Recolher dados de modelos em produção
APLICA-SE A: SDK python azureml v1
SDK python azureml v1
Este artigo mostra como recolher dados de um modelo do Azure Machine Learning implementado num cluster de Azure Kubernetes Service (AKS). Em seguida, os dados recolhidos são armazenados no armazenamento de Blobs do Azure.
Assim que a recolha estiver ativada, os dados recolhidos ajudam-no:
Monitorize os desvios de dados nos dados de produção que recolhe.
Analisar dados recolhidos com o Power BI ou o Azure Databricks
Tome melhores decisões sobre quando voltar a preparar ou otimizar o modelo.
Volte a preparar o modelo com os dados recolhidos.
Limitações
- A funcionalidade de recolha de dados do modelo só pode funcionar com a imagem do Ubuntu 18.04.
Importante
A partir de 10/03/2023, a imagem do Ubuntu 18.04 foi preterida. O suporte para imagens do Ubuntu 18.04 será removido a partir de janeiro de 2023, quando chegar à EOL a 30 de abril de 2023.
A funcionalidade MDC é incompatível com qualquer outra imagem que não o Ubuntu 18.04, que não está disponível depois de a imagem do Ubuntu 18.04 ter sido preterida.
MMais informações a que se pode referir:
Nota
A funcionalidade de recolha de dados está atualmente em pré-visualização. As funcionalidades de pré-visualização não são recomendadas para cargas de trabalho de produção.
O que é recolhido e para onde vai
Os seguintes dados podem ser recolhidos:
Dados de entrada de modelos de serviços Web implementados num cluster do AKS. O áudio de voz, as imagens e o vídeo não são recolhidos.
Predições de modelos com dados de entrada de produção.
Nota
A pré-agregação e os pré-cálculos destes dados não fazem atualmente parte do serviço de recolha.
A saída é guardada no armazenamento de Blobs. Uma vez que os dados são adicionados ao armazenamento de Blobs, pode escolher a sua ferramenta favorita para executar a análise.
O caminho para os dados de saída no blob segue esta sintaxe:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv
# example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv
Nota
Nas versões do SDK do Azure Machine Learning para Python anteriores à versão 0.1.0a16, o designation argumento chama-se identifier. Se tiver desenvolvido o código com uma versão anterior, terá de atualizá-lo em conformidade.
Pré-requisitos
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Tem de instalar uma área de trabalho do Azure Machine Learning, um diretório local que contenha os scripts e o SDK do Azure Machine Learning para Python. Para saber como instalá-los, veja Como configurar um ambiente de desenvolvimento.
Precisa de um modelo de machine learning preparado para ser implementado no AKS. Se não tiver um modelo, veja o tutorial Train image classification model (Preparar modelo de classificação de imagens ).
Precisa de um cluster do AKS. Para obter informações sobre como criar um e implementar no mesmo, veja Implementar modelos de machine learning no Azure.
Configure o seu ambiente e instale o SDK de Monitorização do Azure Machine Learning.
Utilize uma imagem do Docker baseada no Ubuntu 18.04, que é enviado com
libssl 1.0.0, a dependência essencial do modeldatacollector. Pode consultar as imagens pré-criadas.
Ativar a recolha de dados
Pode ativar a recolha de dados independentemente do modelo que implementar através do Azure Machine Learning ou de outras ferramentas.
Para ativar a recolha de dados, tem de:
Abra o ficheiro de classificação.
Adicione o seguinte código na parte superior do ficheiro:
from azureml.monitoring import ModelDataCollectorDeclare as variáveis de recolha de dados na sua
initfunção:global inputs_dc, prediction_dc inputs_dc = ModelDataCollector("best_model", designation="inputs", feature_names=["feat1", "feat2", "feat3", "feat4", "feat5", "feat6"]) prediction_dc = ModelDataCollector("best_model", designation="predictions", feature_names=["prediction1", "prediction2"])CorrelationId é um parâmetro opcional. Não precisa de utilizá-lo se o seu modelo não o exigir. A utilização do CorrelationId ajuda-o a mapear mais facilmente com outros dados, como LoanNumber ou CustomerId.
O parâmetro Identificador é mais tarde utilizado para criar a estrutura de pastas no blob. Pode utilizá-la para diferenciar dados não processados dos dados processados.
Adicione as seguintes linhas de código à
run(input_df)função:data = np.array(data) result = model.predict(data) inputs_dc.collect(data) #this call is saving our input data into Azure Blob prediction_dc.collect(result) #this call is saving our prediction data into Azure BlobA recolha de dados não é definida automaticamente como verdadeira quando implementa um serviço no AKS. Atualize o ficheiro de configuração, tal como no exemplo seguinte:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True)Também pode ativar o Application Insights para monitorização do serviço ao alterar esta configuração:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True, enable_app_insights=True)Para criar uma nova imagem e implementar o modelo de machine learning, veja Implementar modelos de machine learning no Azure.
Adicione o pacote pip "Azure-Monitoring" às conda-dependencies do ambiente do serviço Web:
env = Environment('webserviceenv')
env.python.conda_dependencies = CondaDependencies.create(conda_packages=['numpy'],pip_packages=['azureml-defaults','azureml-monitoring','inference-schema[numpy-support]'])
Desativar a recolha de dados
Pode parar de recolher dados em qualquer altura. Utilize o código Python para desativar a recolha de dados.
## replace <service_name> with the name of the web service
<service_name>.update(collect_model_data=False)
Validar e analisar os seus dados
Pode escolher uma ferramenta da sua preferência para analisar os dados recolhidos no armazenamento de Blobs.
Aceder rapidamente aos seus dados de blobs
Inicie sessão no portal do Azure.
Abra a área de trabalho.
Selecione Armazenamento.

Siga o caminho para os dados de saída do blob com esta sintaxe:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv # example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv

Analisar dados de modelos com o Power BI
Transfira e abra Power BI Desktop.
Selecione Obter Dados e selecione Armazenamento de Blobs do Azure.
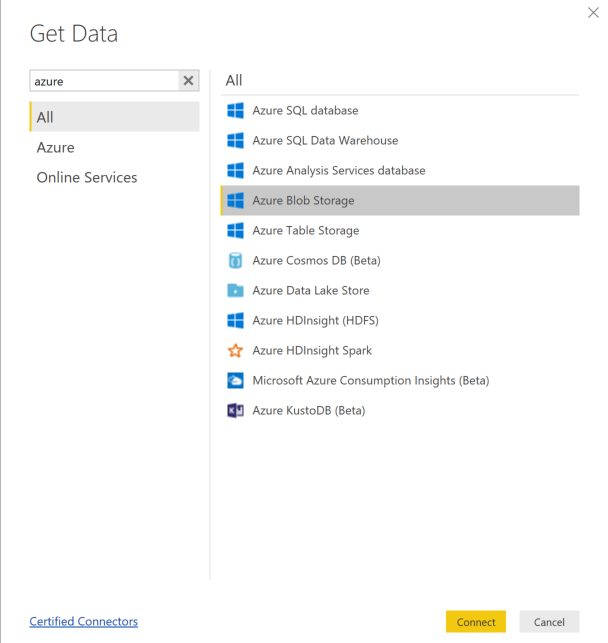
Adicione o nome da conta de armazenamento e introduza a chave de armazenamento. Pode encontrar estas informações ao selecionar Definições>Chaves de acesso no blob.
Selecione o contentor de dados do modelo e selecione Editar.
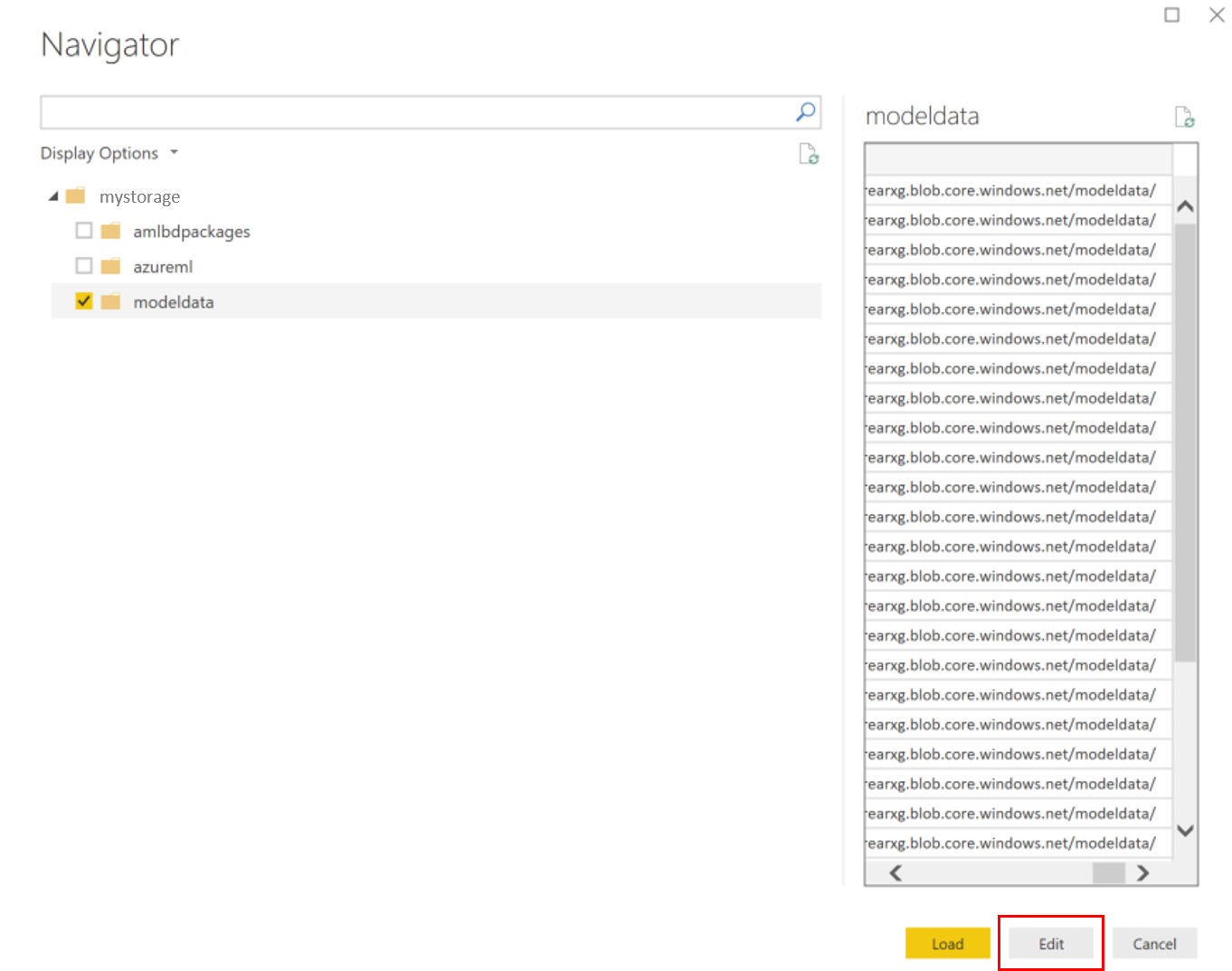
No editor de consultas, clique na coluna Nome e adicione a sua conta de armazenamento.
Introduza o caminho do modelo no filtro. Se quiser procurar apenas ficheiros a partir de um ano ou mês específico, expanda o caminho do filtro. Por exemplo, para analisar apenas os dados de março, utilize este caminho de filtro:
/modeldata/<subscriptionid>/<resourcegroupname>/<workspacename>/<webservicename>/<modelname>/<modelversion>/<designation>/<year>/3
Filtre os dados que são relevantes para si com base nos valores de Nome . Se tiver armazenado predições e entradas, terá de criar uma consulta para cada uma.
Selecione as setas duplas para baixo junto ao cabeçalho da coluna Conteúdo para combinar os ficheiros.

Selecione OK. Os dados são pré-carregados.
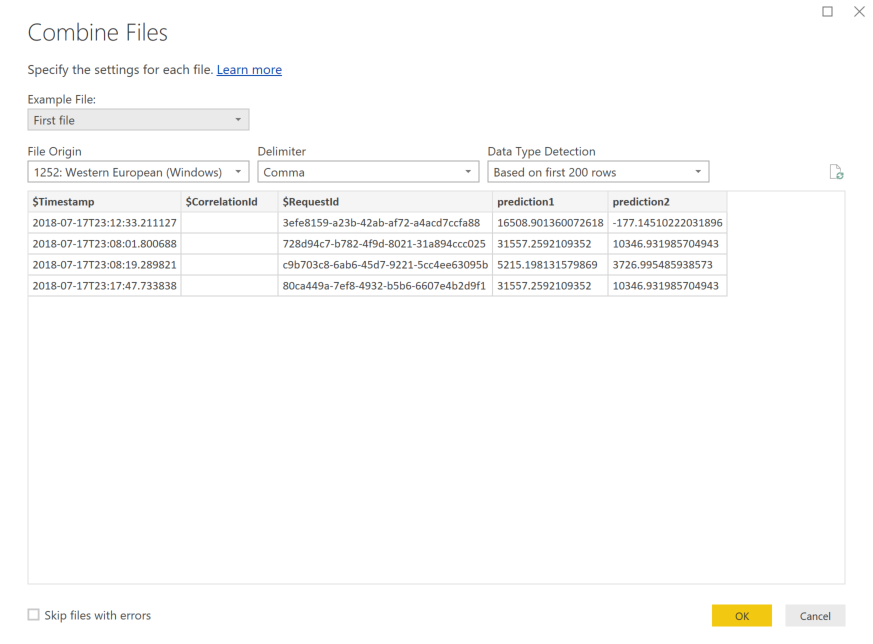
Selecione Fechar e Aplicar.
Se adicionou entradas e predições, as tabelas são ordenadas automaticamente pelos valores requestId .
Comece a criar os seus relatórios personalizados sobre os dados do modelo.




Analisar dados de modelos com o Azure Databricks
Criar uma área de trabalho do Azure Databricks.
Aceda à área de trabalho do Databricks.
Na área de trabalho do Databricks, selecione Carregar Dados.

Selecione Criar Nova Tabela e selecione Outras Origens> de Dados Armazenamento de Blobs do Azure>Criar Tabela no Bloco de Notas.
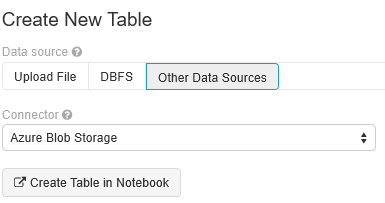
Atualize a localização dos seus dados. Segue-se um exemplo:
file_location = "wasbs://mycontainer@storageaccountname.blob.core.windows.net/modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/*/*/data.csv" file_type = "csv"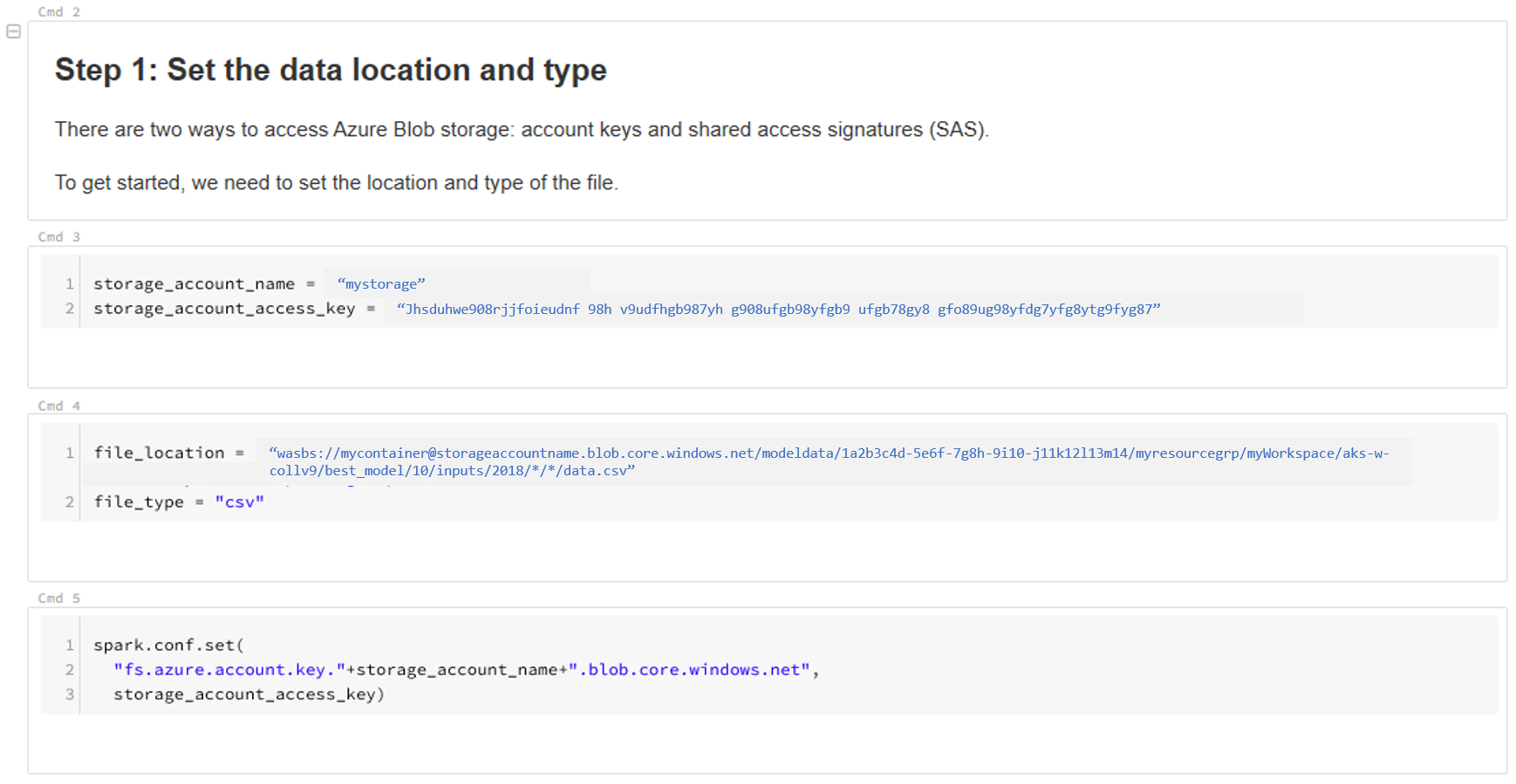
Siga os passos no modelo para ver e analisar os seus dados.



Passos seguintes
Detete o desvio de dados nos dados que recolheu.