Tutorial: Prever a procura com aprendizagem automática sem código no estúdio de Aprendizagem de Máquina do Azure
Saiba como criar um modelo de previsão de séries cronológicas sem escrever uma única linha de código utilizando a aprendizagem automática de máquina no estúdio de Aprendizagem de Máquina do Azure. Este modelo prevê a procura de aluguer para um serviço de partilha de bicicletas.
Você não escreve nenhum código neste tutorial, você usa a interface do estúdio para executar o treinamento. Você aprende a fazer as seguintes tarefas:
- Crie e carregue um conjunto de dados.
- Configure e execute um experimento de ML automatizado.
- Especifique as configurações de previsão.
- Explore os resultados da experiência.
- Implante o melhor modelo.
Experimente também o aprendizado de máquina automatizado para esses outros tipos de modelo:
- Para obter um exemplo sem código de um modelo de classificação, consulte Tutorial: Criar um modelo de classificação com ML automatizado no Azure Machine Learning.
- Para obter um primeiro exemplo de código de um modelo de deteção de objeto, consulte o Tutorial: Treinar um modelo de deteção de objeto com AutoML e Python.
Pré-requisitos
Uma área de trabalho do Azure Machine Learning. Consulte Criar recursos do espaço de trabalho.
Transferir o ficheiro de dados bike-no.csv
Iniciar sessão no estúdio
Para este tutorial, você cria seu experimento de ML automatizado executado no estúdio de Aprendizado de Máquina do Azure, uma interface Web consolidada que inclui ferramentas de aprendizado de máquina para executar cenários de ciência de dados para profissionais de ciência de dados de todos os níveis de habilidade. O estúdio não é suportado nos navegadores Internet Explorer.
Entre no estúdio do Azure Machine Learning.
Selecione sua assinatura e o espaço de trabalho que você criou.
Selecione Introdução.
No painel esquerdo, selecione ML automatizado na seção Autor.
Selecione +Novo trabalho de ML automatizado.
Criar e carregar conjunto de dados
Antes de configurar seu experimento, carregue seu arquivo de dados em seu espaço de trabalho na forma de um conjunto de dados do Azure Machine Learning. Isso permite que você garanta que seus dados sejam formatados adequadamente para seu experimento.
No formulário Selecionar conjunto de dados, selecione De arquivos locais na lista suspensa +Criar conjunto de dados.
No formulário Informações básicas, dê um nome ao conjunto de dados e forneça uma descrição opcional. O tipo de conjunto de dados deve usar como padrão Tabular, já que o ML automatizado no estúdio do Azure Machine Learning atualmente só dá suporte a conjuntos de dados tabulares.
Selecione Avançar no canto inferior esquerdo
No formulário Armazenamento de dados e seleção de arquivos, selecione o armazenamento de dados padrão que foi configurado automaticamente durante a criação do espaço de trabalho, workspaceblobstore (Armazenamento de Blobs do Azure). Este é o local de armazenamento onde você carrega seu arquivo de dados.
Selecione Carregar arquivos na lista suspensa Carregar .
Escolha o arquivo bike-no.csv no computador local. Este é o arquivo que você baixou como pré-requisito.
Selecione Seguinte
Quando o carregamento estiver concluído, o formulário Configurações e visualização será pré-preenchido com base no tipo de arquivo.
Verifique se o formulário Configurações e visualização está preenchido da seguinte forma e selecione Avançar.
Campo Descrição Valor para tutorial File format Define o layout e o tipo de dados armazenados em um arquivo. Delimitado Delimitador Um ou mais caracteres para especificar o limite entre regiões separadas e independentes em texto sem formatação ou outros fluxos de dados. Comma Codificação Identifica qual tabela de esquema de bit a caractere usar para ler seu conjunto de dados. UTF-8 Cabeçalhos de coluna Indica como os cabeçalhos do conjunto de dados, se houver, serão tratados. Apenas o primeiro ficheiro tem cabeçalhos Saltar filas Indica quantas linhas, se houver, são ignoradas no conjunto de dados. Nenhuma O formulário Esquema permite a configuração adicional de seus dados para este experimento.
Para este exemplo, opte por ignorar as colunas casuais e registradas . Essas colunas são um detalhamento da coluna cnt , portanto, não as incluímos.
Também para este exemplo, deixe os padrões para Propriedades e Tipo.
Selecione Seguinte.
No formulário Confirmar detalhes, verifique se as informações correspondem ao que foi preenchido anteriormente nos formulários Informações básicas e Configurações e visualização.
Selecione Criar para concluir a criação do conjunto de dados.
Selecione seu conjunto de dados assim que ele aparecer na lista.
Selecione Seguinte.
Configurar trabalho
Depois de carregar e configurar os dados, configure o destino de computação remoto e selecione qual coluna nos dados você deseja prever.
- Preencha o formulário Configurar trabalho da seguinte maneira:
Insira um nome de experimento:
automl-bikeshareSelecione cnt como a coluna de destino, o que você deseja prever. Esta coluna indica o número total de alugueres de bicicletas partilhadas.
Selecione o cluster de computação como seu tipo de computação.
Selecione +Novo para configurar o destino de computação. O ML automatizado suporta apenas a computação do Azure Machine Learning.
Preencha o formulário Selecionar máquina virtual para configurar sua computação.
Campo Descrição Valor para tutorial Camada de máquina virtual Selecione a prioridade que seu experimento deve ter Dedicada Tipo de máquina virtual Selecione o tipo de máquina virtual para sua computação. CPU (Unidade Central de Processamento) Tamanho da máquina virtual Selecione o tamanho da máquina virtual para sua computação. Uma lista de tamanhos recomendados é fornecida com base em seus dados e tipo de experimento. Standard_DS12_V2 Selecione Avançar para preencher o formulário Configurar configurações.
Campo Descrição Valor para tutorial Nome da computação Um nome exclusivo que identifica seu contexto de computação. bicicleta-computação Nós Min / Max Para criar um perfil, você deve especificar um ou mais nós. Nós mínimos: 1
Nós máximos: 6Segundos ociosos antes de reduzir a escala Tempo ocioso antes que o cluster seja automaticamente reduzido para a contagem mínima de nós. 120 (padrão) Definições avançadas Configurações para configurar e autorizar uma rede virtual para seu experimento. Nenhuma Selecione Criar para obter o destino de computação.
Isso leva alguns minutos para ser concluído.
Após a criação, selecione seu novo destino de computação na lista suspensa.
Selecione Seguinte.
Selecionar configurações de previsão
Conclua a configuração para seu experimento de ML automatizado especificando o tipo de tarefa de aprendizado de máquina e as definições de configuração.
No formulário Tipo de tarefa e configurações, selecione Previsão de séries temporais como o tipo de tarefa de aprendizado de máquina.
Selecione a data como sua coluna Hora e deixe os identificadores de séries temporais em branco.
A Frequência é a frequência com que os seus dados históricos são recolhidos. Mantenha a opção Deteção automática selecionada.
O horizonte de previsão é o período de tempo no futuro que você deseja prever. Desmarque Autodetect e digite 14 no campo.
Selecione Exibir definições de configuração adicionais e preencha os campos da seguinte maneira. Essas configurações são para controlar melhor o trabalho de treinamento e especificar configurações para sua previsão. Caso contrário, os padrões são aplicados com base na seleção e nos dados do experimento.
Configurações adicionais Description Valor para tutorial Métrica primária Métrica de avaliação pela qual o algoritmo de aprendizado de máquina será medido. Erro quadrático médio da raiz normalizada Explicar o melhor modelo Mostra automaticamente a explicabilidade no melhor modelo criado pelo ML automatizado. Ativar Algoritmos bloqueados Algoritmos que pretende excluir do trabalho de formação Árvores aleatórias extremas Configurações de previsão adicionais Essas configurações ajudam a melhorar a precisão do seu modelo.
Defasagens de destino de previsão: até onde você deseja construir as defasagens da variável de destino
Janela rolante de destino: especifica o tamanho da janela rolante sobre a qual recursos, como max , min e soma, são gerados.
Defasagem da meta prevista: Nenhuma
Tamanho da janela rolante alvo: NenhumCritério de saída Se um critério for cumprido, o trabalho de formação é interrompido. Tempo de trabalho de formação (horas): 3
Limite de pontuação métrica: NenhumSimultaneidade O número máximo de iterações paralelas executadas por iteração Máximo de iterações simultâneas: 6 Selecione Guardar.
Selecione Seguinte.
No formulário [Opcional] Validar e testar,
- Selecione k-fold cross-validation como seu tipo de validação.
- Selecione 5 como o número de validações cruzadas.
Executar experimentação
Para executar o experimento, selecione Concluir. A tela Detalhes do trabalho é aberta com o status do trabalho na parte superior ao lado do número do trabalho. Esse status é atualizado à medida que o experimento progride. As notificações também aparecem no canto superior direito do estúdio, para informá-lo sobre o status do seu experimento.
Importante
A preparação leva de 10 a 15 minutos para preparar o trabalho experimental.
Uma vez em execução, leva de 2 a 3 minutos a mais para cada iteração.
Na produção, você provavelmente se afastaria um pouco, pois esse processo leva tempo. Enquanto espera, sugerimos que comece a explorar os algoritmos testados no separador Modelos à medida que forem concluídos.
Explore modelos
Navegue até a guia Modelos para ver os algoritmos (modelos) testados. Por padrão, os modelos são ordenados por pontuação métrica à medida que são concluídos. Para este tutorial, o modelo que pontua mais alto com base na métrica de erro quadrático médio da raiz normalizada escolhida está no topo da lista.
Enquanto aguarda a conclusão de todos os modelos de experimento, selecione o Nome do algoritmo de um modelo concluído para explorar seus detalhes de desempenho.
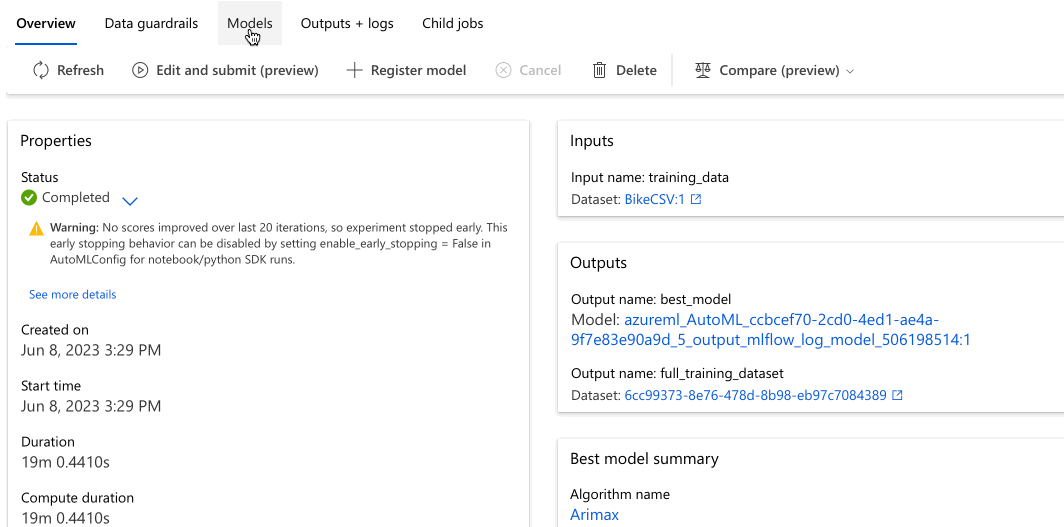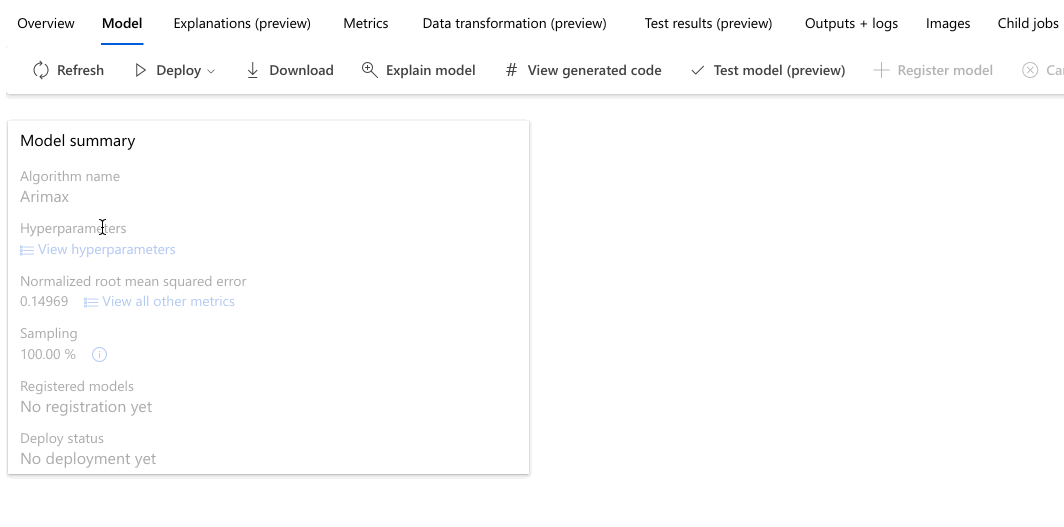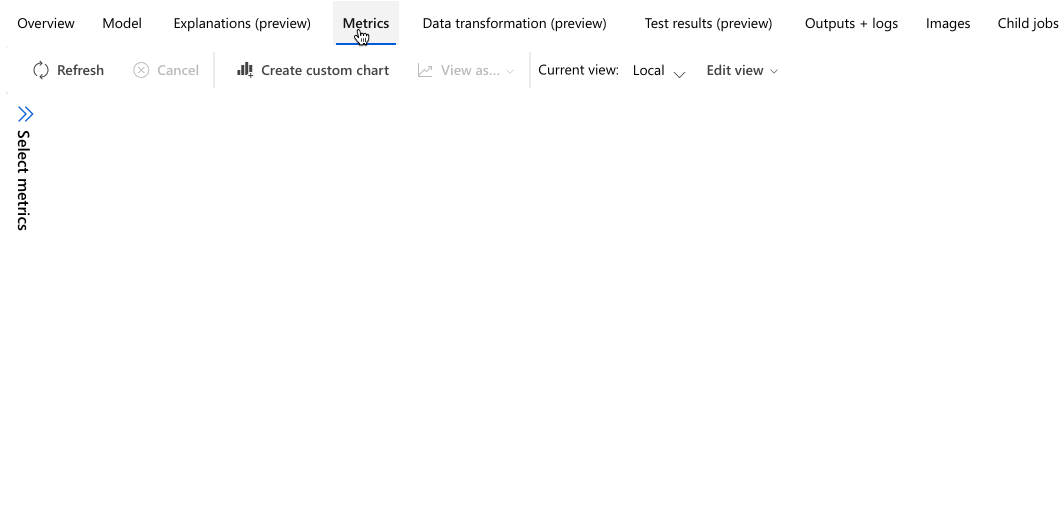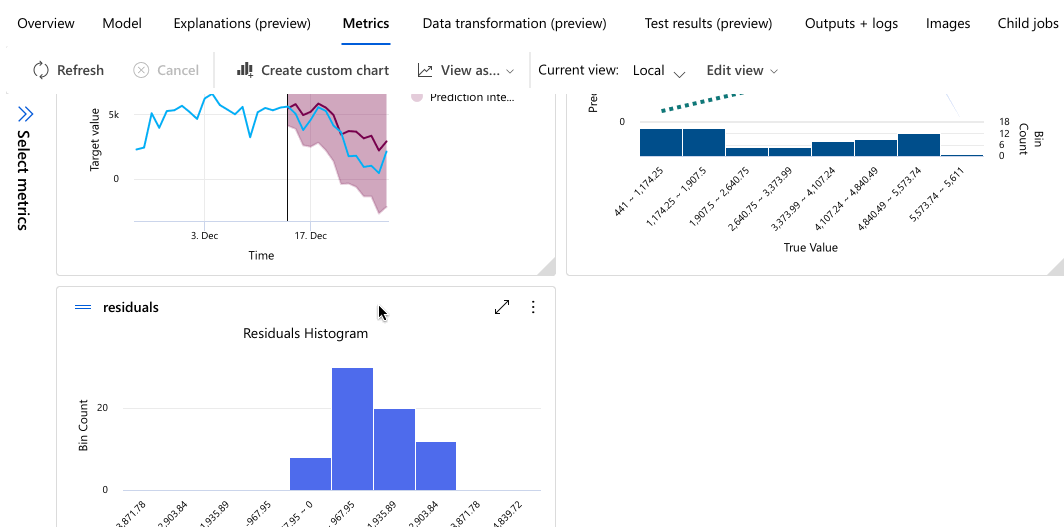
O exemplo a seguir navega para selecionar um modelo da lista de modelos que o trabalho criou. Em seguida, selecione as guias Visão geral e Métricas para exibir as propriedades, métricas e gráficos de desempenho do modelo selecionado.
Implementar o modelo
O aprendizado de máquina automatizado no estúdio de Aprendizado de Máquina do Azure permite implantar o melhor modelo como um serviço Web em algumas etapas. Implantação é a integração do modelo para que ele possa prever novos dados e identificar potenciais áreas de oportunidade.
Para esta experiência, a implementação num serviço Web significa que a empresa de partilha de bicicletas tem agora uma solução Web iterativa e escalável para prever a procura de aluguer de bicicletas partilhadas.
Quando o trabalho estiver concluído, navegue de volta para a página do trabalho pai selecionando Trabalho 1 na parte superior da tela.
Na seção Melhor resumo do modelo, o melhor modelo no contexto deste experimento é selecionado com base na métrica de erro quadrático médio da raiz normalizada.
Implantamos esse modelo, mas esteja avisado, a implantação leva cerca de 20 minutos para ser concluída. O processo de implantação envolve várias etapas, incluindo o registro do modelo, a geração de recursos e a configuração deles para o serviço Web.
Selecione o melhor modelo para abrir a página específica do modelo.
Selecione o botão Implantar localizado na área superior esquerda da tela.
Preencha o painel Implantar um modelo da seguinte maneira:
Campo Value Nome da implementação bikeshare-implantar Descrição da implantação implantação de demanda de compartilhamento de bicicletas Tipo de computação Selecione a Instância de Computação do Azure (ACI) Ative a autenticação Desativar. Usar ativos de implantação personalizados Desativar. A desativação permite que o arquivo de driver padrão (script de pontuação) e o arquivo de ambiente sejam gerados automaticamente. Para este exemplo, usamos os padrões fornecidos no menu Avançado .
Selecione Implementar.
Uma mensagem verde de êxito aparece na parte superior da tela Trabalho informando que a implantação foi iniciada com êxito. O progresso da implantação pode ser encontrado no painel Resumo do modelo em Status da implantação.
Quando a implantação for bem-sucedida, você terá um serviço Web operacional para gerar previsões.
Prossiga para as próximas etapas para saber mais sobre como consumir seu novo serviço Web e testar suas previsões usando o suporte interno do Aprendizado de Máquina do Azure do Power BI.
Clean up resources (Limpar recursos)
Os arquivos de implantação são maiores do que os arquivos de dados e experimentos, portanto, custam mais para armazenar. Exclua apenas os arquivos de implantação para minimizar os custos para sua conta ou se quiser manter seus arquivos de espaço de trabalho e experimento. Caso contrário, exclua todo o grupo de recursos, se você não planeja usar nenhum dos arquivos.
Excluir a instância de implantação
Exclua apenas a instância de implantação do estúdio do Azure Machine Learning, se quiser manter o grupo de recursos e o espaço de trabalho para outros tutoriais e exploração.
Vá para o estúdio do Azure Machine Learning. Navegue até o espaço de trabalho e, à esquerda, no painel Ativos , selecione Pontos de extremidade.
Selecione a implantação que deseja excluir e selecione Excluir.
Selecione Continuar.
Eliminar o grupo de recursos
Importante
Os recursos que você criou podem ser usados como pré-requisitos para outros tutoriais e artigos de instruções do Azure Machine Learning.
Se você não planeja usar nenhum dos recursos que criou, exclua-os para não incorrer em cobranças:
No portal do Azure, na caixa de pesquisa, insira Grupos de recursos e selecione-o nos resultados.
Na lista, selecione o grupo de recursos que você criou.
Na página Visão geral, selecione Excluir grupo de recursos.
