Indexadores na Pesquisa de IA do Azure
Um indexador no Azure AI Search é um rastreador que extrai dados textuais de fontes de dados na nuvem e preenche um índice de pesquisa usando mapeamentos campo a campo entre dados de origem e um índice de pesquisa. Essa abordagem às vezes é chamada de "modelo pull" porque o serviço de pesquisa extrai dados sem que você precise escrever qualquer código que adicione dados a um índice.
Os indexadores também impulsionam a execução de conjuntos de habilidades e o enriquecimento de IA, onde você pode configurar habilidades para integrar processamento extra de conteúdo a caminho de um índice. Alguns exemplos são OCR sobre arquivos de imagem, habilidade de divisão de texto para fragmentação de dados, tradução de texto para vários idiomas.
Os indexadores destinam-se a fontes de dados suportadas. Uma configuração de indexador especifica uma fonte de dados (origem) e um índice de pesquisa (destino). Várias fontes, como o Armazenamento de Blobs do Azure, têm mais propriedades de configuração específicas para esse tipo de conteúdo.
Você pode executar indexadores sob demanda ou em uma agenda de atualização de dados recorrente que é executada a cada cinco minutos. As atualizações mais frequentes exigem um "modelo push" que atualize simultaneamente os dados na Pesquisa de IA do Azure e na sua fonte de dados externa.
Um serviço de pesquisa executa um trabalho de indexador por unidade de pesquisa. Se precisar de processamento simultâneo, certifique-se de ter réplicas suficientes. Os indexadores não são executados em segundo plano, portanto, você pode detetar mais limitação de consulta do que o normal se o serviço estiver sob pressão.
Cenários de indexador e casos de uso
Você pode usar um indexador como o único meio para a ingestão de dados, ou em combinação com outras técnicas. A tabela a seguir resume os principais cenários.
| Cenário | Estratégia |
|---|---|
| Fonte de dados única | Esse padrão é o mais simples: uma fonte de dados é o único provedor de conteúdo para um índice de pesquisa. A maioria das fontes de dados suportadas fornece alguma forma de deteção de alterações para que as execuções subsequentes do indexador captem a diferença quando o conteúdo é adicionado ou atualizado na fonte. |
| Várias fontes de dados | Uma especificação de indexador pode ter apenas uma fonte de dados, mas o próprio índice de pesquisa pode aceitar conteúdo de várias fontes, onde cada indexador executado traz novo conteúdo de um provedor de dados diferente. Cada fonte pode contribuir com sua parte de documentos completos ou preencher campos selecionados em cada documento. Para uma análise mais detalhada desse cenário, consulte Tutorial: Índice de várias fontes de dados. |
| Vários indexadores | Várias fontes de dados geralmente são emparelhadas com vários indexadores se você precisar variar os parâmetros de tempo de execução, a programação ou os mapeamentos de campo. A expansão entre regiões da Pesquisa de IA do Azure é outro cenário. Você pode ter cópias do mesmo índice de pesquisa em regiões diferentes. Para sincronizar o conteúdo do índice de pesquisa, você pode ter vários indexadores extraindo da mesma fonte de dados, onde cada indexador tem como alvo um índice de pesquisa diferente em cada região. A indexação paralela de conjuntos de dados muito grandes também requer uma estratégia de multiindexador, em que cada indexador tem como alvo um subconjunto dos dados. |
| Transformação de conteúdo | Os indexadores impulsionam a execução de conjuntos de habilidades e o enriquecimento da IA. As transformações de conteúdo são definidas em um conjunto de habilidades que você anexa ao indexador. Você pode usar habilidades para incorporar fragmentação e vetorização de dados. |
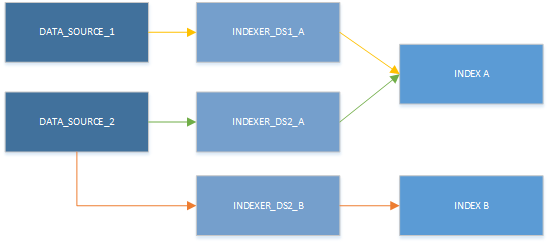
Você deve planejar a criação de um indexador para cada índice de destino e combinação de fonte de dados. Você pode ter vários indexadores gravando no mesmo índice e pode reutilizar a mesma fonte de dados para vários indexadores. No entanto, um indexador só pode consumir uma fonte de dados de cada vez e só pode gravar em um único índice. Como ilustra o gráfico a seguir, uma fonte de dados fornece entrada para um indexador, que preenche um único índice:

Embora você só possa usar um indexador de cada vez, os recursos podem ser usados em diferentes combinações. A principal conclusão da próxima ilustração é observar que uma fonte de dados pode ser emparelhada com mais de um indexador e vários indexadores podem gravar no mesmo índice.
Supported data sources (Origens de dados suportadas)
Os indexadores rastreiam armazenamentos de dados no Azure e fora dele.
- Armazenamento de Blobs do Azure
- BD do Cosmos para o Azure
- Azure Data Lake Storage Gen2 (Armazenamento do Azure Data Lake Gen2)
- Base de Dados SQL do Azure
- Armazenamento de Tabelas do Azure
- Instância Gerida do SQL no Azure
- SQL Server nas Máquinas Virtuais do Azure
- Arquivos do Azure (em visualização)
- Azure MySQL (em pré-visualização)
- SharePoint no Microsoft 365 (em visualização)
- Azure Cosmos DB para MongoDB (em visualização)
- Azure Cosmos DB para Apache Gremlin (em visualização)
O Azure Cosmos DB para Cassandra não é suportado.
Os indexadores aceitam conjuntos de linhas niveladas, como uma tabela ou exibição, ou itens em um contêiner ou pasta. Na maioria dos casos, ele cria um documento de pesquisa por linha, registro ou item.
As conexões de indexador com fontes de dados remotas podem ser feitas usando conexões padrão com a Internet (públicas) ou conexões privadas criptografadas quando você usa um link privado compartilhado. Você também pode configurar conexões para autenticar usando uma identidade gerenciada. Para obter mais informações sobre conexões seguras, consulte Acesso do indexador a conteúdo protegido por recursos de segurança de rede do Azure e Conectar-se a uma fonte de dados usando uma identidade gerenciada.
Etapas da indexação
Em uma execução inicial, quando o índice estiver vazio, um indexador lerá todos os dados fornecidos na tabela ou contêiner. Em execuções subsequentes, o indexador geralmente pode detetar e recuperar apenas os dados que foram alterados. Para dados de blob, a deteção de alterações é automática. Para outras fontes de dados, como o Azure SQL ou o Azure Cosmos DB, a deteção de alterações deve ser habilitada.
Para cada documento que recebe, um indexador implementa ou coordena várias etapas, desde a recuperação de documentos até uma "transferência" final do mecanismo de pesquisa para indexação. Opcionalmente, um indexador também impulsiona a execução e os resultados do conjunto de habilidades, supondo que um conjunto de habilidades seja definido.

Etapa 1: Quebra de documentos
A quebra de documentos é o processo de abrir arquivos e extrair conteúdo. O conteúdo baseado em texto pode ser extraído de arquivos em um serviço, linhas em uma tabela ou itens em contêiner ou coleção. Se você adicionar um conjunto de habilidades e habilidades de imagem, a quebra de documentos também pode extrair imagens e enfileirá-las para processamento de imagens.
Dependendo da fonte de dados, o indexador tentará diferentes operações para extrair conteúdo potencialmente indexável:
Quando o documento é um arquivo com imagens incorporadas, como um PDF, o indexador extrai texto, imagens e metadados. Os indexadores podem abrir arquivos do Armazenamento de Blobs do Azure, do Azure Data Lake Storage Gen2 e do SharePoint.
Quando o documento é um registro no SQL do Azure, o indexador extrai conteúdo não binário de cada campo em cada registro.
Quando o documento é um registro no Azure Cosmos DB, o indexador extrai conteúdo não binário de campos e subcampos do documento do Azure Cosmos DB.
Etapa 2: Mapeamentos de campo
Um indexador extrai texto de um campo de origem e o envia para um campo de destino em um índice ou armazenamento de conhecimento. Quando os nomes de campo e os tipos de dados coincidem, o caminho é claro. No entanto, você pode querer nomes ou tipos diferentes na saída, caso em que você precisa dizer ao indexador como mapear o campo.
Para especificar mapeamentos de campo, insira os campos de origem e destino na definição do indexador.
O mapeamento de campo ocorre após a quebra de documentos, mas antes das transformações, quando o indexador está lendo os documentos de origem. Quando você define um mapeamento de campo, o valor do campo de origem é enviado como está para o campo de destino sem modificações.
Etapa 3: Execução do conjunto de competências
A execução do conjunto de habilidades é uma etapa opcional que invoca o processamento de IA interno ou personalizado. Os conjuntos de habilidades podem adicionar reconhecimento ótico de caracteres (OCR) ou outras formas de análise de imagem se o conteúdo for binário. Os conjuntos de habilidades também podem adicionar processamento de linguagem natural. Por exemplo, você pode adicionar tradução de texto ou extração de frases-chave.
Seja qual for a transformação, a execução do conjunto de habilidades é onde o enriquecimento ocorre. Se um indexador é um pipeline, você pode pensar em um conjunto de habilidades como um "pipeline dentro do pipeline".
Etapa 4: Mapeamentos de campo de saída
Se você incluir um conjunto de habilidades, precisará especificar mapeamentos de campo de saída na definição do indexador. O resultado de um conjunto de habilidades é manifestado internamente como uma estrutura de árvore referida como um documento enriquecido. Os mapeamentos de campos de saída permitem que você selecione quais partes dessa árvore serão mapeadas em campos em seu índice.
Apesar da semelhança nos nomes, mapeamentos de campo de saída e mapeamentos de campo criam associações de fontes diferentes. Os mapeamentos de campo associam o conteúdo do campo de origem a um campo de destino em um índice de pesquisa. Os mapeamentos de campo de saída associam o conteúdo de um documento interno enriquecido (saídas de habilidades) aos campos de destino no índice. Ao contrário dos mapeamentos de campo, que são considerados opcionais, um mapeamento de campo de saída é necessário para qualquer conteúdo transformado que deva estar no índice.
A próxima imagem mostra uma representação de sessão de depuração do indexador de exemplo dos estágios do indexador: quebra de documento, mapeamentos de campo, execução de conjunto de habilidades e mapeamentos de campo de saída.

Fluxo de trabalho básico
Os indexadores podem oferecer funcionalidades que são exclusivas da origem de dados. Relativamente a isto, alguns aspetos de configuração do indexador ou da origem de dados irão variar consoante o tipo de indexador. No entanto, todos os indexadores partilham da mesma composição e requisitos básicos. Os passos que são comuns a todos os indexadores são abordados abaixo.
Passo 1: criar uma origem de dados
Os indexadores exigem um objeto de fonte de dados que forneça uma cadeia de conexão e, possivelmente, credenciais. As fontes de dados são objetos independentes. Vários indexadores podem usar o mesmo objeto de fonte de dados para carregar mais de um índice de cada vez.
Você pode criar uma fonte de dados usando qualquer uma destas abordagens:
- Usando o portal do Azure, na guia Fontes de dados das páginas do serviço de pesquisa, selecione Adicionar fonte de dados para especificar a definição da fonte de dados.
- Usando o portal do Azure, o assistente Importar dados gera uma fonte de dados.
- Usando as APIs REST, chame Create Data Source.
- Usando o SDK do Azure para .NET, chame a classe SearchIndexerDataSourceConnection
Passo 2: criar um índice
Um indexador irá automatizar algumas tarefas relacionadas com a ingestão de dados, mas geralmente a criação de um índice não é uma delas. Como pré-requisito, você deve ter um índice predefinido que contenha campos de destino correspondentes para quaisquer campos de origem em sua fonte de dados externa. Os campos precisam corresponder por nome e tipo de dados. Caso contrário, você pode definir mapeamentos de campo para estabelecer a associação.
Para obter mais informações, consulte Criar um índice.
Etapa 3: Criar e executar (ou agendar) o indexador
Uma definição de indexador consiste em propriedades que identificam exclusivamente o indexador, especificam qual fonte de dados e índice usar e fornecem outras opções de configuração que influenciam os comportamentos de tempo de execução, incluindo se o indexador é executado sob demanda ou em uma agenda.
Quaisquer erros ou avisos sobre acesso a dados ou validação de conjunto de habilidades ocorrerão durante a execução do indexador. Até que a execução do indexador seja iniciada, os objetos dependentes, como fontes de dados, índices e conjuntos de habilidades, são passivos no serviço de pesquisa.
Para obter mais informações, consulte Criar um indexador
Após a primeira execução do indexador, você pode executá-lo novamente sob demanda ou configurar uma agenda.
Você pode monitorar o status do indexador no portal ou através da API Get Indexer Status. Você também deve executar consultas no índice para verificar se o resultado é o esperado.
Os indexadores não têm recursos de processamento dedicados. Com base nisso, o status dos indexadores pode aparecer como ocioso antes da execução (dependendo de outros trabalhos na fila) e os tempos de execução podem não ser previsíveis. Outros fatores também definem o desempenho do indexador, como tamanho do documento, complexidade do documento, análise de imagem, entre outros.
Próximos passos
Agora que você foi apresentado aos indexadores, uma próxima etapa é revisar as propriedades e os parâmetros do indexador, o agendamento e o monitoramento do indexador. Como alternativa, você pode retornar à lista de fontes de dados suportadas para obter mais informações sobre uma fonte específica.