Migrando o Time Series Insights Gen2 para o Real-Time Intelligence no Microsoft Fabric
Nota
O serviço Time Series Insights será desativado em 7 de julho de 2024. Considere migrar os ambientes existentes para soluções alternativas o mais rápido possível. Para obter mais informações sobre a substituição e migração, visite nossa documentação.
Descrição geral
Eventhouse é a base de dados de séries temporais em Real-Time Intelligence. Ele serve como destino para migrar dados do Time Series Insights.
Recomendações de migração de alto nível.
| Caraterística | Migração recomendada |
|---|---|
| Ingerir JSON do Hub com achatamento e fuga | Obter dados dos Hubs de Eventos do Azure |
| Abrir câmara frigorífica | Disponibilidade do Eventhouse OneLake |
| Conector do Power BI | Use o Eventhouse Power BI Connector. Reescreva o TSQ no KQL manualmente. |
| Apache Spark Connector | Migre dados para o Eventhouse. Use um bloco de anotações com o Apache Spark para consultar uma Eventhouse ou Explore os dados em sua casa do lago com um bloco de anotações |
| Carregamento em Massa | Obter dados do armazenamento do Azure |
| Modelo de Série de Tempo | Pode ser exportado como arquivo JSON. Pode ser importado para a Eventhouse. Kusto Graph Semantics permite modelar, percorrer e analisar a hierarquia de modelos de séries temporais como um gráfico |
| Explorador de Séries Temporais | Painel em tempo real, relatório do Power BI ou escrever um painel personalizado usando KustoTrender |
| Linguagem da consulta | Reescreva consultas no KQL. |
Migrando telemetria
Para recuperar a cópia de todos os dados no ambiente, use PT=Time a pasta na conta de armazenamento. Para obter mais informações, consulte Armazenamento de dados.
Etapa de migração 1 – Obter estatísticas sobre dados de telemetria
Dados
- Visão geral do Env
- ID do ambiente de registro da primeira parte do FQDN de acesso a dados (por exemplo, d390b0b0-1445-4c0c-8365-68d6382c1c2a de .env.crystal-dev.windows-int.net)
- Visão geral do Env -> Configuração de armazenamento -> Conta de armazenamento
- Use o Gerenciador de Armazenamento para obter estatísticas de pastas
- Tamanho do registro e o número de blobs da
PT=Timepasta.
- Tamanho do registro e o número de blobs da
Etapa de migração 2 – Migrar dados para o Eventhouse
Criar uma casa de eventos
Para configurar um Eventhouse para seu processo de migração, siga as etapas na criação de um Eventhouse.
Ingestion de Dados
Para recuperar dados para a conta de armazenamento correspondente à sua instância do Time Series Insights, siga as etapas em Obter dados do Armazenamento do Azure.
Certifique-se de que:
Selecione o contêiner apropriado e forneça seu URI, juntamente com o token SAS ou a chave de conta necessários.
Configure o caminho da pasta de filtros de arquivo para
V=1/PT=Timefiltrar os blobs relevantes.Verifique o esquema inferido e remova todas as colunas consultadas com pouca frequência, mantendo pelo menos o carimbo de data/hora, as colunas TSID e os valores. Para garantir que todos os seus dados sejam copiados para o Eventhouse, adicione outra coluna e use a transformação de mapeamento DropMappedFields .
Conclua o processo de ingestão.
Consultando os dados
Agora que você ingeriu os dados com sucesso, pode começar a explorá-los usando um conjunto de consultas KQL. Se você precisar acessar os dados de seu aplicativo cliente personalizado, o Eventhouse fornece SDKs para as principais linguagens de programação, como C# (link), Java (link) e Node.js (link).
Migrando o modelo de série temporal para o Azure Data Explorer
O modelo pode ser baixado em formato JSON do Ambiente TSI usando o TSI Explorer UX ou TSM Batch API. Em seguida, o modelo pode ser importado para a Eventhouse.
Faça o download do TSM da TSI UX.
Exclua as três primeiras linhas usando o Visual Studio Code ou outro editor.
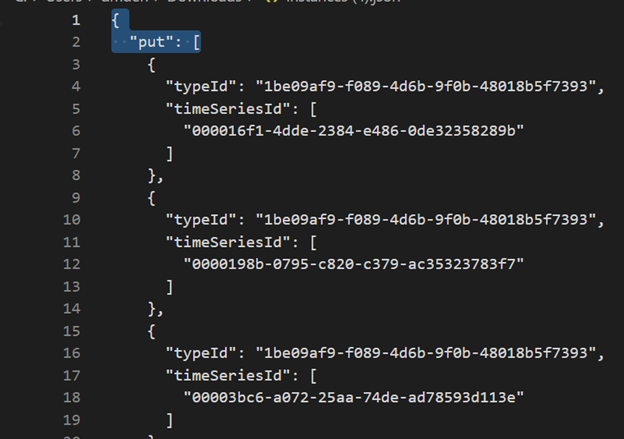
Usando o Visual Studio Code ou outro editor, pesquise e substitua como regex
\},\n \{por}{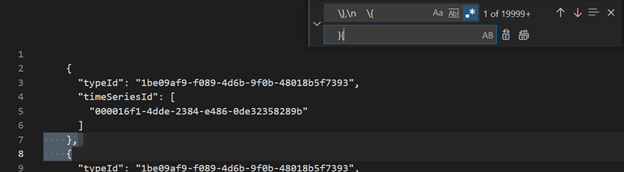
Ingerir como JSON no ADX como uma tabela separada usando Obter dados de um único arquivo.


Depois de migrar seus dados de séries temporais para o Eventhouse in Fabric Real-Time Intelligence, você pode usar o poder da Kusto Graph Semantics para contextualizar e analisar seus dados. Kusto Graph Semantics permite modelar, percorrer e analisar a hierarquia do seu Modelo de Série Temporal como um gráfico. Usando a Semântica do Kusto Graph, você pode obter informações sobre as relações entre diferentes entidades em seus dados de séries temporais, como ativos, sites e pontos de dados. Esses insights ajudam você a entender as dependências e interações entre vários componentes do seu sistema.
Traduzir Consultas de Série Temporal (TSQ) para KQL
GetEvents
{
"getEvents": {
"timeSeriesId": [
"assest1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"inlineVariables": {},
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where assetId_string == "assest1" and siteId_string == "siteId1" and dataid_string == "dataId1"
| take 10000
GetEvents com filtro
{
"getEvents": {
"timeSeriesId": [
"deviceId1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"filter": {
"tsx": "$event.sensors.sensor.String = 'status' AND $event.sensors.unit.String = 'ONLINE"
}
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where deviceId_string== "deviceId1" and siteId_string == "siteId1" and dataId_string == "dataId1"
| where ['sensors.sensor_string'] == "status" and ['sensors.unit_string'] == "ONLINE"
| take 10000
GetEvents com variável projetada
{
"getEvents": {
"timeSeriesId": [
"deviceId1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"inlineVariables": {},
"projectedVariables": [],
"projectedProperties": [
{
"name": "sensors.value",
"type": "String"
},
{
"name": "sensors.value",
"type": "bool"
},
{
"name": "sensors.value",
"type": "Double"
}
]
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where deviceId_string== "deviceId1" and siteId_string == "siteId1" and dataId_string == "dataId1"
| take 10000
| project timestamp, sensorStringValue= ['sensors.value_string'], sensorBoolValue= ['sensors.value_bool'], sensorDoublelValue= ['sensors.value_double']
Série Agregada
{
"aggregateSeries": {
"timeSeriesId": [
"deviceId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:00.0000000Z",
"to": "2021-11-05T00:00:00.0000000Z"
},
"interval": "PT1M",
"inlineVariables": {
"sensor": {
"kind": "numeric",
"value": {
"tsx": "coalesce($event.sensors.value.Double, todouble($event.sensors.value.Long))"
},
"aggregation": {
"tsx": "avg($value)"
}
}
},
"projectedVariables": [
"sensor"
]
}
events
| where timestamp >= datetime(2021-11-01T00:00:00.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.0000000Z)
| where deviceId_string == "deviceId1"
| summarize avgSensorValue= avg(coalesce(['sensors.value_double'], todouble(['sensors.value_long']))) by bin(IntervalTs = timestamp, 1m)
| project IntervalTs, avgSensorValue
AggregateSeries com filtro
{
"aggregateSeries": {
"timeSeriesId": [
"deviceId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:00.0000000Z",
"to": "2021-11-05T00:00:00.0000000Z"
},
"filter": {
"tsx": "$event.sensors.sensor.String = 'heater' AND $event.sensors.location.String = 'floor1room12'"
},
"interval": "PT1M",
"inlineVariables": {
"sensor": {
"kind": "numeric",
"value": {
"tsx": "coalesce($event.sensors.value.Double, todouble($event.sensors.value.Long))"
},
"aggregation": {
"tsx": "avg($value)"
}
}
},
"projectedVariables": [
"sensor"
]
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:00.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.0000000Z)
| where deviceId_string == "deviceId1"
| where ['sensors.sensor_string'] == "heater" and ['sensors.location_string'] == "floor1room12"
| summarize avgSensorValue= avg(coalesce(['sensors.value_double'], todouble(['sensors.value_long']))) by bin(IntervalTs = timestamp, 1m)
| project IntervalTs, avgSensorValue
Power BI
Não há nenhum processo automatizado para migrar relatórios do Power BI baseados em Insights de Série Temporal. Todas as consultas que dependem de dados armazenados no Time Series Insights devem ser migradas para o Eventhouse.
Para criar relatórios de séries cronológicas eficientes no Power BI, recomendamos consultar os seguintes artigos informativos do blog:
- Recursos de séries cronológicas da Eventhouse no Power BI
- Como usar parâmetros dinâmicos M sem a maioria das limitações
- Valores de tempo/duração no KQL, Power Query e Power BI
- Configurações de consulta KQL no Power BI
- Filtragem e visualização de dados Kusto no horário local
- Relatórios quase em tempo real no PBI + Kusto
- Modelagem do Power BI com ADX - cheat sheet
Consulte estes recursos para obter orientações sobre como criar relatórios de séries cronológicas eficazes no Power BI.
Painel em Tempo Real
Um Painel em Tempo Real no Fabric é uma coleção de blocos, opcionalmente organizados em páginas, onde cada bloco tem uma consulta subjacente e uma representação visual. Você pode exportar nativamente consultas KQL (Kusto Query Language) para um painel como elementos visuais e, posteriormente, modificar suas consultas subjacentes e formatação visual, conforme necessário. Além da facilidade de exploração de dados, essa experiência de painel totalmente integrada oferece melhor desempenho de consulta e visualização.
Comece criando um novo painel no Fabric Real-Time Intelligence. Este poderoso recurso permite explorar dados, personalizar elementos visuais, aplicar formatação condicional e utilizar parâmetros. Além disso, pode criar alertas diretamente a partir dos seus Dashboards em Tempo Real, melhorando as suas capacidades de monitorização. Para obter instruções detalhadas sobre como criar um painel, consulte a documentação oficial.