Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Note
Os armazéns de conhecimento são armazenamento secundário que existe no Armazenamento do Azure e contêm resultados dos conjuntos de habilidades do Pesquisa de IA do Azure. São separados das fontes de conhecimento e das bases de conhecimento, que são usados em fluxos de recuperação agênticos.
O repositório de conhecimento é um armazenamento secundário para conteúdo enriquecido com IA criado por um conjunto de habilidades no Pesquisa de IA do Azure. Na Pesquisa de IA do Azure, um trabalho de indexação sempre envia saída para um índice de pesquisa, mas se você anexar um conjunto de habilidades a um indexador, também poderá, opcionalmente, enviar saída enriquecida com IA para um contêiner ou tabela no Armazenamento do Azure. Um repositório de conhecimento pode ser usado para análise independente ou processamento downstream em cenários sem pesquisa, como mineração de conhecimento.
As duas saídas da indexação, um índice de pesquisa e um armazenamento de conhecimento, são produtos mutuamente exclusivos do mesmo pipeline. Eles são derivados das mesmas entradas e contêm os mesmos dados, mas seu conteúdo é estruturado, armazenado e usado em aplicativos diferentes.

Fisicamente, um repositório de conhecimento é o Armazenamento do Azure, o Armazenamento de Tabela do Azure, o Armazenamento de Blob do Azure ou ambos. Qualquer ferramenta ou processo que possa se conectar ao Armazenamento do Azure pode consumir o conteúdo de um repositório de conhecimento. Não há suporte a consultas na Pesquisa de IA do Azure para recuperar conteúdo de um repositório de conhecimento.
Quando visualizado através do portal do Azure, um arquivo de conhecimento se parece com qualquer outra coleção de tabelas, objetos ou arquivos. A captura de tela a seguir mostra um repositório de conhecimento composto por três tabelas. Você pode adotar uma convenção de nomenclatura, como um kstore prefixo, para manter seu conteúdo unido.
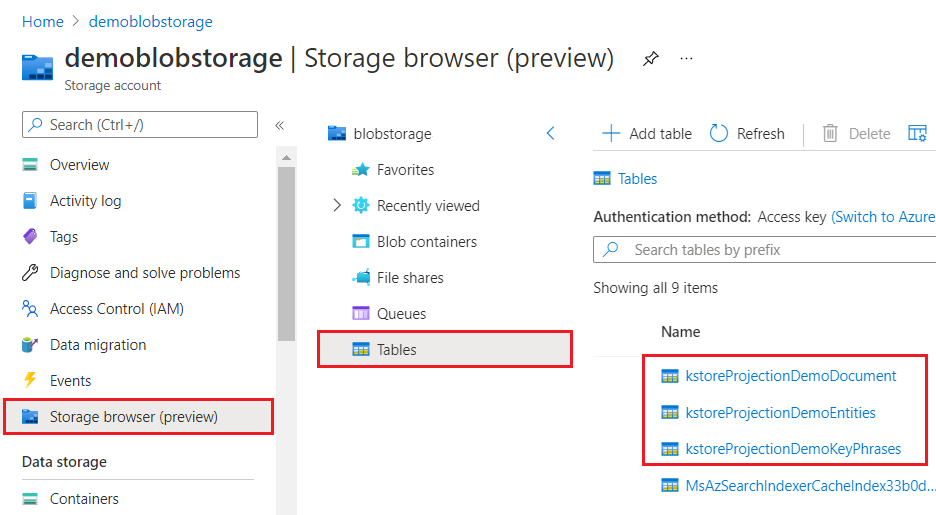
Benefícios do armazenamento de conhecimento
Os principais benefícios de um armazenamento de conhecimento são duplos: acesso flexível ao conteúdo e a capacidade de moldar dados.
Ao contrário de um índice de pesquisa que só pode ser acessado por meio de consultas no Pesquisa de IA do Azure, um repositório de conhecimento é acessível a qualquer ferramenta, aplicativo ou processo que ofereça suporte a conexões com o Armazenamento do Azure. Esta flexibilidade abre novos cenários para o consumo do conteúdo analisado e enriquecido gerado por uma cadeia de processos de enriquecimento.
O mesmo conjunto de habilidades que enriquece os dados também pode ser usado para moldar dados. Algumas ferramentas como o Power BI funcionam melhor com tabelas, enquanto uma carga de trabalho de ciência de dados pode exigir uma estrutura de dados complexa em um formato de blob. Adicionar uma habilidade Shaper a um conjunto de habilidades lhe dá controle sobre a forma de seus dados. Em seguida, você pode passar essas formas para projeções, tabelas ou blobs, para criar estruturas de dados físicas que se alinham com o uso pretendido dos dados.
O vídeo a seguir explica esses dois benefícios e muito mais.
Definição do repositório de conhecimento
Um repositório de conhecimento é definido dentro de uma definição de conjunto de habilidades e tem dois componentes:
Uma cadeia de conexão para o Armazenamento do Azure
Projeções que determinam se o armazenamento de conhecimento consiste em tabelas, objetos ou arquivos. O elemento projeções é uma matriz. Você pode criar vários conjuntos de combinações tabela-objeto-arquivo em um repositório de conhecimento.
"knowledgeStore": { "storageConnectionString":"<YOUR-AZURE-STORAGE-ACCOUNT-CONNECTION-STRING>", "projections":[ { "tables":[ ], "objects":[ ], "files":[ ] } ] }
O tipo de projeção especificado nessa estrutura determina o tipo de armazenamento usado pelo repositório de conhecimento, mas não sua estrutura. Os campos em tabelas, objetos e ficheiros são determinados pela saída da skill do Shaper se estiveres a criar o knowledge store programaticamente, ou pelo assistente de Importação de dados se estiveres a usar o portal Azure.
tablesprojete conteúdo enriquecido no Armazenamento de Tabelas. Defina uma projeção de tabela quando precisar de estruturas de relatórios tabulares para entradas em ferramentas analíticas ou exporte como quadros de dados para outros armazenamentos de dados. Você pode especificar váriostablesdentro do mesmo grupo de projeção para obter um subconjunto ou seção transversal de documentos enriquecidos. Dentro do mesmo grupo de projeção, as relações de tabela são preservadas para que você possa trabalhar com todas elas.O conteúdo projetado não é agregado ou normalizado. O seguinte screenshot mostra uma tabela, classificada por expressão-chave, com o documento principal listado na coluna adjacente. Em contraste com a ingestão de dados durante a indexação, não há análise linguística ou agregação de conteúdo. Formas plurais e diferenças no invólucro são consideradas instâncias únicas.
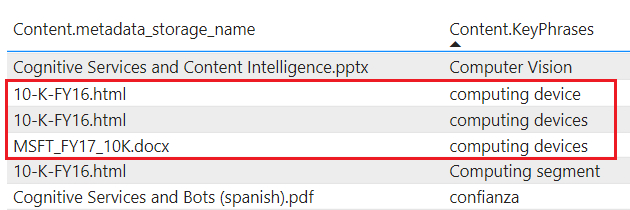
objectsprojete o documento JSON no armazenamento de Blob. A representação física de umobjecté uma estrutura JSON hierárquica que representa um documento enriquecido.filesprojetar arquivos de imagem no armazenamento de Blob. Afileé uma imagem extraída de um documento, transferida intacta para o armazenamento de Blob. Embora seja chamado de "arquivos", ele aparece no armazenamento Blob, e não no armazenamento de arquivos.
Criar um arquivo de conhecimento
Use o portal Azure, APIs REST ou um pacote SDK do Azure para criar um armazenamento de conhecimento. Todos os métodos requerem Armazenamento do Azure, um conjunto de competências e um indexador. Como os indexadores exigem um índice de pesquisa, também deve fornecer uma definição de índice.
As APIs e SDKs REST fornecem controlo total sobre projeções: tabelas, objetos e ficheiros. O portal Azure cria automaticamente um armazenamento de conhecimento como parte do fluxo de trabalho multimodal RAG, que está limitado a projeções de ficheiros para imagens extraídas.
O assistente de importação de dados cria um armazenamento de conhecimento apenas para o cenário multimodal RAG. Para começar, consulte Quickstart: Pesquisa Multimodal no portal Azure.
Conecte-se com aplicativos
Depois que o conteúdo enriquecido existir no armazenamento, qualquer ferramenta ou tecnologia que se conecte ao Armazenamento do Azure poderá ser usada para explorar, analisar ou consumir o conteúdo. A lista a seguir é um começo:
Explorador de Armazenamento ou Navegador de Armazenamento no portal do Azure para visualizar a estrutura e o conteúdo enriquecido do documento. Considere isto como a sua ferramenta padrão para visualizar o conteúdo do armazenamento de conhecimento.
Power BI para relatórios e análises.
Azure Data Factory para manipulação adicional.
Ciclo de vida do conteúdo
Cada vez que você executa o indexador e o conjunto de habilidades, o armazenamento de conhecimento é atualizado se o conjunto de habilidades ou os dados de origem subjacentes tiverem sido alterados. Quaisquer alterações captadas pelo indexador são propagadas através do processo de enriquecimento para as projeções no armazenamento de conhecimento, garantindo que os dados projetados sejam uma representação atual do conteúdo na fonte de dados de origem.
Note
Embora seja possível editar os dados nas projeções, quaisquer edições serão sobrescritas na próxima invocação do pipeline, caso o documento nos dados de origem seja atualizado.
Alterações nos dados de origem
Para fontes de dados que oferecem suporte ao controle de alterações, um indexador processará documentos novos e alterados e ignorará documentos existentes que já foram processados. As informações de carimbo de data/hora variam de acordo com a fonte de dados, mas em um contêiner de blob, o indexador examina a lastmodified data para determinar quais blobs precisam ser ingeridos.
Alterações a um conjunto de competências
Se estiveres a fazer alterações num conjunto de competências, deves habilitar o cache de documentos enriquecidos para reutilizar os enriquecimentos existentes sempre que possível.
Sem cache incremental, o indexador sempre processará documentos na ordem do limite máximo, sem voltar atrás. Para blobs, o indexador processaria blobs classificados por lastModified, independentemente de quaisquer alterações nas configurações do indexador ou no conjunto de habilidades. Se você alterar um conjunto de habilidades, os documentos processados anteriormente não serão atualizados para refletir o novo conjunto de habilidades. Os documentos processados após a mudança do conjunto de competências utilizarão o novo conjunto de competências, resultando em documentos de índice que são uma mistura de conjuntos de competências antigas e novas.
Com o cache incremental, e após uma atualização do conjunto de habilidades, o indexador reutilizará quaisquer enriquecimentos que não sejam afetados pela alteração do conjunto de habilidades. Os enriquecimentos a montante são extraídos do cache, assim como quaisquer enriquecimentos independentes e isolados da habilidade que foi alterada.
Deletions
Embora um indexador crie e atualize estruturas e conteúdo no Armazenamento do Azure, ele não os exclui. As projeções continuam a existir mesmo quando o indexador ou conjunto de habilidades é excluído. Como proprietário da conta de armazenamento, você deve excluir uma projeção se ela não for mais necessária.
Próximos passos
O repositório de conhecimento oferece persistência de documentos enriquecidos, úteis ao projetar um conjunto de habilidades ou a criação de novas estruturas e conteúdo para consumo por qualquer aplicativo cliente capaz de acessar uma conta de Armazenamento do Azure.
A abordagem mais simples para criar documentos enriquecidos programaticamente é através de APIs REST.