Configurar o AutoML para treinar um modelo de previsão de séries cronológicas com SDK e CLI
APLICA-SE A: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Neste artigo, você aprenderá como configurar o AutoML para previsão de séries cronológicas com o ML automatizado do Azure Machine Learning no SDK Python do Azure Machine Learning.
Para tal, terá de:
- Preparar dados para treinamento.
- Configure parâmetros específicos de séries cronológicas em um trabalho de previsão.
- Orquestre treinamento, inferência e avaliação de modelos usando componentes e pipelines.
Para obter uma experiência de baixo código, consulte o Tutorial: Prever a demanda com aprendizado de máquina automatizado para obter um exemplo de previsão de séries cronológicas usando ML automatizado no estúdio de Aprendizado de Máquina do Azure.
O AutoML usa modelos padrão de aprendizado de máquina juntamente com modelos de séries temporais bem conhecidos para criar previsões. Nossa abordagem incorpora informações históricas sobre a variável de destino, recursos fornecidos pelo usuário nos dados de entrada e recursos projetados automaticamente. Em seguida, os algoritmos de pesquisa de modelos trabalham para encontrar um modelo com a melhor precisão preditiva. Para obter mais detalhes, consulte nossos artigos sobre metodologia de previsão e pesquisa de modelos.
Pré-requisitos
Para este artigo você precisa,
Uma área de trabalho do Azure Machine Learning. Para criar o espaço de trabalho, consulte Criar recursos do espaço de trabalho.
A capacidade de iniciar trabalhos de treinamento AutoML. Siga o guia de instruções para configurar o AutoML para obter detalhes.
Dados de formação e validação
Os dados de entrada para previsão de AutoML devem conter séries temporais válidas em formato tabular. Cada variável deve ter sua própria coluna correspondente na tabela de dados. O AutoML requer pelo menos duas colunas: uma coluna de tempo que representa o eixo do tempo e a coluna de destino, que é a quantidade a ser prevista. Outras colunas podem servir como preditores. Para obter mais detalhes, consulte como o AutoML usa seus dados.
Importante
Ao treinar um modelo para previsão de valores futuros, certifique-se de que todos os recursos usados no treinamento possam ser usados ao executar previsões para o horizonte pretendido.
Por exemplo, um recurso para o preço atual das ações poderia aumentar enormemente a precisão do treinamento. No entanto, se você pretende prever com um horizonte longo, talvez não seja capaz de prever com precisão os valores futuros de ações correspondentes a pontos de séries cronológicas futuras, e a precisão do modelo pode ser prejudicada.
Os trabalhos de previsão do AutoML exigem que seus dados de treinamento sejam representados como um objeto MLTable . Um MLTable especifica uma fonte de dados e etapas para carregar os dados. Para obter mais informações e casos de uso, consulte o guia de instruções do MLTable. Como um exemplo simples, suponha que seus dados de treinamento estejam contidos em um arquivo CSV em um diretório local, ./train_data/timeseries_train.csv.
Você pode criar um MLTable usando o SDK do Python mltable como no exemplo a seguir:
import mltable
paths = [
{'file': './train_data/timeseries_train.csv'}
]
train_table = mltable.from_delimited_files(paths)
train_table.save('./train_data')
Esse código cria um novo arquivo, ./train_data/MLTable, que contém o formato do arquivo e instruções de carregamento.
Agora você define um objeto de dados de entrada, que é necessário para iniciar um trabalho de treinamento, usando o SDK Python do Azure Machine Learning da seguinte maneira:
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml import Input
# Training MLTable defined locally, with local data to be uploaded
my_training_data_input = Input(
type=AssetTypes.MLTABLE, path="./train_data"
)
Você especifica os dados de validação de maneira semelhante, criando um MLTable e especificando uma entrada de dados de validação. Como alternativa, se você não fornecer dados de validação, o AutoML criará automaticamente divisões de validação cruzada dos dados de treinamento para usar na seleção de modelos. Consulte o nosso artigo sobre a seleção de modelos de previsão para obter mais detalhes. Consulte também os requisitos de comprimento de dados de treinamento para obter detalhes sobre a quantidade de dados de treinamento necessária para treinar com êxito um modelo de previsão.
Saiba mais sobre como o AutoML aplica a validação cruzada para evitar ajustes excessivos.
Computação para executar a experimentação
O AutoML usa o Azure Machine Learning Compute, que é um recurso de computação totalmente gerenciado, para executar o trabalho de treinamento. No exemplo a seguir, um cluster de computação chamado cpu-compute é criado:
from azure.ai.ml.entities import AmlCompute
# specify aml compute name.
cpu_compute_target = "cpu-cluster"
try:
ml_client.compute.get(cpu_compute_target)
except Exception:
print("Creating a new cpu compute target...")
compute = AmlCompute(
name=cpu_compute_target, size="STANDARD_D2_V2", min_instances=0, max_instances=4
)
ml_client.compute.begin_create_or_update(compute).result()Configurar experiência
Você usa as funções de fábrica automl para configurar trabalhos de previsão no Python SDK. O exemplo a seguir mostra como criar um trabalho de previsão definindo a métrica primária e definindo limites na execução de treinamento:
from azure.ai.ml import automl
# note that the below is a code snippet -- you might have to modify the variable values to run it successfully
forecasting_job = automl.forecasting(
compute="cpu-compute",
experiment_name="sdk-v2-automl-forecasting-job",
training_data=my_training_data_input,
target_column_name=target_column_name,
primary_metric="normalized_root_mean_squared_error",
n_cross_validations="auto",
)
# Limits are all optional
forecasting_job.set_limits(
timeout_minutes=120,
trial_timeout_minutes=30,
max_concurrent_trials=4,
)
Previsão de configurações de trabalho
As tarefas de previsão têm muitas configurações específicas para a previsão. As configurações mais básicas são o nome da coluna de tempo nos dados de treinamento e o horizonte de previsão.
Use os métodos ForecastingJob para definir estas configurações:
# Forecasting specific configuration
forecasting_job.set_forecast_settings(
time_column_name=time_column_name,
forecast_horizon=24
)
O nome da coluna de tempo é uma configuração obrigatória e você geralmente deve definir o horizonte de previsão de acordo com seu cenário de previsão. Se os dados contiverem várias séries temporais, você poderá especificar os nomes das colunas de ID da série temporal. Estas colunas, quando agrupadas, definem as séries individuais. Por exemplo, suponha que você tenha dados que consistem em vendas por hora de diferentes lojas e marcas. O exemplo a seguir mostra como definir as colunas de ID de série temporal assumindo que os dados contêm colunas chamadas "store" e "brand":
# Forecasting specific configuration
# Add time series IDs for store and brand
forecasting_job.set_forecast_settings(
..., # other settings
time_series_id_column_names=['store', 'brand']
)
O AutoML tenta detetar automaticamente colunas de ID de séries cronológicas em seus dados, se nenhuma for especificada.
Outras configurações são opcionais e revisadas na próxima seção.
Configurações opcionais do trabalho de previsão
Configurações opcionais estão disponíveis para tarefas de previsão, como habilitar o aprendizado profundo e especificar uma agregação de janela contínua de destino. Uma lista completa de parâmetros está disponível na documentação de referência de previsão.
Configurações de pesquisa de modelo
Há duas configurações opcionais que controlam o espaço do modelo onde o AutoML procura o melhor modelo allowed_training_algorithms e blocked_training_algorithms. Para restringir o espaço de pesquisa a um determinado conjunto de classes de modelo, use o allowed_training_algorithms parâmetro como no exemplo a seguir:
# Only search ExponentialSmoothing and ElasticNet models
forecasting_job.set_training(
allowed_training_algorithms=["ExponentialSmoothing", "ElasticNet"]
)
Nesse caso, o trabalho de previsão pesquisa apenas as classes de modelo Exponential Smoothing e Elastic Net. Para remover um determinado conjunto de classes de modelo do espaço de pesquisa, use o blocked_training_algorithms como no exemplo a seguir:
# Search over all model classes except Prophet
forecasting_job.set_training(
blocked_training_algorithms=["Prophet"]
)
Agora, o trabalho procura em todas as classes de modelo, exceto Prophet. Para obter uma lista dos nomes de modelos de previsão aceitos em allowed_training_algorithms e blocked_training_algorithms, consulte a documentação de referência das propriedades de treinamento. Ou, mas não ambos, de e blocked_training_algorithms pode ser aplicado a uma corrida de allowed_training_algorithms treinamento.
Habilite o aprendizado profundo
O AutoML é fornecido com um modelo personalizado de rede neural profunda (DNN) chamado TCNForecaster. Este modelo é uma rede convolucional temporal, ou TCN, que aplica métodos comuns de tarefas de imagem à modelagem de séries temporais. Ou seja, convoluções "causais" unidimensionais formam a espinha dorsal da rede e permitem que o modelo aprenda padrões complexos ao longo de longas durações na história do treinamento. Para mais detalhes, consulte o nosso artigo TCNForecaster.
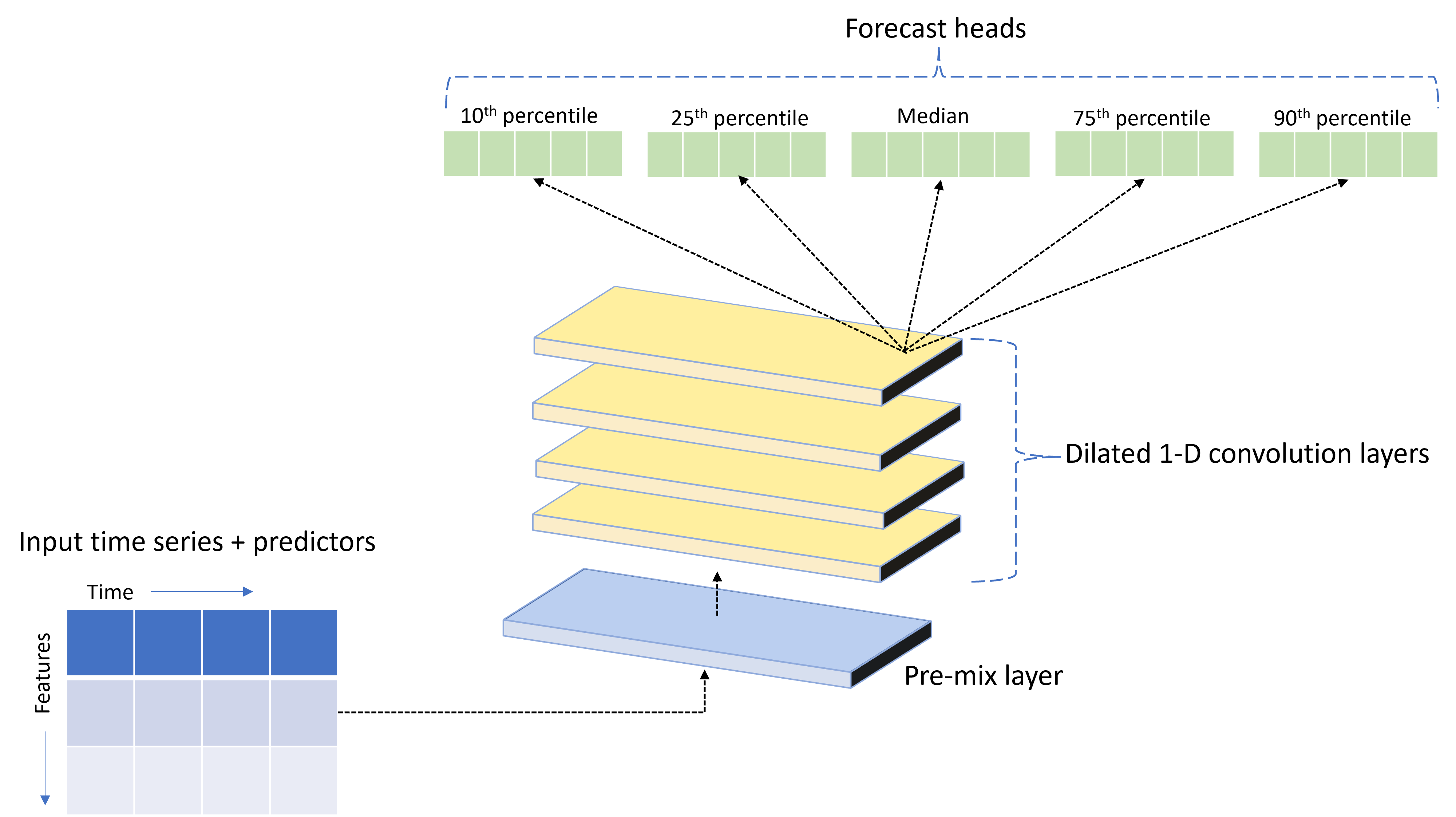
O TCNForecaster geralmente alcança maior precisão do que os modelos de séries temporais padrão quando há milhares ou mais observações no histórico de treinamento. No entanto, também leva mais tempo para treinar e varrer os modelos TCNForecaster devido à sua maior capacidade.
Você pode habilitar o TCNForecaster no AutoML definindo o enable_dnn_training sinalizador na configuração de treinamento da seguinte maneira:
# Include TCNForecaster models in the model search
forecasting_job.set_training(
enable_dnn_training=True
)
Por padrão, o treinamento TCNForecaster é limitado a um único nó de computação e uma única GPU, se disponível, por avaliação do modelo. Para cenários de dados grandes, recomendamos distribuir cada avaliação do TCNForecaster em vários núcleos/GPUs e nós. Consulte nossa seção de artigo de treinamento distribuído para obter mais informações e exemplos de código.
Para habilitar a DNN para um experimento AutoML criado no estúdio do Azure Machine Learning, consulte as configurações de tipo de tarefa no tutorial da interface do usuário do estúdio.
Nota
- Quando você habilita a DNN para experimentos criados com o SDK, as melhores explicações de modelo são desabilitadas.
- O suporte DNN para previsão no Automated Machine Learning não é suportado para execuções iniciadas no Databricks.
- Os tipos de computação de GPU são recomendados quando o treinamento DNN está habilitado
Recursos de atraso e janela rolante
Os valores recentes da meta são muitas vezes características impactantes em um modelo de previsão. Assim, o AutoML pode criar recursos de agregação de janelas com atraso de tempo e rolagem para potencialmente melhorar a precisão do modelo.
Considere um cenário de previsão da procura de energia em que estejam disponíveis dados meteorológicos e a procura histórica. A tabela mostra a engenharia de recursos resultante que ocorre quando a agregação de janelas é aplicada nas três horas mais recentes. As colunas para mínimo, máximo e soma são geradas em uma janela deslizante de três horas com base nas configurações definidas. Por exemplo, para a observação válida em 8 de setembro de 2017 4:00am, os valores máximo, mínimo e soma são calculados usando os valores de demanda para 8 de setembro de 2017 1:00AM - 3:00AM. Essa janela de três horas se desloca para preencher os dados das linhas restantes. Para obter mais detalhes e exemplos, consulte o artigo do recurso de atraso.

Você pode habilitar os recursos de agregação de janela de atraso e rolagem para o destino definindo o tamanho da janela rolante, que era três no exemplo anterior, e as ordens de atraso que você deseja criar. Você também pode ativar atrasos para recursos com a feature_lags configuração. No exemplo a seguir, definimos todas essas configurações para auto que o AutoML determine automaticamente as configurações analisando a estrutura de correlação de seus dados:
forecasting_job.set_forecast_settings(
..., # other settings
target_lags='auto',
target_rolling_window_size='auto',
feature_lags='auto'
)
Manuseamento em séries curtas
O ML automatizado considera uma série temporal uma série curta se não houver pontos de dados suficientes para conduzir as fases de treinamento e validação do desenvolvimento do modelo. Consulte os requisitos de comprimento dos dados de treinamento para obter mais detalhes sobre os requisitos de comprimento.
AutoML tem várias ações que pode tomar para séries curtas. Essas ações são configuráveis com a short_series_handling_config configuração. O valor padrão é "auto". A tabela a seguir descreve as configurações:
| Definição | Descrição |
|---|---|
auto |
O valor padrão para manipulação de séries curtas. - Se todas as séries forem curtas, preencha os dados. - Se nem todas as séries são curtas, abandone as séries curtas. |
pad |
Se short_series_handling_config = pad, então o ML automatizado adiciona valores aleatórios a cada série curta encontrada. A seguir estão listados os tipos de coluna e com o que eles são acolchoados: - Colunas de objetos com NaNs - Colunas numéricas com 0 - Colunas booleanas/lógicas com Falso - A coluna alvo é acolchoada com ruído branco. |
drop |
Se short_series_handling_config = drop, então o ML automatizado descarta a série curta, e ele não será usado para treinamento ou previsão. As previsões para estas séries vão regressar a NaN's. |
None |
Nenhuma série é acolchoada ou descartada |
No exemplo a seguir, definimos a manipulação de séries curtas para que todas as séries curtas sejam acolchoadas com o comprimento mínimo:
forecasting_job.set_forecast_settings(
..., # other settings
short_series_handling_config='pad'
)
Aviso
O preenchimento pode afetar a precisão do modelo resultante, uma vez que estamos introduzindo dados artificiais para evitar falhas de treinamento. Se muitas das séries são curtas, então você também pode ver algum impacto nos resultados de explicabilidade
Frequência & agregação de dados de destino
Use as opções de frequência e agregação de dados para evitar falhas causadas por dados irregulares. Seus dados são irregulares se não seguirem uma cadência definida no tempo, como por hora ou por dia. Os dados dos pontos de venda são um bom exemplo de dados irregulares. Nesses casos, o AutoML pode agregar seus dados para uma frequência desejada e, em seguida, criar um modelo de previsão a partir dos agregados.
Você precisa definir as frequency configurações e target_aggregate_function para lidar com dados irregulares. A configuração de frequência aceita cadeias de caracteres Pandas DateOffset como entrada. Os valores suportados para a função de agregação são:
| Function | Description |
|---|---|
sum |
Soma dos valores-alvo |
mean |
Média ou média dos valores-alvo |
min |
Valor mínimo de um alvo |
max |
Valor máximo de um alvo |
- Os valores da coluna de destino são agregados de acordo com a operação especificada. Normalmente, a soma é apropriada para a maioria dos cenários.
- As colunas de previsão numérica em seus dados são agregadas por soma, média, valor mínimo e valor máximo. Como resultado, o ML automatizado gera novas colunas sufixadas com o nome da função de agregação e aplica a operação de agregação selecionada.
- Para colunas de previsão categórica, os dados são agregados por modo, a categoria mais proeminente na janela.
- As colunas de previsão de data são agregadas por valor mínimo, valor máximo e modo.
O exemplo a seguir define a frequência como horária e a função de agregação como soma:
# Aggregate the data to hourly frequency
forecasting_job.set_forecast_settings(
..., # other settings
frequency='H',
target_aggregate_function='sum'
)
Configurações personalizadas de validação cruzada
Há duas configurações personalizáveis que controlam a validação cruzada para trabalhos de previsão: o número de dobras n_cross_validationse o tamanho da etapa que define o deslocamento de tempo entre dobras, cv_step_size. Consulte a seleção do modelo de previsão para obter mais informações sobre o significado desses parâmetros. Por padrão, o AutoML define ambas as configurações automaticamente com base nas características dos seus dados, mas os usuários avançados podem querer defini-las manualmente. Por exemplo, suponha que você tenha dados de vendas diários e queira que sua configuração de validação consista em cinco dobras com um deslocamento de sete dias entre dobras adjacentes. O exemplo de código a seguir mostra como defini-los:
from azure.ai.ml import automl
# Create a job with five CV folds
forecasting_job = automl.forecasting(
..., # other training parameters
n_cross_validations=5,
)
# Set the step size between folds to seven days
forecasting_job.set_forecast_settings(
..., # other settings
cv_step_size=7
)
Featurização personalizada
Por padrão, o AutoML aumenta os dados de treinamento com recursos projetados para aumentar a precisão dos modelos. Consulte engenharia de recursos automatizada para obter mais informações. Algumas das etapas de pré-processamento podem ser personalizadas usando a configuração de featurização do trabalho de previsão.
As personalizações suportadas para previsão estão na tabela a seguir:
| Personalização | Description | Opções |
|---|---|---|
| Atualização da finalidade da coluna | Substitua o tipo de recurso detetado automaticamente para a coluna especificada. | "Categórico", "DateTime", "Numérico" |
| Atualização dos parâmetros do transformador | Atualizar os parâmetros para o imputador especificado. | {"strategy": "constant", "fill_value": <value>}, {"strategy": "median"}, {"strategy": "ffill"} |
Por exemplo, suponha que você tenha um cenário de demanda de varejo em que os dados incluam preços, um sinalizador "em venda" e um tipo de produto. O exemplo a seguir mostra como você pode definir tipos e imputadores personalizados para esses recursos:
from azure.ai.ml.automl import ColumnTransformer
# Customize imputation methods for price and is_on_sale features
# Median value imputation for price, constant value of zero for is_on_sale
transformer_params = {
"imputer": [
ColumnTransformer(fields=["price"], parameters={"strategy": "median"}),
ColumnTransformer(fields=["is_on_sale"], parameters={"strategy": "constant", "fill_value": 0}),
],
}
# Set the featurization
# Ensure that product_type feature is interpreted as categorical
forecasting_job.set_featurization(
mode="custom",
transformer_params=transformer_params,
column_name_and_types={"product_type": "Categorical"},
)
Se você estiver usando o estúdio de Aprendizado de Máquina do Azure para seu experimento, veja como personalizar a featurização no estúdio.
Enviar um trabalho de previsão
Depois que todas as configurações forem definidas, você iniciará o trabalho de previsão da seguinte maneira:
# Submit the AutoML job
returned_job = ml_client.jobs.create_or_update(
forecasting_job
)
print(f"Created job: {returned_job}")
# Get a URL for the job in the AML studio user interface
returned_job.services["Studio"].endpoint
Depois que o trabalho for enviado, o AutoML provisionará recursos de computação, aplicará featurização e outras etapas de preparação aos dados de entrada e, em seguida, começará a varrer os modelos de previsão. Para obter mais detalhes, consulte nossos artigos sobre metodologia de previsão e pesquisa de modelos.
Orquestrando treinamento, inferência e avaliação com componentes e pipelines
Importante
Esta funcionalidade está atualmente em pré-visualização pública. Esta versão de pré-visualização é fornecida sem um contrato de nível de serviço e não a recomendamos para cargas de trabalho de produção. Algumas funcionalidades poderão não ser suportadas ou poderão ter capacidades limitadas.
Para obter mais informações, veja Termos Suplementares de Utilização para Pré-visualizações do Microsoft Azure.
Seu fluxo de trabalho de ML provavelmente requer mais do que apenas treinamento. Inferência ou recuperação de previsões de modelo em dados mais recentes e avaliação da precisão do modelo em um conjunto de testes com valores de destino conhecidos são outras tarefas comuns que você pode orquestrar no AzureML junto com trabalhos de treinamento. Para dar suporte a tarefas de inferência e avaliação, o AzureML fornece componentes, que são partes autônomas de código que executam uma etapa em um pipeline do AzureML.
No exemplo a seguir, recuperamos o código do componente de um registro do cliente:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Create a client for accessing assets in the AzureML preview registry
ml_client_registry = MLClient(
credential=credential,
registry_name="azureml-preview"
)
# Create a client for accessing assets in the AzureML preview registry
ml_client_metrics_registry = MLClient(
credential=credential,
registry_name="azureml"
)
# Get an inference component from the registry
inference_component = ml_client_registry.components.get(
name="automl_forecasting_inference",
label="latest"
)
# Get a component for computing evaluation metrics from the registry
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
Em seguida, definimos uma função de fábrica que cria pipelines orquestrando treinamento, inferência e computação métrica. Consulte a seção de configuração de treinamento para obter mais detalhes sobre as configurações de treinamento.
from azure.ai.ml import automl
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml.dsl import pipeline
@pipeline(description="AutoML Forecasting Pipeline")
def forecasting_train_and_evaluate_factory(
train_data_input,
test_data_input,
target_column_name,
time_column_name,
forecast_horizon,
primary_metric='normalized_root_mean_squared_error',
cv_folds='auto'
):
# Configure the training node of the pipeline
training_node = automl.forecasting(
training_data=train_data_input,
target_column_name=target_column_name,
primary_metric=primary_metric,
n_cross_validations=cv_folds,
outputs={"best_model": Output(type=AssetTypes.MLFLOW_MODEL)},
)
training_node.set_forecasting_settings(
time_column_name=time_column_name,
forecast_horizon=max_horizon,
frequency=frequency,
# other settings
...
)
training_node.set_training(
# training parameters
...
)
training_node.set_limits(
# limit settings
...
)
# Configure the inference node to make rolling forecasts on the test set
inference_node = inference_component(
test_data=test_data_input,
model_path=training_node.outputs.best_model,
target_column_name=target_column_name,
forecast_mode='rolling',
forecast_step=1
)
# Configure the metrics calculation node
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
ground_truth=inference_node.outputs.inference_output_file,
prediction=inference_node.outputs.inference_output_file,
evaluation_config=inference_node.outputs.evaluation_config_output_file
)
# return a dictionary with the evaluation metrics and the raw test set forecasts
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result,
"rolling_fcst_result": inference_node.outputs.inference_output_file
}
Agora, definimos entradas de dados de treinamento e teste assumindo que elas estão contidas em pastas locais e./test_data: ./train_data
my_train_data_input = Input(
type=AssetTypes.MLTABLE,
path="./train_data"
)
my_test_data_input = Input(
type=AssetTypes.URI_FOLDER,
path='./test_data',
)
Finalmente, construímos o pipeline, definimos seu cálculo padrão e enviamos o trabalho:
pipeline_job = forecasting_train_and_evaluate_factory(
my_train_data_input,
my_test_data_input,
target_column_name,
time_column_name,
forecast_horizon
)
# set pipeline level compute
pipeline_job.settings.default_compute = compute_name
# submit the pipeline job
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name
)
returned_pipeline_job
Uma vez enviado, o pipeline executa o treinamento AutoML, a inferência de avaliação contínua e o cálculo métrico em sequência. Você pode monitorar e inspecionar a execução na interface do usuário do estúdio. Quando a execução estiver concluída, as previsões contínuas e as métricas de avaliação podem ser baixadas para o diretório de trabalho local:
# Download the metrics json
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='metrics_result')
# Download the rolling forecasts
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='rolling_fcst_result')
Em seguida, você pode encontrar os resultados das métricas e ./named-outputs/metrics_results/evaluationResult/metrics.json as previsões, no formato de linhas JSON, em ./named-outputs/rolling_fcst_result/inference_output_file.
Para obter mais detalhes sobre a avaliação contínua, consulte nosso artigo de avaliação de modelo de previsão.
Previsão em escala: muitos modelos
Importante
Esta funcionalidade está atualmente em pré-visualização pública. Esta versão de pré-visualização é fornecida sem um contrato de nível de serviço e não a recomendamos para cargas de trabalho de produção. Algumas funcionalidades poderão não ser suportadas ou poderão ter capacidades limitadas.
Para obter mais informações, veja Termos Suplementares de Utilização para Pré-visualizações do Microsoft Azure.
Os muitos componentes de modelos no AutoML permitem treinar e gerenciar milhões de modelos em paralelo. Para obter mais informações sobre muitos conceitos de modelos, consulte a seção de artigo Muitos modelos.
Configuração de treinamento de muitos modelos
O componente de treinamento de muitos modelos aceita um arquivo de configuração de formato YAML das configurações de treinamento do AutoML. O componente aplica essas configurações a cada instância do AutoML que inicia. Este arquivo YAML tem a mesma especificação que o trabalho de previsão, além de parâmetros partition_column_names adicionais e allow_multi_partitions.
| Parâmetro | Description |
|---|---|
| partition_column_names | Nomes de colunas nos dados que, quando agrupados, definem as partições de dados. O componente de treinamento de muitos modelos lança um trabalho de treinamento independente em cada partição. |
| allow_multi_partitions | Um sinalizador opcional que permite treinar um modelo por partição quando cada partição contém mais de uma série temporal exclusiva. O valor padrão é False. |
O exemplo a seguir fornece um modelo de configuração:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:<cluster-name>
task: forecasting
primary_metric: normalized_root_mean_squared_error
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: date
time_series_id_column_names: ["state", "store"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
partition_column_names: ["state", "store"]
allow_multi_partitions: false
Em exemplos subsequentes, assumimos que a configuração é armazenada no caminho, ./automl_settings_mm.yml.
Pipeline de muitos modelos
Em seguida, definimos uma função de fábrica que cria pipelines para orquestração de muitos modelos de treinamento, inferência e computação métrica. Os parâmetros desta função de fábrica são detalhados na tabela a seguir:
| Parâmetro | Description |
|---|---|
| max_nodes | Número de nós de computação a serem usados no trabalho de treinamento |
| max_concurrency_per_node | Número de processos AutoML a serem executados em cada nó. Assim, a simultaneidade total de muitos trabalhos de modelos é max_nodes * max_concurrency_per_node. |
| parallel_step_timeout_in_seconds | Muitos modelos componente tempo limite dado em número de segundos. |
| retrain_failed_models | Sinalizador para permitir o retreinamento de modelos com falha. Isso é útil se você tiver feito execuções anteriores de muitos modelos que resultaram em trabalhos de AutoML com falha em algumas partições de dados. Quando esse sinalizador está habilitado, muitos modelos só iniciam trabalhos de treinamento para partições com falha anterior. |
| forecast_mode | Modo de inferência para avaliação do modelo. Os valores válidos são "recursive" e "rolling". Consulte o artigo de avaliação do modelo para obter mais informações. |
| forecast_step | Tamanho do passo para previsão contínua. Consulte o artigo de avaliação do modelo para obter mais informações. |
O exemplo a seguir ilustra um método de fábrica para construir muitos pipelines de treinamento e avaliação de modelos de modelos:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a many models training component
mm_train_component = ml_client_registry.components.get(
name='automl_many_models_training',
version='latest'
)
# Get a many models inference component
mm_inference_component = ml_client_registry.components.get(
name='automl_many_models_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML Many Models Forecasting Pipeline")
def many_models_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
compute_name,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
retrain_failed_model=False,
forecast_mode="rolling",
forecast_step=1
):
mm_train_node = mm_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
retrain_failed_model=retrain_failed_model,
compute_name=compute_name
)
mm_inference_node = mm_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=mm_train_node.outputs.run_output,
forecast_mode=forecast_mode,
forecast_step=forecast_step,
compute_name=compute_name
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=mm_inference_node.outputs.evaluation_data,
ground_truth=mm_inference_node.outputs.evaluation_data,
evaluation_config=mm_inference_node.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
Agora, construímos o pipeline através da função de fábrica, assumindo que os dados de treinamento e teste estão em pastas locais e./data/test, ./data/train respectivamente. Finalmente, definimos o cálculo padrão e enviamos o trabalho como no exemplo a seguir:
pipeline_job = many_models_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_mm.yml"
),
compute_name="<cluster name>"
)
pipeline_job.settings.default_compute = "<cluster name>"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
Após a conclusão do trabalho, as métricas de avaliação podem ser baixadas localmente usando o mesmo procedimento do pipeline de execução de treinamento único.
Veja também a previsão de demanda com muitos modelos de notebook para um exemplo mais detalhado.
Nota
Os muitos componentes de treinamento e inferência de modelos particionam condicionalmente seus dados de acordo com a configuração para partition_column_names que cada partição esteja em seu próprio arquivo. Este processo pode ser muito lento ou falhar quando os dados são muito grandes. Nesse caso, recomendamos particionar seus dados manualmente antes de executar muitos modelos de treinamento ou inferência.
Previsão em escala: séries temporais hierárquicas
Importante
Esta funcionalidade está atualmente em pré-visualização pública. Esta versão de pré-visualização é fornecida sem um contrato de nível de serviço e não a recomendamos para cargas de trabalho de produção. Algumas funcionalidades poderão não ser suportadas ou poderão ter capacidades limitadas.
Para obter mais informações, veja Termos Suplementares de Utilização para Pré-visualizações do Microsoft Azure.
Os componentes de séries temporais hierárquicas (HTS) no AutoML permitem treinar um grande número de modelos em dados com estrutura hierárquica. Para obter mais informações, consulte a seção de artigo HTS.
Configuração de treinamento HTS
O componente de treinamento HTS aceita um arquivo de configuração de formato YAML das configurações de treinamento AutoML. O componente aplica essas configurações a cada instância do AutoML que inicia. Este arquivo YAML tem a mesma especificação que o trabalho de previsão, além de parâmetros adicionais relacionados às informações de hierarquia:
| Parâmetro | Description |
|---|---|
| hierarchy_column_names | Uma lista de nomes de colunas nos dados que definem a estrutura hierárquica dos dados. A ordem das colunas nesta lista determina os níveis hierárquicos; O grau de agregação diminui com o índice de lista. Ou seja, a última coluna da lista define o nível folha (mais desagregada) da hierarquia. |
| hierarchy_training_level | O nível de hierarquia a ser usado para o treinamento do modelo de previsão. |
A seguir mostra um exemplo de configuração:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:cluster-name
task: forecasting
primary_metric: normalized_root_mean_squared_error
log_verbosity: info
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: "date"
time_series_id_column_names: ["state", "store", "SKU"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
hierarchy_column_names: ["state", "store", "SKU"]
hierarchy_training_level: "store"
Em exemplos subsequentes, assumimos que a configuração é armazenada no caminho, ./automl_settings_hts.yml.
Pipeline HTS
Em seguida, definimos uma função de fábrica que cria pipelines para orquestração de treinamento HTS, inferência e computação métrica. Os parâmetros desta função de fábrica são detalhados na tabela a seguir:
| Parâmetro | Description |
|---|---|
| forecast_level | O nível da hierarquia para recuperar previsões para |
| allocation_method | Método de repartição a utilizar quando as previsões são desagregadas. Os valores válidos são "proportions_of_historical_average" e "average_historical_proportions". |
| max_nodes | Número de nós de computação a serem usados no trabalho de treinamento |
| max_concurrency_per_node | Número de processos AutoML a serem executados em cada nó. Assim, a simultaneidade total de um trabalho HTS é max_nodes * max_concurrency_per_node. |
| parallel_step_timeout_in_seconds | Muitos modelos componente tempo limite dado em número de segundos. |
| forecast_mode | Modo de inferência para avaliação do modelo. Os valores válidos são "recursive" e "rolling". Consulte o artigo de avaliação do modelo para obter mais informações. |
| forecast_step | Tamanho do passo para previsão contínua. Consulte o artigo de avaliação do modelo para obter mais informações. |
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a HTS training component
hts_train_component = ml_client_registry.components.get(
name='automl_hts_training',
version='latest'
)
# Get a HTS inference component
hts_inference_component = ml_client_registry.components.get(
name='automl_hts_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML HTS Forecasting Pipeline")
def hts_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
forecast_mode="rolling",
forecast_step=1,
forecast_level="SKU",
allocation_method='proportions_of_historical_average'
):
hts_train = hts_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
max_nodes=max_nodes
)
hts_inference = hts_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=hts_train.outputs.run_output,
forecast_level=forecast_level,
allocation_method=allocation_method,
forecast_mode=forecast_mode,
forecast_step=forecast_step
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=hts_inference.outputs.evaluation_data,
ground_truth=hts_inference.outputs.evaluation_data,
evaluation_config=hts_inference.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
Agora, construímos o pipeline através da função de fábrica, assumindo que os dados de treinamento e teste estão em pastas locais e./data/test, ./data/train respectivamente. Finalmente, definimos o cálculo padrão e enviamos o trabalho como no exemplo a seguir:
pipeline_job = hts_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_hts.yml"
)
)
pipeline_job.settings.default_compute = "cluster-name"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
Após a conclusão do trabalho, as métricas de avaliação podem ser baixadas localmente usando o mesmo procedimento do pipeline de execução de treinamento único.
Consulte também a previsão de demanda com o caderno hierárquico de séries temporais para obter um exemplo mais detalhado.
Nota
Os componentes de treinamento e inferência HTS particionam condicionalmente seus dados de acordo com a configuração para hierarchy_column_names que cada partição esteja em seu próprio arquivo. Este processo pode ser muito lento ou falhar quando os dados são muito grandes. Nesse caso, recomendamos particionar seus dados manualmente antes de executar o treinamento ou a inferência do HTS.
Previsão em escala: treinamento distribuído de DNN
- Para saber como funciona o treinamento distribuído para tarefas de previsão, consulte nosso artigo de previsão em escala.
- Consulte nossa seção de artigo de treinamento distribuído de configuração para dados tabulares para obter exemplos de código.
Blocos de notas de exemplo
Veja os blocos de notas de previsão de exemplo para obter exemplos de código detalhados de configuração de previsão avançada, incluindo:
- Exemplos de pipeline de previsão de demanda
- Modelos de aprendizagem profunda
- Deteção e caracterização de feriados
- Configuração manual para atrasos e recursos de agregação de janelas rolantes
Próximos passos
- Saiba mais sobre Como implantar um modelo AutoML em um ponto de extremidade online.
- Saiba mais sobre Interpretabilidade: explicações de modelo em aprendizado de máquina automatizado (visualização).
- Saiba mais sobre como o AutoML cria modelos de previsão.
- Saiba mais sobre a previsão em escala.
- Saiba como configurar o AutoML para vários cenários de previsão.
- Saiba mais sobre inferência e avaliação de modelos de previsão.