Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este artigo é uma coleção de dicas e práticas recomendadas para aumentar o desempenho de consulta e indexação para pesquisa de palavras-chave. Saber quais são os fatores com maior probabilidade de afetar o desempenho da pesquisa pode ajudá-lo a evitar ineficiências e a tirar o máximo partido do seu serviço de pesquisa. Alguns fatores-chave incluem:
- Composição do índice (esquema e tamanho)
- Design de consulta
- Capacidade de serviço (camada e número de réplicas e partições)
Nota
À procura de estratégias para indexação de grande volume? Consulte Indexar grandes conjuntos de dados no Azure AI Search.
Tamanho e esquema do índice
As consultas são executadas mais rapidamente em índices menores. Isso é em parte uma função de ter menos campos para verificar, mas também é devido à forma como o sistema armazena em cache o conteúdo para consultas futuras. Após a primeira consulta, algum conteúdo permanece na memória onde é pesquisado de forma mais eficiente. Como o tamanho do índice tende a crescer com o tempo, uma prática recomendada é revisitar periodicamente a composição do índice, tanto o esquema quanto os documentos, para procurar oportunidades de redução de conteúdo. No entanto, se o índice for de tamanho correto, a única outra calibração que você pode fazer é aumentar a capacidade atualizando seu serviço, adicionando réplicas ou mudando para um nível de preço mais alto. A seção "Dica: Alternar para uma camada S2 padrão" discute a decisão de aumentar ou reduzir.
A complexidade do esquema também pode afetar negativamente a indexação e o desempenho da consulta. A atribuição excessiva de campo aumenta as limitações e os requisitos de processamento. Tipos complexos levam mais tempo para indexar e consultar. As próximas seções exploram cada condição.
Dica: Seja seletivo na atribuição de campo
Um erro comum que administradores e desenvolvedores cometem ao criar um índice de pesquisa é selecionar todas as propriedades disponíveis para os campos, em vez de selecionar apenas as propriedades necessárias. Por exemplo, se um campo não precisar ser pesquisável em texto completo, ignore esse campo ao definir o atributo pesquisável.
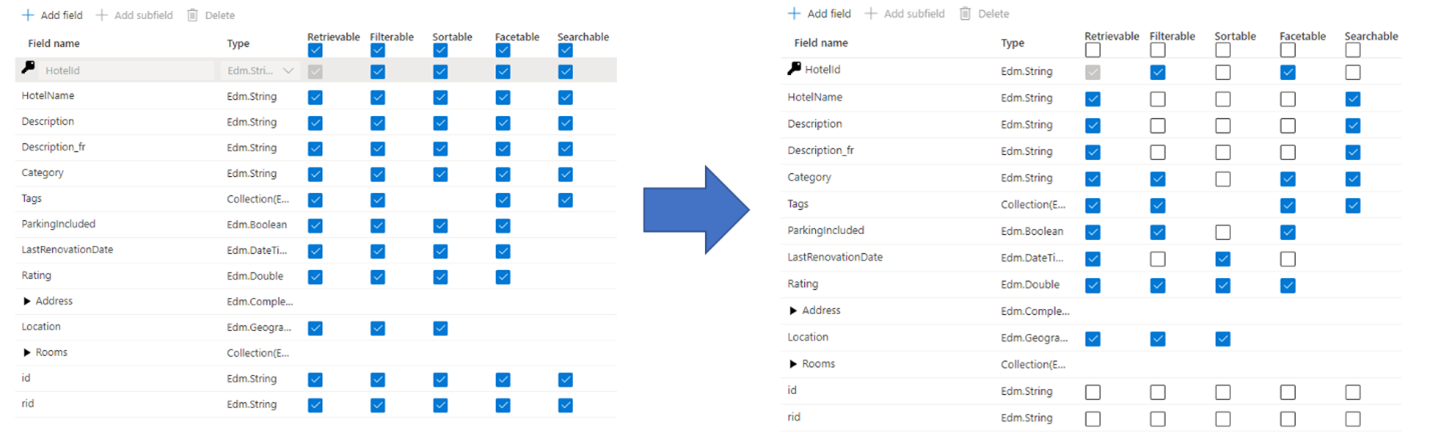
O suporte para filtros, facetas e classificação pode quadruplicar os requisitos de armazenamento. Se você adicionar sugestões, os requisitos de armazenamento aumentam ainda mais. Para obter uma ilustração sobre o impacto dos atributos no armazenamento, consulte Atributos e tamanho do índice.
Resumidamente, as ramificações da atribuição excessiva incluem:
Degradação do desempenho de indexação devido ao trabalho extra necessário para processar o conteúdo no campo e, em seguida, armazená-lo dentro do índice invertido de pesquisa (defina o atributo "pesquisável" apenas em campos que contenham conteúdo pesquisável).
Cria uma superfície maior que cada consulta deve cobrir. Todos os campos marcados como pesquisáveis são digitalizados numa pesquisa de texto completo.
