Preparar para reproteção e reativação pós-falha de VMs do VMware
Após a ativação pós-falha de VMs VMware no local ou servidores físicos para o Azure, volta a proteger as VMs do Azure criadas após a ativação pós-falha, para que sejam replicadas novamente para o site no local. Com a replicação do Azure para o local no local, pode efetuar a reativação pós-falha ao executar uma ativação pós-falha do Azure para o local quando estiver pronto.
Componentes de reproteção ou reativação pós-falha
Precisa de vários componentes e definições antes de poder voltar a proteger e efetuar a reativação pós-falha do Azure.
| Componente | Detalhes |
|---|---|
| Servidor de configuração no local | O servidor de configuração no local tem de estar em execução e ligado ao Azure. A VM para a qual está a falhar tem de existir na base de dados do servidor de configuração. Se o desastre afetar o servidor de configuração, restaure-o com o mesmo endereço IP para garantir que a reativação pós-falha funciona. Se os endereços IP das máquinas replicadas forem mantidos na ativação pós-falha, a conectividade site a site (ou conectividade do ExpressRoute) deve ser estabelecida entre as máquinas virtuais das VMs do Azure e a NIC de reativação pós-falha do servidor de configuração. Para endereços IP retidos, o servidor de configuração precisa de dois NICs: um para a conectividade do computador de origem e outro para a conectividade de reativação pós-falha do Azure. Isto evita a sobreposição de intervalos de endereços de sub-rede para a origem e a ativação pós-falha de VMs. |
| Servidor de processos no Azure | Precisa de um servidor de processos no Azure antes de poder efetuar a reativação pós-falha para o seu site no local. O servidor de processos recebe dados da VM do Azure protegida e envia-os para o site no local. Precisa de uma rede de baixa latência entre o servidor de processos e a VM protegida, pelo que recomendamos que implemente o servidor de processos no Azure para um desempenho de replicação mais elevado. Para prova de conceito, pode utilizar o servidor de processos no local e o ExpressRoute com peering privado. O servidor de processos deve estar na rede do Azure na qual a VM com ativação pós-falha está localizada. O servidor de processos também tem de conseguir comunicar com o servidor de configuração no local e com o servidor de destino principal. |
| Separar o servidor de destino principal | O servidor de destino principal recebe dados de reativação pós-falha e, por predefinição, um servidor de destino principal do Windows é executado no servidor de configuração no local. Um servidor de destino principal pode ter até 60 discos ligados ao mesmo. Se a reativação pós-falha das VMs tiver mais do que um total coletivo de 60 discos ou se estiver a efetuar a reativação pós-falha de grandes volumes de tráfego, crie um servidor de destino principal separado para reativação pós-falha. Se as máquinas forem recolhidas num grupo de replicação para consistência de várias VMs, as VMs têm de ser todas windows ou todas têm de ser Linux. Porquê? Uma vez que todas as VMs num grupo de replicação têm de utilizar o mesmo servidor de destino principal e o servidor de destino principal tem de ter o mesmo sistema operativo (com a mesma versão ou uma versão superior) do que as das máquinas replicadas. O servidor de destino principal não deve ter instantâneos nos discos, caso contrário, a reproteção e a reativação pós-falha não funcionarão. O destino principal não pode ter um controlador SCSI paravirtual. O controlador só pode ser um controlador de Lógica LSI. Sem um controlador LSI Logic, a reproteção falha. |
| Política de replicação de reativação pós-falha | Para replicar novamente para o site no local, precisa de uma política de reativação pós-falha. Esta política é criada automaticamente quando cria uma política de replicação para o Azure. A política é associada automaticamente ao servidor de configuração. Está definido como um limiar RPO de 15 minutos, retenção do ponto de recuperação de 24 horas e a frequência de instantâneo consistente com a aplicação é de 60 minutos. Não é possível editar a política. |
| Peering privado de VPN/ExpressRoute site a site | A reproteção e a reativação pós-falha precisam de uma ligação VPN site a site ou peering privado do ExpressRoute para replicar dados. |
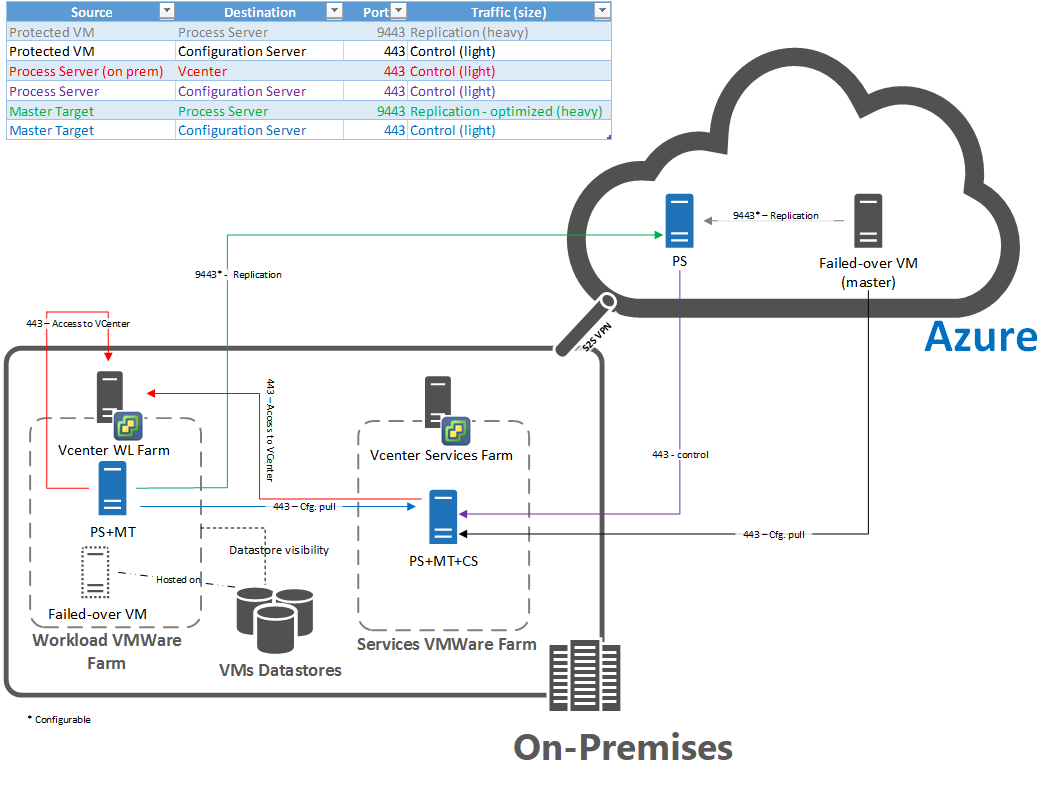
Portas para reproteção/reativação pós-falha
Tem de abrir várias portas para reproteção/reativação pós-falha. O gráfico seguinte ilustra as portas e o fluxo de reproteção/reativação pós-falha.
Implementar um servidor de processos no Azure
- Configure um servidor de processos no Azure para reativação pós-falha.
- Certifique-se de que as VMs do Azure conseguem aceder ao servidor de processos.
- Certifique-se de que a ligação VPN site a site ou a rede de peering privado do ExpressRoute têm largura de banda suficiente para enviar dados do servidor de processos para o site no local.
Implementar um servidor de destino principal separado
Tenha em atenção os requisitos e limitações do servidor de destino principal.
Crie um servidor de destino principal do Windows ou Linux para corresponder ao sistema operativo das VMs que pretende proteger novamente e efetuar a reativação pós-falha.
Certifique-se de que não utiliza o Armazenamento vMotion para o servidor de destino principal ou se a reativação pós-falha pode falhar. O computador da VM não consegue iniciar porque os discos não estão disponíveis para o mesmo.
- Para evitar esta situação, exclua o servidor de destino principal da sua lista vMotion.
- Se um destino principal for submetido a uma tarefa vMotion de Armazenamento após a reproteção, os discos de VM protegidos anexados ao servidor de destino principal migram para o destino da tarefa vMotion. Se tentar efetuar a reativação pós-falha após esta ação, o desanexamento do disco falhará porque os discos não foram encontrados. Em seguida, é difícil encontrar os discos nas suas contas de armazenamento. Se isto ocorrer, localize-os manualmente e anexe-os à VM. Depois disso, a VM no local pode ser iniciada.
Adicione uma unidade de retenção ao servidor de destino principal do Windows existente. Adicione um novo disco e formate a unidade. A unidade de retenção é utilizada para parar os pontos no tempo em que a VM é replicada novamente para o site no local. Tenha em atenção estes critérios. Se não forem cumpridas, a unidade não está listada para o servidor de destino principal:
- O volume não é utilizado para qualquer outra finalidade, como um destino de replicação e não está no modo de bloqueio.
- O volume não é um volume de cache. O volume de instalação personalizado para o servidor de processos e o destino principal não é elegível para um volume de retenção. Quando o servidor de processos e o destino principal são instalados num volume, o volume é um volume de cache do destino principal.
- O tipo de sistema de ficheiros do volume não é FAT ou FAT32.
- A capacidade de volume não é azero.
- O volume de retenção predefinido para Windows é o volume R.
- O volume de retenção predefinido para Linux é /mnt/retention.
Adicione uma unidade se estiver a utilizar um servidor de processos existente. A nova unidade tem de cumprir os requisitos no último passo. Se a unidade de retenção não estiver presente, não será apresentada na lista pendente de seleção no portal. Depois de adicionar uma unidade ao destino principal no local, a unidade demora até 15 minutos a aparecer na seleção no portal. Pode atualizar o servidor de configuração se a unidade não aparecer após 15 minutos.
Instale ferramentas VMware ou open-vm-tools no servidor de destino principal. Sem as ferramentas, os arquivos de dados no anfitrião ESXi do destino principal não podem ser detetados.
Defina o disco. EnableUUID=true definição nos parâmetros de configuração da VM de destino principal no VMware. Se esta linha não existir, adicione-a. Esta definição é necessária para fornecer um UUID consistente ao VMDK para que seja montado corretamente.
Verifique os requisitos de acesso do vCenter Server:
- Se a VM para a qual está a efetuar a reativação pós-falha estiver num anfitrião ESXi gerido pelo VMware vCenter Server, o servidor de destino principal precisa de acesso ao ficheiro VM Virtual Machine Disk (VMDK) no local, para escrever os dados replicados nos discos da máquina virtual. Certifique-se de que o arquivo de dados da VM no local está montado no anfitrião de destino principal com acesso de leitura/escrita.
- Se a VM não estiver num anfitrião ESXi gerido por um VMware vCenter Server, Site Recovery cria uma nova VM durante a reproteção. Esta VM é criada no anfitrião ESXi no qual cria a VM do servidor de destino principal. Escolha cuidadosamente o anfitrião ESXi para criar a VM no anfitrião pretendido. O disco rígido da VM tem de estar num arquivo de dados que seja acessível pelo anfitrião no qual o servidor de destino principal está em execução.
- Outra opção, se a VM no local já existir para a reativação pós-falha, é eliminá-la antes de efetuar uma reativação pós-falha. Em seguida, a reativação pós-falha cria uma nova VM no mesmo anfitrião que o anfitrião ESXi de destino principal. Quando efetua a reativação pós-falha para uma localização alternativa, os dados são recuperados para o mesmo arquivo de dados e para o mesmo anfitrião ESXi que o utilizado pelo servidor de destino principal no local.
Para máquinas físicas com falhas nas VMs VMware, deve concluir a deteção do anfitrião no qual o servidor de destino principal está em execução, antes de poder voltar a proteger o computador.
Verifique se o anfitrião ESXi no qual a VM de destino principal tem, pelo menos, um arquivo de dados do sistema de ficheiros de máquina virtual (VMFS) ligado ao mesmo. Se não estiverem anexados arquivos de dados VMFS, a entrada do arquivo de dados nas definições de reproteção estará vazia e não poderá continuar.
Passos seguintes
Saiba como voltar a proteger uma VM.