Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este artigo descreve como usar o componente Seleção de Recursos Baseada em Filtro no designer do Azure Machine Learning. Esse componente ajuda a identificar as colunas no conjunto de dados de entrada que têm o maior poder preditivo.
Em geral, a seleção de recursos refere-se ao processo de aplicação de testes estatísticos às entradas, dada uma saída especificada. O objetivo é determinar quais colunas são mais preditivas da saída. O componente Seleção de recursos baseada em filtro fornece vários algoritmos de seleção de recursos para escolher. O componente inclui métodos de correlação como correlação de Pearson e valores qui-quadrado.
Ao usar o componente Seleção de Recursos Baseada em Filtro, você fornece um conjunto de dados e identifica a coluna que contém o rótulo ou a variável dependente. Em seguida, especifique um único método a ser usado na medição da importância do recurso.
O componente gera um conjunto de dados que contém as melhores colunas de recursos, classificadas por poder preditivo. Ele também produz os nomes dos recursos e suas pontuações da métrica selecionada.
O que é a seleção de recursos baseada em filtro
Esse componente para seleção de recursos é chamado de "baseado em filtro" porque você usa a métrica selecionada para localizar atributos irrelevantes. Em seguida, você filtra colunas redundantes do seu modelo. Você escolhe uma única medida estatística que se adapta aos seus dados e o componente calcula uma pontuação para cada coluna de recurso. As colunas são retornadas classificadas por suas pontuações de recursos.
Ao escolher os recursos certos, você pode melhorar a precisão e a eficiência da classificação.
Normalmente, você usa apenas as colunas com as melhores pontuações para criar seu modelo preditivo. Colunas com pontuações de seleção de recursos ruins podem ser deixadas no conjunto de dados e ignoradas quando você cria um modelo.
Como escolher uma métrica de seleção de recursos
O componente Seleção de recursos baseada em filtro fornece uma variedade de métricas para avaliar o valor das informações em cada coluna. Esta seção fornece uma descrição geral de cada métrica e como ela é aplicada. Você pode encontrar requisitos adicionais para usar cada métrica nas notas técnicas e nas instruções para configurar cada componente.
Correlação de Pearson
A estatística de correlação de Pearson, ou coeficiente de correlação de Pearson, também é conhecida em modelos estatísticos como o
rvalor. Para quaisquer duas variáveis, ele retorna um valor que indica a força da correlação.O coeficiente de correlação de Pearson é calculado tomando a covariância de duas variáveis e dividindo pelo produto de seus desvios-padrão. Mudanças de escala nas duas variáveis não afetam o coeficiente.
Chi quadrado
O teste qui-quadrado bidirecional é um método estatístico que mede o quão próximos os valores esperados estão dos resultados reais. O método assume que as variáveis são aleatórias e extraídas de uma amostra adequada de variáveis independentes. A estatística qui-quadrado resultante indica quão longe os resultados estão do resultado esperado (aleatório).
Gorjeta
Se você precisar de uma opção diferente para o método de seleção de recursos personalizados, use o componente Executar Script R.
Como configurar a seleção de recursos baseada em filtro
Você escolhe uma métrica estatística padrão. O componente calcula a correlação entre um par de colunas: a coluna do rótulo e uma coluna de feição.
Adicione o componente Seleção de recursos baseada em filtro ao seu pipeline. Você pode encontrá-lo na categoria Seleção de recursos no designer.
Conecte um conjunto de dados de entrada que contenha pelo menos duas colunas que são recursos potenciais.
Para garantir que uma coluna seja analisada e uma pontuação de recurso seja gerada, use o componente Editar metadados para definir o atributo IsFeature .
Importante
Certifique-se de que as colunas que você está fornecendo como entrada são recursos potenciais. Por exemplo, uma coluna que contém um único valor não tem valor de informação.
Se você sabe que algumas colunas fariam recursos incorretos, você pode removê-las da seleção de colunas. Você também pode usar o componente Editar metadados para sinalizá-los como categóricos.
Para o método de pontuação de recursos, escolha um dos seguintes métodos estatísticos estabelecidos para usar no cálculo de pontuações.
Método Requisitos Correlação de Pearson O rótulo pode ser texto ou numérico. Os recursos devem ser numéricos. Chi quadrado Os rótulos e recursos podem ser de texto ou numéricos. Use este método para calcular a importância do recurso para duas colunas categóricas. Gorjeta
Se você alterar a métrica selecionada, todas as outras seleções serão redefinidas. Portanto, certifique-se de definir essa opção primeiro.
Selecione a opção Operar somente em colunas de feição para gerar uma pontuação somente para colunas que foram marcadas anteriormente como recursos.
Se você desmarcar essa opção, o componente criará uma pontuação para qualquer coluna que atenda aos critérios, até o número de colunas especificado em Número de recursos desejados.
Em Coluna de destino, selecione Iniciar seletor de coluna para escolher a coluna de rótulo por nome ou por seu índice. (Os índices são baseados em um.)
Uma coluna de rótulo é necessária para todos os métodos que envolvem correlação estatística. O componente retorna um erro em tempo de design se você escolher nenhuma coluna de rótulo ou várias colunas de rótulo.Em Número de recursos desejados, insira o número de colunas de recursos que você deseja retornar como resultado:
O número mínimo de recursos que você pode especificar é um, mas recomendamos que você aumente esse valor.
Se o número especificado de recursos desejados for maior do que o número de colunas no conjunto de dados, todos os recursos serão retornados. Mesmo recursos com pontuação zero são retornados.
Se você especificar menos colunas de resultados do que colunas de recursos, os recursos serão classificados por pontuação decrescente. Apenas os principais recursos são retornados.
Envie o pipeline.
Importante
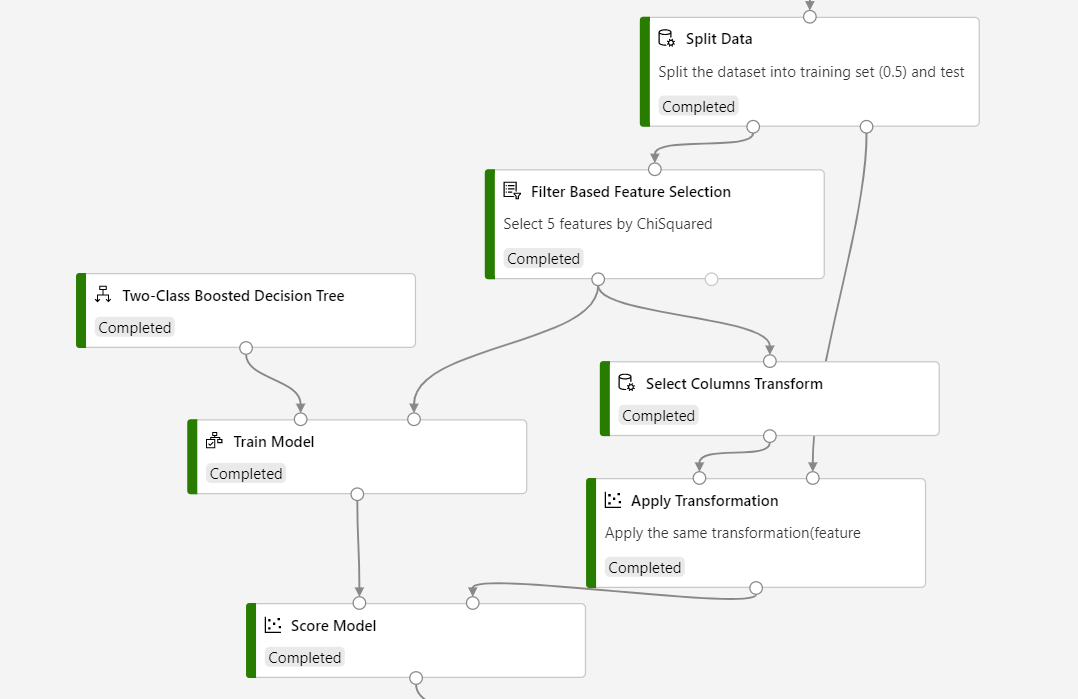
Se você for usar a Seleção de Recursos Baseada em Filtro na inferência, precisará usar Selecionar Transformação de Colunas para armazenar o resultado selecionado do recurso e Aplicar Transformação para aplicar a transformação do recurso selecionado ao conjunto de dados de pontuação.
Consulte a captura de tela a seguir para criar seu pipeline, para garantir que as seleções de coluna sejam as mesmas para o processo de pontuação.
Resultados
Após a conclusão do processamento:
Para ver uma lista completa das colunas de recursos analisados e suas pontuações, clique com o botão direito do mouse no componente e selecione Visualizar.
Para exibir o conjunto de dados com base nos critérios de seleção de recursos, clique com o botão direito do mouse no componente e selecione Visualizar.
Se o conjunto de dados contiver menos colunas do que o esperado, verifique as configurações do componente. Verifique também os tipos de dados das colunas fornecidas como entrada. Por exemplo, se você definir Número de recursos desejados como 1, o conjunto de dados de saída conterá apenas duas colunas: a coluna de rótulo e a coluna de recurso mais bem classificada.
Notas técnicas
Detalhes da implementação
Se você usar a correlação de Pearson em um recurso numérico e um rótulo categórico, a pontuação do recurso será calculada da seguinte maneira:
Para cada nível na coluna categórica, calcule a média condicional da coluna numérica.
Correlacione a coluna de médias condicionais com a coluna numérica.
Requisitos
Uma pontuação de seleção de recursos não pode ser gerada para nenhuma coluna designada como coluna Rótulo ou Pontuação .
Se você tentar usar um método de pontuação com uma coluna de um tipo de dados que o método não suporta, o componente gerará um erro. Ou, uma pontuação zero será atribuída à coluna.
Se uma coluna contiver valores lógicos (verdadeiro/falso), eles serão processados como
True = 1eFalse = 0.Uma coluna não pode ser um recurso se tiver sido designada como um Rótulo ou uma Pontuação.
Como os valores em falta são tratados
Não é possível especificar como coluna de destino (rótulo) qualquer coluna que tenha todos os valores ausentes.
Se uma coluna contiver valores ausentes, o componente os ignorará quando estiver calculando a pontuação da coluna.
Se uma coluna designada como coluna de feição tiver todos os valores ausentes, o componente atribuirá uma pontuação zero.
Próximos passos
Consulte o conjunto de componentes disponíveis para o Azure Machine Learning.