Aumenta os custos operacionais devido ao armazenamento extra. A filtragem e a classificação exigem espaço adicional para armazenar cadeias de caracteres originais (não analisadas). Evite definir filtrável ou classificável em campos que não precisam.
Em muitos casos, a atribuição excessiva limita as capacidades do campo. Por exemplo, se um campo for facetável, filtrável e pesquisável, só se pode armazenar 16 KB de texto nesse campo, enquanto um campo pesquisável pode conter até 16 MB de texto.
Nota
Apenas a atribuição desnecessária deve ser evitada. Filtros e facetas são muitas vezes essenciais para a experiência de pesquisa e, nos casos em que os filtros são usados, você frequentemente precisa de classificação para que possa ordenar os resultados (os filtros por si só retornam em um conjunto não ordenado).
Dica: considere alternativas para tipos complexos
Tipos de dados complexos são úteis quando os dados têm uma estrutura aninhada complicada, como os elementos pai-filho encontrados em documentos JSON. A desvantagem dos tipos complexos são os requisitos de armazenamento extra e os recursos adicionais necessários para indexar o conteúdo, em comparação com os tipos de dados não complexos.
Em alguns casos, pode-se evitar esses compromissos ao mapear uma estrutura de dados complexa para um tipo de campo mais simples, como uma coleção. Como alternativa, você pode optar por nivelar uma hierarquia de campo em campos de nível raiz individuais.

Design de consulta
A composição e a complexidade da consulta são um dos fatores mais importantes para o desempenho, e a otimização da consulta pode melhorar drasticamente o desempenho. Ao criar consultas, pense nos seguintes pontos:
Número de campos pesquisáveis. Cada campo pesquisável adicional resulta em mais trabalho para o serviço de pesquisa. Você pode limitar os campos que estão sendo pesquisados no momento da consulta usando o parâmetro "searchFields". É melhor especificar apenas os campos que mais lhe interessam para melhorar o desempenho.
Quantidade de dados que estão sendo retornados. A recuperação de uma grande quantidade de conteúdo pode tornar as consultas mais lentas. Ao estruturar uma consulta, devolva apenas os campos que necessita para compor a página de resultados e, em seguida, obtenha os campos restantes com a API de Procura assim que um utilizador selecionar uma correspondência.
Utilização de pesquisas parciais de termos.Pesquisas parciais de termos, como pesquisa de prefixo, pesquisa difusa e pesquisa de expressão regular, são mais caras computacionalmente do que as pesquisas de palavras-chave típicas, pois exigem varreduras completas de índice para produzir resultados.
Número de facetas. Adicionar facetas às consultas requer agregações para cada consulta. Solicitar uma "contagem" mais elevada para uma faceta também requer trabalho adicional do serviço. Em geral, adicione apenas as facetas que planeia renderizar na sua aplicação e evite solicitar uma contagem elevada de facetas, a menos que seja necessário.
Valores de salto altos. Definir o parâmetro
$skippara um valor elevado (por exemplo, para milhares) aumenta a latência de pesquisa porque o motor está a obter e a classificar um maior volume de documentos para cada pedido. Por motivos de desempenho, é melhor evitar valores$skipelevados e utilizar outras técnicas, como a filtragem, para obter grandes números de documentos.Limite os campos de cardinalidade elevada. Um campo de cardinalidade alta refere-se a uma tabela facial ou campo filtrável que tem um número significativo de valores exclusivos e, como resultado, consome recursos significativos ao calcular resultados. Por exemplo, definir um campo ID do Produto ou Descrição como facetable e filtrável contaria como cardinalidade alta porque a maioria dos valores de documento para documento são exclusivos.
Dica: use funções de pesquisa em vez de sobrecarregar os critérios de filtro
Como uma consulta usa critérios de filtro cada vez mais complexos, o desempenho da consulta de pesquisa diminuirá. Considere o exemplo a seguir que demonstra o uso de filtros para cortar resultados com base em uma identidade de usuário:
$filter= userid eq 123 or userid eq 234 or userid eq 345 or userid eq 456 or userid eq 567
Nesse caso, as expressões de filtro são usadas para verificar se um único campo em cada documento é igual a um dos muitos valores possíveis de uma identidade de usuário. É mais provável que você encontre esse padrão em aplicativos que implementam filtragem de segurança (verificando um campo contendo uma ou mais IDs principais em relação a uma lista de IDs principais que representam o usuário que emite a consulta).
Uma maneira mais eficiente de executar filtros que contêm um grande número de valores é usar search.in a função, como mostrado neste exemplo:
search.in(userid, '123,234,345,456,567', ',')
Dica: Adicione partições para consultas individuais lentas
Quando o desempenho das consultas diminui de modo geral, adicionar mais réplicas frequentemente resolve o problema. Mas e se o problema for uma única consulta que demora muito tempo a concluir? Nesse cenário, adicionar réplicas não ajudará, mas mais partições poderão ajudar. Uma partição divide os dados entre recursos de computação extras. Duas partições dividem os dados ao meio, uma terceira partição os divide em terços, e assim por diante.
