Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Pesquisa de IA do Azure pode indexar documentos e arrays Markdown em Armazenamento de Blobs do Azure usando um indexador que sabe ler dados Markdown.
Este tutorial mostra-te como indexar ficheiros Markdown usando o oneToMany modo de análise Markdown e as APIs REST do Serviço de Pesquisa.
Neste tutorial, tu:
- Configure dados de amostra e estabeleça uma
azureblobfonte de dados - Crie um índice Pesquisa de IA do Azure para conter conteúdos pesquisáveis
- Crie e execute um indexador para ler o contentor e extrair conteúdos pesquisáveis
- Pesquisa no índice que acabaste de criar
Pré-requisitos
Uma conta no Azure com uma subscrição ativa. Cria uma conta gratuitamente.
Uma conta Armazenamento do Azure.
Um serviço Pesquisa de IA do Azure.
Visual Studio Code com a Extensão do Cliente REST.
Nota
Pode usar um serviço de pesquisa gratuito para este tutorial. O nível Gratuito limita-o a três índices, três indexadores e três fontes de dados. Este tutorial irá criar um de cada tipo. Antes de começar, certifique-se de que o seu serviço tem espaço para aceitar os novos recursos.
Preparar dados de amostra
Criar um ficheiro Markdown
Copie e cole o seguinte Markdown num ficheiro chamado sample_markdown.md. Os dados de exemplo são um único ficheiro Markdown contendo vários elementos Markdown. Escolhemos um ficheiro Markdown para ficar abaixo dos limites de armazenamento do nível Gratuito.
# Project Documentation
## Introduction
This document provides a complete overview of the **Markdown Features** used within this project. The following sections demonstrate the richness of Markdown formatting, with examples of lists, tables, links, images, blockquotes, inline styles, and more.
---
## Table of Contents
1. [Headers](#headers)
2. [Introduction](#introduction)
3. [Basic Text Formatting](#basic-text-formatting)
4. [Lists](#lists)
5. [Blockquotes](#blockquotes)
6. [Images](#images)
7. [Links](#links)
8. [Tables](#tables)
9. [Code Blocks and Inline Code](#code-blocks-and-inline-code)
10. [Horizontal Rules](#horizontal-rules)
11. [Inline Elements](#inline-elements)
12. [Escaping Characters](#escaping-characters)
13. [HTML Elements](#html-elements)
14. [Emojis](#emojis)
15. [Footnotes](#footnotes)
16. [Task Lists](#task-lists)
17. [Conclusion](#conclusion)
---
## Headers
Markdown supports six levels of headers. Use `#` to create headers:
"# Project Documentation" at the top of the document is an example of an h1 header.
"## Headers" above is an example of an h2 header.
### h3 example
#### h4 example
##### h5 example
###### h6 example
This is an example of content underneath a header.
## Basic Text Formatting
You can apply various styles to your text:
- **Bold**: Use double asterisks or underscores: `**bold**` or `__bold__`.
- *Italic*: Use single asterisks or underscores: `*italic*` or `_italic_`.
- ~~Strikethrough~~: Use double tildes: `~~strikethrough~~`.
## Lists
### Ordered List
1. First item
2. Second item
3. Third item
### Unordered List
- Item A
- Item B
- Item C
### Nested List
1. Parent item
- Child item
- Child item
## Blockquotes
> This is a blockquote.
> Blockquotes are great for emphasizing important information.
>> Nested blockquotes are also possible!
## Images

## Links
[Visit Markdown Guide](https://www.markdownguide.org)
## Tables
| Syntax | Description | Example |
|-------------|-------------|---------------|
| Header | Title | Header Cell |
| Paragraph | Text block | Row Content |
## Code Blocks and Inline Code
### Inline Code
Use backticks to create `inline code`.
### Code Block
```javascript
// JavaScript example
function greet(name) {
console.log(`Hello, ${name}!`);
}
greet('World');
```
## Horizontal Rules
Use three or more dashes or underscores to create a horizontal rule.
---
___
## Inline Elements
Sometimes, it’s useful to include `inline code` to highlight code-like content.
You can also emphasize text like *this* or make it **bold**.
## Escaping Characters
To render special Markdown characters, use backslashes:
- \*Asterisks\*
- \#Hashes\#
- \[Brackets\]
## HTML Elements
You can mix HTML tags with Markdown:
<table>
<tr>
<th>HTML Table</th>
<th>With Markdown</th>
</tr>
<tr>
<td>Row 1</td>
<td>Data 1</td>
</tr>
</table>
## Emojis
Markdown supports some basic emojis:
- :smile: 😄
- :rocket: 🚀
- :checkered_flag: 🏁
## Footnotes
This is an example of a footnote[^1]. Footnotes allow you to add notes without cluttering the main text.
[^1]: This is the content of the footnote.
## Task Lists
- [x] Complete the introduction
- [ ] Add more examples
- [ ] Review the document
## Conclusion
Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.
Thank you for reviewing this example!
Carregue o ficheiro e obtenha uma string de conexão
Siga estas instruções para carregar o ficheiro sample_markdown.md para um contentor na sua conta Armazenamento do Azure. Também deves obter a string de conexão da conta de armazenamento. Anota a cadeia de ligação e o nome do contentor para uso posterior.
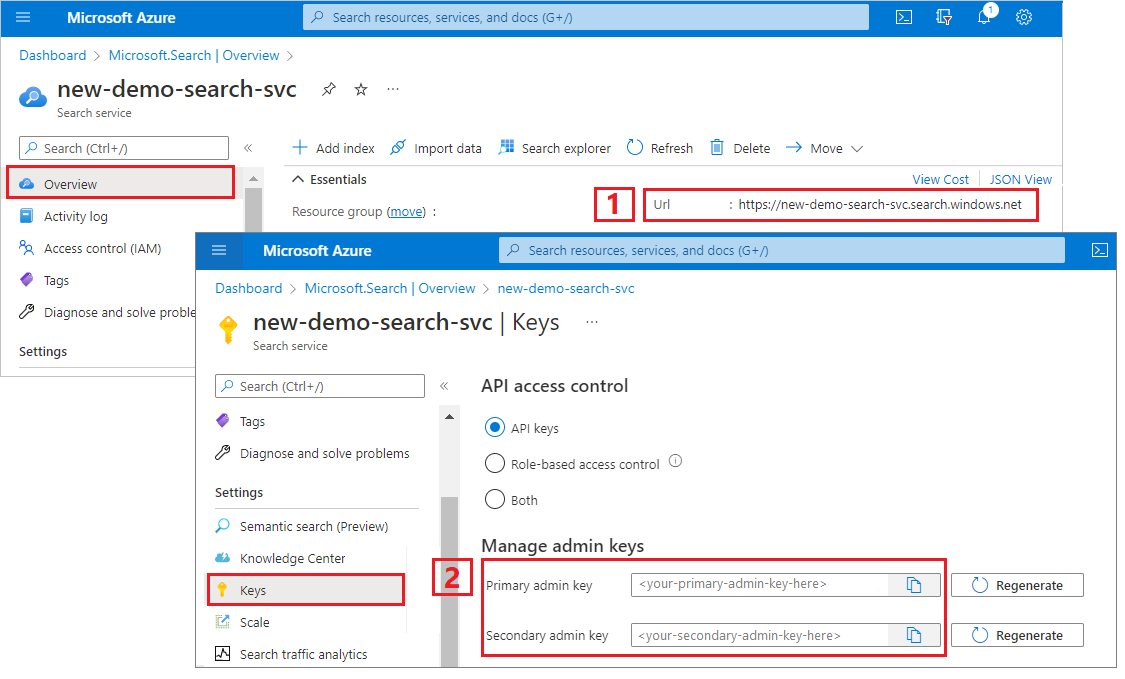
Copie um URL de serviço de pesquisa e uma chave API
Para este tutorial, as ligações ao Pesquisa de IA do Azure requerem um endpoint e uma chave API. Pode obter estes valores no portal do Azure. Para métodos alternativos de ligação, veja Identidades geridas.
Vá ao seu serviço de pesquisa no portal Azure.
No painel esquerdo, selecione Visão Geral.
Anote o URL, que deve parecer
https://my-service.search.windows.net.No painel esquerdo, selecione Definições>Teclas.
Anote uma chave de administrador para obter todos os direitos sobre o serviço. Existem duas chaves de administração intercambiáveis, fornecidas para a continuidade do negócio caso precise de transferir uma. Pode usar qualquer uma das chaves em solicitações para adicionar, modificar e eliminar objetos.
Configura o teu ficheiro REST
Crie um ficheiro no Visual Studio Code.
Forneça os valores das variáveis usadas no pedido.
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnectionString = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @blobContainer = PUT-YOUR-CONTAINER-NAME-HEREGuarde o ficheiro usando uma extensão de ficheiro
.restou.http.
Para ajuda com o cliente REST, consulte Quickstart: Pesquisa em texto completo usando REST.
Criar uma fonte de dados
Fontes de Dados - Create (API REST) cria uma ligação à fonte de dados que especifica que dados indexar.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Envia o pedido. A resposta deve ser a seguinte:
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
ETag: "0x8DCF52E926A3C76"
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net:443/datasources('sample-markdown-ds')?api-version=2026-04-01
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 0714c187-217e-4d35-928a-5069251e5cba
elapsed-time: 204
Date: Fri, 25 Oct 2024 19:52:35 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DCF52E926A3C76\"",
"name": "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": null
},
"container": {
"name": "markdown-container",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
Criar um índice
Índices - Create (REST API) cria um índice de pesquisa no seu serviço de pesquisa. Um índice especifica todos os campos e os seus atributos.
Na análise sintática um-para-muitos, o documento de pesquisa define o lado 'muitos' da relação. Os campos que especifica no índice determinam a estrutura do documento de pesquisa.
Só precisas de campos para os elementos Markdown que o parser suporta. Estes campos são:
content: Uma cadeia que contém o Markdown bruto encontrado numa localização específica, com base nos metadados do cabeçalho nesse ponto do documento.sections: Um objeto que contém subcampos para os metadados do cabeçalho até ao nível desejado do cabeçalho. Por exemplo, quandomarkdownHeaderDepthé definido parah3, contém corposh1de cadeia ,h2, eh3. Estes campos são indexados espelhando esta estrutura no índice, ou através de mapeamentos de campos no formato/sections/h1,/sections/h2, e assim sucessivamente. Para exemplos em contexto, veja as configurações de índice e indexador nos exemplos seguintes. Os subcampos contidos são:-
h1- Uma cadeia contendo o valor do cabeçalho h1. Cadeia vazia se não estiver definida neste ponto do documento. - (Opcional)
h2- Uma cadeia contendo o valor do cabeçalho h2. Cadeia vazia se não estiver definida neste ponto do documento. - (Opcional)
h3- Uma cadeia contendo o valor do cabeçalho h3. Cadeia vazia se não estiver definida neste ponto do documento. - (Opcional)
h4- Uma cadeia contendo o valor do cabeçalho h4. Cadeia vazia se não estiver definida neste ponto do documento. - (Opcional)
h5- Uma cadeia contendo o valor do cabeçalho h5. Cadeia vazia se não estiver definida neste ponto do documento. - (Opcional)
h6- Uma cadeia contendo o valor do cabeçalho h6. Cadeia vazia se não estiver definida neste ponto do documento.
-
ordinal_position: Um valor inteiro que indica a posição da secção dentro da hierarquia do documento. Este campo é usado para ordenar as secções na sua sequência original conforme aparecem no documento, começando com uma posição ordinal de 1 e incrementando sequencialmente para cada bloco de conteúdo.
Esta implementação utiliza mapeamentos de campos no indexador para mapear do conteúdo enriquecido para o índice. Para mais informações sobre a estrutura de documento analisada de um para muitos, consulte Blobs de Indexação Markdown.
Este exemplo fornece exemplos de como indexar dados tanto com como sem mapeamentos de campo. Neste caso, h1 contém o título do documento e corresponde a um campo chamado title. Os campos h2 e h3 correspondem, respetivamente, a h2_subheader e h3_subheader. Os campos content e ordinal_position não requerem mapeamento porque são extraídos diretamente do Markdown para campos que usam esses nomes. Para um exemplo de esquema de índice completo que não requer mapeamentos de campos, veja o final desta secção.
### Create an index
POST {{baseUrl}}/indexes?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "title", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
Esquema de índice numa configuração sem mapeamentos de campo
Os mapeamentos de campos permitem-lhe manipular e filtrar conteúdo enriquecido para se ajustar à forma de índice desejada. No entanto, talvez queira simplesmente utilizar o conteúdo enriquecido diretamente. Nesse caso, o esquema seria assim:
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "sections",
"type": "Edm.ComplexType",
"fields": [
{"name": "h1", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
Para reiterar, temos subcampos até h3 no objeto de secções porque markdownHeaderDepth é definido como h3.
Se usar este esquema, certifique-se de ajustar os pedidos posteriores em conformidade. Para isso, é necessário remover os mapeamentos de campos da configuração do indexador e atualizar as consultas de pesquisa para usar os respetivos nomes dos campos.
Criar e executar um indexador
Indexadores - Create (REST API) cria um indexador no seu serviço de pesquisa. Um indexador liga-se à fonte de dados, carrega e indexa os dados e, opcionalmente, fornece um calendário para automatizar a atualização dos dados.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-indexer",
"dataSourceName": "sample-markdown-ds",
"targetIndexName": "sample-markdown-index",
"parameters" : {
"configuration": {
"parsingMode": "markdown",
"markdownParsingSubmode": "oneToMany",
"markdownHeaderDepth": "h3"
}
},
"fieldMappings" : [
{
"sourceFieldName": "/sections/h1",
"targetFieldName": "title",
"mappingFunction": null
}
]
}
Pontos-chave:
O indexador analisa apenas cabeçalhos até
h3. Quaisquer cabeçalhos de nível inferior (h4,,)h5são tratados como texto simples e aparecem noh6contentcampo. É por isso que os mapeamentos de índice e campo só existem até uma profundidade deh3.Os campos
contenteordinal_positionnão requerem mapeamento de campo porque existem com esses nomes no conteúdo enriquecido.
Executar consultas
Pode começar a procurar assim que o primeiro documento for carregado.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
Envia o pedido. Esta é uma consulta de pesquisa em texto completo não especificada que devolve todos os campos marcados como recuperáveis no índice, juntamente com a contagem de documentos. A resposta deve ser a seguinte:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 6b94e605-55e8-47a5-ae15-834f926ddd14
elapsed-time: 77
Date: Fri, 25 Oct 2024 20:22:58 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 22,
"value": [
<22 search documents here>
]
}
Adicione um search parâmetro para procurar uma cadeia.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "h4",
"count": true
}
Envia o pedido. A resposta deve ser a seguinte:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: ec5d03f1-e3e7-472f-9396-7ff8e3782105
elapsed-time: 52
Date: Fri, 25 Oct 2024 20:26:29 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 0.8744742,
"section_id": "aHR0cHM6Ly9hcmphZ2Fubmpma2ZpbGVzLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tYXJrZG93bi10dXRvcmlhbC9zYW1wbGVfbWFya2Rvd24ubWQ7NA2",
"content": "#### h4 example\r\n##### h5 example\r\n###### h6 example\r\nThis is an example of content underneath a header.\r\n",
"title": "Project Documentation",
"h2_subheader": "Headers",
"h3_subheader": "h3 example",
"ordinal_position": 4
}
]
}
Pontos-chave:
Como o
markdownHeaderDepthestá definido comoh3, oh4,h5, eh6os cabeçalhos são tratados como texto simples, pelo que aparecem nocontentcampo.A posição ordinal aqui é
4. Este conteúdo aparece em quarto lugar entre as 22 secções totais de conteúdo.
Adicione um select parâmetro para limitar os resultados a menos campos. Adicione filter para restringir ainda mais a pesquisa.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "Markdown",
"count": true,
"select": "title, content, h2_subheader",
"filter": "h2_subheader eq 'Conclusion'"
}
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: a6f9bd46-a064-4e28-818f-ea077618014b
elapsed-time: 35
Date: Fri, 25 Oct 2024 20:36:10 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 1.1029507,
"content": "Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.\r\n\r\nThank you for reviewing this example!",
"title": "Project Documentation",
"h2_subheader": "Conclusion"
}
]
}
Para filtros, também podes usar operadores lógicos (and, ou, não) e operadores de comparação (eq, ne, gt, lt, ge, le). As comparações de cadeias de caracteres são sensíveis a maiúsculas e minúsculas. Para mais informações e exemplos, veja Criar uma consulta.
Nota
O $filter parâmetro só funciona em campos que foram marcados como filtráveis na criação do seu índice.
Reiniciar e repetir
Os indexadores podem ser reiniciados para limpar o histórico de execução, o que permite uma repetição completa. Os pedidos seguintes reiniciam e reexecutam o indexador.
### Reset the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/reset?api-version=2026-04-01 HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/run?api-version=2026-04-01 HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/sample-markdown-indexer/status?api-version=2026-04-01 HTTP/1.1
api-key: {{apiKey}}
Recursos de limpeza
Quando trabalha com a sua própria subscrição, no final de um projeto, é boa ideia remover os recursos que já não precisa. Os recursos que restam a funcionar podem custar-te dinheiro. Podes eliminar recursos individualmente ou eliminar o grupo de recursos para eliminar todo o conjunto de recursos.
Pode usar o portal do Azure para eliminar índices, indexadores e fontes de dados.
Próximos passos
Agora que já está familiarizado com os fundamentos da indexação Azure Blob, olhe mais de perto para a configuração do indexador para blobs Markdown no Armazenamento do Azure: