Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Importante
O Azure Synapse Analytics Data Explorer (Visualização) será desativado em 7 de outubro de 2025. Após essa data, as cargas de trabalho em execução no Synapse Data Explorer serão excluídas e os dados do aplicativo associados serão perdidos. É altamente recomendável migrar para o Eventhouse no Microsoft Fabric.
O programa Microsoft Cloud Migration Factory (CMF) foi projetado para ajudar os clientes na migração para o Fabric. O programa oferece recursos práticos de teclado sem nenhum custo para o cliente. Estes recursos são atribuídos por um período de 6-8 semanas, com um âmbito pré-definido e acordado. As nomeações de clientes são aceites pela equipa da conta Microsoft ou diretamente através do envio de um pedido de ajuda à equipa CMF.
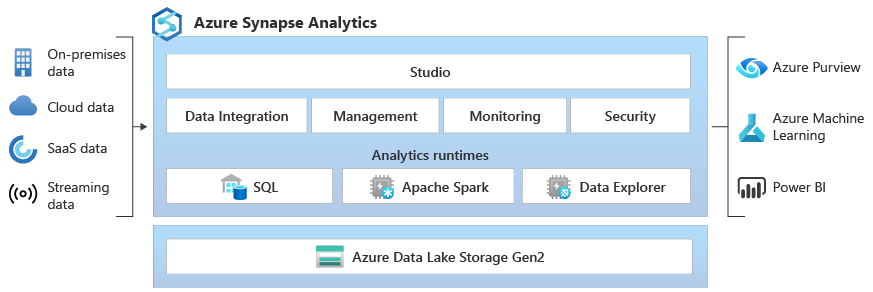
O Azure Synapse Data Explorer fornece aos clientes uma experiência de consulta interativa para desbloquear informações de dados de log e telemetria. Para complementar os mecanismos de tempo de execução de análise SQL e Apache Spark existentes, o tempo de execução de análise do Data Explorer é otimizado para análise de log eficiente usando uma poderosa tecnologia de indexação para indexar automaticamente dados semiestruturados e de texto livre comumente encontrados em dados de telemetria.
Para saber mais, veja o seguinte vídeo:
O que torna o Azure Synapse Data Explorer único?
Fácil ingestão - O Data Explorer oferece integrações integradas para ingestão de dados sem código/low-code, alta taxa de transferência e armazenamento em cache de dados de fontes em tempo real. Os dados podem ser ingeridos de fontes como Hubs de Eventos do Azure, Kafka, Azure Data Lake, agentes de código aberto, como Fluentd/Fluent Bit, e uma ampla variedade de fontes de dados locais e na nuvem.
Sem modelagem de dados complexa - Com o Data Explorer, não há necessidade de criar modelos de dados complexos e não há necessidade de scripts complexos para transformar dados antes que eles sejam consumidos.
Sem manutenção de índice - Não há necessidade de tarefas de manutenção para otimizar os dados para o desempenho da consulta e não há necessidade de manutenção do índice. Com o Data Explorer, todos os dados brutos ficam disponíveis imediatamente, permitindo que você execute consultas de alto desempenho e alta simultaneidade em seus dados persistentes e de streaming. Você pode usar essas consultas para criar painéis e alertas quase em tempo real e conectar dados de análise operacional com o restante da plataforma de análise de dados.
Democratizando a análise de dados - O Data Explorer democratiza o autosserviço e a análise de big data com a intuitiva Kusto Query Language (KQL) que fornece a expressividade e o poder do SQL com a simplicidade do Excel. O KQL é altamente otimizado para explorar dados brutos de telemetria e séries temporais, aproveitando a melhor tecnologia de indexação de texto do Data Explorer para pesquisa eficiente de texto livre e regex, e recursos abrangentes de análise para consultar rastreamentos\dados de texto e dados semiestruturados JSON, incluindo matrizes e estruturas aninhadas. O KQL oferece suporte avançado a séries temporais para criar, manipular e analisar várias séries temporais com suporte de execução Python no mecanismo para pontuação de modelos.
Tecnologia comprovada em escala de petabytes - O Data Explorer é um sistema distribuído com recursos de computação e armazenamento que pode ser dimensionado de forma independente, permitindo análises em gigabytes ou petabytes de dados.
Integrado - O Azure Synapse Analytics fornece interoperabilidade entre dados entre o Data Explorer, Apache Spark e mecanismos SQL, capacitando engenheiros de dados, cientistas de dados e analistas de dados para acessar e colaborar com facilidade e segurança nos mesmos dados no data lake.
Quando usar o Azure Synapse Data Explorer?
Use o Data Explorer como uma plataforma de dados para criar soluções de análise de log e análise de IoT quase em tempo real para:
Consolide e correlacione seus dados de logs e eventos em fontes de dados locais, na nuvem e de terceiros.
Acelere sua jornada de AI Ops (reconhecimento de padrões, deteção de anomalias, previsão e muito mais).
Substitua as soluções de pesquisa de logs baseadas em infraestrutura para economizar custos e aumentar a produtividade.
Crie soluções de análise de IoT para seus dados de IoT.
Crie soluções SaaS analíticas para oferecer serviços aos seus clientes internos e externos.
Arquitetura do pool do Data Explorer
Os pools do Data Explorer implementam uma arquitetura de expansão separando os recursos de computação e armazenamento. Isso permite dimensionar de forma independente cada recurso e, por exemplo, executar vários processos de computação somente leitura nos mesmos dados. Os pools do Data Explorer consistem em um conjunto de recursos de computação que executam o mecanismo responsável pela indexação, compactação, armazenamento em cache e atendimento automático de consultas distribuídas. Eles também dispõem de um segundo conjunto de recursos de computação que executa o serviço de gestão de dados, responsável por tarefas do sistema em segundo plano, e pela ingestão de dados monitorizada e em fila. Todos os dados são mantidos em contas de armazenamento de blob gerenciadas usando um formato colunar compactado.
Os pools do Data Explorer oferecem suporte a um ecossistema avançado para ingestão de dados usando conectores, SDKs, APIs REST e outros recursos gerenciados. Ele oferece várias maneiras de consumir dados para consultas ad hoc, relatórios, painéis, alertas, APIs REST e SDKs.
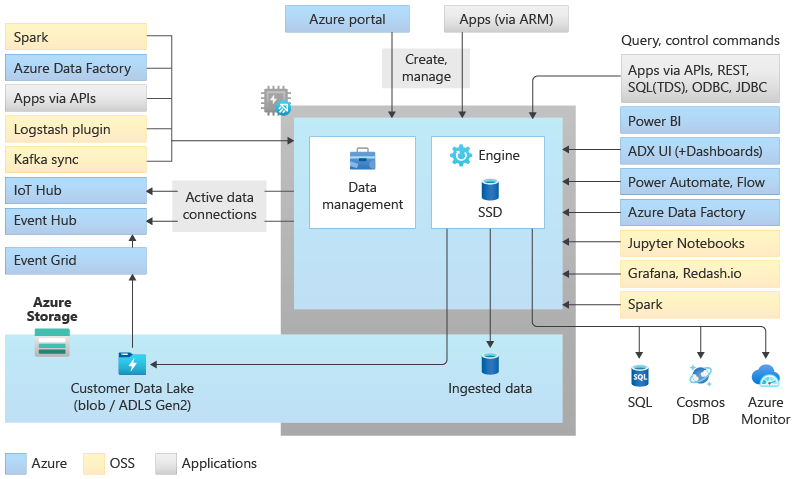
Há muitos recursos exclusivos que tornam o Data Explore o melhor mecanismo analítico para análises de log e séries cronológicas no Azure.
As seções a seguir destacam os principais diferenciais.
A indexação de dados de texto livre e semiestruturados permite consultas de alto desempenho quase em tempo real e simultâneas.
O Data Explorer indexa dados semiestruturados (JSON) e dados não estruturados (texto livre), o que faz com que as consultas em execução tenham um bom desempenho nesse tipo de dados. Por padrão, cada campo é indexado durante a ingestão de dados com a opção de usar uma política de codificação de baixo nível para ajustar ou desabilitar o índice para campos específicos. O escopo do índice é um único fragmento de dados.
A implementação do índice depende do tipo de campo, da seguinte forma:
| Tipo de campo | Implementação de indexação |
|---|---|
| String | O sistema cria um índice de termos invertido para valores de colunas de cadeia de caracteres. Cada valor de cadeia de caracteres é analisado e dividido em termos normalizados e uma lista ordenada de posições lógicas, contendo ordinais de registro, é registrada para cada termo. A lista classificada resultante de termos e suas posições associadas é armazenada como uma árvore B imutável. |
|
Numérico Data/Hora Período de tempo |
O mecanismo cria um índice avançado simples baseado em intervalo. O índice registra os valores min/max para cada bloco, para um grupo de blocos e para toda a coluna dentro do fragmento de dados. |
| dinâmico | O processo de ingestão enumera todos os elementos "atômicos" dentro do valor dinâmico, como nomes de propriedade, valores e elementos de matriz, e os encaminha para o construtor de índice. Os campos dinâmicos têm o mesmo índice de termos invertidos que os campos de cadeia de caracteres. |
Esses recursos eficientes de indexação permitem que o Data Explore disponibilize os dados quase em tempo real para consultas de alto desempenho e alta simultaneidade. O sistema otimiza automaticamente os fragmentos de dados para aumentar ainda mais o desempenho.
Linguagem de consulta Kusto
A KQL tem uma comunidade grande e crescente com a rápida adoção do Azure Monitor Log Analytics e Application Insights, Microsoft Sentinel, Azure Data Explorer e outras ofertas da Microsoft. A linguagem é bem projetada com uma sintaxe fácil de ler e fornece uma transição suave de simples uma linha para consultas complexas de processamento de dados. Isso permite que o Data Explorer forneça suporte avançado ao Intellisense e um rico conjunto de construções de linguagem e recursos internos para agregações, séries temporais e análises de usuário que não estão disponíveis no SQL para exploração rápida de dados de telemetria.