Migração do StorSimple 1200 para o Azure File Sync
A série StorSimple 1200 é uma aplicação virtual que é executada num datacenter no local. É possível migrar os dados desta aplicação para um ambiente Azure File Sync. Azure File Sync é o serviço predefinido e estratégico de longo prazo do Azure para o qual as aplicações storSimple podem ser migradas. Este artigo fornece os passos necessários de conhecimentos e migrações em segundo plano para uma migração com êxito para Azure File Sync.
Nota
O Serviço StorSimple (incluindo o StorSimple Gestor de Dispositivos para as séries 8000 e 1200 e o StorSimple Data Manager) chegou ao fim do suporte. O fim do suporte para o StorSimple foi publicado em 2019 nas páginas Política de Ciclo de Vida da Microsoft e Comunicações do Azure . Foram enviadas notificações adicionais por e-mail e publicadas no portal do Azure e na descrição geral do StorSimple. Contacte Suporte da Microsoft para obter detalhes adicionais.
Aplica-se a
| Tipo de partilhas de ficheiros | SMB | NFS |
|---|---|---|
| Partilhas de ficheiros Standard (GPv2), LRS/ZRS | ||
| Partilhas de ficheiros Standard (GPv2), GRS/GZRS | ||
| Partilhas de ficheiros Premium (FileStorage), LRS/ZRS |
Azure File Sync
Azure File Sync é um serviço cloud da Microsoft, baseado em dois componentes principais:
- Sincronização de ficheiros e arrumo na cloud.
- Partilhas de ficheiros como armazenamento nativo no Azure, que podem ser acedidas através de vários protocolos, como SMB e REST de ficheiros. Uma partilha de ficheiros do Azure é comparável a uma partilha de ficheiros num Windows Server, que pode montar nativamente como uma unidade de rede. Suporta aspetos importantes de fidelidade de ficheiros, como atributos, permissões e carimbos de data/hora. Ao contrário do StorSimple, não é necessária nenhuma aplicação/serviço para interpretar os ficheiros e pastas armazenados na cloud. A abordagem ideal e mais flexível para armazenar dados do servidor de ficheiros para fins gerais e alguns dados da aplicação na cloud.
Este artigo centra-se nos passos de migração. Se antes de migrar quiser saber mais sobre Azure File Sync, recomendamos os seguintes artigos:
Objetivos de migração
O objetivo é garantir a integridade dos dados de produção e garantir a disponibilidade. Este último requer um mínimo de tempo de inatividade, para que possa caber ou exceder ligeiramente as janelas de manutenção regulares.
Caminho de migração do StorSimple 1200 para Azure File Sync
É necessário um Windows Server local para executar um agente Azure File Sync. O Windows Server pode ser, no mínimo, um servidor 2012R2, mas idealmente é um Windows Server 2019.
Existem inúmeros caminhos de migração alternativos e criaria demasiado tempo de um artigo para documentar todos eles e ilustrar por que razão suportam riscos ou desvantagens sobre a rota que recomendamos como melhor prática neste artigo.
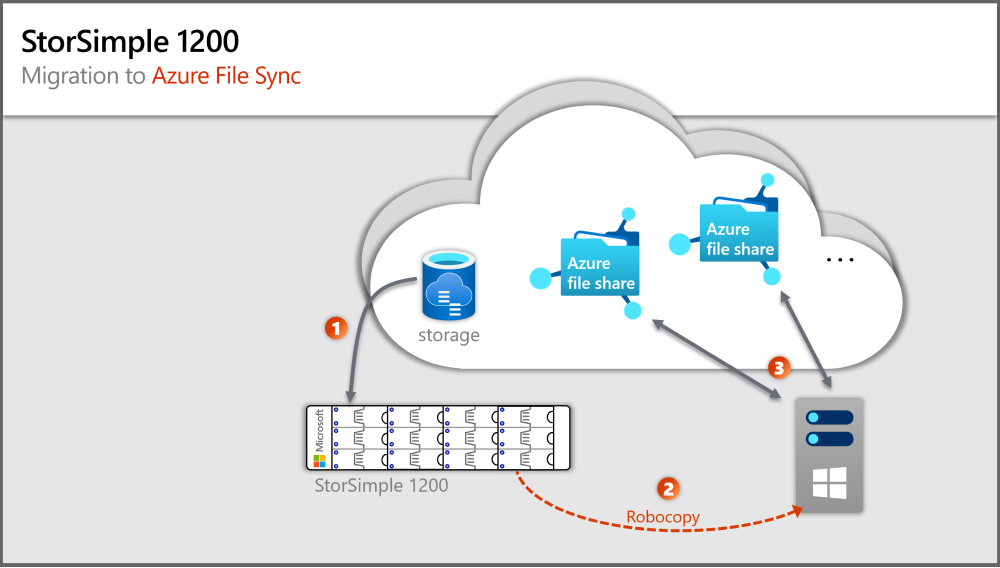
A imagem anterior ilustra os passos que correspondem às secções neste artigo.
Passo 1: Aprovisionar o Windows Server no local e o armazenamento
- Crie um Windows Server 2019 , no mínimo 2012R2, como uma máquina virtual ou servidor físico. Também é suportado um cluster de ativação pós-falha do Windows Server.
- Aprovisionar ou adicionar Armazenamento Ligado Direto (DAS em comparação com NAS, o que não é suportado). O tamanho do armazenamento do Windows Server tem de ser igual ou maior do que o tamanho da capacidade disponível da sua aplicação virtual StorSimple 1200.
Passo 2: Configurar o armazenamento do Windows Server
Neste passo, vai mapear a estrutura de armazenamento do StorSimple (volumes e partilhas) para a sua estrutura de armazenamento do Windows Server. Se planeia fazer alterações à sua estrutura de armazenamento, ou seja, o número de volumes, a associação de pastas de dados a volumes ou a estrutura da subpasta acima ou abaixo das partilhas SMB/NFS atuais, agora é a altura de ter estas alterações em consideração. A alteração da estrutura de ficheiros e pastas após a configuração do Azure File Sync é complicada e deve ser evitada. Este artigo pressupõe que está a mapear 1:1, pelo que tem de ter em consideração as alterações de mapeamento quando seguir os passos neste artigo.
- Nenhum dos seus dados de produção deve acabar no volume de sistema do Windows Server. O arrumo na cloud não é suportado em volumes de sistema. No entanto, esta funcionalidade é necessária para a migração, bem como operações contínuas como uma substituição do StorSimple.
- Aprovisione o mesmo número de volumes no Windows Server que tem na sua aplicação virtual StorSimple 1200.
- Configure todas as funções, funcionalidades e definições do Windows Server de que precisa. Recomendamos que opte pelas atualizações do Windows Server para manter o SO seguro e atualizado. Da mesma forma, recomendamos que opte pelo Microsoft Update para manter as aplicações da Microsoft atualizadas, incluindo o agente Azure File Sync.
- Não configure quaisquer pastas ou partilhas antes de ler os seguintes passos.
Passo 3: implementar o primeiro recurso Azure File Sync cloud
Para concluir este passo, precisa das suas credenciais de subscrição do Azure.
O recurso principal a configurar para Azure File Sync é denominado Serviço de Sincronização de Armazenamento. Recomendamos que implemente apenas um para todos os servidores que estão a sincronizar o mesmo conjunto de ficheiros agora ou no futuro. Crie vários Serviços de Sincronização de Armazenamento apenas se tiver conjuntos distintos de servidores que nunca devem trocar dados. Por exemplo, poderá ter servidores que nunca devem sincronizar a mesma partilha de ficheiros do Azure. Caso contrário, utilizar um único Serviço de Sincronização de Armazenamento é a melhor prática.
Escolha uma região do Azure para o Serviço de Sincronização de Armazenamento que esteja perto da sua localização. Todos os outros recursos da cloud têm de ser implementados na mesma região. Para simplificar a gestão, crie um novo grupo de recursos na sua subscrição que aloja recursos de sincronização e armazenamento.
Para obter mais informações, veja a secção sobre como implementar o Serviço de Sincronização de Armazenamento no artigo sobre como implementar Azure File Sync. Siga apenas esta secção do artigo. Haverá ligações para outras secções do artigo em passos posteriores.
Passo 4: Corresponder o volume local e a estrutura de pastas aos recursos de partilha de ficheiros do Azure File Sync e do Azure
Neste passo, irá determinar quantas partilhas de ficheiros do Azure precisa. Uma única instância do Windows Server (ou cluster) pode sincronizar até 30 partilhas de ficheiros do Azure.
Poderá ter mais pastas nos volumes que partilha atualmente localmente como partilhas SMB com os seus utilizadores e aplicações. A forma mais fácil de imaginar este cenário é visualizar uma partilha no local que mapeia 1:1 para uma partilha de ficheiros do Azure. Se tiver um número suficientemente pequeno de partilhas, abaixo de 30 para uma única instância do Windows Server, recomendamos um mapeamento 1:1.
Se tiver mais de 30 partilhas, o mapeamento de uma partilha no local 1:1 para uma partilha de ficheiros do Azure é, muitas vezes, desnecessário. Considere as seguintes opções.
Partilhar agrupamento
Por exemplo, se o departamento de recursos humanos (RH) tiver 15 partilhas, poderá considerar armazenar todos os dados de RH numa única partilha de ficheiros do Azure. Armazenar várias partilhas no local numa partilha de ficheiros do Azure não o impede de criar as habituais partilhas de 15 SMB na sua instância do Windows Server local. Significa apenas que organiza as pastas raiz destas 15 partilhas como subpastas numa pasta comum. Em seguida, sincroniza esta pasta comum com uma partilha de ficheiros do Azure. Desta forma, só é necessária uma única partilha de ficheiros do Azure na cloud para este grupo de partilhas no local.
Sincronização de volume
Azure File Sync suporta a sincronização da raiz de um volume com uma partilha de ficheiros do Azure. Se sincronizar a raiz do volume, todas as subpastas e ficheiros irão para a mesma partilha de ficheiros do Azure.
Sincronizar a raiz do volume nem sempre é a melhor opção. Existem vantagens em sincronizar várias localizações. Por exemplo, fazê-lo ajuda a manter o número de itens mais baixo por âmbito de sincronização. Testamos partilhas de ficheiros do Azure e Azure File Sync com 100 milhões de itens (ficheiros e pastas) por partilha. Mas uma melhor prática é tentar manter o número abaixo de 20 milhões ou 30 milhões numa única parte. Configurar Azure File Sync com um número mais baixo de itens não é vantajoso apenas para a sincronização de ficheiros. Um número mais baixo de itens também beneficia cenários como estes:
- A análise inicial do conteúdo da cloud pode ser concluída mais rapidamente, o que, por sua vez, diminui a espera que o espaço de nomes apareça num servidor ativado para Azure File Sync.
- O restauro do lado da cloud a partir de um instantâneo de partilha de ficheiros do Azure será mais rápido.
- A recuperação após desastre de um servidor no local pode acelerar significativamente.
- As alterações efetuadas diretamente numa partilha de ficheiros do Azure (fora da sincronização) podem ser detetadas e sincronizadas mais rapidamente.
Dica
Se não souber quantos ficheiros e pastas tem, consulte a ferramenta TreeSize da JAM Software GmbH.
Uma abordagem estruturada a um mapa de implementação
Antes de implementar o armazenamento na cloud num passo posterior, é importante criar um mapa entre pastas no local e partilhas de ficheiros do Azure. Este mapeamento irá informar quantos e que Azure File Sync recursos do grupo de sincronização que irá aprovisionar. Um grupo de sincronização associa a partilha de ficheiros do Azure e a pasta no seu servidor e estabelece uma ligação de sincronização.
Para decidir quantas partilhas de ficheiros do Azure precisa, veja os seguintes limites e melhores práticas. Ao fazê-lo, irá ajudá-lo a otimizar o seu mapa.
Um servidor no qual o agente Azure File Sync está instalado pode sincronizar com até 30 partilhas de ficheiros do Azure.
Uma partilha de ficheiros do Azure é implementada numa conta de armazenamento. Essa disposição torna a conta de armazenamento um destino de dimensionamento para números de desempenho, como IOPS e débito.
Preste atenção às limitações de IOPS de uma conta de armazenamento ao implementar partilhas de ficheiros do Azure. Idealmente, deve mapear partilhas de ficheiros 1:1 com contas de armazenamento. No entanto, isto pode nem sempre ser possível devido a vários limites e restrições, tanto da sua organização como do Azure. Quando não for possível ter apenas uma partilha de ficheiros implementada numa conta de armazenamento, considere que partilhas serão altamente ativas e que partilhas serão menos ativas para garantir que as partilhas de ficheiros mais quentes não são colocadas na mesma conta de armazenamento em conjunto.
Se planear elevar uma aplicação para o Azure que irá utilizar a partilha de ficheiros do Azure nativamente, poderá precisar de mais desempenho da partilha de ficheiros do Azure. Se este tipo de utilização for uma possibilidade, mesmo no futuro, é melhor criar uma única partilha de ficheiros padrão do Azure na sua própria conta de armazenamento.
Existe um limite de 250 contas de armazenamento por subscrição por região do Azure.
Dica
Tendo em conta estas informações, muitas vezes torna-se necessário agrupar várias pastas de nível superior nos seus volumes num novo diretório de raiz comum. Em seguida, sincronize este novo diretório de raiz e todas as pastas agrupadas no mesmo para uma única partilha de ficheiros do Azure. Esta técnica permite-lhe manter-se dentro do limite de 30 sincronizações de partilhas de ficheiros do Azure por servidor.
Este agrupamento numa raiz comum não afeta o acesso aos seus dados. As suas ACLs permanecem como estão. Só precisa de ajustar os caminhos de partilha (como partilhas SMB ou NFS) que possa ter nas pastas do servidor local que agora alterou para uma raiz comum. Nada mais muda.
Importante
O vetor de escala mais importante para Azure File Sync é o número de itens (ficheiros e pastas) que precisam de ser sincronizados. Veja os Azure File Sync destinos de dimensionamento para obter mais detalhes.
É uma melhor prática manter o número de itens por âmbito de sincronização baixo. É um fator importante a ter em conta no mapeamento de pastas para partilhas de ficheiros do Azure. Azure File Sync é testado com 100 milhões de itens (ficheiros e pastas) por partilha. Mas, muitas vezes, é melhor manter o número de itens abaixo de 20 milhões ou 30 milhões numa única acção. Divida o espaço de nomes em múltiplas partilhas se começar a exceder estes números. Pode continuar a agrupar várias partilhas no local na mesma partilha de ficheiros do Azure se permanecer aproximadamente abaixo destes números. Esta prática irá fornecer-lhe espaço para crescer.
É possível que, na sua situação, um conjunto de pastas possa sincronizar logicamente com a mesma partilha de ficheiros do Azure (utilizando a nova abordagem de pasta raiz comum mencionada anteriormente). No entanto, ainda poderá ser melhor reagrupar pastas para que sejam sincronizadas com duas em vez de uma partilha de ficheiros do Azure. Pode utilizar esta abordagem para manter o número de ficheiros e pastas por partilha de ficheiros equilibrado no servidor. Também pode dividir as partilhas no local e sincronizar entre servidores mais no local, adicionando a capacidade de sincronizar com mais 30 partilhas de ficheiros do Azure por servidor extra.
Cenários e considerações comuns de sincronização de ficheiros
| # | Cenário de sincronização | Suportado | Considerações (ou limitações) | Solução (ou solução) |
|---|---|---|---|---|
| 1 | Servidor de ficheiros com vários discos/volumes e várias partilhas para a mesma partilha de ficheiros do Azure de destino (consolidação) | No | Uma partilha de ficheiros do Azure de destino (ponto final da cloud) só suporta a sincronização com um grupo de sincronização. Um grupo de sincronização só suporta um ponto final de servidor por servidor registado. |
1) Comece por sincronizar um disco (o volume de raiz) para direcionar a partilha de ficheiros do Azure. Começar com o maior disco/volume ajudará com os requisitos de armazenamento no local. Configure o arrumo na cloud para colocar todos os dados em camadas na cloud, libertando assim espaço no disco do servidor de ficheiros. Mover dados de outros volumes/partilhas para o volume atual que está a ser sincronizado. Continue os passos um a um até que todos os dados sejam escalonados para a cloud/migrados. 2) Segmente um volume de raiz (disco) de cada vez. Utilize o arrumo na cloud para colocar todos os dados em camadas para direcionar a partilha de ficheiros do Azure. Remova o ponto final do servidor do grupo de sincronização, recrie o ponto final com o volume/disco de raiz seguinte, sincronize e repita o processo. Nota: poderá ser necessária a reinstalação do agente. 3) Recomendamos a utilização de várias partilhas de ficheiros do Azure de destino (conta de armazenamento igual ou diferente com base nos requisitos de desempenho) |
| 2 | Servidor de ficheiros com volume único e várias partilhas para a mesma partilha de ficheiros do Azure de destino (consolidação) | Yes | Não é possível ter vários pontos finais do servidor por servidor registado a sincronizar com a mesma partilha de ficheiros do Azure de destino (igual à anterior) | Sincronizar a raiz do volume que contém várias partilhas ou pastas de nível superior. Veja Partilhar conceito de agrupamento e Sincronização de volumes para obter mais informações. |
| 3 | Servidor de ficheiros com múltiplas partilhas e/ou volumes para várias partilhas de ficheiros do Azure numa única conta de armazenamento (mapeamento de partilha 1:1) | Yes | Uma única instância do Windows Server (ou cluster) pode sincronizar até 30 partilhas de ficheiros do Azure. Uma conta de armazenamento é um destino de dimensionamento para o desempenho. O IOPS e o débito são partilhados entre partilhas de ficheiros. Mantenha o número de itens por grupo de sincronização dentro de 100 milhões de itens (ficheiros e pastas) por partilha. Idealmente, é melhor ficar abaixo dos 20 ou 30 milhões por ação. |
1) Utilize vários grupos de sincronização (número de grupos de sincronização = número de partilhas de ficheiros do Azure para sincronizar). 2) Apenas 30 partilhas podem ser sincronizadas neste cenário de cada vez. Se tiver mais de 30 partilhas nesse servidor de ficheiros, utilize o conceito de Agrupamento de partilhas e a Sincronização de volumes para reduzir o número de pastas de raiz ou de nível superior na origem. 3) Utilize servidores File Sync adicionais no local e divida/mova dados para estes servidores para contornar as limitações no servidor Windows de origem. |
| 4 | Servidor de ficheiros com múltiplas partilhas e/ou volumes para várias partilhas de ficheiros do Azure numa conta de armazenamento diferente (mapeamento de partilhas 1:1) | Yes | Uma única instância do Windows Server (ou cluster) pode sincronizar até 30 partilhas de ficheiros do Azure (a mesma ou outra conta de armazenamento). Mantenha o número de itens por grupo de sincronização dentro de 100 milhões de itens (ficheiros e pastas) por partilha. Idealmente, é melhor ficar abaixo dos 20 ou 30 milhões por ação. |
A mesma abordagem que acima |
| 5 | Vários servidores de ficheiros com um único (volume de raiz ou partilha) para a mesma partilha de ficheiros do Azure de destino (consolidação) | No | Um grupo de sincronização não pode utilizar o ponto final da cloud (partilha de ficheiros do Azure) já configurado noutro grupo de sincronização. Embora um grupo de sincronização possa ter pontos finais de servidor em servidores de ficheiros diferentes, os ficheiros não podem ser distintos. |
Siga as orientações no Cenário n.º 1 acima, com considerações adicionais sobre como direcionar um servidor de ficheiros de cada vez. |
Criar uma tabela de mapeamento

Utilize as informações anteriores para determinar quantas partilhas de ficheiros do Azure precisa e que partes dos seus dados existentes acabarão por ser partilhadas pelo Azure.
Crie uma tabela que regista os seus pensamentos para que possa fazer referência à mesma quando precisar. Manter-se organizado é importante porque pode ser fácil perder detalhes do seu plano de mapeamento quando está a aprovisionar muitos recursos do Azure ao mesmo tempo. Transfira o seguinte ficheiro do Excel para utilizar como modelo para ajudar a criar o seu mapeamento.

|
Transfira um modelo de mapeamento de espaços de nomes. |
Passo 5: Aprovisionar partilhas de ficheiros do Azure
Uma partilha de ficheiros do Azure é armazenada na cloud numa conta de armazenamento do Azure. Aplica-se aqui outro nível de considerações de desempenho.
Se tiver partilhas altamente ativas (partilhas utilizadas por muitos utilizadores e/ou aplicações), duas partilhas de ficheiros do Azure poderão atingir o limite de desempenho de uma conta de armazenamento.
Uma melhor prática é implementar contas de armazenamento com uma partilha de ficheiros cada. Pode aloja várias partilhas de ficheiros do Azure na mesma conta de armazenamento se tiver partilhas de arquivo ou se esperar uma atividade diária baixa nas mesmas.
Estas considerações aplicam-se mais ao acesso direto à cloud (através de uma VM do Azure) do que a Azure File Sync. Se pretender utilizar apenas Azure File Sync nestas partilhas, agrupar várias numa única conta de armazenamento do Azure é bom.
Se tiver feito uma lista das suas partilhas, deve mapear cada partilha para a conta de armazenamento em que se encontra.
Na fase anterior, determinou o número adequado de partilhas. Neste passo, tem um mapeamento de contas de armazenamento para partilhas de ficheiros. Agora, implemente o número adequado de contas de armazenamento do Azure com o número adequado de partilhas de ficheiros do Azure nas mesmas.
Certifique-se de que a região de cada uma das suas contas de armazenamento é a mesma e corresponde à região do recurso do Serviço de Sincronização de Armazenamento que já implementou.
Atenção
Se criar uma partilha de ficheiros do Azure com um limite de 100 TiB, essa partilha só pode utilizar opções de redundância de armazenamento localmente redundante ou redundância de armazenamento com redundância entre zonas. Considere as suas necessidades de redundância de armazenamento antes de utilizar 100 partilhas de ficheiros TiB.
As partilhas de ficheiros do Azure ainda são criadas com um limite de 5 TiB por predefinição. Siga os passos em Criar uma partilha de ficheiros do Azure para criar uma partilha de ficheiros grande.
Outra consideração ao implementar uma conta de armazenamento é a redundância do Armazenamento do Azure. Veja Opções de redundância do Armazenamento do Azure.
Os nomes dos seus recursos também são importantes. Por exemplo, se agrupar várias partilhas para o departamento de RH numa conta de armazenamento do Azure, deve atribuir um nome adequado à conta de armazenamento. Da mesma forma, quando atribuir um nome às partilhas de ficheiros do Azure, deve utilizar nomes semelhantes aos utilizados para os respetivos homólogos no local.
Definições da conta de armazenamento
Existem muitas configurações que pode fazer numa conta de armazenamento. A seguinte lista de verificação deve ser utilizada para as configurações da conta de armazenamento. Pode alterar, por exemplo, a configuração de rede após a conclusão da migração.
- Partilhas de ficheiros grandes: ativadas – as partilhas de ficheiros grandes melhoram o desempenho e permitem-lhe armazenar até 100TiB numa partilha.
- Firewall e redes virtuais: Desativada – não configure quaisquer restrições de IP nem limite o acesso da conta de armazenamento a uma VNET específica. O ponto final público da conta de armazenamento é utilizado durante a migração. Todos os endereços IP de VMs do Azure têm de ser permitidos. É melhor configurar quaisquer regras de firewall na conta de armazenamento após a migração.
- Pontos Finais Privados: Suportados – pode ativar pontos finais privados, mas o ponto final público é utilizado para a migração e tem de permanecer disponível.
Passo 6: Configurar pastas de destino do Windows Server
Nos passos anteriores, considerou todos os aspetos que irão determinar os componentes das topologias de sincronização. Chegou a altura de preparar o servidor para receber ficheiros para carregamento.
Crie todas as pastas, que sincronizarão cada uma com a sua própria partilha de ficheiros do Azure. É importante que siga a estrutura de pastas que documentou anteriormente. Se, por exemplo, tiver decidido sincronizar múltiplas partilhas SMB locais numa única partilha de ficheiros do Azure, terá de as colocar numa pasta raiz comum no volume. Crie esta pasta raiz de destino no volume agora.
O número de partilhas de ficheiros do Azure que aprovisionou deve corresponder ao número de pastas que criou neste passo + o número de volumes que irá sincronizar ao nível da raiz.
Passo 7: Implementar o agente Azure File Sync
Nesta secção, vai instalar o agente Azure File Sync na sua instância do Windows Server.
O guia de implementação explica que tem de desativar a Configuração de Segurança Avançada do Internet Explorer. Esta medida de segurança não é aplicável ao Azure File Sync. Desativá-lo permite-lhe autenticar-se no Azure sem problemas.
Abra o PowerShell. Instale os módulos do PowerShell necessários com os seguintes comandos. Certifique-se de que instala o módulo completo e o fornecedor NuGet quando lhe for pedido para o fazer.
Install-Module -Name Az -AllowClobber
Install-Module -Name Az.StorageSync
Se tiver problemas ao aceder à Internet a partir do servidor, agora é a altura de resolvê-los. Azure File Sync utiliza qualquer ligação de rede disponível à Internet. A necessidade de um servidor proxy para aceder à Internet também é suportada. Pode configurar um proxy em todo o computador agora ou, durante a instalação do agente, especificar um proxy que apenas Azure File Sync irá utilizar.
Se configurar um proxy significa que precisa de abrir as firewalls para o servidor, essa abordagem poderá ser aceitável para si. No final da instalação do servidor, depois de concluir o registo do servidor, um relatório de conectividade de rede irá mostrar-lhe os URLs exatos do ponto final no Azure com os quais Azure File Sync precisa de comunicar para a região que selecionou. O relatório também indica por que motivo é necessária comunicação. Pode utilizar o relatório para bloquear as firewalls em torno do servidor para URLs específicos.
Também pode adotar uma abordagem mais conservadora na qual não abra as firewalls. Em vez disso, pode limitar o servidor a comunicar com espaços de nomes DNS de nível superior. Para obter mais informações, veja Azure File Sync definições de proxy e firewall. Siga as suas próprias melhores práticas de rede.
No final do assistente de instalação do servidor, será aberto um assistente de registo do servidor. Registe o servidor no recurso do Azure do Serviço de Sincronização de Armazenamento a partir de anteriormente.
Estes passos são descritos mais detalhadamente no guia de implementação, que inclui os módulos do PowerShell que deve instalar primeiro: Azure File Sync instalação do agente.
Utilize o agente mais recente. Pode transferi-lo a partir do Centro de Transferências da Microsoft: Azure File Sync Azure File Sync Agente.
Após um registo de instalação e servidor com êxito, pode confirmar que concluiu este passo com êxito. Aceda ao recurso do Serviço de Sincronização de Armazenamento no portal do Azure. No menu esquerdo, aceda a Servidores registados. Verá o seu servidor listado aí.
Passo 8: Configurar a sincronização
Este passo associa todos os recursos e pastas que configurou na sua instância do Windows Server durante os passos anteriores.
- Inicie sessão no portal do Azure.
- Localize o recurso do Serviço de Sincronização de Armazenamento.
- Crie um novo grupo de sincronização no recurso do Serviço de Sincronização de Armazenamento para cada partilha de ficheiros do Azure. Na Azure File Sync terminologia, a partilha de ficheiros do Azure tornar-se-á um ponto final da cloud na topologia de sincronização que está a descrever com a criação de um grupo de sincronização. Quando criar o grupo de sincronização, atribua-lhe um nome familiar para que reconheça que conjunto de ficheiros é sincronizado. Certifique-se de que referencia a partilha de ficheiros do Azure com um nome correspondente.
- Depois de criar o grupo de sincronização, será apresentada uma linha para o mesmo na lista de grupos de sincronização. Selecione o nome (uma ligação) para apresentar o conteúdo do grupo de sincronização. Verá a partilha de ficheiros do Azure em Pontos finais da cloud.
- Localize o botão Adicionar Ponto Final do Servidor . A pasta no servidor local que aprovisionou tornar-se-á o caminho para este ponto final do servidor.
Aviso
Certifique-se de que ativa o arrumo na cloud! Isto é necessário se o servidor local não tiver espaço suficiente para armazenar o tamanho total dos seus dados no armazenamento na cloud do StorSimple. Defina a política de camadas, temporariamente para a migração, para 99% de espaço livre em volume.
Repita os passos de criação e adição do grupo de sincronização da pasta de servidor correspondente como ponto final de servidor para todas as partilhas de ficheiros/localizações do servidor do Azure, que têm de ser configuradas para sincronização.
Passo 9: Copiar os seus ficheiros
A abordagem de migração básica é um RoboCopy da sua aplicação virtual StorSimple para o seu Windows Server e Azure File Sync para partilhas de ficheiros do Azure.
Execute a primeira cópia local para a pasta de destino do Windows Server:
- Identifique a primeira localização na sua aplicação virtual StorSimple.
- Identifique a pasta correspondente no Windows Server, que já tem Azure File Sync configurado no mesmo.
- Iniciar a cópia com o RoboCopy
O seguinte comando RoboCopy irá recuperar ficheiros do armazenamento do StorSimple do Azure para o StorSimple local e, em seguida, movê-los para a pasta de destino do Windows Server. O Windows Server irá sincronizá-lo com as partilhas de ficheiros do Azure. À medida que o volume local do Windows Server fica cheio, o arrumo na cloud será iniciado e os ficheiros de camada que já foram sincronizados com êxito. O arrumo na cloud irá gerar espaço suficiente para continuar a cópia a partir da aplicação virtual StorSimple. O arrumo na cloud verifica uma vez por hora para ver o que sincronizou e libertar espaço em disco para alcançar o espaço livre em volume de 99%.
robocopy <SourcePath> <Dest.Path> /MT:20 /R:2 /W:1 /B /MIR /IT /COPY:DATSO /DCOPY:DAT /NP /NFL /NDL /XD "System Volume Information" /UNILOG:<FilePathAndName>
| Comutador | Significado |
|---|---|
/MT:n |
Permite ao Robocopy ser executado com vários threads. A predefinição para n é 8. O máximo é de 128 threads. Embora uma contagem elevada de threads ajude a saturar a largura de banda disponível, não significa que a migração seja sempre mais rápida com mais threads. Os testes com Ficheiros do Azure indicam que entre 8 e 20 mostra um desempenho equilibrado para uma execução de cópia inicial. As execuções subsequentes /MIR são progressivamente afetadas pela computação disponível vs. largura de banda de rede disponível. Nas execuções subsequentes, faça corresponder o valor da contagem de threads a um valor próximo da contagem de núcleos do processador e da contagem de threads por núcleo. Considere se os núcleos precisam de ser reservados para outras tarefas que um servidor de produção possa ter. Os testes com Ficheiros do Azure mostraram que até 64 threads produzem um bom desempenho, mas apenas se os processadores os conseguirem manter vivos ao mesmo tempo. |
/R:n |
Contagem máxima de novas tentativas para um ficheiro cuja cópia falhou na primeira tentativa. O Robocopy tentará horas n antes de o ficheiro falhar permanentemente na cópia na execução. Pode otimizar o desempenho da sua execução: escolha um valor de dois ou três se acreditar que os problemas de tempo limite causaram falhas no passado. Isto pode ser mais comum através de ligações WAN. Não escolha nenhuma repetição ou um valor de um caso acredite que o ficheiro não conseguiu copiar porque estava a ser utilizado ativamente. Tentar novamente alguns segundos depois pode não ser tempo suficiente para o estado em utilização do ficheiro ser alterado. Os utilizadores ou aplicações que mantêm o ficheiro aberto podem precisar de horas mais tempo. Neste caso, aceitar que o ficheiro não foi copiado e detetá-lo numa das execuções planeadas e subsequentes do Robocopy poderá, eventualmente, conseguir copiar o ficheiro com êxito. Isto ajuda a execução atual a terminar mais rapidamente sem ser prolongada por muitas repetições que acabam na maioria das falhas de cópia devido a ficheiros ainda abertos após o tempo limite de repetição. |
/W:n |
Especifica o tempo que o Robocopy aguarda antes de tentar copiar um ficheiro que não foi copiado com êxito na tentativa anterior. n é o número de segundos a aguardar entre repetições. /W:n é frequentemente utilizado em conjunto com /R:n. |
/B |
Executa o Robocopy no mesmo modo que uma aplicação de cópia de segurança utilizaria. Esta opção permite que o Robocopy mova os ficheiros para os quais o atual utilizador não tem permissões. O comutador de cópia de segurança depende da execução do comando Robocopy numa consola elevada do administrador ou na janela do PowerShell. Se utilizar o Robocopy para Ficheiros do Azure, certifique-se de que monta a partilha de ficheiros do Azure com a chave de acesso da conta de armazenamento vs. uma identidade de domínio. Se não o fizer, as mensagens de erro poderão não o levar intuitivamente a uma resolução do problema. |
/MIR |
(Espelhar origem para destino.) Permite que o Robocopy copie apenas os detalhes entre a origem e o destino. Os subdiretórios vazios serão copiados. Os itens (ficheiros ou pastas) que tenham sido alterados ou não existam no destino serão copiados. Os itens que existam no destino, mas não na origem, serão removidos (eliminados) do destino. Quando utilizar esta opção, faça corresponder exatamente as estruturas das pastas de origem e de destino. A correspondência significa copiar do nível de origem e pasta correto para o nível de pasta correspondente no destino. Só, assim, é que uma cópia “atualizada” pode ter êxito. Quando a origem e o destino não correspondem, a utilização /MIR levará a eliminações e recopiações em larga escala. |
/IT |
Garante que a fidelidade é preservada em determinados cenários de espelhamento. Por exemplo, se um ficheiro registar uma alteração da ACL e uma atualização de atributos entre duas execuções do Robocopy, será marcado como oculto. Sem /IT, a alteração da ACL poderá não ser efetuada pelo Robocopy e não ser transferida para a localização de destino. |
/COPY:[copyflags] |
A fidelidade da cópia do ficheiro. Predefinição: /COPY:DAT. Sinalizadores de cópia: D= Dados, A= Atributos, T= Carimbos de data/hora, S= Segurança = ACLs NTFS, O= Informações do proprietário, U= Auditing information. As informações de auditoria não podem ser armazenadas numa partilha de ficheiros do Azure. |
/DCOPY:[copyflags] |
Fidelidade para a cópia de diretórios. Predefinição: /DCOPY:DA. Copiar sinalizadores: D= Dados, A= Atributos, T= Carimbos de data/hora. |
/NP |
Especifica que o progresso da cópia de cada ficheiro e pasta não será apresentado. A apresentação do progresso reduz significativamente o desempenho da cópia. |
/NFL |
Especifica que os nomes de ficheiro não estão registados. Melhora o desempenho da cópia. |
/NDL |
Especifica que os nomes de diretório não estão registados. Melhora o desempenho da cópia. |
/XD |
Especifica diretórios a serem excluídos. Ao executar o Robocopy na raiz de um volume, considere excluir a pasta oculta System Volume Information . Se for utilizado como concebido, todas as informações aí contidas são específicas do volume exato neste sistema exato e podem ser reconstruídas a pedido. Copiar estas informações não será útil na cloud ou quando os dados forem copiados novamente para outro volume do Windows. Deixar este conteúdo para trás não deve ser considerado perda de dados. |
/UNILOG:<file name> |
Escreve o estado no ficheiro de registo como Unicode. (Substitui o registo existente.) |
/L |
Apenas para uma execução de teste Os ficheiros devem ser listados apenas. Não serão copiados, nem eliminados e não terão nenhum carimbo de data/hora. Frequentemente utilizado com /TEE para a saída da consola. Os sinalizadores do script de exemplo, como /NP, /NFLe /NDL, poderão ter de ser removidos para obter resultados de teste devidamente documentados. |
/LFSM |
Só para destinos com armazenamento escalonado. Não suportado quando o destino é uma partilha SMB remota. Especifica que o Robocopy funciona no "modo de espaço livre baixo". Este comutador é útil apenas para destinos com armazenamento em camadas que pode ficar sem capacidade local antes de o Robocopy terminar. Foi adicionado especificamente para utilização com um destino ativado para o arrumo na cloud do Azure File Sync. Pode ser utilizado independentemente do Azure File Sync. Neste modo, o Robocopy será colocado em pausa sempre que a cópia de um ficheiro possa fazer com que o espaço livre num volume de destino fique abaixo do valor “limite”. Este valor pode ser especificado pela /LFSM:n forma do sinalizador. O parâmetro n é especificado na base 2: nKB, nMBou nGB. Se /LFSM for especificado sem valor de piso explícito, o piso está definido como 10 por cento do tamanho do volume de destino. O modo de espaço livre baixo não é compatível com /MT, /EFSRAWou /ZB. O suporte para /B foi adicionado no Windows Server 2022. Consulte a secção Windows Server 2022 e RoboCopy LFSM abaixo para obter mais informações, incluindo detalhes sobre um erro relacionado e uma solução. |
/Z |
Utilizar com cuidadoCopia ficheiros no modo de reinício. Esta opção só é recomendada num ambiente de rede instável. Reduz significativamente o desempenho da cópia devido ao registo extra. |
/ZB |
Utilizar com cuidadoUtiliza o modo de reinício. Se o acesso for negado, esta opção utilizará o modo de cópia de segurança. Esta opção reduz significativamente o desempenho da cópia devido ao controlo de pontos de verificação. |
Importante
Recomendamos que utilize um Windows Server 2022. Ao utilizar um Windows Server 2019, certifique-se de que está instalado o nível de patch mais recente ou, pelo menos, a atualização KB5005103 do SO. Contém correções importantes para determinados cenários do Robocopy.
Quando executa o comando RoboCopy pela primeira vez, os seus utilizadores e aplicações continuam a aceder aos ficheiros e pastas do StorSimple e, potencialmente, a alterá-lo. É possível que o RoboCopy tenha processado um diretório, avance para o seguinte e, em seguida, um utilizador na localização de origem (StorSimple) adicione, altere ou elimine um ficheiro que agora não será processado nesta execução atual do RoboCopy. Não há problema.
A primeira execução consiste em mover a maior parte dos dados de volta para o local, para o Windows Server e fazer uma cópia de segurança para a cloud através de Azure File Sync. Isto pode demorar muito tempo, consoante:
- a largura de banda de transferência
- a velocidade de revocação do serviço cloud StorSimple
- a largura de banda de carregamento
- o número de itens (ficheiros e pastas), que têm de ser processados por qualquer um dos serviços
Assim que a execução inicial estiver concluída, execute o comando novamente.
A segunda vez será concluída mais rapidamente, porque só precisa de transportar as alterações que ocorreram desde a última execução. Essas alterações são provavelmente locais para o StorSimple já, porque são recentes. Isto reduz ainda mais o tempo porque a necessidade de recuperação da cloud é reduzida. Durante esta segunda execução, ainda assim, podem acumular-se novas alterações.
Repita este processo até estar convencido de que a quantidade de tempo que demora a concluir é um período de indisponibilidade aceitável.
Quando considerar o período de indisponibilidade aceitável e estiver preparado para colocar a localização do StorSimple offline, faça-o agora: por exemplo, remova a partilha SMB para que nenhum utilizador possa aceder à pasta ou siga qualquer outro passo adequado que impeça a alteração do conteúdo nesta pasta no StorSimple.
Execute uma última ronda do RoboCopy. Esta ação irá recolher quaisquer alterações que possam ter sido perdidas. Quanto tempo demora este passo final, depende da velocidade da análise do RoboCopy. Pode estimar o tempo (que é igual ao tempo de inatividade) ao medir quanto tempo demorou a execução anterior.
Crie uma partilha na pasta Windows Server e, possivelmente, ajuste a sua implementação DFS-N para apontar para a mesma. Certifique-se de que define as mesmas permissões de nível de partilha que na partilha SMB do StorSimple.
Concluiu a migração de uma partilha/grupo de partilhas para uma raiz ou volume comum. (Dependendo do que mapeou e decidiu que precisava de entrar na mesma partilha de ficheiros do Azure.)
Pode tentar executar algumas destas cópias em paralelo. Recomendamos que processe o âmbito de uma partilha de ficheiros do Azure de cada vez.
Aviso
Depois de mover todos os dados do StorSimple para o Windows Server e a migração estar concluída: regresse a todos os grupos de sincronização no portal do Azure e ajuste o valor de percentagem de espaço livre do volume de arrumo na cloud para algo mais adequado para a utilização da cache, por exemplo, 20%.
A política de espaço livre do volume de arrumo na cloud atua ao nível do volume com potencialmente múltiplos pontos finais do servidor a sincronizar a partir do mesmo. Se se esquecer de ajustar o espaço livre num ponto final de servidor, a sincronização continuará a aplicar a regra mais restritiva e tentará manter 99% de espaço livre em disco, fazendo com que a cache local não funcione como seria de esperar. A menos que seja o seu objetivo ter apenas o espaço de nomes de um volume que contém apenas dados de arquivo raramente acedidos.
Resolução de problemas
O problema mais provável que pode encontrar é que o comando RoboCopy falha com "Volume cheio" no lado do Windows Server. Se for esse o caso, é provável que a velocidade de transferência seja melhor do que a velocidade de carregamento. O arrumo na cloud atua uma vez por hora para evacuar o conteúdo do disco do Windows Server local, que foi sincronizado.
Permita que o progresso da sincronização e o arrumo na cloud libertem espaço em disco. Pode observar que, no Explorador de Ficheiros no seu Windows Server.
Quando o Windows Server tiver capacidade disponível suficiente, voltar a executar o comando irá resolver o problema. Nada se parte quando entras nesta situação e podes seguir em frente com confiança. O inconveniente de executar o comando novamente é a única consequência.
Também poderá deparar-se com outros problemas de Azure File Sync. Se isso acontecer, veja Azure File Sync guia de resolução de problemas.
A velocidade e a taxa de sucesso de uma determinada execução do RoboCopy dependerão de vários fatores:
- IOPS no armazenamento de origem e de destino
- a largura de banda de rede disponível entre a origem e o destino
- a capacidade de processar rapidamente ficheiros e pastas num espaço de nomes
- o número de alterações entre as execuções do RoboCopy
- o tamanho e o número de ficheiros que precisa de copiar
Considerações de IOPS e largura de banda
Nesta categoria, tem de considerar as capacidades do armazenamento de origem, do armazenamento de destino e da rede que as liga. O débito máximo possível é determinado pelo mais lento destes três componentes. Certifique-se de que a infraestrutura de rede está configurada para suportar velocidades de transferência ideais para as suas melhores capacidades.
Atenção
Embora copiar o mais rápido possível seja muitas vezes o mais desejado, considere a utilização da sua rede local e da aplicação NAS para outras tarefas, muitas vezes críticas para a empresa.
Copiar o mais rápido possível pode não ser desejável quando existe o risco de a migração monopolizar os recursos disponíveis.
- Considere quando é melhor no seu ambiente executar migrações: durante o dia, fora do horário de expediente ou durante os fins de semana.
- Considere também a rede QoS num Windows Server para limitar a velocidade do RoboCopy.
- Evite trabalhos desnecessários para as ferramentas de migração.
O RoboCopy pode inserir atrasos entre pacotes ao especificar o /IPG:n comutador onde n é medido em milissegundos entre pacotes roboCopy. A utilização deste comutador pode ajudar a evitar o monopolização de recursos em dispositivos restritos de E/S e ligações de rede cheias.
/IPG:n não pode ser utilizado para limitação de rede precisa para determinados Mbps. Em alternativa, utilize a QoS de Rede do Windows Server. O RoboCopy depende inteiramente do protocolo SMB para todas as necessidades de rede. A utilização do SMB é a razão pela qual o RoboCopy não pode influenciar o débito de rede propriamente dito, mas pode abrandar a sua utilização.
Uma linha de pensamento semelhante aplica-se ao IOPS observado no NAS. O tamanho do cluster no volume NAS, os tamanhos dos pacotes e uma matriz de outros fatores influenciam o IOPS observado. A introdução do atraso entre pacotes é, muitas vezes, a forma mais fácil de controlar a carga no NAS. Teste múltiplos valores, por exemplo, de cerca de 20 milissegundos (n=20) a múltiplos desse número. Depois de introduzir um atraso, pode avaliar se as outras aplicações podem agora funcionar conforme esperado. Esta estratégia de otimização irá permitir-lhe encontrar a velocidade ideal do RoboCopy no seu ambiente.
Velocidade de processamento
O RoboCopy irá percorrer o espaço de nomes para o qual está apontado e avaliar cada ficheiro e pasta para cópia. Todos os ficheiros serão avaliados durante uma cópia inicial e durante as cópias de recuperação. Por exemplo, execuções repetidas do RoboCopy /MIR nas mesmas localizações de armazenamento de origem e de destino. Estas execuções repetidas são úteis para minimizar o tempo de inatividade para utilizadores e aplicações e para melhorar a taxa de êxito geral dos ficheiros migrados.
Muitas vezes, a predefinição é considerar a largura de banda como o fator mais limitador numa migração e isso pode ser verdade. Mas a capacidade de enumerar um espaço de nomes pode influenciar o tempo total para copiar ainda mais para espaços de nomes maiores com ficheiros mais pequenos. Considere que copiar 1 TiB de ficheiros pequenos demorará consideravelmente mais tempo do que copiar 1 TiB de menos ficheiros, mas maiores, assumindo que todas as outras variáveis permanecem as mesmas. Por conseguinte, poderá deparar-se com uma transferência lenta se estiver a migrar um grande número de ficheiros pequenos. Este é um comportamento esperado.
A causa desta diferença é a capacidade de processamento necessária para percorrer um espaço de nomes. O RoboCopy suporta cópias com vários threads através do /MT:n parâmetro em que n significa o número de threads a utilizar. Assim, ao aprovisionar um computador especificamente para o RoboCopy, considere o número de núcleos do processador e a respetiva relação com a contagem de threads que fornecem. Os mais comuns são dois threads por núcleo. A contagem de núcleos e threads de uma máquina é um ponto de dados importante para decidir que valores de vários threads /MT:n deve especificar. Considere também quantas tarefas do RoboCopy planeia executar em paralelo num determinado computador.
Mais threads copiarão o nosso exemplo 1-TiB de ficheiros pequenos consideravelmente mais rápido do que menos threads. Ao mesmo tempo, o investimento adicional de recursos no nosso 1 TiB de ficheiros maiores pode não produzir benefícios proporcionais. Uma contagem elevada de threads tentará copiar mais ficheiros grandes através da rede em simultâneo. Esta atividade de rede adicional aumenta a probabilidade de ficar restringida pelo débito ou IOPS de armazenamento.
Durante um primeiro RoboCopy num destino vazio ou numa execução diferencial com muitos ficheiros alterados, é provável que esteja limitado pelo débito de rede. Comece com uma contagem de threads elevada na execução inicial. Uma contagem elevada de threads, mesmo para além dos threads atualmente disponíveis no computador, ajuda a saturar a largura de banda de rede disponível. As execuções subsequentes /MIR são progressivamente afetadas pelo processamento de itens. Menos alterações numa execução diferencial significam menos transporte de dados através da rede. A velocidade está agora mais dependente da sua capacidade de processar itens de espaço de nomes do que de movê-los através da ligação de rede. Para execuções subsequentes, corresponda o valor da contagem de threads à contagem de núcleos do processador e à contagem de threads por núcleo. Considere se os núcleos precisam de ser reservados para outras tarefas que um servidor de produção possa ter.
Dica
Regra geral: a primeira execução do RoboCopy, que irá mover muitos dados de uma rede de latência superior, beneficia do aprovisionamento excessivo da contagem de threads (/MT:n). As execuções subsequentes irão copiar menos diferenças e é mais provável que mude do débito de rede restrito à computação restrita. Nestas circunstâncias, muitas vezes é melhor corresponder a contagem de threads do RoboCopy aos threads realmente disponíveis no computador. O aprovisionamento excessivo nesse cenário pode levar a mais mudanças de contexto no processador, possivelmente ao abrandar a cópia.
Evitar trabalho desnecessário
Evite alterações em grande escala no seu espaço de nomes. Por exemplo, mover ficheiros entre diretórios, alterar propriedades em grande escala ou alterar permissões (ACLs NTFS). Especialmente as alterações da ACL podem ter um impacto elevado, uma vez que muitas vezes têm um efeito de alteração em cascata nos ficheiros mais baixos na hierarquia de pastas. As consequências podem ser:
- tempo de execução da tarefa do RoboCopy expandido porque cada ficheiro e pasta afetados por uma alteração da ACL precisam de ser atualizados
- A reutilização de dados movidos anteriormente poderá ter de ser recopida. Por exemplo, mais dados terão de ser copiados quando as estruturas de pastas forem alteradas depois de os ficheiros já terem sido copiados anteriormente. Uma tarefa do RoboCopy não consegue "reproduzir" uma alteração no espaço de nomes. A tarefa seguinte tem de remover os ficheiros anteriormente transportados para a estrutura de pastas antiga e carregar novamente os ficheiros na nova estrutura de pastas.
Outro aspeto importante é utilizar a ferramenta RoboCopy de forma eficaz. Com o script do RoboCopy recomendado, irá criar e guardar um ficheiro de registo para erros. Podem ocorrer erros de cópia – isto é normal. Estes erros tornam frequentemente necessário executar várias rondas de uma ferramenta de cópia, como o RoboCopy. Uma execução inicial, por exemplo, de um NAS para o DataBox ou de um servidor para uma partilha de ficheiros do Azure. E uma ou mais execuções adicionais com o comutador /MIR para capturar e repetir ficheiros que não foram copiados.
Deve estar preparado para executar várias rondas do RoboCopy num determinado âmbito de espaço de nomes. As execuções sucessivas terminarão mais rapidamente, uma vez que têm menos para copiar, mas são cada vez mais limitadas pela velocidade de processamento do espaço de nomes. Quando executa várias rondas, pode acelerar cada ronda ao não ter o RoboCopy a tentar copiar tudo de forma irracional numa determinada execução. Estes comutadores RoboCopy podem fazer uma diferença significativa:
/R:nn = com que frequência tenta copiar um ficheiro com falhas e/W:nn = quantos segundos esperar entre repetições
/R:5 /W:5 é uma definição razoável que pode ajustar ao seu gosto. Neste exemplo, um ficheiro com falha será repetido cinco vezes, com cinco segundos de tempo de espera entre repetições. Se o ficheiro continuar a não conseguir copiar, a próxima tarefa do RoboCopy tentará novamente. Muitas vezes, os ficheiros que falharam porque estão a ser utilizados ou devido a problemas de tempo limite podem eventualmente ser copiados com êxito desta forma.
Windows Server 2022 e RoboCopy LFSM
O comutador /LFSM RoboCopy pode ser utilizado para evitar que uma tarefa do RoboCopy falhe com um erro de volume completo . O RoboCopy colocará em pausa sempre que uma cópia de ficheiro faria com que o espaço livre do volume de destino fosse inferior a um valor "floor".
Utilize o RoboCopy com o Windows Server 2022. Apenas esta versão do RoboCopy contém importantes correções de erros e funcionalidades que tornam o comutador compatível com sinalizadores adicionais necessários na maioria das migrações. Por exemplo, compatibilidade com o /B sinalizador.
/B executa o RoboCopy no mesmo modo que uma aplicação de cópia de segurança utilizaria. Este comutador permite ao RoboCopy mover ficheiros para os quais o utilizador atual não tem permissões.
Normalmente, o RoboCopy pode ser executado na Origem, Destino ou num terceiro computador.
Importante
Se pretender utilizar /LFSMo , o RoboCopy tem de ser executado no servidor Azure File Sync de destino do Windows Server 2022.
Tenha também em atenção que, com /LFSM o utilizador, também tem de utilizar um caminho local para o destino e não um caminho UNC. Por exemplo, como um caminho de destino, deve utilizar E:\Foldername em vez de um caminho UNC como \\ServerName\FolderName.
Atenção
A versão atualmente disponível do RoboCopy no Windows Server 2022 tem um erro que faz com que as pausas contem com a contagem de erros por ficheiro. Aplique a seguinte solução.
Os sinalizadores recomendados /R:2 /W:1 aumentam a probabilidade de um ficheiro falhar devido a uma /LFSM pausa induzida. Neste exemplo, um ficheiro que não foi copiado após 3 pausas porque /LFSM causou a pausa fará com que o RoboCopy falhe incorretamente no ficheiro. A solução para isto é utilizar valores mais elevados para /R:n e /W:n. Um bom exemplo é /R:10 /W:1800 (10 repetições de 30 minutos cada). Isto deve dar tempo ao algoritmo de camadas Azure File Sync para criar espaço no volume de destino.
Este erro foi corrigido, mas a correção ainda não está disponível publicamente. Consulte este parágrafo para obter atualizações sobre a disponibilidade da correção e como implementá-la.
Nota
Ainda tem dúvidas ou encontrou problemas?Estamos aqui para ajudar: 
Ligações relevantes
Conteúdo da migração:
Azure File Sync conteúdo: