Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Neste tutorial, você cria um aplicativo MSTest para avaliar a resposta de bate-papo de um modelo OpenAI. A aplicação de teste usa o Microsoft. Extensions.AI.Evaluation bibliotecas para realizar as avaliações, armazenar em cache as respostas do modelo e criar relatórios. O tutorial usa avaliadores internos e personalizados. Os avaliadores de qualidade incorporados (do Microsoft. Extensions.AI.Evaluation.Quality package) utilizam um LLM para realizar avaliações; o avaliador personalizado não usa IA.
Pré-requisitos
- .NET 8 ou uma versão posterior
- Visual Studio Code (opcional)
Configurar o serviço de IA
Para provisionar um Azure OpenAI service e modelar usando o portal Azure, complete os passos no artigo Criar e implementar um recurso Azure OpenAI Service. Na etapa "Implantar um modelo", selecione o modelo gpt-5.
Criar o aplicativo de teste
Complete os passos seguintes para criar um projeto MSTest que se ligue a um modelo de IA.
Em uma janela de terminal, navegue até o diretório onde você deseja criar seu aplicativo e crie um novo aplicativo MSTest com o
dotnet newcomando:dotnet new mstest -o TestAIWithReportingNavegue até o diretório
TestAIWithReportinge adicione os pacotes necessários ao seu aplicativo:dotnet add package Azure.AI.OpenAI dotnet add package Azure.Identity dotnet add package Microsoft.Extensions.AI.Abstractions dotnet add package Microsoft.Extensions.AI.Evaluation dotnet add package Microsoft.Extensions.AI.Evaluation.Quality dotnet add package Microsoft.Extensions.AI.Evaluation.Reporting dotnet add package Microsoft.Extensions.AI.OpenAI dotnet add package Microsoft.Extensions.Configuration dotnet add package Microsoft.Extensions.Configuration.UserSecretsExecute os seguintes comandos para adicionar app secrets para o seu endpoint do Azure OpenAI e ID de locatário:
dotnet user-secrets init dotnet user-secrets set AZURE_OPENAI_ENDPOINT <your-Azure-OpenAI-endpoint> dotnet user-secrets set AZURE_TENANT_ID <your-tenant-ID>(Dependendo do seu ambiente, o ID do locatário pode não ser necessário. Nesse caso, remova-o do código que instancia o DefaultAzureCredential.)
Abra o novo aplicativo no editor de sua escolha.
Adicionar o código do aplicativo de teste
Renomeie o arquivo Test1.cs para MyTests.cs e, em seguida, abra o arquivo e renomeie a classe para
MyTests. Exclua o método vazioTestMethod1.Adicione as diretivas necessárias
usingà parte superior do arquivo.using Azure.AI.OpenAI; using Azure.Identity; using Microsoft.Extensions.AI.Evaluation; using Microsoft.Extensions.AI; using Microsoft.Extensions.Configuration; using Microsoft.Extensions.AI.Evaluation.Reporting.Storage; using Microsoft.Extensions.AI.Evaluation.Reporting; using Microsoft.Extensions.AI.Evaluation.Quality;Adicione a propriedade TestContext à classe.
// The value of the TestContext property is populated by MSTest. public TestContext? TestContext { get; set; }Adicione o
GetAzureOpenAIChatConfigurationmétodo, que cria o IChatClient que o avaliador usa para se comunicar com o modelo.private static ChatConfiguration GetAzureOpenAIChatConfiguration() { IConfigurationRoot config = new ConfigurationBuilder().AddUserSecrets<MyTests>().Build(); string endpoint = config["AZURE_OPENAI_ENDPOINT"]; string tenantId = config["AZURE_TENANT_ID"]; string model = "gpt-5"; // Get an instance of Microsoft.Extensions.AI's <see cref="IChatClient"/> // interface for the selected LLM endpoint. AzureOpenAIClient azureClient = new( new Uri(endpoint), new DefaultAzureCredential(new DefaultAzureCredentialOptions() { TenantId = tenantId })); IChatClient client = azureClient.GetChatClient(deploymentName: model).AsIChatClient(); // Create an instance of <see cref="ChatConfiguration"/> // to communicate with the LLM. return new ChatConfiguration(client); }Configure a funcionalidade de relatório.
private string ScenarioName => $"{TestContext!.FullyQualifiedTestClassName}.{TestContext.TestName}"; private static string ExecutionName => $"{DateTime.Now:yyyyMMddTHHmmss}"; private static readonly ReportingConfiguration s_defaultReportingConfiguration = DiskBasedReportingConfiguration.Create( storageRootPath: "C:\\TestReports", evaluators: GetEvaluators(), chatConfiguration: GetAzureOpenAIChatConfiguration(), enableResponseCaching: true, executionName: ExecutionName);Nome do cenário
O nome do cenário é definido como o nome totalmente qualificado do método de teste atual. No entanto, pode defini-la para qualquer string quando chamar CreateScenarioRunAsync(String, String, IEnumerable<String>, IEnumerable<String>, CancellationToken). Considere estes fatores ao escolher o nome de um cenário:
- Ao usar o armazenamento baseado em disco, o nome do cenário é usado como o nome da pasta na qual os resultados da avaliação correspondente são armazenados. Portanto, é uma boa ideia manter o nome razoavelmente curto e evitar caracteres que não são permitidos em nomes de arquivos e diretórios.
- Por defeito, o relatório de avaliação gerado divide os nomes dos cenários em
., de forma que os resultados sejam exibidos numa visão hierárquica com agrupamento, aninhamento e agregação apropriados. A visão hierárquica é especialmente útil quando o nome do cenário é o nome totalmente qualificado do método de teste correspondente, porque agrupa os resultados por namespaces e nomes de classes na hierarquia. No entanto, você também pode aproveitar esse recurso incluindo pontos (.) em seus próprios nomes de cenário personalizados para criar uma hierarquia de relatórios que funcione melhor para seus cenários.
Nome da execução
O nome de execução é usado para agrupar os resultados da avaliação que fazem parte da mesma execução de avaliação (ou execução de teste) quando os resultados da avaliação são armazenados. Se não fornecer um nome de execução ao criar um ReportingConfiguration, todas as execuções de avaliação usam o mesmo nome de execução padrão de
Default. Neste caso, os resultados de uma sequência são sobrescritos pela seguinte, e perde-se a capacidade de comparar resultados entre diferentes sequências.Este exemplo usa um timestamp como nome de execução. Se você tiver mais de um teste em seu projeto, certifique-se de que os resultados sejam agrupados corretamente usando o mesmo nome de execução em todas as configurações de relatório usadas nos testes.
Em um cenário mais real, você também pode querer compartilhar o mesmo nome de execução entre testes de avaliação que vivem em vários assemblies diferentes e que são executados em processos de teste diferentes. Nesses casos, você pode usar um script para atualizar uma variável de ambiente com um nome de execução apropriado (como o número de compilação atual atribuído pelo seu sistema CI/CD) antes de executar os testes. Ou, se o seu sistema de compilação produzir versões de ficheiros de assemblagem monotonicamente crescentes, poderá ler o AssemblyFileVersionAttribute dentro do código de teste e usá-lo como nome de execução para comparar os resultados entre diferentes versões do produto.
Configuração de relatórios
A ReportingConfiguration identifica:
- O conjunto de avaliadores que devem ser invocados para cada ScenarioRun criado ao chamar CreateScenarioRunAsync(String, String, IEnumerable<String>, IEnumerable<String>, CancellationToken).
- O endpoint LLM que os avaliadores devem utilizar (ver ReportingConfiguration.ChatConfiguration).
- Como e onde os resultados das execuções do cenário devem ser armazenados.
- A forma como as respostas LLM relacionadas ao cenário são executadas deve ser armazenada em cache.
- O nome de execução que deve ser usado quando relatar resultados para as execuções de cenários.
Este teste usa uma configuração de relatório baseada em disco.
Em um arquivo separado, adicione classe
WordCountEvaluator, que é um avaliador personalizado que implementa IEvaluator.using System.Text.RegularExpressions; using Microsoft.Extensions.AI; using Microsoft.Extensions.AI.Evaluation; namespace TestAIWithReporting; public class WordCountEvaluator : IEvaluator { public const string WordCountMetricName = "Words"; public IReadOnlyCollection<string> EvaluationMetricNames => [WordCountMetricName]; /// <summary> /// Counts the number of words in the supplied string. /// </summary> private static int CountWords(string? input) { if (string.IsNullOrWhiteSpace(input)) { return 0; } MatchCollection matches = Regex.Matches(input, @"\b\w+\b"); return matches.Count; } /// <summary> /// Provides a default interpretation for the supplied <paramref name="metric"/>. /// </summary> private static void Interpret(NumericMetric metric) { if (metric.Value is null) { metric.Interpretation = new EvaluationMetricInterpretation( EvaluationRating.Unknown, failed: true, reason: "Failed to calculate word count for the response."); } else { if (metric.Value <= 100 && metric.Value > 5) metric.Interpretation = new EvaluationMetricInterpretation( EvaluationRating.Good, reason: "The response was between 6 and 100 words."); else metric.Interpretation = new EvaluationMetricInterpretation( EvaluationRating.Unacceptable, failed: true, reason: "The response was either too short or greater than 100 words."); } } public ValueTask<EvaluationResult> EvaluateAsync( IEnumerable<ChatMessage> messages, ChatResponse modelResponse, ChatConfiguration? chatConfiguration = null, IEnumerable<EvaluationContext>? additionalContext = null, CancellationToken cancellationToken = default) { // Count the number of words in the supplied <see cref="modelResponse"/>. int wordCount = CountWords(modelResponse.Text); string reason = $"This {WordCountMetricName} metric has a value of {wordCount} because " + $"the evaluated model response contained {wordCount} words."; // Create a <see cref="NumericMetric"/> with value set to the word count. // Include a reason that explains the score. var metric = new NumericMetric(WordCountMetricName, value: wordCount, reason); // Attach a default <see cref="EvaluationMetricInterpretation"/> for the metric. Interpret(metric); return new ValueTask<EvaluationResult>(new EvaluationResult(metric)); } }A
WordCountEvaluatorconta o número de palavras presentes na resposta. Ao contrário de alguns avaliadores, não se baseia em IA. OEvaluateAsyncmétodo devolve um EvaluationResult que inclui um NumericMetric que contém a contagem de palavras.O
EvaluateAsyncmétodo também anexa uma interpretação padrão à métrica. A interpretação padrão considera a métrica boa (aceitável) se a contagem de palavras detetada estiver entre 6 e 100. Caso contrário, a métrica é considerada falha. O chamador pode sobrepor esta interpretação padrão, se necessário.De volta ao
MyTests.cs, adicione um método para reunir os avaliadores para usar na avaliação.private static IEnumerable<IEvaluator> GetEvaluators() { IEvaluator relevanceEvaluator = new RelevanceEvaluator(); IEvaluator coherenceEvaluator = new CoherenceEvaluator(); IEvaluator wordCountEvaluator = new WordCountEvaluator(); return [relevanceEvaluator, coherenceEvaluator, wordCountEvaluator]; }Adicione um método para adicionar um prompt ChatMessagedo sistema, defina as opções de bate-papo e peça ao modelo uma resposta a uma determinada pergunta.
private static async Task<(IList<ChatMessage> Messages, ChatResponse ModelResponse)> GetAstronomyConversationAsync( IChatClient chatClient, string astronomyQuestion) { const string SystemPrompt = """ You're an AI assistant that can answer questions related to astronomy. Keep your responses concise and under 100 words. Use the imperial measurement system for all measurements in your response. """; IList<ChatMessage> messages = [ new ChatMessage(ChatRole.System, SystemPrompt), new ChatMessage(ChatRole.User, astronomyQuestion) ]; var chatOptions = new ChatOptions { Temperature = 0.0f, ResponseFormat = ChatResponseFormat.Text }; ChatResponse response = await chatClient.GetResponseAsync(messages, chatOptions); return (messages, response); }O teste neste tutorial avalia a resposta do LLM a uma pergunta de astronomia. Como o ReportingConfiguration tem a cache de resposta ativada, e porque o IChatClient fornecido é sempre obtido do ScenarioRun criado usando esta configuração de relatório, a resposta do modelo LLM para o teste é armazenada em cache e reutilizada. A resposta é reutilizada até que a entrada correspondente da cache expire (em 14 dias por padrão), ou até que qualquer parâmetro de pedido, como o endpoint do LLM ou a pergunta colocada, mude.
Adicione um método para validar a resposta.
/// <summary> /// Runs basic validation on the supplied <see cref="EvaluationResult"/>. /// </summary> private static void Validate(EvaluationResult result) { // Retrieve the score for relevance from the <see cref="EvaluationResult"/>. NumericMetric relevance = result.Get<NumericMetric>(RelevanceEvaluator.RelevanceMetricName); Assert.IsFalse(relevance.Interpretation!.Failed, relevance.Reason); Assert.IsTrue(relevance.Interpretation.Rating is EvaluationRating.Good or EvaluationRating.Exceptional); // Retrieve the score for coherence from the <see cref="EvaluationResult"/>. NumericMetric coherence = result.Get<NumericMetric>(CoherenceEvaluator.CoherenceMetricName); Assert.IsFalse(coherence.Interpretation!.Failed, coherence.Reason); Assert.IsTrue(coherence.Interpretation.Rating is EvaluationRating.Good or EvaluationRating.Exceptional); // Retrieve the word count from the <see cref="EvaluationResult"/>. NumericMetric wordCount = result.Get<NumericMetric>(WordCountEvaluator.WordCountMetricName); Assert.IsFalse(wordCount.Interpretation!.Failed, wordCount.Reason); Assert.IsTrue(wordCount.Interpretation.Rating is EvaluationRating.Good or EvaluationRating.Exceptional); Assert.IsFalse(wordCount.ContainsDiagnostics()); Assert.IsTrue(wordCount.Value > 5 && wordCount.Value <= 100); }Sugestão
Cada métrica inclui uma propriedade
Reasonque explica o raciocínio da pontuação. O motivo está incluído no relatório gerado e pode ser visualizado clicando no ícone de informações no cartão da métrica correspondente.Finalmente, adicione o método de teste em si.
[TestMethod] public async Task SampleAndEvaluateResponse() { // Create a <see cref="ScenarioRun"/> with the scenario name // set to the fully qualified name of the current test method. await using ScenarioRun scenarioRun = await s_defaultReportingConfiguration.CreateScenarioRunAsync( ScenarioName, additionalTags: ["Moon"]); // Use the <see cref="IChatClient"/> that's included in the // <see cref="ScenarioRun.ChatConfiguration"/> to get the LLM response. (IList<ChatMessage> messages, ChatResponse modelResponse) = await GetAstronomyConversationAsync( chatClient: scenarioRun.ChatConfiguration!.ChatClient, astronomyQuestion: "How far is the Moon from the Earth at its closest and furthest points?"); // Run the evaluators configured in <see cref="s_defaultReportingConfiguration"/> against the response. EvaluationResult result = await scenarioRun.EvaluateAsync(messages, modelResponse); // Run some basic validation on the evaluation result. Validate(result); }Este método de ensaio:
Cria o ScenarioRun.
await usingAssegura a correta eliminação doScenarioRune a correta persistência dos resultados da avaliação para o repositório de resultados.Obtém a resposta do LLM a uma pergunta específica de astronomia. O teste passa o mesmo IChatClient que é utilizado na avaliação ao
GetAstronomyConversationAsyncmétodo a fim de obter cache de resposta para a resposta principal do LLM que está a ser avaliada. (Passar pelo mesmo cliente também permite a cache de respostas para os turnos LLM que os avaliadores usam para realizar as suas avaliações internamente.) Com a cache de respostas, a resposta do LLM é obtida ou:- Diretamente do ponto de extremidade do LLM na primeira execução do teste atual ou em execuções subsequentes, caso a entrada em cache tenha expirado (14 dias, por padrão).
- A partir da cache de respostas (baseada em disco) configurada
s_defaultReportingConfigurationem execuções subsequentes do teste.
Executa os módulos de avaliação contra a resposta. Tal como a resposta do LLM, as execuções subsequentes obtêm a avaliação a partir da cache de resposta (baseada em disco) configurada em
s_defaultReportingConfiguration.Executa alguma validação básica no resultado da avaliação.
Esta etapa é opcional e principalmente para fins de demonstração. Em avaliações do mundo real, pode não querer validar resultados individuais porque as respostas e pontuações dos LLMs podem mudar ao longo do tempo à medida que o seu produto (e os modelos utilizados) evoluem. Pode não querer que testes individuais de avaliação "falhem" e bloqueiem builds nos seus pipelines CI/CD quando os resultados mudam. Em vez disso, pode ser melhor confiar no relatório gerado e acompanhar as tendências gerais para pontuações de avaliação em diferentes cenários ao longo do tempo (e só falhar em compilações individuais quando há uma queda significativa nas pontuações de avaliação em vários testes diferentes). Dito isto, há algumas nuances aqui e a escolha de validar ou não resultados individuais pode variar dependendo do caso de uso específico.
Quando o método retorna, o objeto é descartado
scenarioRune o resultado da avaliação é armazenado no armazenamento de resultados (baseado em disco) configurado ems_defaultReportingConfiguration.
Executar o teste/avaliação
Execute o teste usando seu fluxo de trabalho de teste preferido, por exemplo, usando o comando dotnet test CLI ou através do Test Explorer.
Gerar um relatório
Instala o Microsoft. Extensions.AI.Evaluation.Console .NET ao executar o seguinte comando a partir de uma janela de terminal:
dotnet tool install --create-manifest-if-needed Microsoft.Extensions.AI.Evaluation.ConsoleGere um relatório executando o seguinte comando:
dotnet tool run aieval report --path <path\to\your\cache\storage> --output report.htmlAbra o ficheiro
report.html. O relatório assemelha-se à seguinte captura de ecrã.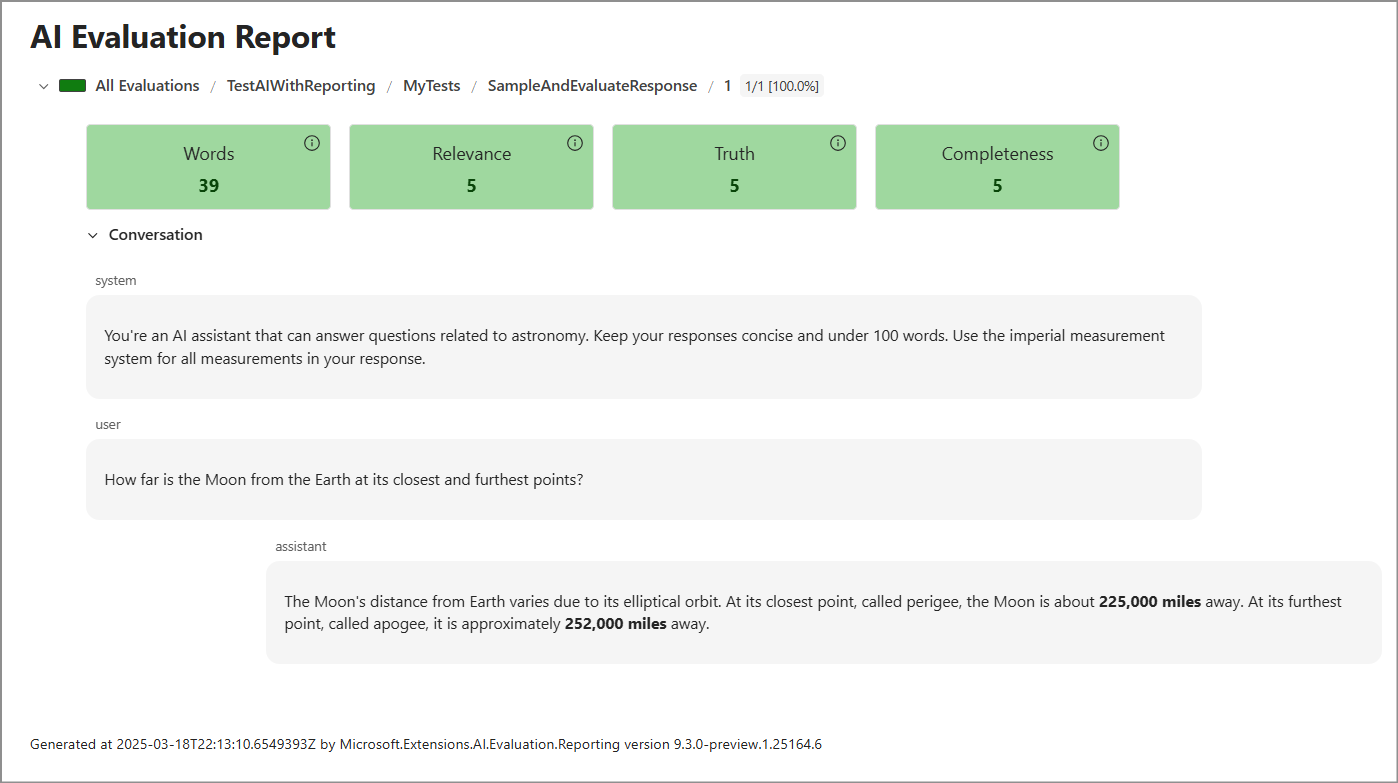
Próximos passos
- Navegue até o diretório onde os resultados do teste são armazenados (que é
C:\TestReports, a menos que você modificou o local quando criou o ReportingConfiguration). No subdiretórioresults, observe que há uma pasta para cada execução de teste nomeada com um carimbo de data/horaExecutionName. Dentro de cada uma dessas pastas há uma pasta para cada nome de cenário — neste caso, apenas o único método de teste no projeto. Essa pasta contém um ficheiro JSON com todos os dados, incluindo as mensagens, resposta e resultado da avaliação. - Expanda a avaliação. Aqui ficam algumas ideias:
- Adicione outro avaliador personalizado, como um avaliador que usa IA para determinar o sistema de medição utilizado na resposta.
- Adicione outro método de teste, por exemplo, um método que avalia várias respostas do LLM. Como cada resposta pode ser diferente, é bom analisar e avaliar pelo menos algumas respostas a uma pergunta. Nesse caso, você especifica um nome de iteração cada vez que chama CreateScenarioRunAsync(String, String, IEnumerable<String>, IEnumerable<String>, CancellationToken).
Colabore connosco no GitHub
A origem deste conteúdo pode ser encontrada no GitHub, onde também pode criar e rever problemas e pedidos Pull. Para mais informações, consulte o nosso guia do contribuidor.