Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
O Azure Synapse Analytics oferece vários mecanismos de análise para ajudá-lo a ingerir, transformar, modelar e analisar seus dados. Um pool SQL dedicado oferece recursos de computação e armazenamento baseados em T-SQL. Depois de criar um pool SQL dedicado em seu espaço de trabalho Synapse, os dados podem ser carregados, modelados, processados e entregues para uma visão analítica mais rápida.
Neste início rápido, você aprenderá a carregar dados do Banco de Dados SQL do Azure no Azure Synapse Analytics. Você pode seguir etapas semelhantes para copiar dados de outros tipos de armazenamentos de dados. Esse fluxo semelhante também se aplica à cópia de dados para outras fontes e destinos.
Pré-requisitos
- Assinatura do Azure: se você não tiver uma assinatura do Azure, crie uma conta gratuita do Azure antes de começar.
- Espaço de trabalho do Azure Synapse: crie um espaço de trabalho Synapse usando o portal do Azure seguindo as instruções em Guia de início rápido: criar um espaço de trabalho Synapse.
- Banco de Dados SQL do Azure: este tutorial copia dados do conjunto de dados de exemplo do Adventure Works LT no Banco de Dados SQL do Azure. Você pode criar esse banco de dados de exemplo no Banco de Dados SQL seguindo as instruções em Criar um banco de dados de exemplo no Banco de Dados SQL do Azure. Ou você pode usar outros armazenamentos de dados seguindo etapas semelhantes.
- Conta de armazenamento do Azure: o Armazenamento do Azure é usado como a área de preparo na operação de cópia. Se não tem uma conta de armazenamento do Azure, veja as instruções apresentadas em Criar uma conta de armazenamento.
- Azure Synapse Analytics: você usa um pool SQL dedicado como destino de armazenamento de dados. Se você não tiver uma instância do Azure Synapse Analytics, consulte Criar um pool SQL dedicado para conhecer as etapas para criar uma.
Navegue até o Synapse Studio
Depois que o espaço de trabalho Synapse for criado, você terá duas maneiras de abrir o Synapse Studio:
- Abra seu espaço de trabalho Synapse no portal do Azure. Selecione Abrir no cartão Open Synapse Studio em Introdução.
- Abra o Azure Synapse Analytics e inicie sessão na sua área de trabalho.
Neste início rápido, usamos o espaço de trabalho chamado "adftest2020" como exemplo. Ele irá navegar automaticamente para a página inicial do Synapse Studio.
Criar serviços vinculados
No Azure Synapse Analytics, um serviço vinculado é onde você define suas informações de conexão com outros serviços. Nesta seção, você criará dois tipos de serviços vinculados a seguir: Banco de Dados SQL do Azure e serviços vinculados do Azure Data Lake Storage Gen2 (ADLS Gen2).
Na página inicial do Synapse Studio, selecione a guia Gerenciar na navegação à esquerda.
Em Conexões externas, selecione Serviços vinculados.

Para adicionar um serviço vinculado, selecione Novo.
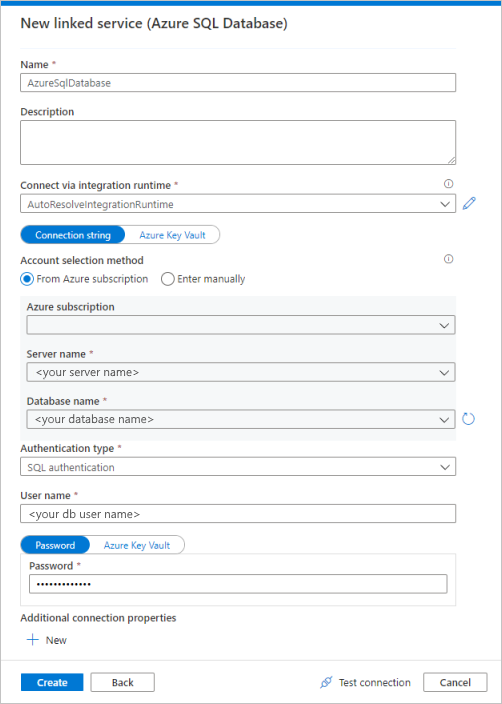
Selecione Banco de Dados SQL do Azure na galeria e, em seguida, selecione Continuar. Você pode digitar "sql" na caixa de pesquisa para filtrar os conectores.

Na página Novo Serviço Ligado, selecione o nome do servidor e o nome da base de dados na lista suspensa e especifique o nome de utilizador e a senha. Clique em Testar conexão para validar as configurações e selecione Criar.
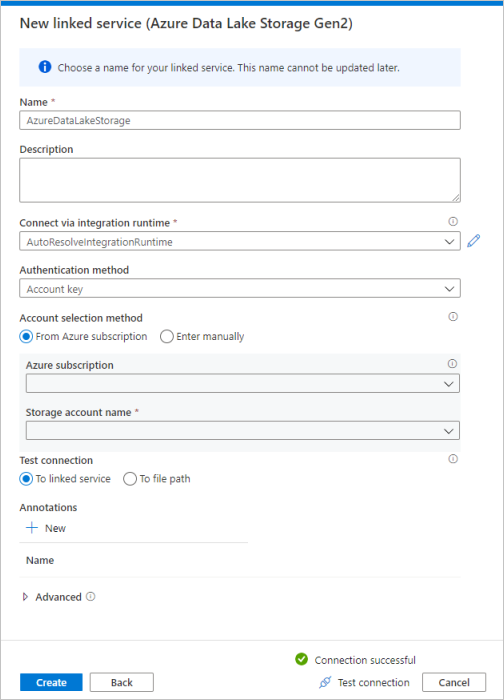
Repita as etapas 3 a 4, mas selecione Azure Data Lake Storage Gen2 na galeria. Na página Novo Serviço Vinculado, selecione o nome da sua conta de armazenamento na lista suspensa. Clique em Testar conexão para validar as configurações e selecione Criar.
Criar uma canalização
Um pipeline contém o fluxo lógico para uma execução de um conjunto de atividades. Nesta seção, você criará um pipeline contendo uma atividade de cópia que ingere dados do Banco de Dados SQL do Azure em um pool SQL dedicado.
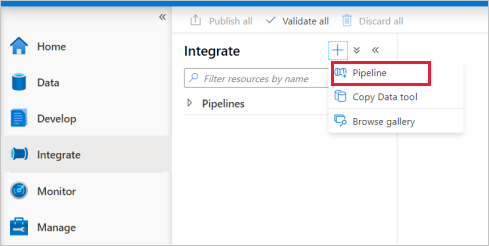
Vá para o separador Integrar. Clique no ícone do sinal de adição ao lado do cabeçalho dos pipelines e escolha a opção Pipeline.
Em Mover e Transformar no painel Atividades, arraste Copiar dados para a tela do pipeline.
Selecione a atividade de cópia e vá para a guia Origem. Selecione Novo para criar um novo conjunto de dados de origem.
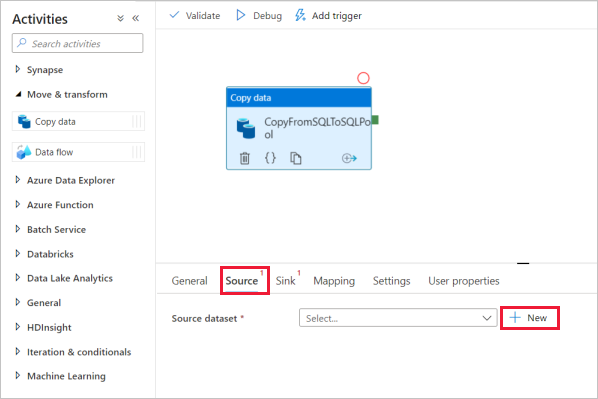
Selecione Banco de Dados SQL do Azure como seu armazenamento de dados e selecione Continuar.
No painel Definir propriedades , selecione o serviço vinculado do Banco de Dados SQL do Azure que você criou na etapa anterior.
Em Nome da tabela, selecione uma tabela de exemplo para usar na atividade de cópia a seguir. Neste guia de início rápido, usamos a tabela "SalesLT.Customer" como exemplo.
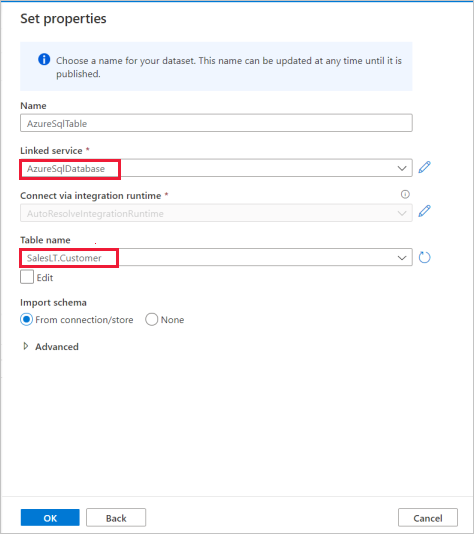
Selecione OK quando terminar.
Selecione a atividade de cópia e vá para a guia Coletor. Selecione Novo para criar um novo conjunto de dados de coletor.
Selecione o pool SQL dedicado do Azure Synapse como seu armazenamento de dados e selecione Continuar.
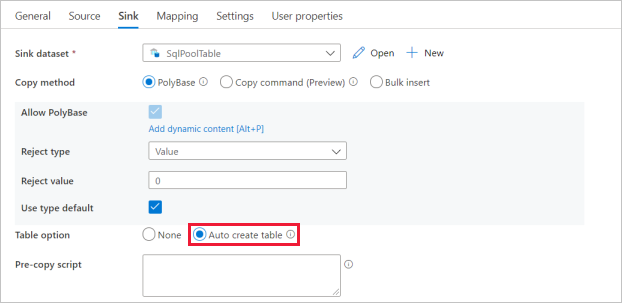
No painel Definir propriedades , selecione o pool do SQL Analytics criado na etapa anterior. Se estiver a escrever numa tabela existente, em Nome da tabela, selecione-a na lista pendente. Caso contrário, marque "Editar" e insira o nome da nova tabela. Selecione OK quando terminar.
Para Configurações do conjunto de dados do coletor, habilite a criação automática de tabela no campo de opção Tabela.
Na página Definições, marque a caixa de seleção Habilitar staging. Esta opção se aplica se os dados de origem não forem compatíveis com o PolyBase. Na seção Configurações de preparação, selecione o serviço de ligação do Azure Data Lake Storage Gen2 que foi criado na etapa anterior como armazenamento de preparação.
O armazenamento é usado para preparar os dados antes de serem carregados no Azure Synapse Analytics usando o PolyBase. Após a conclusão da cópia, os dados provisórios no Azure Data Lake Storage Gen2 são limpos automaticamente.
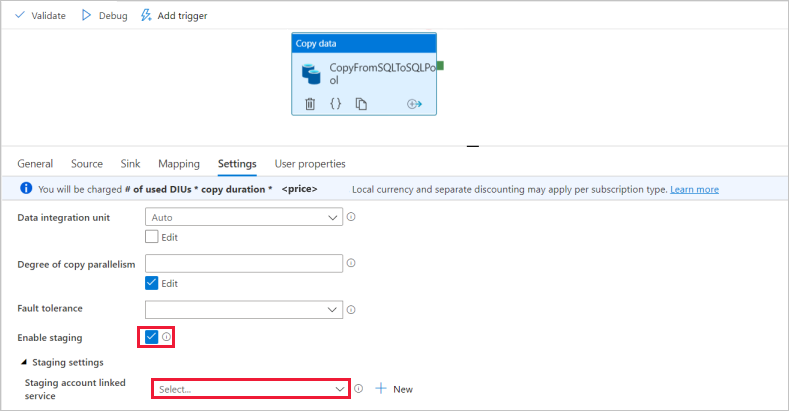
Para validar o pipeline, selecione Validar na barra de ferramentas. Pode ver o resultado da validação do pipeline à direita da página.
Debug and publish the pipeline (Depurar e publicar o pipeline)
Depois de concluir a configuração do pipeline, você pode executar uma execução de depuração antes de publicar seus artefatos para verificar se tudo está correto.
Para depurar o pipeline, selecione Depurar na barra de ferramentas. Verá o estado da execução do pipeline no separador Saída, na parte inferior da janela.
Quando a execução do pipeline for bem-sucedida, na barra de ferramentas superior, selecione Publicar tudo. Esta ação publica entidades (conjuntos de dados e pipelines) que você criou no serviço Synapse Analytics.
Aguarde até surgir a mensagem Publicação bem-sucedida. Para ver as mensagens de notificação, selecione o botão de sino no canto superior direito.
Acionar e monitorizar o pipeline
Nesta seção, você aciona manualmente o pipeline publicado na etapa anterior.
Selecione Adicionar gatilho na barra de ferramentas e, em seguida, selecione Gatilho agora. Na página Execução de pipeline, selecione OK.
Vá para a guia Monitor localizada na barra lateral esquerda. Verá uma execução de pipeline que é acionada por um acionador manual.
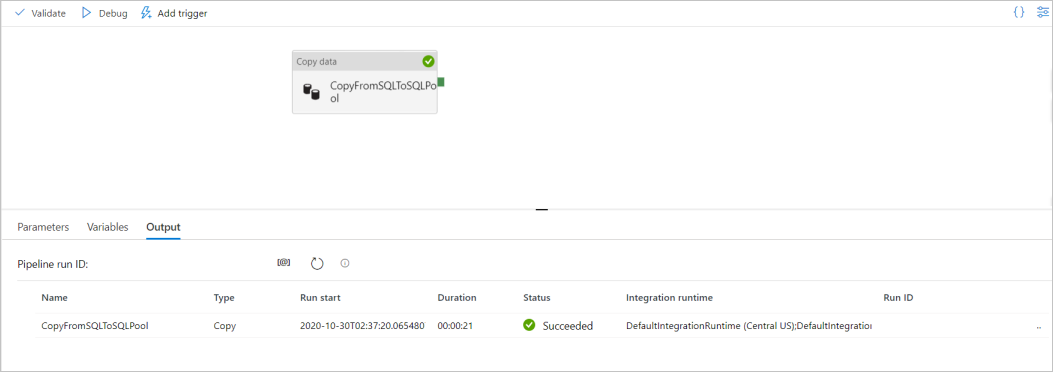
Quando a execução do pipeline for concluída com êxito, selecione o link na coluna Nome do pipeline para exibir os detalhes da execução da atividade ou para executar novamente o pipeline. Neste exemplo, há apenas uma atividade, portanto, você vê apenas uma entrada na lista.
Para obter detalhes sobre a operação de cópia, selecione o link Detalhes (ícone de óculos) na coluna Nome da atividade. Você pode monitorar detalhes como o volume de dados copiados da origem para o coletor, taxa de transferência de dados, etapas de execução com duração correspondente e configurações usadas.
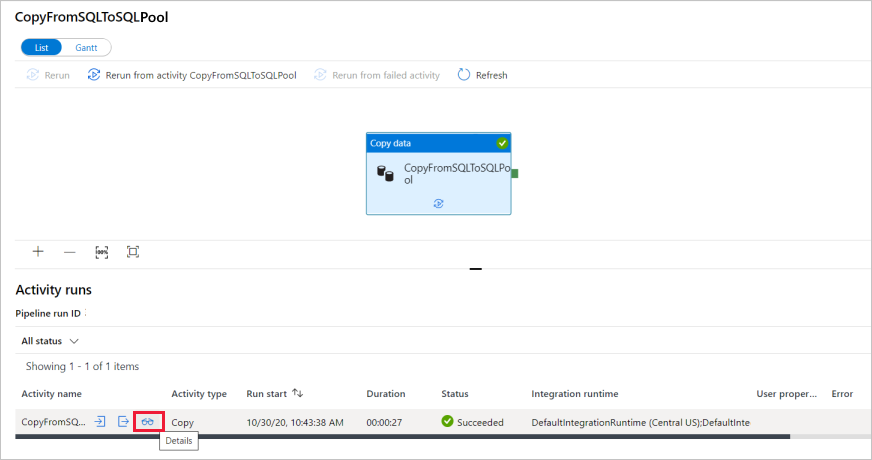
Para voltar para a exibição de execuções de pipeline, selecione o link Todas as execuções de pipeline na parte superior. Selecione Atualizar para atualizar a lista.
Verifique se seus dados estão escritos corretamente no pool SQL dedicado.
Próximos passos
Avance para o seguinte artigo para saber mais sobre o suporte do Azure Synapse Analytics: