Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este artigo contém recomendações para projetar tabelas distribuídas por hash e round-robin em pools SQL dedicados.
Este artigo pressupõe que você esteja familiarizado com os conceitos de distribuição e movimentação de dados no pool SQL dedicado. Para obter mais informações, consulte Arquitetura do Azure Synapse Analytics.
O que é uma tabela distribuída?
Uma tabela distribuída aparece como uma única tabela, mas as linhas são realmente armazenadas em 60 distribuições. As linhas são distribuídas com algoritmos de hash ou de round-robin.
A distribuição de hash melhora o desempenho da consulta em grandes tabelas de fatos e é o foco deste artigo. Distribuição round-robin é útil para melhorar a velocidade de carregamento. Essas opções de design têm um efeito significativo na melhoria do desempenho de consulta e carregamento.
Outra opção de armazenamento de tabela é replicar uma pequena tabela em todos os nós de computação. Para obter mais informações, consulte Diretrizes de design para tabelas replicadas. Para escolher rapidamente entre as três opções, consulte a secção Tabelas distribuídas na visão geral das tabelas.
Como parte do design da tabela, entenda o máximo possível sobre seus dados e como eles são consultados. Por exemplo, considere estas perguntas:
- Qual é o tamanho da mesa?
- Com que frequência a tabela é atualizada?
- Tenho tabelas de fatos e dimensões em um pool SQL dedicado?
Distribuição hash
Uma tabela de distribuição por hash distribui as linhas da tabela pelos nós de computação usando uma função hash determinista para atribuir cada linha a uma distribuição.
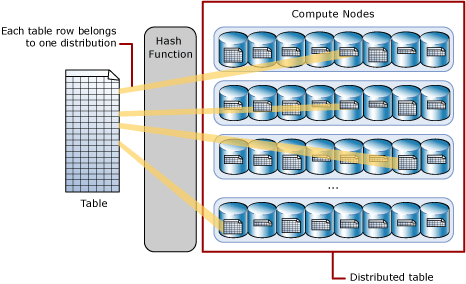
Uma vez que os valores idênticos aplicam sempre hash à mesma distribuição, a Análise de SQL tem conhecimento incorporado das localizações das linhas. No pool SQL dedicado, esse conhecimento é usado para minimizar a movimentação de dados durante as consultas, o que melhora o desempenho da consulta.
As tabelas distribuídas com hash funcionam bem com grandes tabelas de factos num esquema de estrela. Eles podem ter um número muito grande de linhas e ainda alcançar elevado desempenho. Há algumas considerações de design que ajudam você a obter o desempenho que o sistema distribuído foi projetado para fornecer. Escolher uma boa coluna ou colunas de distribuição é uma dessas considerações descritas neste artigo.
Considere utilizar uma tabela distribuída com hash quando:
- O tamanho da tabela no disco é superior a 2 GB.
- A tabela tem operações frequentes de inserção, atualização e exclusão.
Round-robin distribuído
Uma tabela distribuída de round-robin distribui as linhas da tabela uniformemente por todas as distribuições. A atribuição de linhas a distribuições é aleatória. Ao contrário das tabelas distribuídas com hash, não é garantido que as linhas com valores iguais sejam atribuídas à mesma distribuição.
Como resultado, o sistema às vezes precisa invocar uma operação de movimentação de dados para organizar melhor seus dados antes de resolver uma consulta. Este passo extra pode tornar as suas consultas mais lentas. Por exemplo, participar de uma mesa de round-robin geralmente requer a reorganização das linhas, o que é um impacto negativo no desempenho.
Considere usar a distribuição round-robin para sua tabela nos seguintes cenários:
- Ao começar, é útil usar um ponto de partida simples, visto que é o padrão.
- Se não houver uma chave de junção óbvia
- Se não houver uma boa coluna candidata para a distribuição hash da tabela
- Se a tabela não partilhar uma chave de junção comum com outras tabelas
- Se a associação for menos significativa do que outras associações na consulta
- Quando a tabela é uma tabela de preparo temporária
O tutorial Load New York taxicab data dá um exemplo de carregamento de dados numa tabela de preparação round-robin.
Escolher uma coluna de distribuição
Uma tabela distribuída por hash tem uma coluna de distribuição ou um conjunto de colunas que é a chave de hash. Por exemplo, o código a seguir cria uma tabela distribuída por hash com ProductKey como a coluna de distribuição.
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey])
);
A distribuição de hash pode ser aplicada em várias colunas para uma distribuição mais uniforme da tabela base. A distribuição de várias colunas permite que você escolha até oito colunas para distribuição. Isso não só reduz a distorção de dados ao longo do tempo, mas também melhora o desempenho da consulta. Por exemplo:
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey], [OrderDateKey], [CustomerKey] , [PromotionKey])
);
Nota
A distribuição de várias colunas no Azure Synapse Analytics pode ser habilitada alterando o nível de compatibilidade do banco de dados para 50 com este comando.
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50;Para obter mais informações sobre como definir o nível de compatibilidade do banco de dados, consulte ALTER DATABASE SCOPED CONFIGURATION. Para obter mais informações sobre distribuições de várias colunas, consulte CREATE MATERIALIZED VIEW, CREATE TABLE ou CREATE TABLE AS SELECT.
Os dados armazenados nas colunas de distribuição podem ser atualizados. Atualizações de dados em colunas de distribuição podem resultar em operações de reordenamento de dados.
Escolher colunas de distribuição é uma decisão de design importante, uma vez que os valores nas colunas de hash determinam como as linhas são distribuídas. A melhor escolha depende de vários fatores, e geralmente envolve compensações. Depois que uma coluna de distribuição ou um conjunto de colunas é escolhido, você não pode alterá-lo. Se você não escolheu as melhores colunas na primeira vez, você pode usar CREATE TABLE AS SELECT (CTAS) para recriar a tabela com a chave de hash de distribuição desejada.
Escolha uma coluna de distribuição com dados que distribua uniformemente
Para um melhor desempenho, todas as distribuições devem ter aproximadamente o mesmo número de linhas. Quando uma ou mais distribuições têm um número desproporcional de linhas, algumas distribuições terminam sua parte de uma consulta paralela antes de outras. Como a consulta não pode ser concluída até que todas as distribuições tenham terminado o processamento, cada consulta é tão rápida quanto a distribuição mais lenta.
- A distorção de dados significa que os dados não são distribuídos uniformemente entre as distribuições
- A distorção de processamento significa que algumas distribuições levam mais tempo do que outras ao executar consultas paralelas. Isso pode acontecer quando os dados são distorcidos.
Para equilibrar o processamento paralelo, selecione uma coluna de distribuição ou um conjunto de colunas que:
- Tem muitos valores únicos. Uma ou mais colunas de distribuição podem ter valores duplicados. Todas as linhas com o mesmo valor são atribuídas à mesma distribuição. Como existem 60 distribuições, algumas distribuições podem ter > 1 valor único, enquanto outras podem terminar com valores zero.
- Não tem NULLs, ou tem apenas poucos NULLs. Para um exemplo extremo, se todos os valores nas colunas de distribuição forem NULL, todas as linhas serão atribuídas à mesma distribuição. Como resultado, o processamento de consultas fica enviesado para uma distribuição e não se beneficia do processamento paralelo.
- Não é uma coluna de data. Todos os dados para a mesma data ficam na mesma distribuição ou agrupam registros por data. Se vários usuários estiverem filtrando na mesma data (como a data de hoje), apenas 1 das 60 distribuições faz todo o trabalho de processamento.
Escolha uma coluna de distribuição que minimize a movimentação de dados
Para obter o resultado de consulta correto, as consultas podem mover dados de um nó de computação para outro. A movimentação de dados geralmente acontece quando as consultas têm junções e agregações em tabelas distribuídas. Escolher uma coluna de distribuição ou um conjunto de colunas que ajude a minimizar a movimentação de dados é uma das estratégias mais importantes para otimizar o desempenho do seu pool SQL dedicado.
Para minimizar a movimentação de dados, selecione uma coluna de distribuição ou um conjunto de colunas que:
- É usado em
JOIN,GROUP BY,DISTINCT,OVER, eHAVINGcláusulas. Quando duas grandes tabelas de fatos têm junções frequentes, o desempenho da consulta melhora quando você distribui ambas as tabelas em uma das colunas de junção. Quando uma tabela não é usada em junções, considere distribuir a tabela em uma coluna ou conjunto de colunas que esteja frequentemente na cláusulaGROUP BY. - Não é usado em
WHEREcláusulas. Quando a cláusulaWHEREde uma consulta e as colunas de distribuição da tabela estão na mesma coluna, a consulta pode encontrar um alto desequilíbrio de dados, o que faz com que a carga de processamento recaia apenas sobre algumas distribuições. Isso afeta o desempenho da consulta, idealmente muitas distribuições compartilham a carga de processamento. - Não é uma coluna de data.
WHEREAs cláusulas geralmente filtram por data. Quando isso acontece, todo o processamento pode ser executado em apenas algumas distribuições que afetam o desempenho da consulta. Idealmente, muitas distribuições compartilham a carga de processamento.
Depois de criar a tabela distribuída com hash, o passo seguinte consistirá em carregar dados para a tabela. Para obter orientação sobre carregamento, consulte Visão geral de carregamento.
Como saber se a sua distribuição é uma boa escolha
Depois de carregar os dados para a tabela distribuída com hash, verifique se as linhas estão distribuídas uniformemente pelas 60 distribuições. As linhas por distribuição podem variar até 10% sem um impacto percetível no desempenho.
Considere as seguintes maneiras de avaliar suas colunas de distribuição.
Determinar se a tabela tem distorção de dados
Uma maneira rápida de verificar a distorção de dados é usar o DBCC PDW_SHOWSPACEUSED. O código SQL a seguir retorna o número de linhas da tabela armazenadas em cada uma das 60 distribuições. Para um desempenho equilibrado, as linhas na tabela distribuída devem ser distribuídas uniformemente em todas as distribuições.
-- Find data skew for a distributed table
DBCC PDW_SHOWSPACEUSED('dbo.FactInternetSales');
Para identificar quais tabelas têm mais de 10% de distorção de dados:
- Crie a vista
dbo.vTableSizesque é mostrada no artigo Visão geral de tabelas. - Execute a seguinte consulta:
select *
from dbo.vTableSizes
where two_part_name in
(
select two_part_name
from dbo.vTableSizes
where row_count > 0
group by two_part_name
having (max(row_count * 1.000) - min(row_count * 1.000))/max(row_count * 1.000) >= .10
)
order by two_part_name, row_count;
Verificar planos de consulta para transferência de dados
Um bom conjunto de colunas de distribuição permite que junções e agregações tenham um movimento mínimo de dados. Isso afeta a forma como as junções devem ser escritas. Para obter um movimento mínimo de dados numa junção entre duas tabelas distribuídas por hash, uma das colunas de junção precisa estar numa coluna ou em colunas de distribuição. Quando duas tabelas distribuídas com hash são associadas numa coluna de distribuição com o mesmo tipo de dados, a associação não necessita do movimento de dados. As associações podem usar colunas adicionais sem incorrer em movimentação de dados.
Para evitar a movimentação de dados durante uma associação:
- As tabelas envolvidas na junção têm de ser distribuídas com hash numa das colunas que participam na junção.
- Os tipos de dados das colunas de junção devem corresponder entre ambas as tabelas.
- As colunas devem ser unidas com um operador equals.
- O tipo de junção não pode ser um
CROSS JOIN.
Para verificar se as consultas estão a enfrentar movimentação de dados, pode-se examinar o plano de consulta.
Resolver um problema de coluna de distribuição
Não é necessário resolver todos os casos de distorção de dados. Distribuir dados é uma questão de encontrar o equilíbrio certo entre minimizar a distorção de dados e a movimentação de dados. Nem sempre é possível minimizar a distorção e a movimentação de dados. Às vezes, o benefício de ter a movimentação mínima de dados pode superar o efeito de ter a distorção de dados.
Para decidir se você deve resolver a distorção de dados em uma tabela, você deve entender o máximo possível sobre os volumes de dados e consultas em sua carga de trabalho. Você pode usar as etapas no artigo de Monitorização de Consultas para monitorizar o efeito da distorção no desempenho das consultas. Especificamente, procure saber quanto tempo demoram as consultas grandes a concluir em distribuições individuais.
Como não é possível alterar as colunas de distribuição em uma tabela existente, a maneira típica de resolver distorção de dados é recriar a tabela com colunas de distribuição diferentes.
Recriar a tabela com um novo conjunto de colunas de distribuição
Este exemplo usa CREATE TABLE AS SELECT para recriar uma tabela com diferentes colunas de distribuição de hash.
Primeiro, use CREATE TABLE AS SELECT (CTAS) a nova tabela com a nova chave. Em seguida, recrie as estatísticas e, finalmente, troque as tabelas renomeando-as.
CREATE TABLE [dbo].[FactInternetSales_CustomerKey]
WITH ( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([CustomerKey])
, PARTITION ( [OrderDateKey] RANGE RIGHT FOR VALUES ( 20000101, 20010101, 20020101, 20030101
, 20040101, 20050101, 20060101, 20070101
, 20080101, 20090101, 20100101, 20110101
, 20120101, 20130101, 20140101, 20150101
, 20160101, 20170101, 20180101, 20190101
, 20200101, 20210101, 20220101, 20230101
, 20240101, 20250101, 20260101, 20270101
, 20280101, 20290101
)
)
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
OPTION (LABEL = 'CTAS : FactInternetSales_CustomerKey')
;
--Create statistics on new table
CREATE STATISTICS [ProductKey] ON [FactInternetSales_CustomerKey] ([ProductKey]);
CREATE STATISTICS [OrderDateKey] ON [FactInternetSales_CustomerKey] ([OrderDateKey]);
CREATE STATISTICS [CustomerKey] ON [FactInternetSales_CustomerKey] ([CustomerKey]);
CREATE STATISTICS [PromotionKey] ON [FactInternetSales_CustomerKey] ([PromotionKey]);
CREATE STATISTICS [SalesOrderNumber] ON [FactInternetSales_CustomerKey] ([SalesOrderNumber]);
CREATE STATISTICS [OrderQuantity] ON [FactInternetSales_CustomerKey] ([OrderQuantity]);
CREATE STATISTICS [UnitPrice] ON [FactInternetSales_CustomerKey] ([UnitPrice]);
CREATE STATISTICS [SalesAmount] ON [FactInternetSales_CustomerKey] ([SalesAmount]);
--Rename the tables
RENAME OBJECT [dbo].[FactInternetSales] TO [FactInternetSales_ProductKey];
RENAME OBJECT [dbo].[FactInternetSales_CustomerKey] TO [FactInternetSales];
Conteúdos relacionados
Para criar uma tabela distribuída, use uma destas instruções: