Arquitetura de pool SQL dedicado (anteriormente SQL DW) no Azure Synapse Analytics
O Azure Synapse Analytics é um serviço de análise que reúne armazenamento de dados corporativos e análise de Big Data. Dá-lhe a liberdade de consultar dados nos seus termos.
Nota
Para saber mais sobre o Azure Synapse Analytics, assista a este vídeo explicando os aprimoramentos de movimentação de dados.
Componentes da arquitetura Synapse SQL
O pool SQL dedicado (anteriormente SQL DW) aproveita uma arquitetura de expansão para distribuir o processamento computacional de dados entre vários nós. A unidade de escala é uma abstração do poder de computação que é conhecida como uma unidade de armazém de dados. A computação é separada do armazenamento, o que permite dimensioná-la independentemente dos dados no sistema.
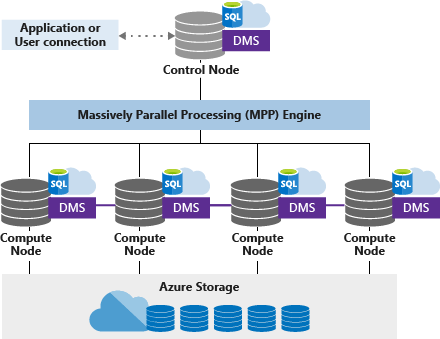
O pool SQL dedicado (anteriormente SQL DW) usa uma arquitetura baseada em nós. Os aplicativos se conectam e emitem comandos T-SQL para um nó de controle. O nó Controle hospeda o mecanismo de consulta distribuído, que otimiza consultas para processamento paralelo e, em seguida, passa operações para nós de computação para fazer seu trabalho em paralelo.
Os nós de computação armazenam todos os dados de utilizador no Armazenamento do Microsoft Azure e executam as consultas paralelas. O Serviço de Movimento de Dados (DMS – Data Movement Service) é um serviço interno ao nível do sistema que move os dados em todos os nós, conforme necessário, para executar consultas em paralelo e devolver resultados precisos.
Com armazenamento e computação dissociados, ao usar um pool SQL dedicado (anteriormente SQL DW) pode-se:
- Dimensione o poder de computação de forma independente, independentemente das suas necessidades de armazenamento.
- Aumente ou diminua o poder de computação, dentro de um pool SQL dedicado (anteriormente SQL DW), sem mover dados.
- Colocar a capacidade de computação em pausa, mantendo os dados intactos, pelo que só paga pelo armazenamento.
- Retomar a capacidade de computação durante as horas de funcionamento.
Armazenamento do Azure
O SQL pool dedicado (anteriormente SQL DW) aproveita o Armazenamento do Azure para manter seus dados de usuário seguros. Como seus dados são armazenados e gerenciados pelo Armazenamento do Azure, há uma cobrança separada para seu consumo de armazenamento. Os dados são fragmentados em distribuições para otimizar o desempenho do sistema. Pode escolher o padrão de fragmentação que será utilizado para distribuir os dados, ao definir a tabela. Estes padrões de fragmentação são suportados:
- Hash
- Round Robin
- Replicar
Nó de controlo
O nó de Controlo é o cérebro da arquitetura. É o front-end que interage com todas as ligações e aplicações. O mecanismo de consulta distribuído é executado no nó Controle para otimizar e coordenar consultas paralelas. Quando você envia uma consulta T-SQL, o nó Control a transforma em consultas que são executadas em cada distribuição em paralelo.
Nós de computação
Os nós de Computação conferem capacidade de computação. As distribuições são mapeadas para nós de computação para processamento. À medida que você paga por mais recursos de computação, as distribuições são remapeadas para nós de computação disponíveis. O número de nós de computação varia de 1 a 60 e é determinado pelo nível de serviço do Synapse SQL.
Cada nó de computação tem um ID de nó que é visível nas exibições do sistema. Você pode ver a ID do nó de computação procurando a coluna node_id nas visualizações do sistema cujos nomes começam com sys.pdw_nodes. Para obter uma lista dessas exibições do sistema, consulte Exibições do sistema Synapse SQL.
Serviço de Movimento de Dados
O Data Movement Service (DMS) é a tecnologia de transporte de dados que coordena a movimentação de dados entre os nós de computação. Algumas consultas exigem movimentação de dados para garantir que as consultas paralelas retornem resultados precisos. Quando a movimentação de dados é necessária, o DMS garante que os dados certos cheguem ao local certo.
Distribuições
As distribuições são as unidades básicas de armazenamento e processamento de consultas paralelas que são executadas em dados distribuídos. Quando o Synapse SQL executa uma consulta, o trabalho é dividido em 60 consultas menores que são executadas em paralelo.
Cada uma das 60 consultas menores é executada em uma das distribuições de dados. Cada nó de computação gerencia uma ou mais das 60 distribuições. Um pool SQL dedicado (anteriormente SQL DW) com recursos de computação máximos tem uma distribuição por nó de computação. Um pool SQL dedicado (anteriormente SQL DW) com recursos mínimos de computação tem todas as distribuições em um nó de computação.
Nota
Para obter recomendações sobre a melhor estratégia de distribuição de tabela a ser usada com base em suas cargas de trabalho, consulte o Azure Synapse SQL Distribution Advisor.
Tabelas distribuídas com hash
Uma tabela distribuída com hash pode proporcionar o mais elevado desempenho de consulta para associações e agregações em tabelas grandes.
Para realizar a extensão de dados para uma tabela distribuída por hash, é utilizada uma função hash para atribuir de forma determinista cada linha a uma distribuição. Na definição da tabela, uma das colunas será a coluna de distribuição. A função hash utiliza os valores da coluna de distribuição para atribuir cada linha a uma distribuição.
O diagrama seguinte ilustra como uma tabela não distribuída completa é armazenada como uma tabela distribuída por hash.

- Cada linha pertence a uma distribuição.
- Um algoritmo hash determinista atribui cada linha a uma distribuição.
- O número de linhas da tabela por distribuição varia conforme mostrado pelos diferentes tamanhos das tabelas.
Há considerações de desempenho para a seleção de uma coluna de distribuição, como distinção, distorção de dados e os tipos de consultas que são executadas no sistema.
Tabelas distribuídas por round robin
Uma mesa round-robin é a mesa mais simples de criar e oferece desempenho rápido quando usada como uma mesa de preparo para cargas.
As tabelas distribuídas com round robin distribuem uniformemente os dados por uma tabela, mas sem qualquer otimização adicional. Uma distribuição é primeiro escolhida aleatoriamente e, em seguida, buffers de linhas são atribuídos a distribuições sequencialmente. O carregamento de dados para tabelas round robin é rápido, mas o desempenho das consultas é, muitas vezes, superior se as tabelas forem distribuídas com hash. As junções em mesas round-robin exigem a reorganização dos dados, o que leva mais tempo.
Tabelas replicadas
As tabelas replicadas proporcionam o desempenho de consulta mais rápido para tabelas pequenas.
Uma tabela replicada armazena em cache uma cópia completa da tabela em cada nó de computação. Por conseguinte, a replicação de uma tabela elimina a necessidade de transferir dados entre nós de computação antes de se proceder a uma associação ou agregação. Idealmente, as tabelas replicadas devem ser utilizadas com tabelas pequenas. É necessário armazenamento extra e há sobrecarga adicional incorrida ao gravar dados, o que torna as tabelas grandes impraticáveis.
O diagrama abaixo mostra uma tabela replicada que é armazenada em cache na primeira distribuição em cada nó de computação.

Próximos passos
Agora que você sabe um pouco sobre o Azure Synapse, saiba como criar rapidamente um pool SQL dedicado (anteriormente SQL DW) e carregar dados de exemplo. Se não estiver familiarizado com o Azure, poderá achar útil o Glossário do Azure quando se deparar com terminologia nova. Ou veja alguns desses outros Recursos do Azure Synapse.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários