Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Neste tutorial, vais aprender a realizar análises exploratórias de dados usando Azure Open Datasets e Apache Spark. Pode então visualizar os resultados num caderno do Synapse Studio no Azure Synapse Analytics.
Em particular, vamos analisar o conjunto de dados de táxis da cidade de Nova Iorque (NYC ). Os dados estão disponíveis através dos Conjuntos de Dados Abertos do Azure. Este subconjunto do conjunto de dados contém informações sobre viagens de táxi amarelo: informações sobre cada viagem, a hora e locais de início e fim, o custo e outros atributos interessantes.
Antes de começar
Crie um Apache Spark Pool seguindo o tutorial Criar um Apache Spark Pool.
Faça o download e prepare os dados
Crie um bloco de anotações usando o kernel do PySpark. Para obter instruções, consulte Criar um bloco de anotações.
Observação
Devido ao kernel do PySpark, você não precisa criar nenhum contexto explicitamente. O contexto do Spark é criado automaticamente para você quando você executa a primeira célula de código.
Neste tutorial, vamos usar várias bibliotecas diferentes para nos ajudar a visualizar o conjunto de dados. Para fazer essa análise, importe as seguintes bibliotecas:
import matplotlib.pyplot as plt import seaborn as sns import pandas as pdComo os dados brutos estão em um formato Parquet, você pode usar o contexto do Spark para carregar o arquivo diretamente para a memória como um DataFrame. Crie um DataFrame Spark recuperando os dados através da API Open Datasets. Aqui, usamos o esquema Spark DataFrame nas propriedades de leitura para inferir os tipos de dados e o esquema.
from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())Depois de os dados serem lidos, vamos querer fazer uma filtragem inicial para limpar o conjunto de dados. Podemos remover colunas desnecessárias e adicionar colunas que extraiam informação importante. Além disso, vamos filtrar anomalias dentro do conjunto de dados.
# Filter the dataset from pyspark.sql.functions import * filtered_df = df.select('vendorID', 'passengerCount', 'tripDistance','paymentType', 'fareAmount', 'tipAmount'\ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , dayofweek('tpepPickupDateTime').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month'))\ .filter((df.passengerCount > 0)\ & (df.tipAmount >= 0)\ & (df.fareAmount >= 1) & (df.fareAmount <= 250)\ & (df.tripDistance > 0) & (df.tripDistance <= 200)) filtered_df.createOrReplaceTempView("taxi_dataset")
Analise dados
Como analista de dados, você tem uma ampla gama de ferramentas disponíveis para ajudá-lo a extrair insights dos dados. Nesta parte do tutorial, vamos apresentar algumas ferramentas úteis disponíveis nos cadernos Azure Synapse Analytics. Nesta análise, queremos compreender os fatores que resultam em gorjetas de táxi mais elevadas durante o período que escolhemos.
Apache Spark SQL Magic
Primeiro, vamos realizar análises exploratórias de dados com Apache Spark SQL e comandos mágicos com o caderno Azure Synapse. Depois de termos a nossa consulta, visualizamos os resultados usando a funcionalidade incorporada chart options .
No seu caderno, crie uma nova célula e copie o código seguinte. Ao usar esta consulta, queremos compreender como as quantidades médias das gorjetas mudaram ao longo do período que selecionámos. Esta consulta também nos ajudará a identificar outras informações úteis, incluindo o valor mínimo/máximo das gorjetas por dia e o valor médio da tarifa.
%%sql SELECT day_of_month , MIN(tipAmount) AS minTipAmount , MAX(tipAmount) AS maxTipAmount , AVG(tipAmount) AS avgTipAmount , AVG(fareAmount) as fareAmount FROM taxi_dataset GROUP BY day_of_month ORDER BY day_of_month ASCDepois de a nossa consulta terminar de ser executada, podemos visualizar os resultados mudando para a vista do gráfico. Este exemplo cria um gráfico de linhas especificando o
day_of_monthcampo como a chave eavgTipAmountcomo o valor. Depois de fazer as seleções, selecione Aplicar para atualizar o seu gráfico.
Visualizar os dados
Além das opções de gráficos de bloco de anotações integradas, você pode usar bibliotecas de código aberto populares para criar suas próprias visualizações. Nos exemplos seguintes, vamos usar Seaborn e Matplotlib. Estas são bibliotecas Python frequentemente utilizadas para visualização de dados.
Observação
Por padrão, cada pool do Apache Spark no Azure Synapse Analytics contém um conjunto de bibliotecas comumente usadas. Pode consultar a lista completa de bibliotecas na documentação do runtime do Azure Synapse. Além disso, para disponibilizar código de terceira parte ou criado localmente para as suas aplicações, pode instalar uma biblioteca num dos seus pools Spark.
Para tornar o desenvolvimento mais fácil e menos dispendioso, vamos reduzir o conjunto de dados. Vamos usar a capacidade incorporada de amostragem do Apache Spark. Além disso, tanto Seaborn quanto Matplotlib exigem uma matriz Pandas DataFrame ou NumPy. Para obter um Pandas DataFrame, use o
toPandas()comando para converter o DataFrame.# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) # The charting package needs a Pandas DataFrame or NumPy array to do the conversion sampled_taxi_pd_df = sampled_taxi_df.toPandas()Queremos compreender a distribuição das dicas no nosso conjunto de dados. Vamos usar o Matplotlib para criar um histograma que mostra a distribuição do valor e do número de gorjetas. Com base na distribuição, podemos ver que as gorjetas estão tendenciosas para valores inferiores ou iguais a 10 dólares.
# Look at a histogram of tips by count by using Matplotlib ax1 = sampled_taxi_pd_df['tipAmount'].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show()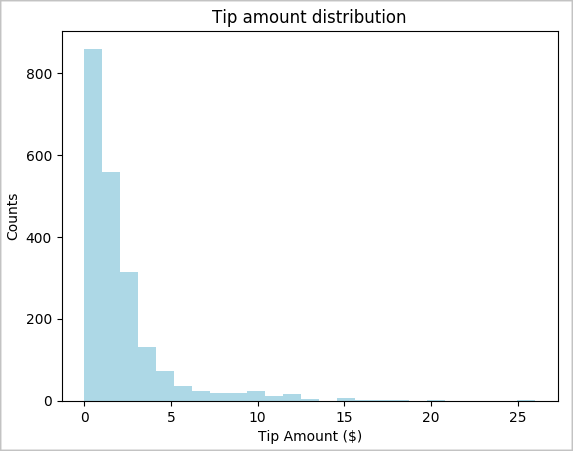
De seguida, queremos compreender a relação entre as gorjetas de uma determinada viagem e o dia da semana. Utilize o Seaborn para criar um diagrama de caixa que resuma as tendências de cada dia da semana.
# View the distribution of tips by day of week using Seaborn ax = sns.boxplot(x="day_of_week", y="tipAmount",data=sampled_taxi_pd_df, showfliers = False) ax.set_title('Tip amount distribution per day') ax.set_xlabel('Day of Week') ax.set_ylabel('Tip Amount ($)') plt.show()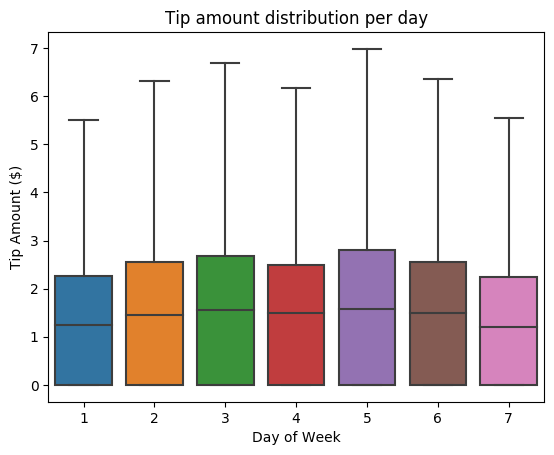
Outra hipótese nossa pode ser que existe uma relação positiva entre o número de passageiros e o valor total das gorjetas do táxi. Para verificar esta relação, execute o código a seguir para gerar um gráfico de caixa que ilustra a distribuição de gorjetas para cada contagem de passageiros.
# How many passengers tipped by various amounts ax2 = sampled_taxi_pd_df.boxplot(column=['tipAmount'], by=['passengerCount']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') ax2.set_ylim(0,30) plt.suptitle('') plt.show()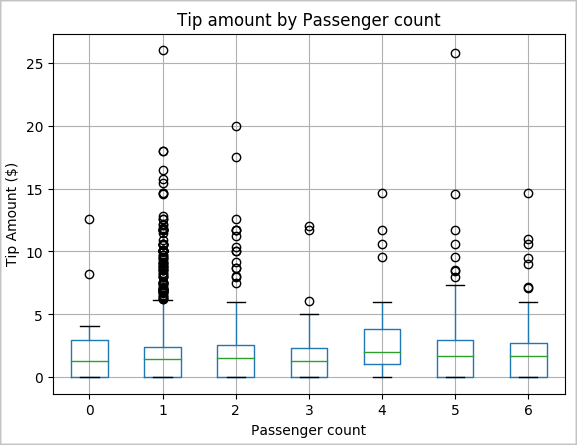
Por fim, queremos compreender a relação entre o valor da tarifa e o valor das gorjetas. Com base nos resultados, podemos ver que há várias observações em que as pessoas não dão gorjeta. No entanto, também vemos uma relação positiva entre a tarifa total e os montantes das gorjetas.
# Look at the relationship between fare and tip amounts ax = sampled_taxi_pd_df.plot(kind='scatter', x= 'fareAmount', y = 'tipAmount', c='blue', alpha = 0.10, s=2.5*(sampled_taxi_pd_df['passengerCount'])) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.suptitle('') plt.show()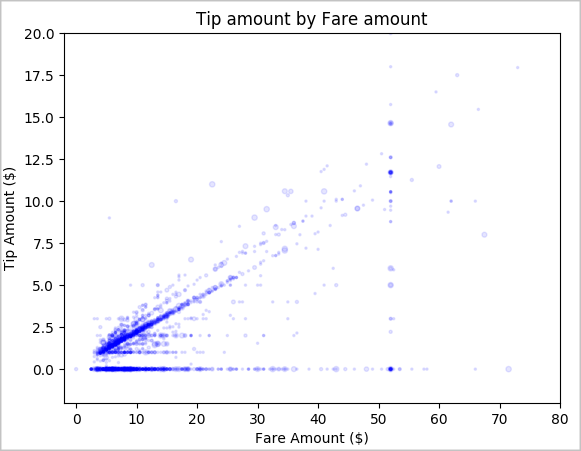
Encerrar a instância do Spark
Depois de terminares de executar a aplicação, desliga o caderno para libertar os recursos. Ou fecha o separador ou seleciona Terminar Sessão no painel de estado na parte inferior do caderno.
Consulte também
- Visão geral: Apache Spark no Azure Synapse Analytics
- Construir um modelo de aprendizagem automática com Apache SparkML