Diretrizes de design para usar tabelas replicadas no pool SQL Synapse
Este artigo fornece recomendações para criar tabelas replicadas em seu esquema de pool SQL Synapse. Use essas recomendações para melhorar o desempenho da consulta, reduzindo a movimentação de dados e a complexidade da consulta.
Pré-requisitos
Este artigo pressupõe que você esteja familiarizado com os conceitos de distribuição e movimentação de dados no pool SQL. Para obter mais informações, consulte o artigo sobre arquitetura .
Como parte do design da tabela, entenda o máximo possível sobre seus dados e como eles são consultados. Por exemplo, considere estas perguntas:
- Qual é o tamanho da mesa?
- Com que frequência a tabela é atualizada?
- Tenho tabelas de fatos e dimensões em um pool SQL?
O que é uma tabela replicada?
Uma tabela replicada tem uma cópia completa da tabela acessível em cada nó de computação. A replicação de uma tabela elimina a necessidade de transferir dados entre nós de Computação antes de se proceder a uma associação ou agregação. Como a tabela tem várias cópias, as tabelas replicadas funcionam melhor quando o tamanho da tabela é inferior a 2 GB compactado. 2 GB não é um limite rígido. Se os dados forem estáticos e não forem alterados, você poderá replicar tabelas maiores.
O diagrama a seguir mostra uma tabela replicada que é acessível em cada nó de computação. No pool SQL, a tabela replicada é totalmente copiada para um banco de dados de distribuição em cada nó de computação.

As tabelas replicadas funcionam bem para tabelas de dimensão em um esquema em estrela. As tabelas de dimensão são normalmente unidas a tabelas de factos, que são distribuídas de forma diferente da tabela de dimensões. As dimensões são geralmente de um tamanho que torna viável armazenar e manter várias cópias. As dimensões armazenam dados descritivos que mudam lentamente, como nome e endereço do cliente e detalhes do produto. A natureza lentamente variável dos dados leva a menos manutenção da tabela replicada.
Considere o uso de uma tabela replicada quando:
- O tamanho da tabela no disco é inferior a 2 GB, independentemente do número de linhas. Para encontrar o tamanho de uma tabela, você pode usar o comando DBCC PDW_SHOWSPACEUSED :
DBCC PDW_SHOWSPACEUSED('ReplTableCandidate'). - A tabela é usada em junções que, de outra forma, exigiriam movimentação de dados. Ao associar as tabelas que não estão distribuídas na mesma coluna, como uma tabela distribuída com hash para uma tabela round robin, será necessário o movimento de dados para concluir a consulta. Se uma das tabelas for pequena, considere uma tabela replicada. Na maioria dos casos, recomendamos o uso de tabelas replicadas em vez de tabelas round-robin. Para exibir operações de movimentação de dados em planos de consulta, use sys.dm_pdw_request_steps. O BroadcastMoveOperation é a operação típica de movimentação de dados que pode ser eliminada usando uma tabela replicada.
As tabelas replicadas podem não produzir o melhor desempenho de consulta quando:
- A tabela tem operações frequentes de inserção, atualização e exclusão. As operações de linguagem de manipulação de dados (DML) exigem uma reconstrução da tabela replicada. A reconstrução frequente pode causar um desempenho mais lento.
- O pool SQL é dimensionado com freqüência. O dimensionamento de um pool SQL altera o número de nós de computação, o que incorre na reconstrução da tabela replicada.
- A tabela tem um grande número de colunas, mas as operações de dados normalmente acessam apenas um pequeno número de colunas. Nesse cenário, em vez de replicar a tabela inteira, pode ser mais eficaz distribuir a tabela e, em seguida, criar um índice nas colunas acessadas com freqüência. Quando uma consulta requer movimentação de dados, o pool SQL move apenas dados para as colunas solicitadas.
Gorjeta
Para obter mais orientações sobre indexação e tabelas replicadas, consulte Cheat sheet for dedicated SQL pool (anteriormente SQL DW) no Azure Synapse Analytics.
Usar tabelas replicadas com predicados de consulta simples
Antes de optar por distribuir ou replicar uma tabela, pense nos tipos de consultas que você planeja executar na tabela. Sempre que possível,
- Use tabelas replicadas para consultas com predicados de consulta simples, como igualdade ou desigualdade.
- Use tabelas distribuídas para consultas com predicados de consulta complexos, como LIKE ou NOT LIKE.
As consultas com uso intensivo de CPU têm melhor desempenho quando o trabalho é distribuído em todos os nós de computação. Por exemplo, consultas que executam cálculos em cada linha de uma tabela têm melhor desempenho em tabelas distribuídas do que tabelas replicadas. Como uma tabela replicada é armazenada na íntegra em cada nó de computação, uma consulta com uso intensivo de CPU em relação a uma tabela replicada é executada em relação à tabela inteira em cada nó de computação. A computação extra pode diminuir o desempenho da consulta.
Por exemplo, esta consulta tem um predicado complexo. Ele é executado mais rapidamente quando os dados estão em uma tabela distribuída em vez de uma tabela replicada. Neste exemplo, os dados podem ser distribuídos round-robin.
SELECT EnglishProductName
FROM DimProduct
WHERE EnglishDescription LIKE '%frame%comfortable%';
Converter tabelas round-robin existentes em tabelas replicadas
Se você já tiver tabelas round-robin, recomendamos convertê-las em tabelas replicadas se atenderem aos critérios descritos neste artigo. As tabelas replicadas melhoram o desempenho em relação às tabelas round-robin porque eliminam a necessidade de movimentação de dados. Uma tabela round-robin sempre requer movimentação de dados para junções.
Este exemplo usa CTAS para alterar a DimSalesTerritory tabela para uma tabela replicada. Este exemplo funciona independentemente de ser DimSalesTerritory distribuído por hash ou round-robin.
CREATE TABLE [dbo].[DimSalesTerritory_REPLICATE]
WITH
(
HEAP,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory]
OPTION (LABEL = 'CTAS : DimSalesTerritory_REPLICATE')
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[DimSalesTerritory_REPLICATE] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
Exemplo de desempenho de consulta para round-robin versus replicado
Uma tabela replicada não requer nenhum movimento de dados para junções porque a tabela inteira já está presente em cada nó de computação. Se as tabelas de dimensão forem distribuídas round-robin, uma junção copiará a tabela de dimensão na íntegra para cada nó de computação. Para mover os dados, o plano de consulta contém uma operação chamada BroadcastMoveOperation. Esse tipo de operação de movimentação de dados diminui o desempenho da consulta e é eliminado usando tabelas replicadas. Para exibir as etapas do plano de consulta, use a exibição sys.dm_pdw_request_steps catálogo do sistema.
Por exemplo, ao seguir a AdventureWorks consulta no esquema, a tabela é distribuída FactInternetSales por hash. As DimDate tabelas e DimSalesTerritory são tabelas de dimensões menores. Esta consulta retorna o total de vendas na América do Norte para o ano fiscal de 2004:
SELECT [TotalSalesAmount] = SUM(SalesAmount)
FROM dbo.FactInternetSales s
INNER JOIN dbo.DimDate d
ON d.DateKey = s.OrderDateKey
INNER JOIN dbo.DimSalesTerritory t
ON t.SalesTerritoryKey = s.SalesTerritoryKey
WHERE d.FiscalYear = 2004
AND t.SalesTerritoryGroup = 'North America'
Recriámos DimDate e DimSalesTerritory como mesas redondas. Como resultado, a consulta mostrou o seguinte plano de consulta, que tem várias operações de movimentação de difusão:
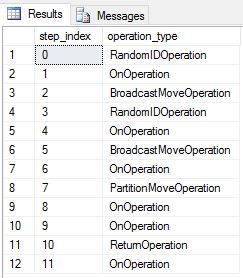
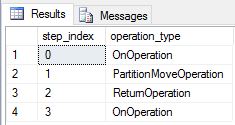
Recriamos DimDate e DimSalesTerritory como tabelas replicadas e executamos a consulta novamente. O plano de consulta resultante é muito mais curto e não tem nenhum movimento de transmissão.
Considerações de desempenho para modificar tabelas replicadas
O pool SQL implementa uma tabela replicada mantendo uma versão mestre da tabela. Ele copia a versão mestre para o primeiro banco de dados de distribuição em cada nó de computação. Quando há uma alteração, a versão mestre é atualizada primeiro e, em seguida, as tabelas em cada nó de computação são reconstruídas. Uma reconstrução de uma tabela replicada inclui copiar a tabela para cada nó de computação e, em seguida, criar os índices. Por exemplo, uma tabela replicada em um DW2000c tem cinco cópias dos dados. Uma cópia mestre e uma cópia completa em cada nó de computação. Todos os dados são armazenados em bancos de dados de distribuição. O pool SQL usa esse modelo para oferecer suporte a instruções de modificação de dados mais rápidas e operações de dimensionamento flexíveis.
As reconstruções assíncronas são acionadas pela primeira consulta na tabela replicada após:
- Os dados são carregados ou modificados
- A instância Synapse SQL é dimensionada para um nível diferente
- A definição da tabela é atualizada
As reconstruções não são necessárias após:
- Pausar operação
- Retomar a operação
A reconstrução não acontece imediatamente após a modificação dos dados. Em vez disso, a reconstrução é acionada na primeira vez que uma consulta é selecionada na tabela. A consulta que disparou a reconstrução é lida imediatamente da versão mestra da tabela enquanto os dados são copiados de forma assíncrona para cada nó de computação. Até que a cópia de dados seja concluída, as consultas subsequentes continuarão a usar a versão mestre da tabela. Se alguma atividade acontecer na tabela replicada que forçar outra reconstrução, a cópia de dados será invalidada e a próxima instrução select acionará os dados a serem copiados novamente.
Use os índices de forma conservadora
As práticas de indexação padrão aplicam-se a tabelas replicadas. O pool SQL recria cada índice de tabela replicado como parte da reconstrução. Use índices apenas quando o ganho de desempenho superar o custo de reconstrução dos índices.
Carga de dados em lote
Ao carregar dados em tabelas replicadas, tente minimizar as reconstruções agrupando cargas em lote. Execute todas as cargas em lote antes de executar instruções select.
Por exemplo, esse padrão de carga carrega dados de quatro fontes e invoca quatro reconstruções.
- Carregar a partir da fonte 1.
- Selecione a instrução triggers rebuild 1.
- Carregue a partir da fonte 2.
- Selecione a instrução triggers rebuild 2.
- Carregar a partir da fonte 3.
- Selecione a instrução triggers rebuild 3.
- Carregue a partir da fonte 4.
- Selecione a instrução triggers rebuild 4.
Por exemplo, esse padrão de carregamento carrega dados de quatro fontes, mas invoca apenas uma reconstrução.
- Carregar a partir da fonte 1.
- Carregue a partir da fonte 2.
- Carregar a partir da fonte 3.
- Carregue a partir da fonte 4.
- Selecione a instrução aciona a reconstrução.
Reconstruir uma tabela replicada após um carregamento em lote
Para garantir tempos de execução de consulta consistentes, considere forçar a compilação das tabelas replicadas após um carregamento em lote. Caso contrário, a primeira consulta ainda usará a movimentação de dados para concluir a consulta.
A operação “Criar Cache de Tabela Replicada” pode executar até duas operações simultaneamente. Por exemplo, se você tentar reconstruir o cache para cinco tabelas, o sistema utilizará uma staticrc20 (que não pode ser modificada) para construir simultaneamente duas tabelas no momento. Assim, é recomendado evitar a utilização de tabelas replicadas grandes que excedam 2 GB, pois isso pode abrandar a recriação da cache nos nós e aumentar o tempo total.
Essa consulta usa o sys.pdw_replicated_table_cache_state DMV para listar as tabelas replicadas que foram modificadas, mas não recriadas.
SELECT SchemaName = SCHEMA_NAME(t.schema_id)
, [ReplicatedTable] = t.[name]
, [RebuildStatement] = 'SELECT TOP 1 * FROM ' + '[' + SCHEMA_NAME(t.schema_id) + '].[' + t.[name] +']'
FROM sys.tables t
JOIN sys.pdw_replicated_table_cache_state c
ON c.object_id = t.object_id
JOIN sys.pdw_table_distribution_properties p
ON p.object_id = t.object_id
WHERE c.[state] = 'NotReady'
AND p.[distribution_policy_desc] = 'REPLICATE'
Para acionar uma reconstrução, execute a seguinte instrução em cada tabela na saída anterior.
SELECT TOP 1 * FROM [ReplicatedTable]
Nota
Se você estiver planejando reconstruir as estatísticas da tabela replicada não armazenada em cache, atualize as estatísticas antes de acionar o cache. A atualização das estatísticas invalidará o cache, por isso a sequência é importante.
Exemplo: Comece com UPDATE STATISTICSe, em seguida, acione a reconstrução do cache. Nos exemplos a seguir, o exemplo correto atualiza as estatísticas e dispara a reconstrução do cache.
-- Incorrect sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
SELECT TOP 1 * FROM [ReplicatedTable]
UPDATE STATISTICS [ReplicatedTable]
END
-- Correct sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
UPDATE STATISTICS [ReplicatedTable]
SELECT TOP 1 * FROM [ReplicatedTable]
END
Para monitorar o processo de reconstrução, você pode usar sys.dm_pdw_exec_requests, onde o command começará com 'BuildReplicatedTableCache'. Por exemplo:
-- Monitor Build Replicated Cache
SELECT *
FROM sys.dm_pdw_exec_requests
WHERE command like 'BuildReplicatedTableCache%'
Gorjeta
As consultas de tamanho de tabela podem ser usadas para verificar quais tabelas têm uma política de distribuição replicada e quais são maiores que 2 GB.
Próximos passos
Para criar uma tabela replicada, use uma destas instruções:
Para obter uma visão geral das tabelas distribuídas, consulte tabelas distribuídas.