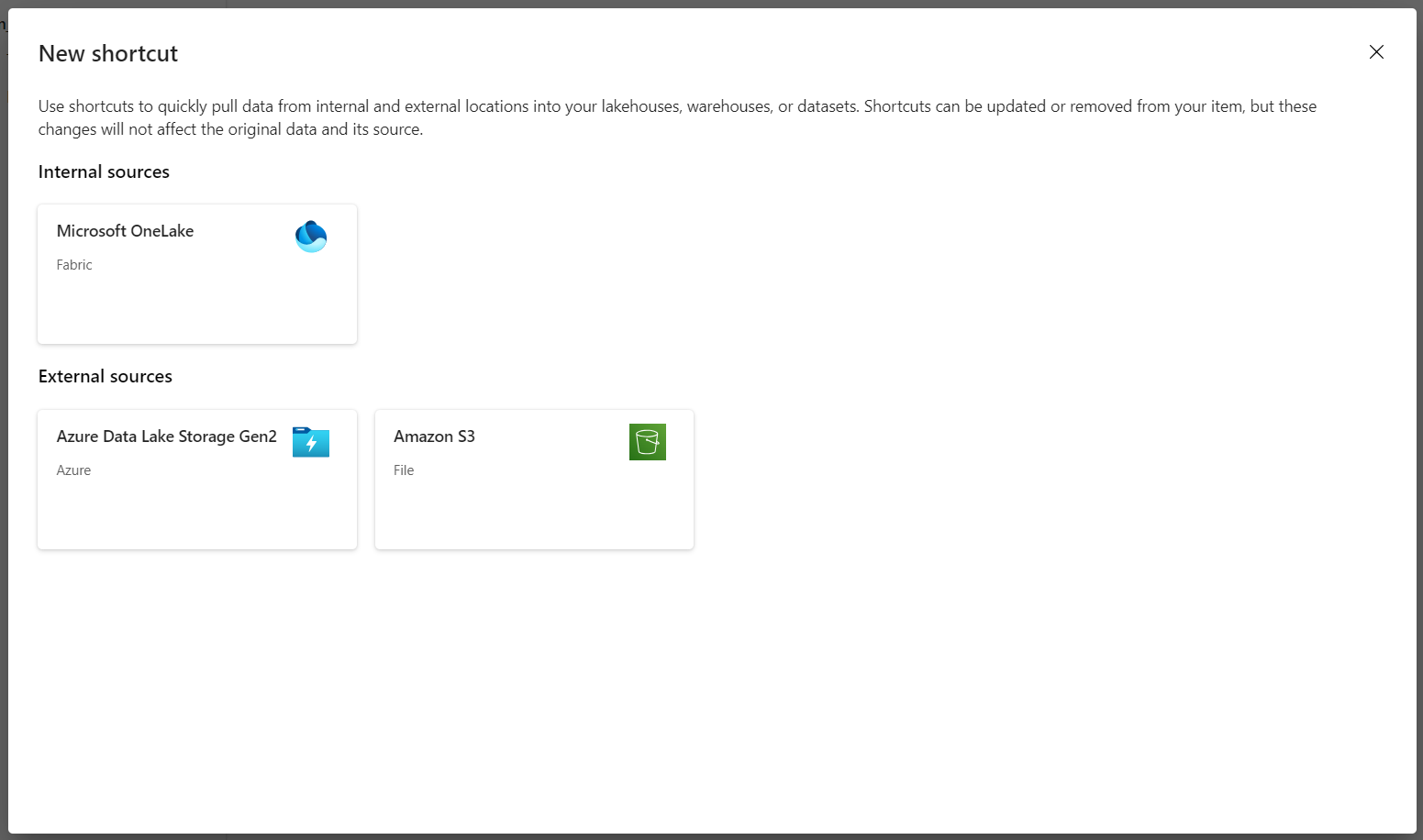
Em Configurações de conexão, insira a URL usada na seção Serviços vinculados .
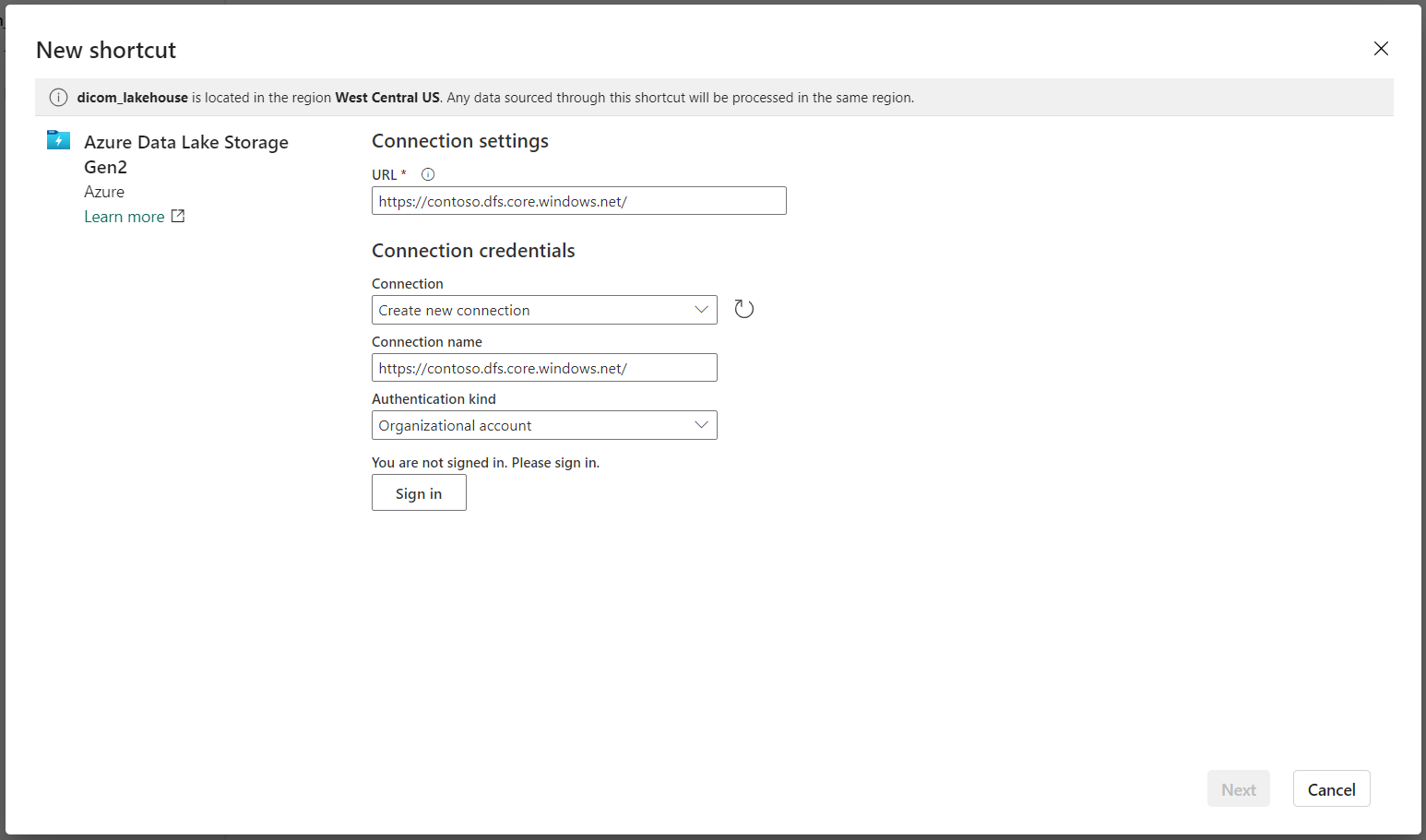
Selecione uma conexão existente ou crie uma nova conexão selecionando o tipo de autenticação que você deseja usar.
Nota
Há algumas opções para autenticação entre o Data Lake Storage Gen2 e o Fabric. Você pode usar uma conta organizacional ou uma entidade de serviço. Não recomendamos o uso de chaves de conta ou tokens de assinatura de acesso compartilhado.
Selecione Seguinte.
Insira um Nome de Atalho que represente os dados criados pelo pipeline do Data Factory. Por exemplo, para a
instancetabela Delta, o nome do atalho provavelmente deve ser instância.Insira o Subcaminho que corresponde ao
ContainerNameparâmetro da configuração de parâmetros de execução e o nome da tabela para o atalho. Por exemplo, use/dicom/instancepara a tabela Delta com o caminhoinstancenodicomcontêiner.Selecione Criar para criar o atalho.
Repita as etapas 2 a 9 para adicionar os atalhos restantes às outras tabelas Delta na conta de armazenamento (por exemplo,
seriesestudy).



Depois de criar os atalhos, expanda uma tabela para mostrar os nomes e tipos das colunas.

Criar atalhos para ficheiros
Se você estiver usando um serviço DICOM com o Armazenamento Data Lake, poderá criar adicionalmente um atalho para os dados do arquivo DICOM armazenados no data lake.
Vá para a casa do lago criada nos pré-requisitos. Na vista do Explorer, selecione o menu de reticências (...) junto à pasta Ficheiros.
Selecione Novo atalho para criar um novo atalho para a conta de armazenamento que contém os dados DICOM.
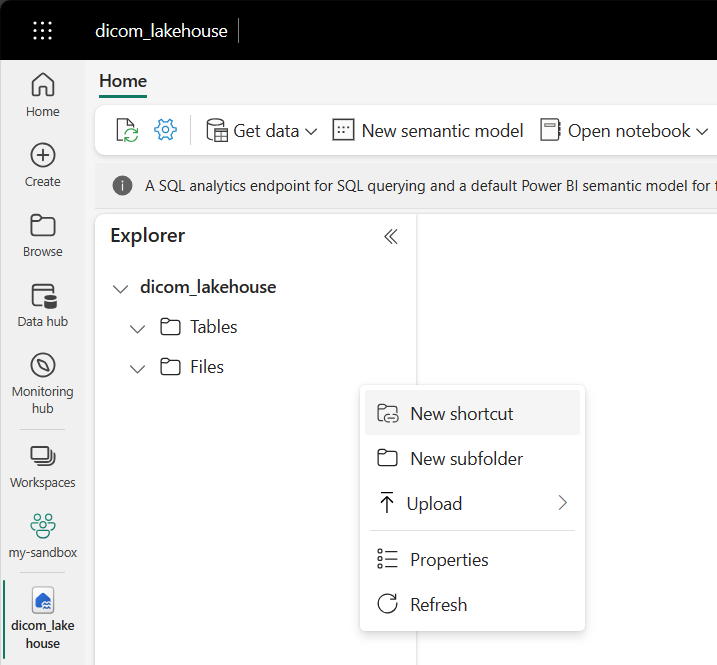
Selecione Azure Data Lake Storage Gen2 como a origem do atalho.
Em Configurações de conexão, insira a URL usada na seção Serviços vinculados .
Selecione uma conexão existente ou crie uma nova conexão selecionando o tipo de autenticação que você deseja usar.
Selecione Seguinte.
Insira um nome de atalho que descreva os dados DICOM. Por exemplo, contoso-dicom-files.
Insira o Subcaminho que corresponde ao nome do contêiner de armazenamento e da pasta usados pelo serviço DICOM. Por exemplo, se você quisesse vincular à pasta raiz, o Subcaminho seria /dicom/AHDS. A pasta raiz é sempre
AHDS, mas você pode, opcionalmente, vincular a uma pasta filho para um espaço de trabalho específico ou instância de serviço DICOM.Selecione Criar para criar o atalho.


Executar blocos de notas
Depois que as tabelas são criadas na casa do lago, você pode consultá-las a partir de blocos de anotações de malha. Você pode criar blocos de anotações diretamente da casa do lago selecionando Abrir Bloco de Anotações na barra de menus.
Na página do caderno, o conteúdo da casa do lago pode ser visto no lado esquerdo, incluindo tabelas recém-adicionadas. Na parte superior da página, selecione o idioma do bloco de anotações. O idioma também pode ser configurado para células individuais. O exemplo a seguir usa o Spark SQL.
Consultar tabelas usando o Spark SQL
No editor de células, insira uma consulta do Spark SQL como uma SELECT instrução.
SELECT * from instance
Esta consulta seleciona todo o conteúdo da instance tabela. Quando estiver pronto, selecione Executar célula para executar a consulta.

Após alguns segundos, os resultados da consulta aparecem em uma tabela abaixo da célula, como mostra o exemplo a seguir. O tempo pode ser maior se essa consulta do Spark for a primeira da sessão porque o contexto do Spark precisa ser inicializado.

Acessar dados de arquivos DICOM em blocos de anotações
Se você usou um modelo para criar o pipeline e criou um atalho para os dados do arquivo DICOM, poderá usar a filePath coluna na tabela para correlacionar metadados de instance instância aos dados do arquivo.
SELECT sopInstanceUid, filePath from instance

Resumo
Neste artigo, você aprendeu como:
- Use modelos do Data Factory para criar um pipeline do serviço DICOM para uma conta do Data Lake Storage Gen2.
- Configure um gatilho para extrair metadados DICOM em uma programação horária.
- Use atalhos para conectar dados DICOM em uma conta de armazenamento a um lago de malha.
- Use blocos de anotações para consultar dados DICOM na casa do lago.
Próximos passos
Nota
DICOM® é a marca registrada da National Electrical Manufacturers Association para suas publicações de padrões relacionados a comunicações digitais de informações médicas.