Um efeito colateral positivo da adição de partições é que consultas mais lentas às vezes têm um desempenho mais rápido devido à computação paralela. Observamos paralelização em consultas de baixa seletividade, como consultas que correspondem a muitos documentos ou facetas que fornecem contagens sobre um grande número de documentos. Como é necessário um cálculo significativo para pontuar a relevância dos documentos ou para contar o número de documentos, adicionar partições extras ajuda a concluir as consultas mais rapidamente.
Para adicionar partições, use o portal do Azure, PowerShell, CLI do Azure ou um SDK de gerenciamento.
Capacidade de serviço
Um serviço fica sobrecarregado quando as consultas demoram muito tempo ou quando o serviço começa a descartar solicitações. Se isso acontecer, você pode resolver o problema atualizando o serviço ou adicionando capacidade.
A camada do seu serviço de pesquisa e o número de réplicas/partições também têm um grande impacto no desempenho. Cada camada progressivamente mais alta fornece CPUs mais rápidas e mais memória, o que tem um impacto positivo no desempenho.
Dica: crie um novo serviço de pesquisa de alta capacidade
Os serviços básicos e padrão criados em regiões suportadas após 3 de abril de 2024 têm mais armazenamento por partição do que os serviços mais antigos. Se tiver um serviço mais antigo, verifique se pode atualizar o seu serviço para beneficiar de mais capacidade com a mesma taxa de faturação. Se uma atualização não estiver disponível, revise os limites de serviço de camada para ver se a mesma camada em um serviço mais recente oferece o armazenamento necessário.
Dica: Mude para uma camada S2 padrão
A camada de pesquisa Standard S1 geralmente é onde os clientes começam. Um padrão comum para serviços S1 é que os índices crescem ao longo do tempo, o que requer mais partições. Mais partições levam a tempos de resposta mais lentos, portanto, mais réplicas são adicionadas para lidar com a carga da consulta. Como você pode imaginar, o custo de execução de um serviço S1 agora progrediu para níveis além da configuração inicial.
Nesta conjuntura, uma questão importante a fazer é se seria benéfico mudar para um nível de preços mais elevado, em vez de aumentar progressivamente o número de partições ou réplicas do serviço atual.
Considere a topologia a seguir como um exemplo de um serviço que assumiu níveis crescentes de capacidade:
- Nível S1 padrão
- Tamanho do índice: 190 GB
- Contagem de partições: 8 (em S1, o tamanho da partição é de 25 GB por partição)
- Contagem de réplicas: 2
- Total de unidades de pesquisa: 16 (8 partições x 2 réplicas)
- Preço de varejo hipotético: ~$4.000 USD / mês (suponha 250 USD x 16 unidades de pesquisa)
Suponha que o administrador de serviço ainda esteja vendo taxas de latência mais altas e esteja considerando adicionar outra réplica. Isso mudaria a contagem de réplicas de 2 para 3 e, como resultado, alteraria a contagem de unidades de pesquisa para 24 e um preço resultante de US$ 6.000/mês.
No entanto, se o administrador optar por mudar para uma camada Standard S2, a topologia terá a seguinte aparência:
- Nível S2 padrão
- Tamanho do índice: 190 GB
- Contagem de partições: 2 (no S2, o tamanho da partição é de 100 GB por partição)
- Contagem de réplicas: 2
- Total de unidades de pesquisa: 4 (2 partições x 2 réplicas)
- Preço de varejo hipotético: ~$4,000 USD / mês (1,000 USD x 4 unidades de pesquisa)
Como este cenário hipotético ilustra, você pode ter configurações em camadas mais baixas que resultam em custos semelhantes como se você tivesse optado por uma camada mais alta em primeiro lugar. No entanto, os níveis mais altos vêm com armazenamento premium, o que torna a indexação mais rápida. Níveis mais altos também têm muito mais poder de computação, bem como memória extra. Pelos mesmos custos, você poderia ter uma infraestrutura mais poderosa suportando o mesmo índice.
Um benefício importante da memória adicionada é que mais do índice pode ser armazenado em cache, resultando em menor latência de pesquisa e um maior número de consultas por segundo. Com esse poder extra, o administrador pode nem precisar aumentar a contagem de réplicas e pode potencialmente pagar menos do que permanecer no serviço S1.
Dica: considere alternativas às consultas de expressão regular
Consultas de expressão regular, ou regex, podem ser particularmente dispendiosas. Embora possam ser muito úteis para pesquisas avançadas, a execução pode exigir muito poder de processamento, especialmente se a expressão regular for complicada ou se você estiver pesquisando uma grande quantidade de dados. Todos esses fatores contribuem para uma alta latência de pesquisa. Como atenuação, tente simplificar a expressão regular ou dividir a consulta complexa em consultas menores e mais gerenciáveis.
Próximos passos
Analise estes outros artigos relacionados ao desempenho do serviço: