Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este artigo descreve um componente no designer do Azure Machine Learning.
Use esse componente para carregar dados em um pipeline de aprendizado de máquina a partir de serviços de dados em nuvem existentes.
Nota
Todas as funcionalidades fornecidas por esse componente podem ser feitas pelo armazenamento de dados e conjuntos de dados na página inicial do espaço de trabalho. Recomendamos que você use o armazenamento de dados e o conjunto de dados, que incluem recursos adicionais, como monitoramento de dados. Para saber mais, consulte o artigo Como acessar dados e Como registrar conjuntos de dados. Depois de registrar um conjunto de dados, você pode encontrá-lo na categoria Datasets -> na interface do designer. Este componente é reservado para usuários do Studio (clássico) para uma experiência familiar.
O componente Importar dados suporta dados de leitura das seguintes fontes:
- URL via HTTP
- Armazenamentos na nuvem do Azure através de Datastores)
- Contentor de Blobs do Azure
- Partilha de Ficheiros do Azure
- Azure Data Lake
- Azure Data Lake Gen2
- Base de Dados SQL do Azure
- Azure PostgreSQL
Antes de usar o armazenamento em nuvem, você deve registrar um armazenamento de dados em seu espaço de trabalho do Azure Machine Learning primeiro. Para obter mais informações, consulte Como acessar dados.
Depois de definir os dados desejados e conectar-se à fonte, Importar Dados infere o tipo de dados de cada coluna com base nos valores que ela contém e carrega os dados no pipeline do designer. A saída de Import Data é um conjunto de dados que pode ser usado com qualquer pipeline de designer.
Se os dados de origem forem alterados, você poderá atualizar o conjunto de dados e adicionar novos dados executando novamente Importar Dados.
Aviso
Se seu espaço de trabalho estiver em uma rede virtual, você deverá configurar seus armazenamentos de dados para usar os recursos de visualização de dados do designer. Para obter mais informações sobre como usar armazenamentos de dados e conjuntos de dados em uma rede virtual, consulte Usar o estúdio do Azure Machine Learning em uma rede virtual do Azure.
Como configurar a importação de dados
Adicione o componente Importar dados ao seu pipeline. Você pode encontrar esse componente na categoria Entrada e saída de dados no designer.
Selecione o componente para abrir o painel direito.
Selecione Fonte de dados e escolha o tipo de fonte de dados. Pode ser HTTP ou armazenamento de dados.
Se você escolher armazenamento de dados, poderá selecionar armazenamentos de dados existentes que já estão registrados em seu espaço de trabalho do Azure Machine Learning ou criar um novo armazenamento de dados. Em seguida, defina o caminho dos dados a serem importados no armazenamento de dados. Você pode facilmente navegar pelo caminho selecionando Procurar caminho.
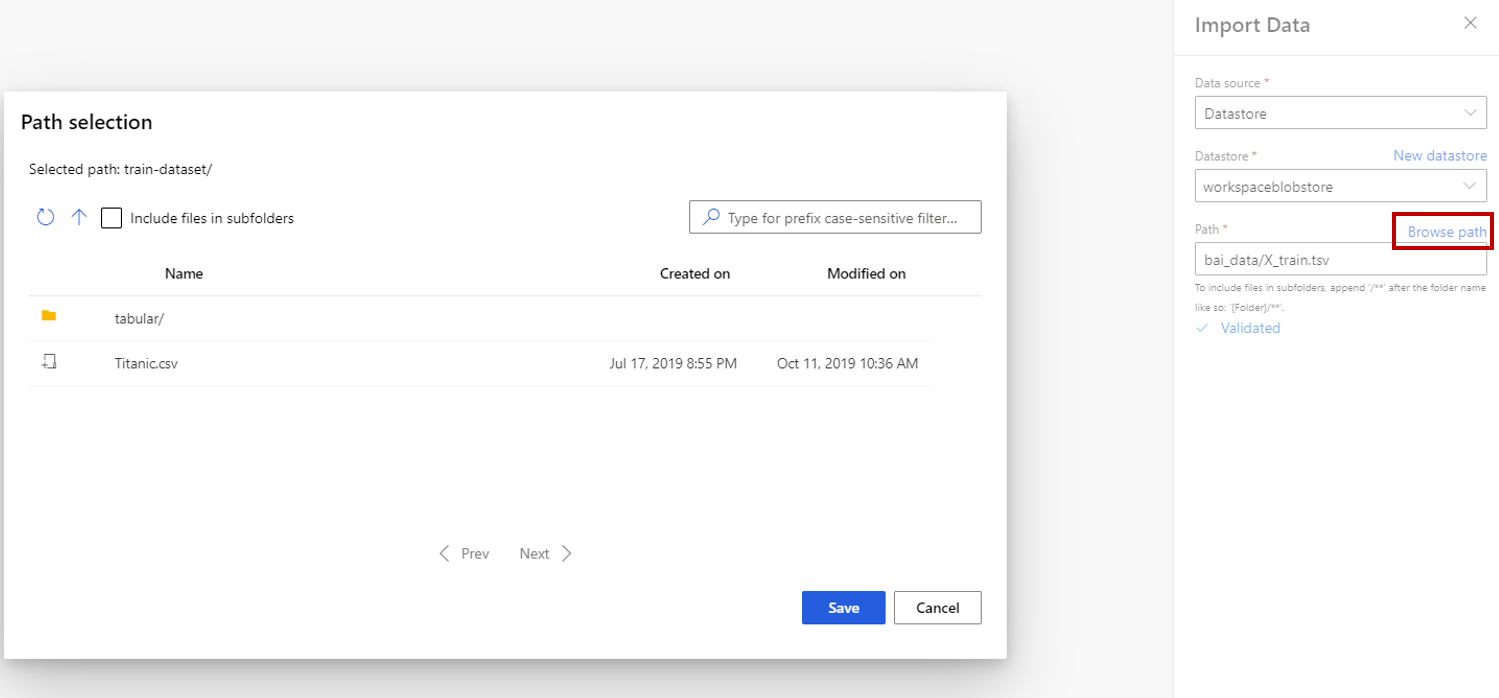
Nota
O componente Importar dados destina-se apenas a dados tabulares . Se você quiser importar vários arquivos de dados tabulares uma vez, isso requer as seguintes condições, caso contrário, ocorrerão erros:
- Para incluir todos os arquivos de dados na pasta, você precisa inserir
folder_name/**para Path. - Todos os arquivos de dados devem ser codificados em unicode-8.
- Todos os arquivos de dados devem ter os mesmos números de coluna e nomes de coluna.
- O resultado da importação de vários arquivos de dados é concatenar todas as linhas de vários arquivos em ordem.
- Para incluir todos os arquivos de dados na pasta, você precisa inserir
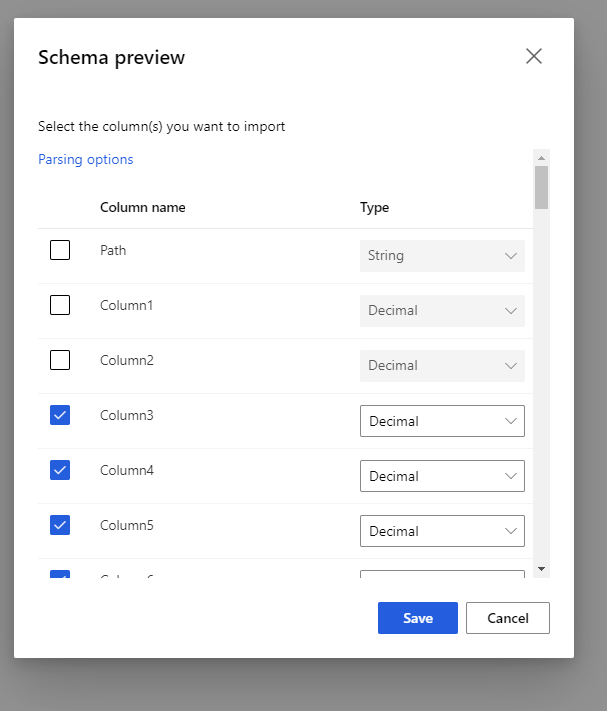
Selecione o esquema de visualização para filtrar as colunas que você deseja incluir. Você também pode definir configurações avançadas, como Delimitador em Opções de análise.
A caixa de seleção, Regenerar saída, decide se o componente deve ser executado para regenerar a saída em tempo de execução.
É por padrão desmarcado, o que significa que se o componente tiver sido executado com os mesmos parâmetros anteriormente, o sistema reutiliza a saída da última execução para reduzir o tempo de execução.
Se for selecionado, o sistema executa o componente novamente para regenerar a saída. Portanto, selecione essa opção quando os dados subjacentes no armazenamento forem atualizados, isso pode ajudar a obter os dados mais recentes.
Envie o pipeline.
Quando Import Data carrega os dados no designer, ele infere o tipo de dados de cada coluna com base nos valores que ela contém, numéricos ou categóricos.
Se um cabeçalho estiver presente, o cabeçalho será usado para nomear as colunas do conjunto de dados de saída.
Se não houver cabeçalhos de coluna existentes nos dados, novos nomes de coluna serão gerados usando o formato col1, col2,... , Coln*.

Resultados
Quando a importação for concluída, clique com o botão direito do mouse no conjunto de dados de saída e selecione Visualizar para ver se os dados foram importados com êxito.
Se você quiser salvar os dados para reutilização, em vez de importar um novo conjunto de dados cada vez que o pipeline for executado, selecione o ícone Registrar conjunto de dados na guia Saídas+logs no painel direito do componente. Escolha um nome para o conjunto de dados. O conjunto de dados salvo preserva os dados no momento de salvar. O conjunto de dados não é atualizado quando o pipeline é executado novamente, mesmo que o conjunto de dados no pipeline seja alterado. Isso pode ser útil para tirar instantâneos de dados.
Depois de importar os dados, talvez seja necessário alguns preparativos adicionais para modelagem e análise:
Use Editar metadados para alterar nomes de colunas, manipular uma coluna como um tipo de dados diferente ou indicar que algumas colunas são rótulos ou recursos.
Use Selecionar Colunas no Conjunto de Dados para selecionar um subconjunto de colunas a serem transformadas ou usadas na modelagem. As colunas transformadas ou removidas podem ser facilmente unidas ao conjunto de dados original usando o componente Adicionar colunas .
Use Partição e Amostra para dividir o conjunto de dados, executar amostragem ou obter as n linhas superiores.
Limitações
Devido à limitação de acesso ao armazenamento de dados, se o pipeline de inferência contiver o componente Importar Dados , ele será removido automaticamente quando implantado no ponto de extremidade em tempo real.
Próximos passos
Consulte o conjunto de componentes disponíveis para o Azure Machine Learning.