Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este artigo descreve como o aprendizado de máquina automatizado (AutoML) no Azure Machine Learning procura e seleciona modelos de previsão. Se você estiver interessado em saber mais sobre a metodologia de previsão no AutoML, consulte Visão geral dos métodos de previsão no AutoML. Para explorar exemplos de treinamento para modelos de previsão no AutoML, consulte Configurar o AutoML para treinar um modelo de previsão de séries cronológicas com o SDK e a CLI.
Varredura de modelos no AutoML
A tarefa central do AutoML é treinar e avaliar vários modelos e escolher o melhor em relação à métrica primária dada. A palavra "modelo", neste caso, refere-se tanto à classe de modelo, como ARIMA ou Random Forest, quanto às configurações específicas de hiperparâmetros que distinguem modelos dentro de uma classe. Por exemplo, ARIMA refere-se a uma classe de modelos que compartilham um modelo matemático e um conjunto de pressupostos estatísticos. O treinamento, ou ajuste, de um modelo ARIMA requer uma lista de inteiros positivos que especificam a forma matemática precisa do modelo. Estes valores são os hiperparâmetros. Os modelos ARIMA(1, 0, 1) e ARIMA(2, 1, 2) têm a mesma classe, mas hiperparâmetros diferentes. Essas definições podem ser ajustadas separadamente com os dados de treinamento e avaliadas umas em relação às outras. O AutoML pesquisa, ou varre, em diferentes classes de modelo e dentro de classes, variando os hiperparâmetros.
Métodos de varredura de hiperparâmetros
A tabela a seguir mostra os diferentes métodos de varredura de hiperparâmetros que o AutoML usa para diferentes classes de modelo:
| Grupo de classes modelo | Tipo de modelo | Método de varredura de hiperparâmetros |
|---|---|---|
| Ingênuo, Sazonal Ingênuo, Média, Sazonal Médio | Séries cronológicas | Sem varredura dentro da classe devido à simplicidade do modelo |
| Alisamento Exponencial, ARIMA(X) | Séries cronológicas | Pesquisa de grade para varredura dentro da classe |
| Profeta | Regressão | Sem varredura dentro da sala de aula |
| Linear SGD, LARS LASSO, Rede Elástica, K Vizinhos Mais Próximos, Árvore Decisão, Floresta Aleatória, Árvores Extremamente Aleatórias, Árvores Impulsionadas por Gradiente, LightGBM, XGBoost | Regressão | O serviço de recomendação de modelo do AutoML explora dinamicamente espaços de hiperparâmetros |
| PrevisãoTCN | Regressão | Lista estática de modelos seguida de pesquisa aleatória sobre o tamanho da rede, taxa de abandono e taxa de aprendizagem |
Para obter uma descrição dos diferentes tipos de modelo, consulte a seção Modelos de previsão no AutoML do artigo de visão geral dos métodos de previsão.
A quantidade de varredura pelo AutoML depende da configuração do trabalho de previsão. Você pode especificar os critérios de parada como um limite de tempo ou um limite para o número de ensaios, ou o número equivalente de modelos. A lógica de terminação antecipada pode ser usada em ambos os casos para parar a varredura se a métrica primária não estiver melhorando.
Seleção de modelos no AutoML
O AutoML segue um processo trifásico para procurar e selecionar modelos de previsão:
Fase 1: Varrer os modelos de séries cronológicas e selecionar o melhor modelo de cada classe usando métodos de estimativa de máxima verossimilhança.
Fase 2: Varrer os modelos de regressão e classificá-los, juntamente com os melhores modelos de séries temporais da fase 1, de acordo com seus valores métricos primários dos conjuntos de validação.
Fase 3: Construa um modelo de conjunto a partir dos modelos mais bem classificados, calcule sua métrica de validação e classifique-o com os outros modelos.
O modelo com o valor métrico mais bem classificado no final da fase 3 é designado o melhor modelo.
Importante
Na Fase 3, o AutoML sempre calcula métricas em dados fora da amostra que não são usados para ajustar os modelos. Esta abordagem ajuda a proteger contra o excesso de ajuste.
Configurações de validação
O AutoML tem duas configurações de validação: validação cruzada e dados de validação explícitos.
No caso de validação cruzada, o AutoML usa a configuração de entrada para criar divisões de dados em dobras de treinamento e validação. A ordem do tempo deve ser preservada nessas divisões. O AutoML usa a chamada Validação Cruzada de Origem Contínua, que divide a série em dados de treinamento e validação usando um ponto de tempo de origem. Deslizar a origem no tempo gera as dobras de validação cruzada. Cada dobra de validação contém o horizonte seguinte de observações imediatamente após a posição da origem para a dobra dada. Essa estratégia preserva a integridade dos dados das séries cronológicas e reduz o risco de vazamento de informações.
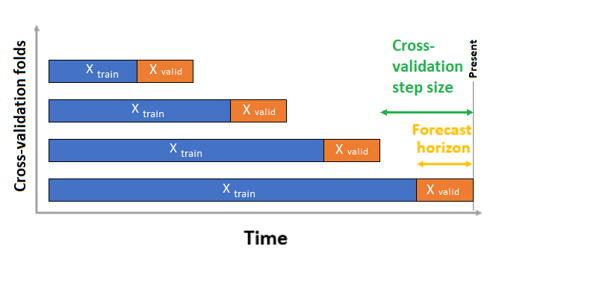
O AutoML segue o procedimento habitual de validação cruzada, treinando um modelo separado em cada dobra e calculando a média das métricas de validação de todas as dobras.
A validação cruzada para trabalhos de previsão é configurada definindo o número de dobras de validação cruzada e, opcionalmente, o número de períodos de tempo entre duas dobras de validação cruzada consecutivas. Para obter mais informações e um exemplo de configuração da validação cruzada para previsão, consulte Configurações personalizadas de validação cruzada.
Você também pode trazer seus próprios dados de validação. Para obter mais informações, consulte Configurar dados de treinamento, validação, validação cruzada e teste no AutoML (SDK v1).