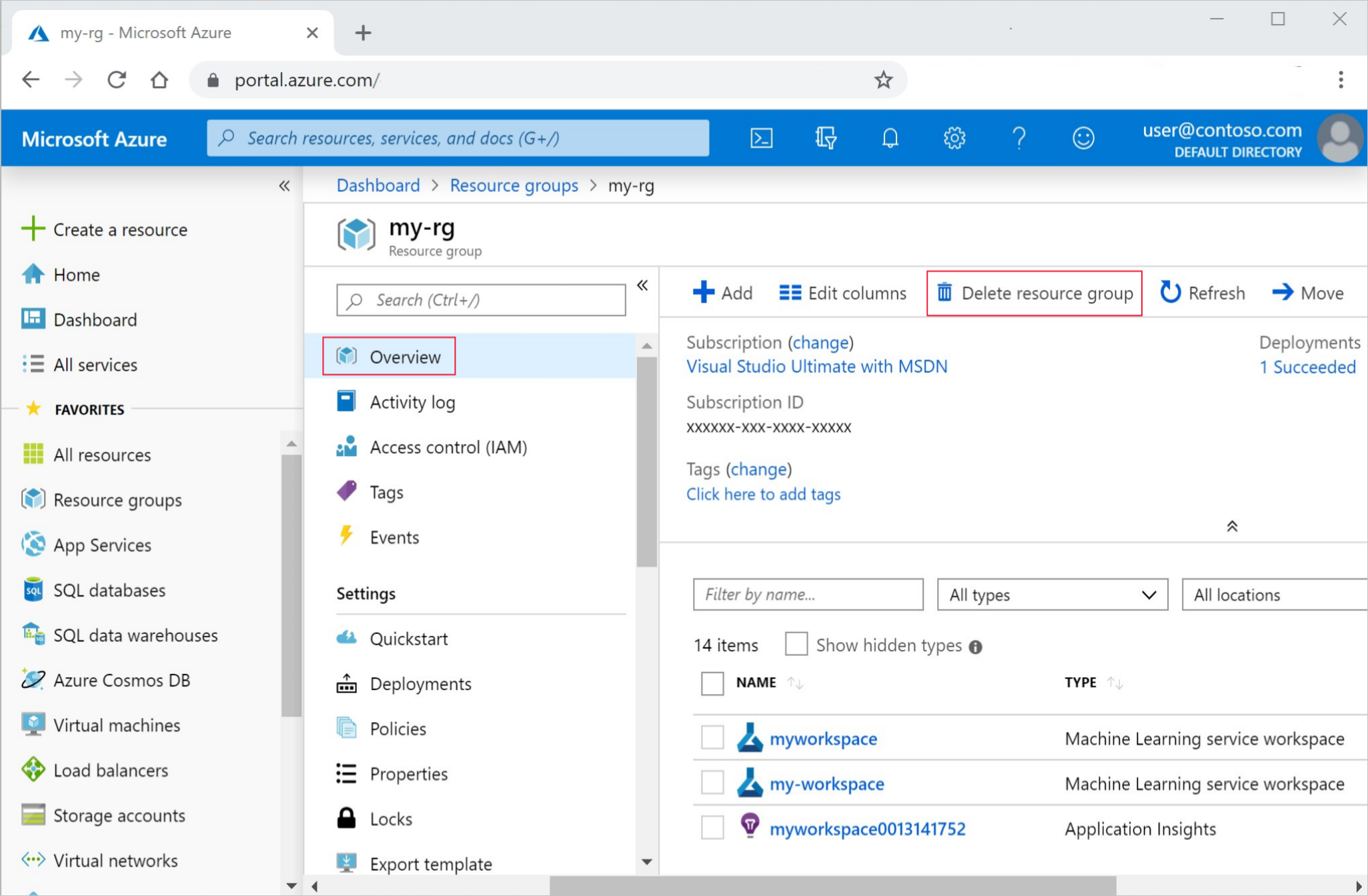
Insira o nome do grupo de recursos. Em seguida, selecione Eliminar.
Próximos passos
Neste tutorial, você usou o ML automatizado no estúdio de Aprendizado de Máquina do Azure para criar e implantar um modelo de previsão de séries temporais que prevê a demanda de aluguel de compartilhamento de bicicletas.
- Saiba mais sobre o aprendizado de máquina automatizado.
- Para obter mais informações sobre métricas e gráficos de classificação, consulte o artigo Compreender os resultados do aprendizado de máquina automatizado.
- Para mais informações sobre as perguntas frequentes sobre previsões.
Nota
Este conjunto de dados de compartilhamento de bicicletas foi modificado para este tutorial. Este conjunto de dados foi disponibilizado como parte de uma competição Kaggle e foi originalmente disponibilizado via Capital Bikeshare. Ele também pode ser encontrado dentro do UCI Machine Learning Database.
Fonte: Fanaee-T, Hadi, e Gama, João, Event labeling combining ensemble detectors and background knowledge, Progress in Artificial Intelligence (2013): pp. 1-15, Springer Berlin Heidelberg.